

Pourquoi devrions-nous limiter le courant ?
Comme je l'ai dit plus haut, plus de trafic est effectivement une bonne chose, mais s'il est surchargé et que le système se bloque, tout le monde en souffrira.

Ainsi, avant diverses activités de promotion majeures, il est nécessaire de tester le système, d'évaluer le QPS de pointe de l'ensemble du système et d'effectuer certains réglages de limitation de courant s'il dépasse un certain seuil. , il refusera de traiter ou retardera le traitement pour éviter un blocage du système.
Quelle est la différence entre la limitation de courant et la fusion ?
La limitation du trafic se produit avant l'arrivée du trafic et le trafic excédentaire est restreint.
Le disjoncteur est un mécanisme permettant de gérer les défauts. Il se produit après l'arrivée du trafic. Si le système tombe en panne ou est anormal, le fusible coupe automatiquement la demande pour empêcher le défaut de s'étendre davantage et de provoquer une avalanche de service.
Quelle est la différence entre la limitation de courant et l'écrêtage de pointe ?
Le Peak Clipping est un processus de lissage du trafic, qui évite une surcharge instantanée du système en augmentant lentement le taux de traitement des requêtes.
La coupe de pointe est probablement un réservoir, qui stocke le débit et s'écoule lentement. La limitation du débit est probablement une porte, qui rejette l'excès de débit.
Alors, comment mettre en œuvre une limitation de courant spécifique ? Cela peut se résumer aux étapes suivantes :
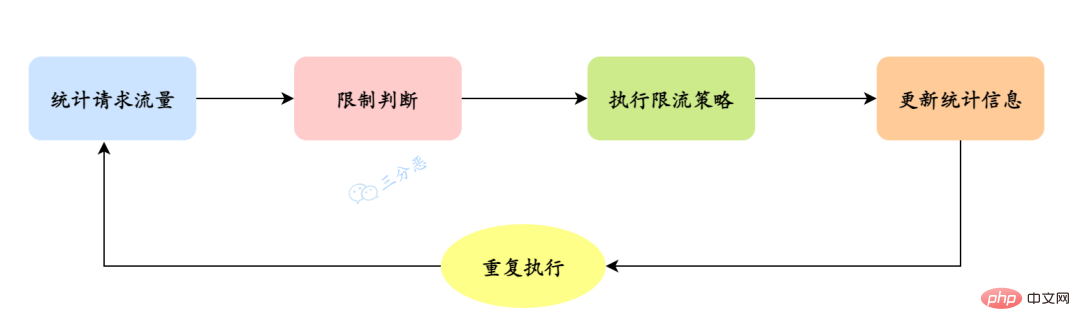
Il convient de noter que la mise en œuvre spécifique de l'algorithme de limitation actuelle peut varier en fonction des différents Ajuster et optimiser en fonction des scénarios et des besoins, comme l'utilisation d'un algorithme de compartiment à jetons, d'un algorithme de compartiment à fuite, etc.
Nous avons remarqué que dans le processus général de limitation de courant, il est nécessaire de compter le volume de la demande et de mettre à jour les statistiques, donc les statistiques et les mises à jour du volume de la demande doivent être conservé dans un entrepôt.
S'il s'agit simplement d'un environnement autonome, il est facile de le manipuler et de le stocker directement localement.

Mais d'une manière générale, nos services sont déployés en clusters. Comment parvenir à une limitation globale du courant entre plusieurs machines ?
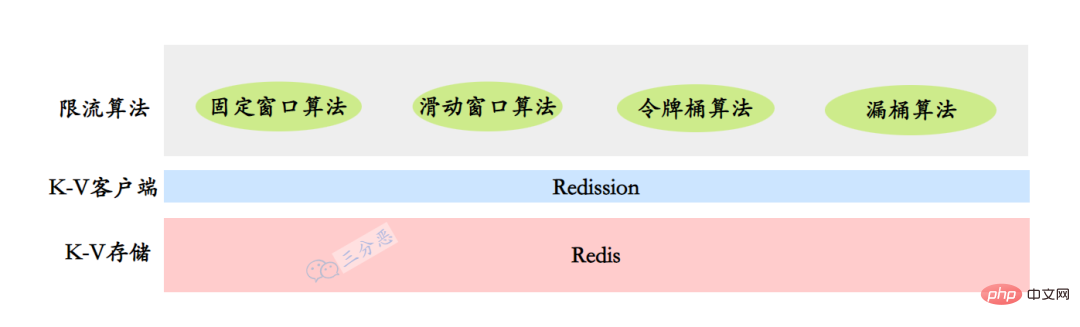
À l'heure actuelle, nous pouvons placer nos informations statistiques dans un stockage K-V distribué tel que Tair ou Redis.
Ensuite, nous commençons à implémenter certains algorithmes de limitation de courant courants. Ici, nous utilisons Redis comme stockage distribué. Inutile de dire que Redis est la base de données de cache distribuée la plus populaire en tant que client Redis. La redission n'est utilisée que pour les verrous distribués, ce qui est un peu "non qualifié". En fait, elle est également très simple à utiliser en tant que client Redis.
Avant de commencer, préparons brièvement l'environnement. Nous n'entrerons pas dans les détails de l'installation de Redis et de la création de projets.
"Ajouter une dépendance" principe <dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.2</version>
</dependency>
public class RedissonConfig {
private static final String REDIS_ADDRESS = "redis://127.0.0.1:6379";
private static volatile RedissonClient redissonClient;
public static RedissonClient getInstance(){
if (redissonClient==null){
synchronized (RedissonConfig.class){
if (redissonClient==null){
Config config = new Config();
config.useSingleServer().setAddress(REDIS_ADDRESS);
redissonClient = Redisson.create(config);
return redissonClient;
}
}
}
return redissonClient;
}
}Bien sûr, vous pouvez également écrire une interface et utiliser des outils de tests de stress tels que Jmeter pour tester. incrementAndGet

Afin d'atténuer le problème de trafic soudain d'une fenêtre fixe, l'algorithme de fenêtre coulissante peut être utilisé. Le contrôle de flux TCP dans les réseaux informatiques utilise l'algorithme de fenêtre coulissante.
Le principe de l'algorithme de limitation de courant à fenêtre glissante est de diviser une grande fenêtre temporelle en plusieurs petites fenêtres temporelles, et chaque petite fenêtre a un décompte indépendant.
Lorsqu'une demande arrive, déterminez si le nombre de demandes dépasse la limite de la fenêtre entière. La fenêtre avance à chaque foisCoulissanteUne petite fenêtre d'unité. 滑动一个小的单元窗口。
例如下面这个滑动窗口,将大时间窗口1min分成了5个小窗口,每个小窗口的时间是12s。
每个单元格有自己独立的计数器,每过12s就会向前移动一格。
假如有请求在00:01的时候过来,这时候窗口的计数就是3+12+9+15=39,也能起到限流的作用。
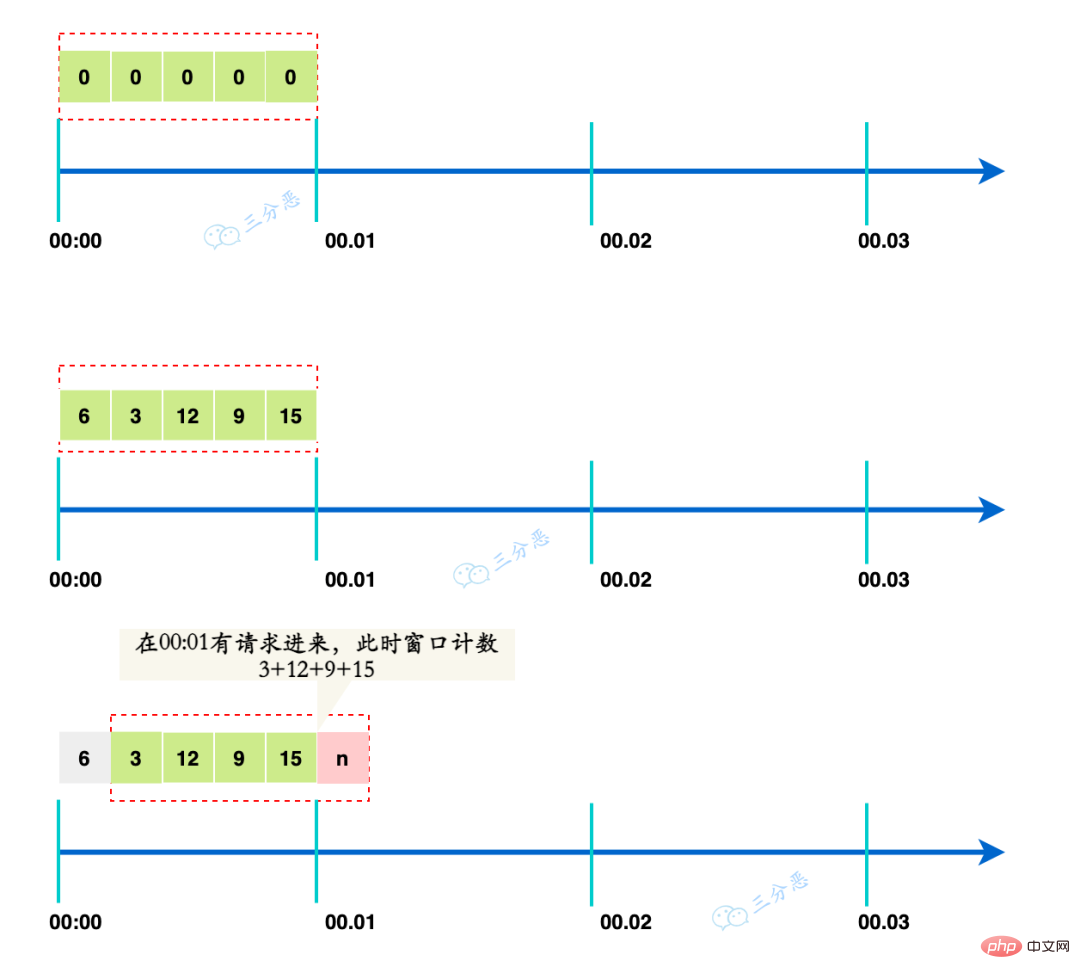
这就是为什么滑动窗口能解决临界问题,滑的格子越多,那么整体的滑动就会越平滑
🎜Schéma schématique de l'algorithme de fenêtre coulissante🎜🎜🎜C'est pourquoi la fenêtre coulissante peut résoudre le problème critique, plus il y a de grilles coulissantes, plus le glissement global sera Lisse</ code>, l'effet limite actuel sera plus précis. 🎜🎜Implémentation de l'algorithme🎜🎜Alors, comment implémentons-nous ici l'algorithme de limitation de courant à fenêtre glissante ? C'est très simple, on peut utiliser directement la structure d'ensemble ordonné (zset) de Redis. 🎜🎜Nous utilisons l'horodatage comme score et membre Lorsqu'une demande arrive, l'horodatage actuel est ajouté à l'ensemble commandé. Ensuite, pour les requêtes en dehors de la fenêtre, nous pouvons calculer l'horodatage de début en fonction de la taille de la fenêtre et supprimer les requêtes en dehors de la fenêtre. De cette façon, la taille de l’ensemble commandé correspond au nombre de requêtes dans notre fenêtre. 🎜<figure data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;display: flex;flex-direction: column;justify-content: center;align-items: center;"><img src="https://img.php.cn/upload/article/001/273/727/677f62b858839b392d242dedd2dafb30-7.png"/ alt="Quatre algorithmes de limitation de courant distribués et implémentation du code" ><figcaption style="max-width:90%">zset实现滑动窗口</figcaption></figure><ul class="list-paddingleft-1" data-tool="mdnice编辑器" style="margin-top: 8px;margin-bottom: 8px;padding-left: 25px;list-style-type: square;"><li><section style="margin-top: 5px;margin-bottom: 5px;line-height: 26px;color: rgb(1, 1, 1);">代码实现</section></li></ul><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false;">public class SlidingWindowRateLimiter {
public static final String KEY = "slidingWindowRateLimiter:";
/**
* 请求次数限制
*/
private Long limit;
/**
* 窗口大小(单位:S)
*/
private Long windowSize;
public SlidingWindowRateLimiter(Long limit, Long windowSize) {
this.limit = limit;
this.windowSize = windowSize;
}
public boolean triggerLimit(String path) {
RedissonClient redissonClient = RedissonConfig.getInstance();
//窗口计数
RScoredSortedSet<Long> counter = redissonClient.getScoredSortedSet(KEY + path);
//使用分布式锁,避免并发设置初始值的时候,导致窗口计数被覆盖
RLock rLock = redissonClient.getLock(KEY + "LOCK:" + path);
try {
rLock.lock(200, TimeUnit.MILLISECONDS);
// 当前时间戳
long currentTimestamp = System.currentTimeMillis();
// 窗口起始时间戳
long windowStartTimestamp = currentTimestamp - windowSize * 1000;
// 移除窗口外的时间戳,左闭右开
counter.removeRangeByScore(0, true, windowStartTimestamp, false);
// 将当前时间戳作为score,也作为member,
// TODO:高并发情况下可能没法保证唯一,可以加一个唯一标识
counter.add(currentTimestamp, currentTimestamp);
//使用zset的元素个数,作为请求计数
long count = counter.size();
// 判断时间戳数量是否超过限流阈值
if (count > limit) {
System.out.println("[triggerLimit] path:" + path + " count:" + count + " over limit:" + limit);
return true;
}
return false;
} finally {
rLock.unlock();
}
}
}</pre><div class="contentsignin">Copier après la connexion</div></div><p data-tool="mdnice编辑器" style="padding-top: 8px;padding-bottom: 8px;line-height: 26px;">这里还有一个小的可以完善的点,zset在member相同的情况下,是会覆盖的,也就是说高并发情况下,时间戳可能会重复,那么就有可能统计的请求偏少,这里可以用<code style="padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(255, 100, 65);">时间戳+随机数来缓解,也可以生成唯一序列来解决,比如UUID、雪花算法等等。class SlidingWindowRateLimiterTest {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(30, 50, 10, TimeUnit.SECONDS, new LinkedBlockingDeque<>(10));
@Test
@DisplayName("滑动窗口限流")
void triggerLimit() throws InterruptedException {
SlidingWindowRateLimiter slidingWindowRateLimiter = new SlidingWindowRateLimiter(10L, 1L);
//模拟在不同时间片内的请求
for (int i = 0; i < 8; i++) {
CountDownLatch countDownLatch = new CountDownLatch(20);
for (int j = 0; j < 20; j++) {
threadPoolExecutor.execute(() -> {
boolean isLimit = slidingWindowRateLimiter.triggerLimit("/test");
System.out.println(isLimit);
countDownLatch.countDown();
});
}
countDownLatch.await();
//休眠10s
TimeUnit.SECONDS.sleep(10L);
}
}
}用Redis实现了滑动窗口限流,解决了固定窗口限流的边界问题,当然这里也带来了新的问题,因为我们存储了窗口期的所有请求,所以高并发的情况下,可能会比较占内存。
我们可以看到,计数器类的限流,体现的是一个“戛然而止”,超过限制,立马决绝,但是有时候,我们可能只是希望请求平滑一些,追求的是“波澜不惊”,这时候就可以考虑使用其它的限流算法。
漏桶算法(Leaky Bucket),名副其实,就是请求就像水一样以任意速度注入漏桶,而桶会按照固定的速率将水漏掉。
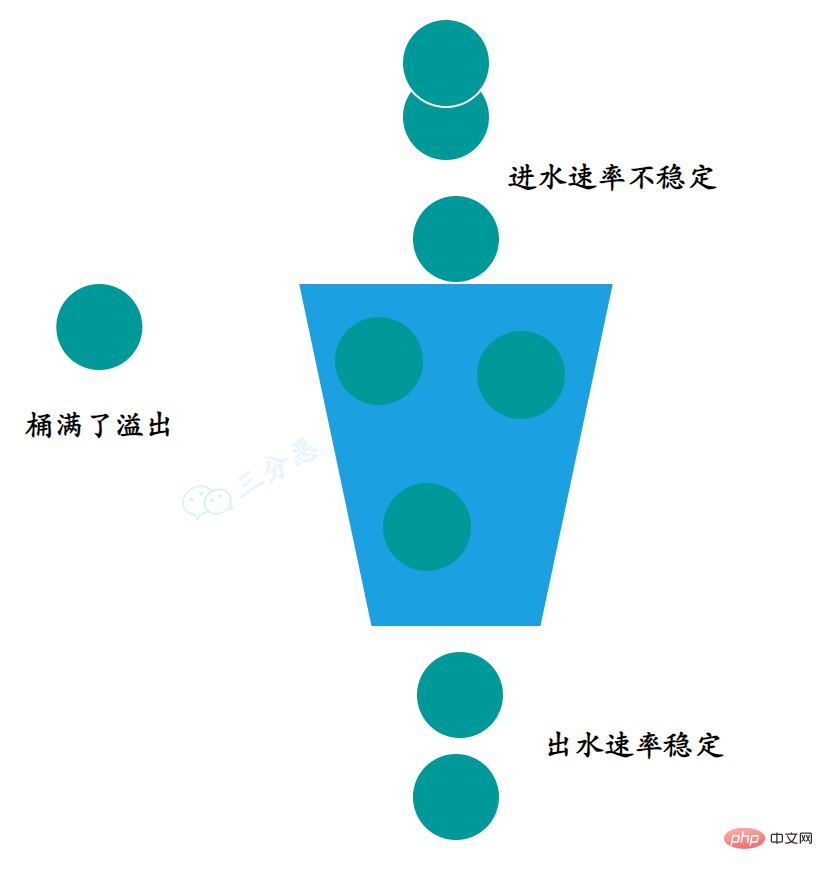
当进水速率大于出水速率的时候,漏桶会变满,此时新进入的请求将会被丢弃。
漏桶算法的两大作用是网络流量整形(Traffic Shaping)和速度限制(Rate Limiting)。
我们接着看看具体应该怎么实现。
在滑动窗口限流算法里我们用到了RScoredSortedSet,非常好用对不对,这里也可以用这个结构,直接使用ZREMRANGEBYSCORE命令来删除旧的请求。
进水就不用多说了,请求进来,判断桶有没有满,满了就拒绝,没满就往桶里丢请求。
那么出水怎么办呢?得保证稳定速率出水,可以用一个定时任务,来定时去删除旧的请求。
public class LeakyBucketRateLimiter {
private RedissonClient redissonClient = RedissonConfig.getInstance();
private static final String KEY_PREFIX = "LeakyBucket:";
/**
* 桶的大小
*/
private Long bucketSize;
/**
* 漏水速率,单位:个/秒
*/
private Long leakRate;
public LeakyBucketRateLimiter(Long bucketSize, Long leakRate) {
this.bucketSize = bucketSize;
this.leakRate = leakRate;
//这里启动一个定时任务,每s执行一次
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);
executorService.scheduleAtFixedRate(this::leakWater, 0, 1, TimeUnit.SECONDS);
}
/**
* 漏水
*/
public void leakWater() {
RSet<String> pathSet=redissonClient.getSet(KEY_PREFIX+":pathSet");
//遍历所有path,删除旧请求
for(String path:pathSet){
String redisKey = KEY_PREFIX + path;
RScoredSortedSet<Long> bucket = redissonClient.getScoredSortedSet(KEY_PREFIX + path);
// 获取当前时间
long now = System.currentTimeMillis();
// 删除旧的请求
bucket.removeRangeByScore(0, true,now - 1000 * leakRate,true);
}
}
/**
* 限流
*/
public boolean triggerLimit(String path) {
//加锁,防止并发初始化问题
RLock rLock = redissonClient.getLock(KEY_PREFIX + "LOCK:" + path);
try {
rLock.lock(100,TimeUnit.MILLISECONDS);
String redisKey = KEY_PREFIX + path;
RScoredSortedSet<Long> bucket = redissonClient.getScoredSortedSet(redisKey);
//这里用一个set,来存储所有path
RSet<String> pathSet=redissonClient.getSet(KEY_PREFIX+":pathSet");
pathSet.add(path);
// 获取当前时间
long now = System.currentTimeMillis();
// 检查桶是否已满
if (bucket.size() < bucketSize) {
// 桶未满,添加一个元素到桶中
bucket.add(now,now);
return false;
}
// 桶已满,触发限流
System.out.println("[triggerLimit] path:"+path+" bucket size:"+bucket.size());
return true;
}finally {
rLock.unlock();
}
}
}在代码实现里,我们用了RSet来存储path,这样一来,一个定时任务,就可以搞定所有path对应的桶的出水,而不用每个桶都创建一个一个定时任务。
这里我直接用ScheduledExecutorService启动了一个定时任务,1s跑一次,当然集群环境下,每台机器都跑一个定时任务,对性能是极大的浪费,而且不好管理,我们可以用分布式定时任务,比如xxl-job去执行leakWater。
class LeakyBucketRateLimiterTest {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(30, 50, 10, TimeUnit.SECONDS, new LinkedBlockingDeque<>(10));
@Test
@DisplayName("漏桶算法")
void triggerLimit() throws InterruptedException {
LeakyBucketRateLimiter leakyBucketRateLimiter = new LeakyBucketRateLimiter(10L, 1L);
for (int i = 0; i < 8; i++) {
CountDownLatch countDownLatch = new CountDownLatch(20);
for (int j = 0; j < 20; j++) {
threadPoolExecutor.execute(() -> {
boolean isLimit = leakyBucketRateLimiter.triggerLimit("/test");
System.out.println(isLimit);
countDownLatch.countDown();
});
}
countDownLatch.await();
//休眠10s
TimeUnit.SECONDS.sleep(10L);
}
}
}漏桶算法能够有效防止网络拥塞,实现也比较简单。
但是,因为漏桶的出水速率是固定的,假如突然来了大量的请求,那么只能丢弃超量的请求,即使下游能处理更大的流量,没法充分利用系统资源。
令牌桶算法来了!
令牌桶算法是对漏桶算法的一种改进。
它的主要思想是:系统以一种固定的速率向桶中添加令牌,每个请求在发送前都需要从桶中取出一个令牌,只有取到令牌的请求才被通过。因此,令牌桶算法允许请求以任意速率发送,只要桶中有足够的令牌。
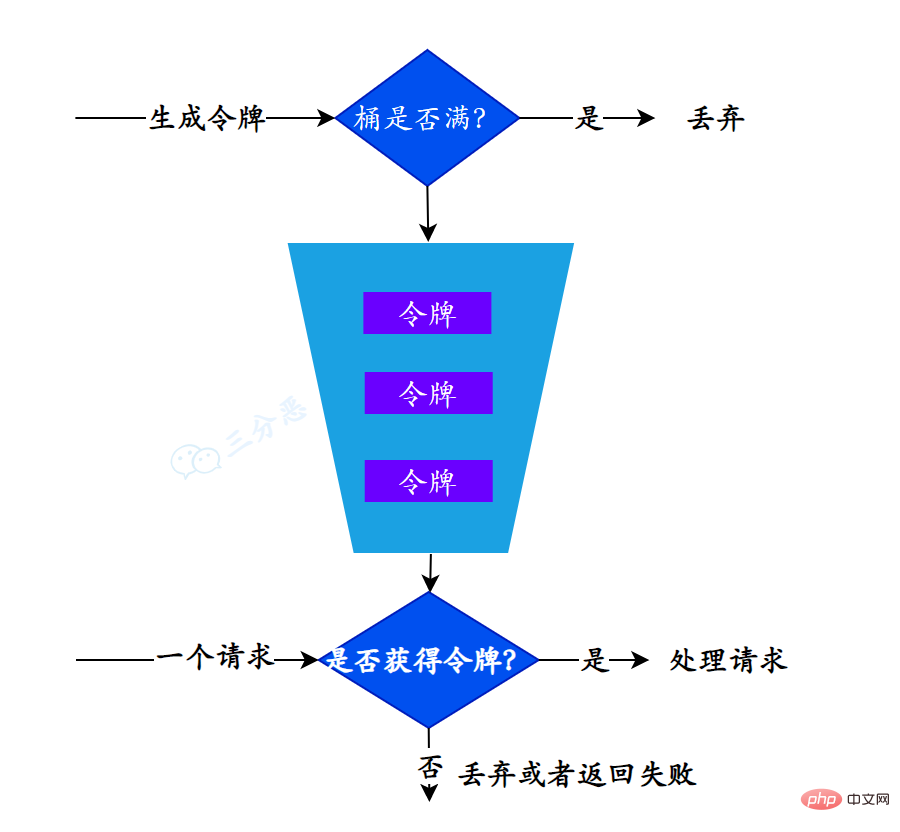
我们继续看怎么实现,首先是要发放令牌,要固定速率,那我们又得开个线程,定时往桶里投令牌,然后……
——然后Redission提供了令牌桶算法的实现,舒不舒服?

拿来就用!
public class TokenBucketRateLimiter {
public static final String KEY = "TokenBucketRateLimiter:";
/**
* 阈值
*/
private Long limit;
/**
* 添加令牌的速率,单位:个/秒
*/
private Long tokenRate;
public TokenBucketRateLimiter(Long limit, Long tokenRate) {
this.limit = limit;
this.tokenRate = tokenRate;
}
/**
* 限流算法
*/
public boolean triggerLimit(String path){
RedissonClient redissonClient=RedissonConfig.getInstance();
RRateLimiter rateLimiter = redissonClient.getRateLimiter(KEY+path);
// 初始化,设置速率模式,速率,间隔,间隔单位
rateLimiter.trySetRate(RateType.OVERALL, limit, tokenRate, RateIntervalUnit.SECONDS);
// 获取令牌
return rateLimiter.tryAcquire();
}
}Redisson实现的,还是比较稳的,这里就不测试了。
关于Redission是怎么实现这个限速器的,大家可以看一下参考[3],还是Redisson家的老传统——Lua脚本,设计相当巧妙。
在这篇文章里,我们对四(三)种限流算法进行了分布式实现,采用了非常好用的Redission客户端,当然我们也有不完善的地方:
如果后面有机会,希望可以继续完善这个简单的Demo,达到工程级的应用。
除此之外,市面上也有很多好用的开源限流工具:
Spring Cloud Gateway、NginxCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



