


Prometheus est un système de surveillance et d'alarme open source basé sur une base de données de séries chronologiques. En parlant de Prometheus, nous devons mentionner SoundCloud, qui est une plateforme de partage de musique en ligne, similaire à YouTube pour le partage de vidéos. À mesure qu'ils progressent sur la voie de l'architecture des microservices, avec l'apparition de centaines ou de milliers de services, l'utilisation des systèmes de surveillance traditionnels StatsD et Graphite présente de nombreuses limites.
Ils ont donc commencé à développer un nouveau système de surveillance en 2012. L'auteur original de Prometheus est Matt T. Proud, qui a également rejoint SoundCloud en 2012. En fait, avant de rejoindre SoundCloud, Matt travaillait chez Google. Il s'est inspiré du gestionnaire de cluster de Google, Borg, et de son système de surveillance Borgmon, pour développer l'open. système de surveillance des sources Prometheus Comme de nombreux projets Google, le langage de programmation utilisé est Go.
Évidemment, en tant que solution de système de surveillance de l'architecture des microservices, Prometheus est également indissociable des conteneurs. Dès le 9 août 2006, Eric Schmidt a proposé pour la première fois le concept de cloud computing (Cloud Computing) lors de la Search Engine Conference. Au cours des dix années suivantes, le développement du cloud computing a été rapide.
En 2013, Matt Stine de Pivotal a proposé le concept de Cloud Native. Cloud Native se compose d'une architecture de microservices, de DevOps et d'une infrastructure agile représentée par des conteneurs pour aider les entreprises à fournir des logiciels de manière rapide, continue et fiable.
Afin d'unifier les interfaces de cloud computing et les normes associées, en juillet 2015, la Cloud Native Computing Foundation (CNCF), affiliée à la Linux Foundation, a vu le jour. Le premier projet à rejoindre le CNCF était Kubernetes de Google, et Prometheus a été le deuxième à le rejoindre (en 2016).
Nous pouvons trouver un article sur le blog officiel de SoundCloud expliquant pourquoi ils doivent développer un nouveau système de surveillance, Prometheus : Monitoring at SoundCloud. Dans cet article, ils ont présenté, Le système de surveillance qu'ils ont. Le besoin doit répondre aux quatre caractéristiques suivantes :
Simplement parlant, il s'agit des quatre caractéristiques suivantes :
"Modèle de données multidimensionnel" Cette fonctionnalité correspond exactement à ce dont a besoin une base de données de séries chronologiques. Prometheus n'est donc pas seulement un système de surveillance, mais également une base de données de séries chronologiques. Alors pourquoi Prometheus n'utilise-t-il pas directement la base de données de séries chronologiques existante comme stockage principal ? En effet, SoundCloud souhaite non seulement que son système de surveillance ait les caractéristiques d'une base de données de séries chronologiques, mais doit également être très facile à déployer et à entretenir.En plus de ces quatre fonctionnalités majeures, à mesure que Prometheus continue de se développer, il commence à prendre en charge des fonctionnalités de plus en plus avancées, telles que : la découverte de services, un affichage de graphiques plus riche, l'utilisation de stockage externe, des règles d'alarme puissantes et diverses méthodes de notification.
L'image suivante est le schéma global de l'architecture de Prometheus :
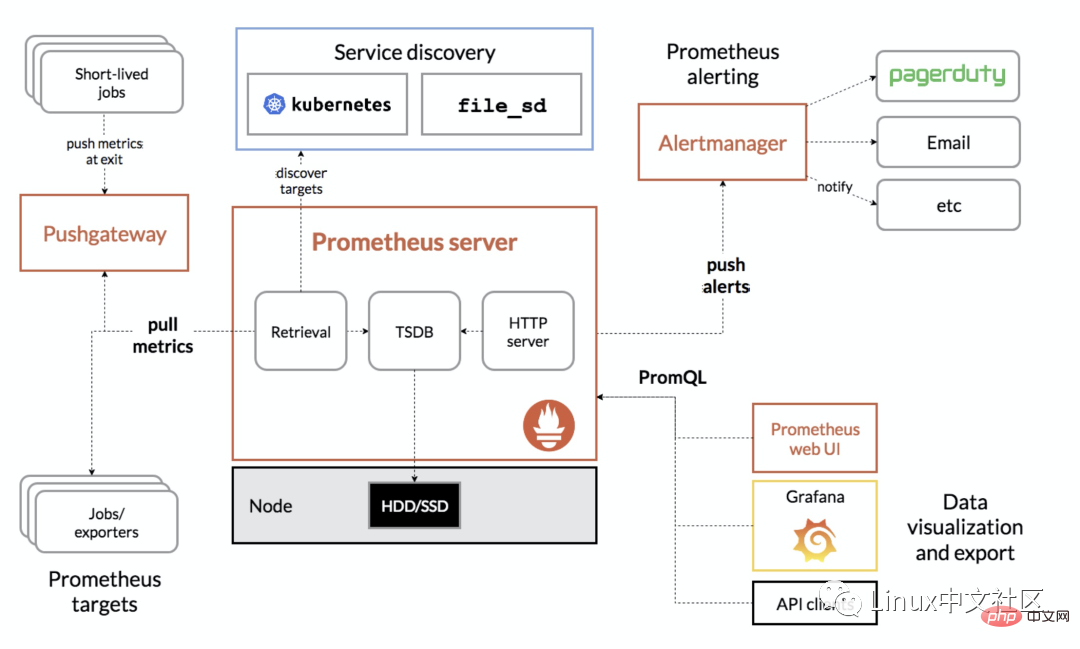
Prometheus peut prendre en charge diverses méthodes d'installation, notamment Docker, Ansible, Chef, Puppet, Saltstack, etc. Les deux méthodes les plus simples sont présentées ci-dessous. L'une consiste à utiliser directement le fichier exécutable compilé, qui peut être utilisé immédiatement, et l'autre consiste à utiliser une image Docker.
Obtenez d'abord la dernière version et l'adresse de téléchargement de Prometheus sur la page de téléchargement du site officiel. La dernière version est la 2.4.3 (octobre 2018). Exécutez la commande suivante pour télécharger et décompresser :
.$ wget https://github.com/prometheus/prometheus/releases/download/v2.4.3/prometheus-2.4.3.linux-amd64.tar.gz $ tar xvfz prometheus-2.4.3.linux-amd64.tar.gz
Puis changez Allez dans le répertoire décompressé et vérifiez la version de Prometheus :
$ cd prometheus-2.4.3.linux-amd64 $ ./prometheus --version prometheus, version 2.4.3 (branch: HEAD, revision: 167a4b4e73a8eca8df648d2d2043e21bdb9a7449) build user: root@1e42b46043e9 build date: 20181004-08:42:02 go version: go1.11.1
Exécutez le serveur Prometheus :
$ ./prometheus --config.file=prometheus.yml
Il est plus facile d'installer Prometheus à l'aide de Docker, exécutez simplement la commande suivante :
$ sudo docker run -d -p 9090:9090 prom/prometheus
Généralement , nous spécifierons également l'emplacement du fichier de configuration :
$ sudo docker run -d -p 9090:9090 \ -v ~/docker/prometheus/:/etc/prometheus/ \ prom/prometheus
Nous plaçons le fichier de configuration à l'emplacement local~/docker/prometheus/prometheus.yml,这样可以方便编辑和查看,通过-v参数将本地的配置文件挂载到/etc/prometheus/, qui est l'emplacement par défaut du fichier de configuration chargé par prometheus dans le conteneur.
如果我们不确定默认的配置文件在哪,可以先执行上面的不带-v参数的命令,然后通过docker inspect命名看看容器在运行时默认的参数有哪些(下面的 Args 参数):
$ sudo docker inspect 0c [...] "Id": "0c4c2d0eed938395bcecf1e8bb4b6b87091fc4e6385ce5b404b6bb7419010f46", "Created": "2018-10-15T22:27:34.56050369Z", "Path": "/bin/prometheus", "Args": [ "--config.file=/etc/prometheus/prometheus.yml", "--storage.tsdb.path=/prometheus", "--web.console.libraries=/usr/share/prometheus/console_libraries", "--web.console.templates=/usr/share/prometheus/consoles" ], [...]
正如上面两节看到的,Prometheus 有一个配置文件,通过参数--config.file来指定,配置文件格式为 YAML。我们可以打开默认的配置文件prometheus.yml看下里面的内容:
/etc/prometheus $ cat prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090']
Prometheus 默认的配置文件分为四大块:
scrape_intervalreprésente comment long Prometheus récupère les données une fois,
evaluation_intervalindique la fréquence de détection de la règle d'alarme ;
scrape_interval表示 Prometheus 多久抓取一次数据,
evaluation_interval表示多久检测一次告警规则;
scrape_config 块:这里定义了 Prometheus 要抓取的目标,我们可以看到默认已经配置了一个名称为prometheus的 job,这是因为 Prometheus 在启动的时候也会通过 HTTP 接口暴露自身的指标数据,这就相当于 Prometheus 自己监控自己,虽然这在真正使用 Prometheus 时没啥用处,但是我们可以通过这个例子来学习如何使用 Prometheus;可以访问http://localhost:9090/metrics查看 Prometheus 暴露了哪些指标;
通过上面的步骤安装好 Prometheus 之后,我们现在可以开始体验 Prometheus 了。Prometheus 提供了可视化的 Web UI 方便我们操作,直接访问http://localhost:9090/
scrape_config block : Prometheus est défini ici. Pour la cible capturée, nous pouvons voir qu'elle a été configurée avec un nom nomméprometheus travail, en effet, Prometheus exposera également ses propres données d'indicateur via l'interface HTTP au démarrage, ce qui équivaut à la surveillance de Prometheus lui-même. Bien que cela soit de peu d'utilité lors de l'utilisation réelle de Prometheus, nous pouvons utilisez cet exemple pour apprendre à utiliser Prometheus ; visitez http://localhost:9090/metricsDécouvrez quels indicateurs Prometheus expose ;













