


Les grands modèles linguistiques (LLM) actuels tels que GPT4 ont montré d'excellentes capacités multimodales en suivant des instructions ouvertes à partir d'une image. Cependant, les performances de ces modèles dépendent fortement des choix de structure du réseau, des données de formation et des stratégies de formation, mais ces choix n'ont pas été largement discutés dans la littérature précédente. De plus, il existe actuellement un manque de références appropriées pour évaluer et comparer ces modèles, ce qui limite le développement de LLM multimodaux.
 Photos
Photos
Dans cet article, l'auteur mène une étude systématique et complète sur la formation de tels modèles sous des aspects à la fois quantitatifs et qualitatifs. Plus de 20 variantes ont été mises en place. Pour la structure du réseau, différents squelettes de LLM et conceptions de modèles ont été comparés ; pour les données de formation, l'impact des données et des stratégies d'échantillonnage a été étudié en termes d'instructions, l'effet de diverses invites sur le modèle ; l’instruction suivant la capacité a été explorée. Pour les benchmarks, l'article propose pour la première fois Open-VQA, un ensemble d'évaluation de questions-réponses visuelles ouvertes comprenant des tâches d'image et de vidéo.
Sur la base des conclusions expérimentales, l'auteur a proposé Lynx, qui montre la compréhension multimodale la plus précise tout en conservant la meilleure multimodalité par rapport au modèle open source existant de style GPT4 Capacité générative.
Différent des tâches typiques de langage visuel, le principal défi de l'évaluation des modèles de style GPT4 est d'équilibrer les performances des capacités de génération de texte et de la précision de la compréhension multimodale. Pour résoudre ce problème, les auteurs proposent un nouveau benchmark Open-VQA incluant des données vidéo et image, et mènent une évaluation complète des modèles open source actuels.
Plus précisément, deux schémas d'évaluation quantitative sont adoptés :
Afin d'étudier en profondeur la stratégie de formation des LLM multimodaux, l'auteur part principalement de la structure du réseau (réglage fin des préfixes/attention croisée), des données de formation (sélection des données et rapport de combinaison), instructions (instruction unique/plus de vingt variantes ont été définies dans divers aspects tels qu'une indication diversifiée), modèle LLM (LLaMA [5]/Vicuna [6]), pixels d'image (420/224), etc., et les principales conclusions suivantes ont été tirées à travers des expériences :
L'auteur a proposé Lynx (猞猁)——formation en deux étapes GPT4 -modèle de style avec réglage fin du préfixe. Dans la première étape, environ 120 M paires image-texte sont utilisées pour aligner les intégrations visuelles et linguistiques ; dans la deuxième étape, 20 images ou vidéos sont utilisées pour des tâches multimodales et des données de traitement du langage naturel (NLP) pour ajuster le modèle. capacités de suivi de commandes.
 Photos
Photos
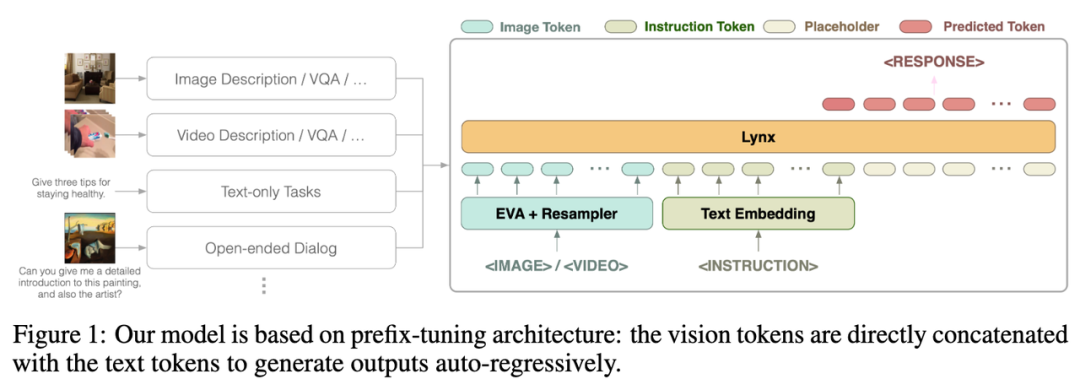
La structure globale du modèle Lynx est présentée dans la figure 1 ci-dessus.
L'entrée visuelle est traitée par l'encodeur visuel pour obtenir des jetons visuels (jetons) $$W_v$$ Après le mappage, elle est épissée avec les jetons d'instruction $$W_l$$ comme entrée des LLM. structure est appelée dans cet article. Il s'agit de "prefix-finetuning" pour la distinguer de la structure cross-attention utilisée par Flamingo [3].
De plus, les auteurs ont découvert que les coûts de formation peuvent être encore réduits en ajoutant Adaptateur après certaines couches de LLM gelés.
L'auteur a évalué les performances des modèles LLM multimodaux open source existants sur Évaluation manuelle Open-VQA, Mme [4] et OwlEval (voir le tableau ci-dessous pour les résultats, et voir le document détaillé de l’évaluation). On peut voir que le modèle Lynx a obtenu les meilleures performances dans les tâches de compréhension d'images et de vidéos Open-VQA, d'évaluation manuelle OwlEval et de tâches Mme Perception. Parmi eux, InstructBLIP atteint également des performances élevées dans la plupart des tâches, mais sa réponse est trop courte. En comparaison, dans la plupart des cas, le modèle Lynx fournit des raisons concises pour soutenir la réponse basée sur la bonne réponse. convivial (voir la section Affichage des cas ci-dessous pour certains cas).
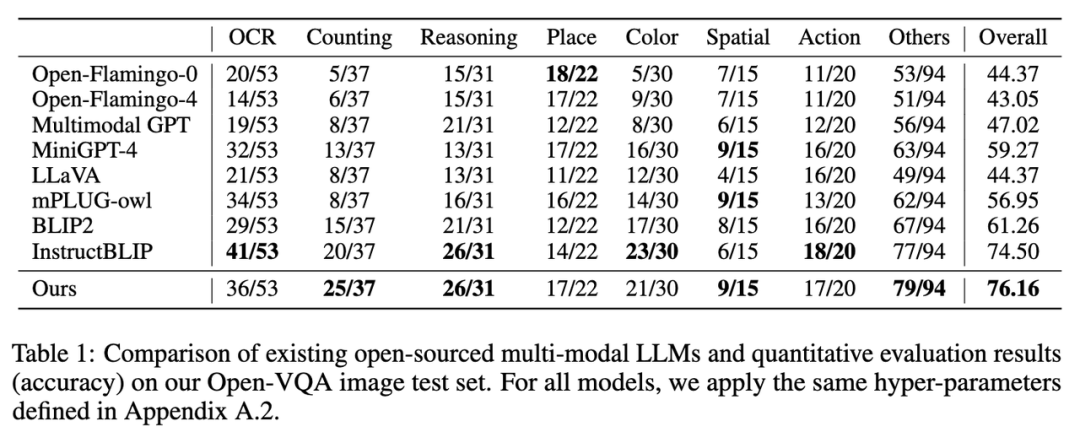
1. Les résultats des indicateurs sur l'ensemble de tests d'images Open-VQA sont présentés dans le tableau 1 ci-dessous :
 Photos
Photos
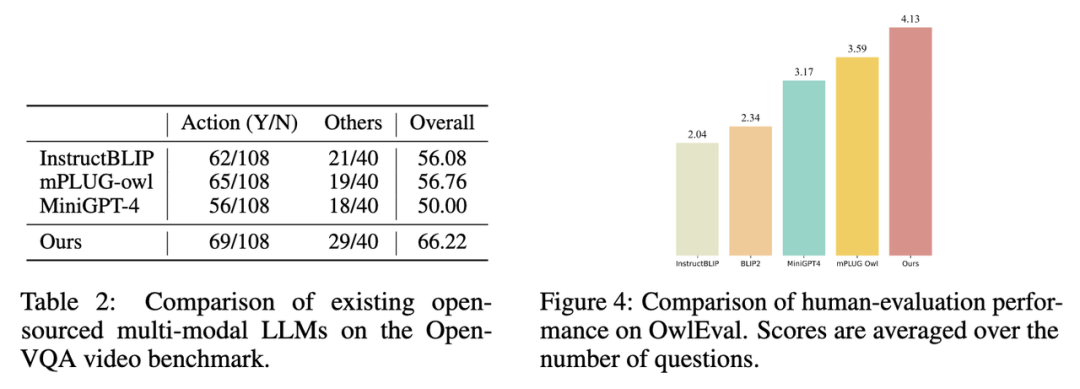
2 Les résultats des indicateurs sur l'ensemble de tests vidéo Open-VQA sont tels qu'indiqués. dans le tableau 1 ci-dessous 2 indiqué.
 photos
photos
3. Sélectionnez le modèle avec le meilleur score dans Open-VQA pour effectuer une évaluation manuelle des effets sur l'ensemble d'évaluation OwlEval. Les résultats sont présentés dans la figure 4 ci-dessus. Il ressort des résultats de l'évaluation manuelle que le modèle Lynx présente les meilleures performances de génération de langage.
 Images
Images
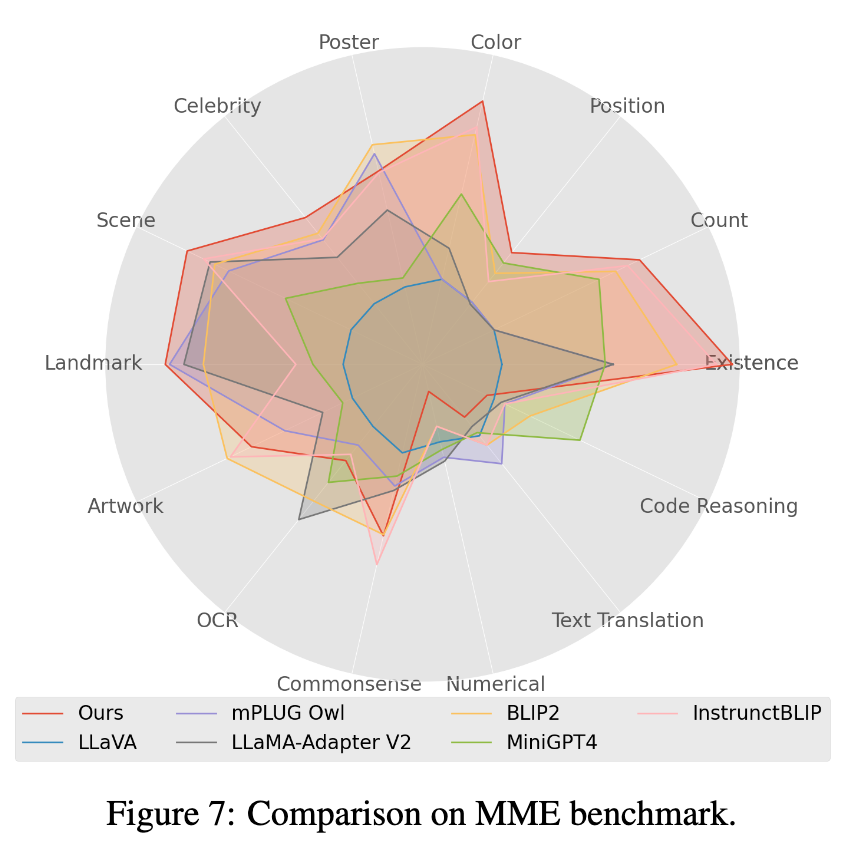
4 Dans le test de référence Mme, les tâches de la classe Perception ont obtenu les meilleures performances, parmi lesquelles 7 des 14 sous-tâches de la classe ont obtenu les meilleures performances. (Voir l'annexe de l'article pour les résultats détaillés) -Boîtier vidéo VQA
Résumé
Dans cet article, à travers des expériences sur plus de vingt variantes de LLM multimodaux, l'auteur détermine le modèle Lynx avec le réglage fin des préfixes comme structure principale et donne un plan d'évaluation Open-VQA avec réponses ouvertes. Les résultats expérimentaux montrent que le modèle Lynx offre la compréhension multimodale la plus précise tout en conservant les meilleures capacités de génération multimodale. 
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quel fichier est une ressource ?
Quel fichier est une ressource ?
 Comment définir un arrêt programmé dans UOS
Comment définir un arrêt programmé dans UOS
 Springcloud cinq composants principaux
Springcloud cinq composants principaux
 Le rôle de la fonction mathématique en langage C
Le rôle de la fonction mathématique en langage C
 Que signifie le wifi désactivé ?
Que signifie le wifi désactivé ?
 Jailbreak iPhone 4
Jailbreak iPhone 4
 La différence entre les fonctions fléchées et les fonctions ordinaires
La différence entre les fonctions fléchées et les fonctions ordinaires
 Comment ignorer la connexion à Internet après le démarrage de Windows 11
Comment ignorer la connexion à Internet après le démarrage de Windows 11








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



