


Le monde vocal auquel participe l'IA est vraiment magique. Il peut non seulement changer la voix d'une personne en celle de n'importe quelle autre personne, mais aussi échanger des voix avec des animaux.
Nous savons que le but de la conversion vocale est de convertir la voix source en voix cible tout en gardant le contenu inchangé. Les méthodes récentes de conversion de la parole de type "any-to-any" améliorent le naturel et la similarité des locuteurs, mais au prix d'une complexité considérablement accrue. Cela signifie que la formation et l’inférence deviennent plus coûteuses, ce qui rend les améliorations difficiles à évaluer et à établir.
La question est la suivante : une conversion vocale de haute qualité nécessite-t-elle de la complexité ? Dans un article récent de l'Université de Stellenbosch en Afrique du Sud, plusieurs chercheurs ont exploré cette question.

Les points forts de la recherche sont :Ils ont introduit la conversion vocale K-Nearest Neighbour (kNN-VC), une méthode de conversion vocale simple et puissante de n'importe quel à n'importe quel. Au lieu de former un modèle de transformation explicite, la régression du K-plus proche voisin est simplement utilisée.
Plus précisément, les chercheurs ont d'abord utilisé un modèle de représentation vocale auto-supervisé pour extraire la séquence de caractéristiques de l'énoncé source et de l'énoncé de référence, puis ont converti chaque image de la représentation source en locuteur cible en la remplaçant par la plus proche. voisin dans la référence, et enfin utiliser un vocodeur neuronal pour synthétiser les caractéristiques converties afin d'obtenir la parole convertie.
À en juger par les résultats, malgré sa simplicité, KNN-VC atteint une intelligibilité et une similarité de locuteur comparables, voire améliorées, dans les évaluations subjectives et objectives par rapport à plusieurs systèmes de conversion vocale de base.
Apprécions l'effet de la conversion vocale KNN-VC. En examinant d'abord la conversion de la voix humaine, KNN-VC est appliqué aux locuteurs sources et cibles invisibles dans l'ensemble de données LibriSpeech.
Voix source00:11
Voix synthétisée 100:11
Voix synthétisée 200:11
K NN-VC prend également en charge la conversion vocale multilingue, Par exemple, de l'espagnol vers l'allemand, de l'allemand vers le japonais, du chinois vers l'espagnol.
Source Chinois00:08
Cible Espagnol00:05
Discours synthétique 300:08
Encore plus étonnant ly, KNN-VC peut toujours échanger des voix humaines et les aboiements du chien.
Source chien qui aboie00:09
Source voix humaine00:05
Voix synthétique 400:08
S voix synthétique 500:05
Voyons comment KNN-VC fonctionne et se compare avec d'autres méthodes jixian.
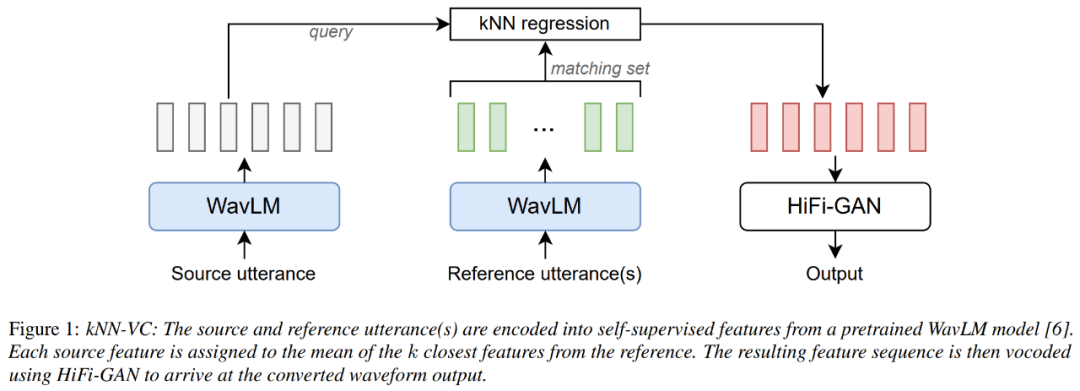
Le schéma d'architecture de kNN-VC est présenté ci-dessous, suivant la structure encodeur-convertisseur-vocodeur. Tout d'abord, l'encodeur extrait les représentations auto-supervisées de la parole source et de référence, puis le convertisseur mappe chaque image source à son voisin le plus proche dans la référence, et enfin le vocodeur génère des formes d'onde audio basées sur les caractéristiques converties.
L'encodeur utilise WavLM, le convertisseur utilise la régression du voisin le plus proche et le vocodeur utilise HiFiGAN. Le seul composant qui nécessite une formation est le vocodeur.
Pour l'encodeur WavLM, le chercheur a uniquement utilisé le modèle WavLM-Large pré-entraîné et n'a effectué aucune formation sur celui-ci dans l'article. Pour le modèle de transformation kNN, kNN est non paramétrique et ne nécessite aucune formation. Pour le vocodeur HiFiGAN, le dépôt original de l'auteur HiFiGAN a été utilisé pour vocoder les fonctionnalités WavLM, devenant ainsi la seule partie nécessitant une formation.
 Photos
Photos
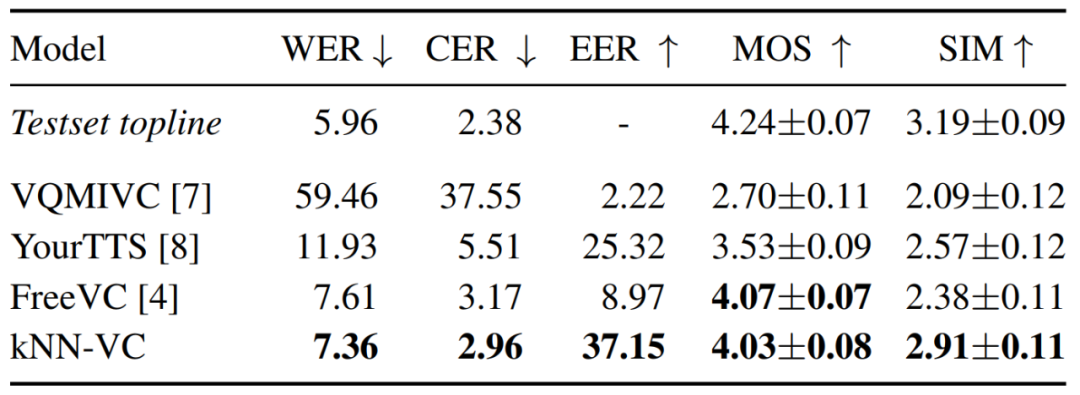
Dans l'expérience, les chercheurs ont d'abord comparé KNN-VC avec d'autres méthodes de base, en utilisant les plus grandes données cibles disponibles (environ 8 minutes d'audio par locuteur) pour tester le système de conversion vocale.
Pour KNN-VC, le chercheur utilise toutes les données cibles comme ensemble de correspondance. Pour la méthode de base, ils font la moyenne des intégrations de locuteurs pour chaque énoncé cible.
Le tableau 1 ci-dessous présente les résultats de chaque modèle en termes d'intelligibilité, de naturel et de similarité des locuteurs. Comme on peut le voir, kNN-VC atteint un naturel et une clarté similaires à ceux du meilleur FreeVC de base, mais avec une similarité de haut-parleur considérablement améliorée. Cela confirme également l'affirmation de cet article : une conversion vocale de haute qualité ne nécessite pas de complexité accrue.
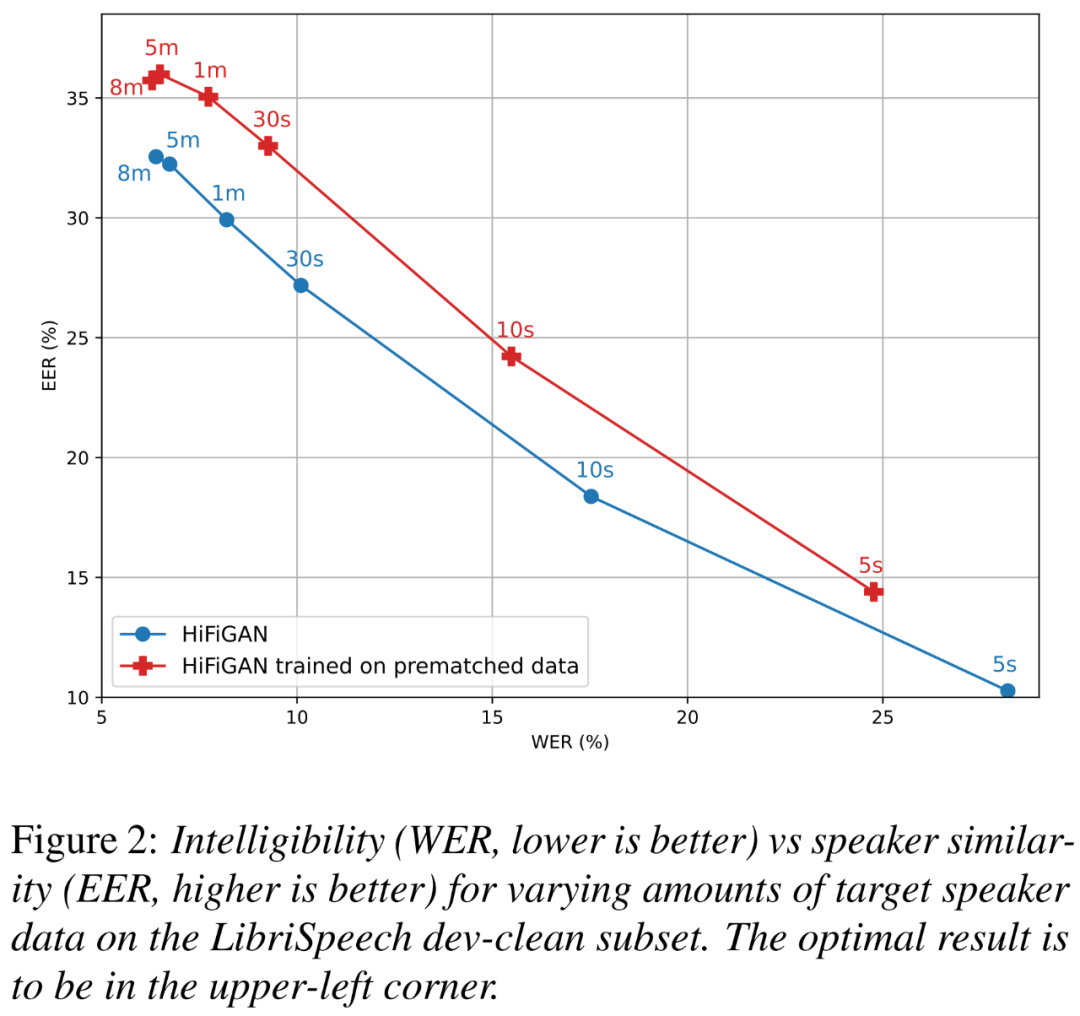
De plus, les chercheurs voulaient comprendre dans quelle mesure l'amélioration était due à la formation HiFi-GAN sur des données pré-appariées, et dans quelle mesure la taille des données du locuteur cible affectait l'intelligibilité et la similarité des locuteurs.
La figure 2 ci-dessous montre la relation entre WER (plus petit est mieux) et EER (plus haut est mieux) pour deux variantes HiFi-GAN à différentes tailles d'enceintes cibles.
 Photos
Photos
Pour cette nouvelle méthode de conversion vocale kNN-VC qui "utilise uniquement les voisins les plus proches", certaines personnes pensent qu'un modèle vocal pré-entraîné est utilisé dans l'article , donc "seulement" est utilisé. Pas tout à fait précis. Mais il est indéniable que le kNN-VC reste plus simple que les autres modèles.
Les résultats prouvent également que kNN-VC est tout aussi efficace, sinon le meilleur, par rapport aux méthodes très complexes de conversion vocale any-to-any.
 Photos
Photos
Certaines personnes ont également dit que l'exemple de l'échange de voix humaine et d'aboiements de chien est très intéressant.
 photos
photos
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment créer un lien symbolique
Comment créer un lien symbolique Comment configurer le serveur Web
Comment configurer le serveur Web Site officiel d'OKEX
Site officiel d'OKEX Linux afficher les informations du système
Linux afficher les informations du système Comment ignorer l'activation en ligne dans Win11
Comment ignorer l'activation en ligne dans Win11 Comment restaurer le casque Bluetooth en mode binaural
Comment restaurer le casque Bluetooth en mode binaural ^quxjg$c
^quxjg$c Comment implémenter la technologie de conteneur Docker en Java
Comment implémenter la technologie de conteneur Docker en Java




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



