


Le contexte LLaMA open source alpaga grand modèle est égal à GPT-4, avec un seul changement simple !
Cet article qui vient d'être soumis par Meta AI montre que moins de 1 000 étapes de réglage fin sont nécessaires une fois la fenêtre contextuelle LLaMA passée de 2 000 à 32 000.
Le coût est négligeable par rapport à la pré-formation.

L'expansion de la fenêtre contextuelle signifie que la capacité de « mémoire de travail » de l'IA est augmentée. Plus précisément, elle peut :
Le plus important est que toutes les grandes familles de modèles d'alpaga basées sur LLaMA peuvent adopter cette méthode à faible coût et évoluer collectivement ?
Alpaca est actuellement le modèle de base open source le plus complet et a dérivé de nombreux grands modèles et modèles industriels verticaux entièrement open source disponibles dans le commerce.
Tian Yuandong, l'auteur correspondant du journal, a également partagé avec enthousiasme ce nouveau développement dans son cercle d'amis.
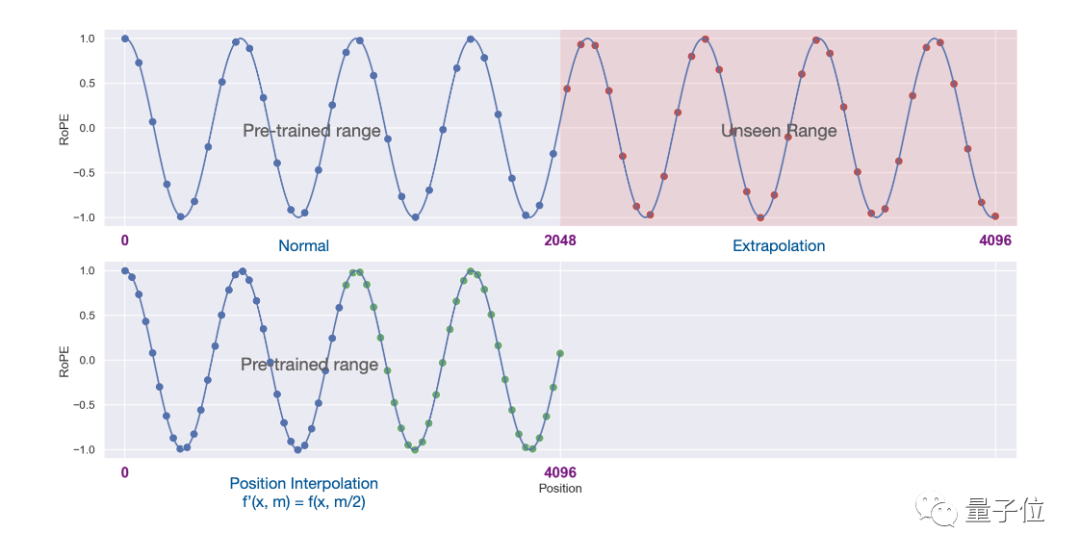
La nouvelle méthode s'appelle Position Interpolation et convient aux grands modèles utilisant RoPE (codage de position de rotation).
RoPE a été proposé par l'équipe de Zhuiyi Technology dès 2021 et est désormais devenu l'une des méthodes de codage de position les plus courantes pour les grands modèles.

Mais utiliser directement l'extrapolation pour étendre la fenêtre contextuelle sous cette architecture détruira complètement le mécanisme d'auto-attention.
Plus précisément, la partie au-delà de la longueur du contexte pré-entraîné fera monter la perplexité du modèle au même niveau qu'un modèle non entraîné.
La nouvelle méthode est modifiée pour réduire linéairement l'indice de position et élargir l'alignement de la plage de l'indice de position avant et arrière et la distance relative.

Il est plus intuitif d'utiliser des images pour exprimer la différence entre les deux.
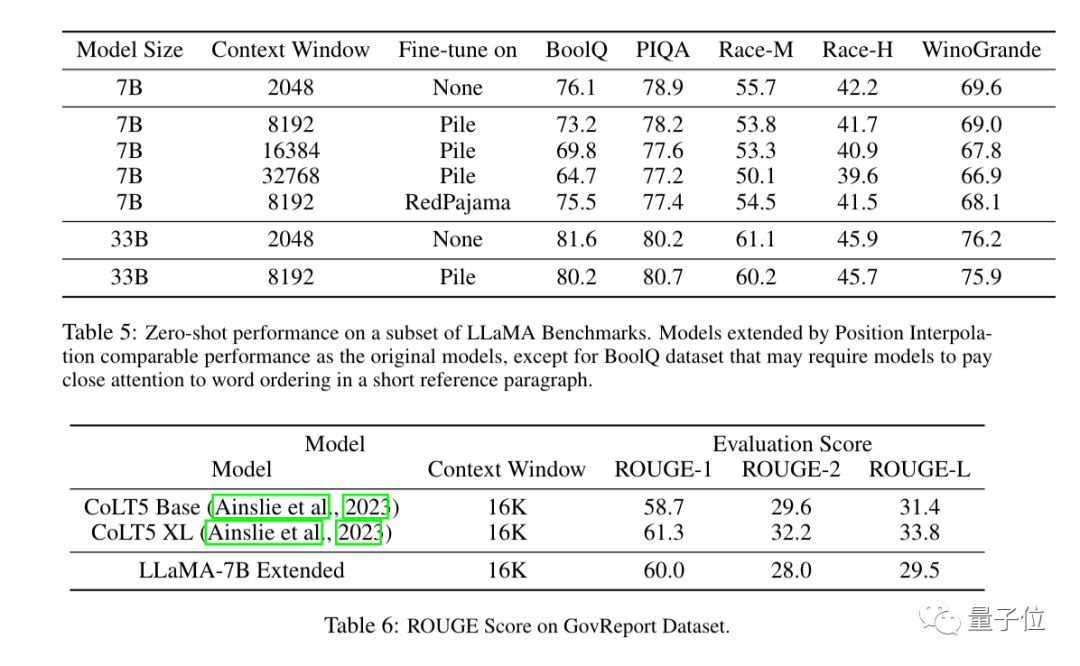
Les résultats expérimentaux montrent que la nouvelle méthode est efficace pour les grands modèles LLaMA du 7B au 65B.
Il n'y a pas de dégradation significative des performances dans la modélisation de langage à séquence longue, la récupération de clé d'accès et la synthèse de documents longs.
En plus des expériences, une preuve détaillée de la nouvelle méthode est également donnée en annexe de l'article.
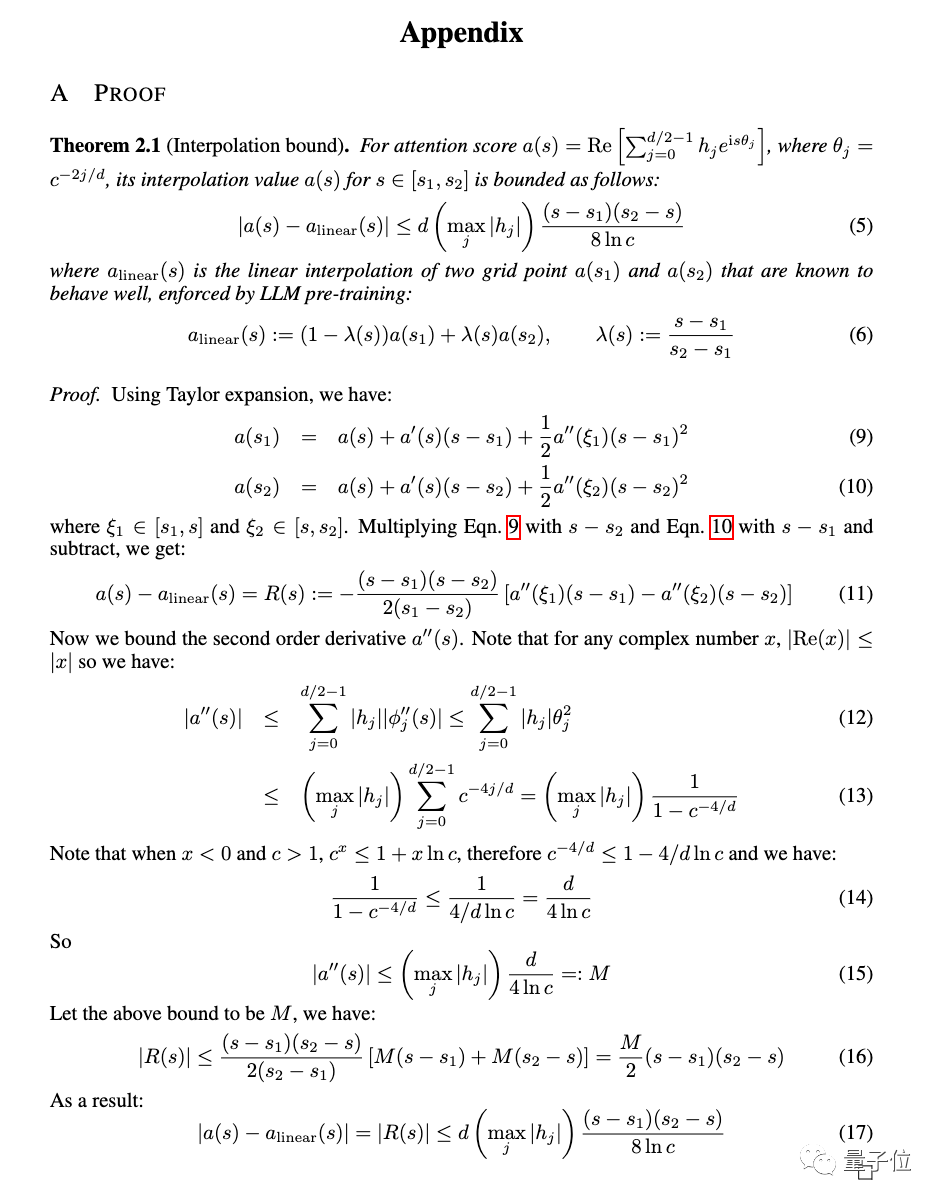
La fenêtre contextuelle constituait autrefois un écart important entre les grands modèles open source et les grands modèles commerciaux.
Par exemple, GPT-3.5 d'OpenAI prend en charge jusqu'à 16 000, GPT-4 prend en charge 32 000 et Claude d'AnthropicAI prend en charge jusqu'à 100 000.
Dans le même temps, de nombreux grands modèles open source tels que LLaMA et Falcon sont toujours bloqués à 2k.
Maintenant, les nouveaux résultats de Meta AI ont directement comblé cet écart.
L'expansion de la fenêtre contextuelle est également l'un des objectifs des recherches récentes sur les grands modèles. En plus des méthodes d'interpolation de position, il existe de nombreuses tentatives pour attirer l'attention de l'industrie.
1. Le développeur kaiokendev a exploré une méthode pour étendre la fenêtre contextuelle de LLaMa à 8k dans un blog technique.
2. Galina Alperovich, responsable de l'apprentissage automatique chez la société de sécurité des données Soveren, a résumé 6 conseils pour élargir la fenêtre contextuelle dans un article.

3. Des équipes de Mila, IBM et d'autres institutions ont également tenté de supprimer complètement le codage positionnel dans Transformer dans un article.伴 Si vous en avez besoin, vous pouvez cliquer sur le lien ci-dessous pour voir ~
Méta-thèse :  Https://m.sbmmt.com/link/0BDF2C1F05365071F0C725D754B96
Https://m.sbmmt.com/link/0BDF2C1F05365071F0C725D754B96
ht TPS:/ /m.sbmmt.com/link/9659078925b57e621eb3f9ef19773ac3
La sauce secrète derrière la fenêtre contextuelle 100K dans les LLM//m.sbmmt.com/link/09a630e07af043e4cae879dd60db1cac
Aucun Papier de codage de positionhttps:/ /m.sbmmt.com/link/fb6c84779f12283a81d739d8f088fc12
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 le démarrage d'Apache a échoué
le démarrage d'Apache a échoué
 utilisation de la fonction memset
utilisation de la fonction memset
 Comment modifier le fichier hosts
Comment modifier le fichier hosts
 Introduction au contenu principal du travail du backend
Introduction au contenu principal du travail du backend
 ASUS x402c
ASUS x402c
 Quelle est la différence entre ibatis et mybatis
Quelle est la différence entre ibatis et mybatis
 Comment aligner les zones de texte en HTML
Comment aligner les zones de texte en HTML
 Analyse coût-efficacité de l'apprentissage de Python, Java et C++
Analyse coût-efficacité de l'apprentissage de Python, Java et C++








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



