


L'IA générative a pris d'assaut la communauté de l'intelligence artificielle. Les particuliers et les entreprises ont commencé à s'intéresser à la création d'applications de conversion modale associées, telles que les images Vincent, les vidéos Vincent, la musique Vincent, etc.
Récemment, plusieurs chercheurs d'institutions de recherche scientifique telles que ServiceNow Research et LIVIA ont essayé de générer des graphiques dans des articles basés sur des descriptions textuelles. À cette fin, ils ont proposé une nouvelle méthode de FigGen, et l’article correspondant a également été inclus en tant que Tiny Paper dans l’ICLR 2023.
 Photos
Photos
Adresse du papier : https://arxiv.org/pdf/2306.00800.pdf
Certaines personnes peuvent se demander : qu'est-ce qui est si difficile à générer les graphiques dans le papier ? En quoi cela aide-t-il la recherche scientifique ?
La génération de graphiques de recherche scientifique aide à diffuser les résultats de la recherche de manière concise et facile à comprendre, et la génération automatique de graphiques peut apporter de nombreux avantages aux chercheurs, tels qu'un gain de temps et d'énergie sans consacrer beaucoup d'efforts à la conception de graphiques à partir de zéro. . De plus, la conception de diagrammes visuellement attrayants et faciles à comprendre peut rendre le document accessible à un plus grand nombre de personnes.
Cependant, la génération de diagrammes est également confrontée à certains défis. Elle doit représenter des relations complexes entre des composants discrets tels que des boîtes, des flèches, du texte, etc. Contrairement à la génération d'images naturelles, les concepts des graphiques papier peuvent avoir des représentations différentes et nécessiter une compréhension fine. Par exemple, la génération d'un graphique de réseau neuronal impliquera un problème mal posé avec une variance élevée.
Par conséquent, les chercheurs de cet article ont formé un modèle génératif sur un ensemble de données de paires de diagrammes papier pour capturer la relation entre les composants du diagramme et le texte correspondant dans l'article. Cela nécessite de gérer des longueurs variables et des descriptions de texte très techniques, différents styles de graphiques, formats d'image et problèmes de police, de taille et d'orientation du rendu du texte.
Au cours du processus de mise en œuvre spécifique, les chercheurs se sont inspirés des résultats récents de la conversion texte-image et ont utilisé le modèle de diffusion pour générer des graphiques. Ils ont proposé un modèle de diffusion potentiel pour générer des graphiques de recherche scientifique à partir de descriptions textuelles - FigGen.
Quelles sont les caractéristiques uniques de ce modèle de diffusion ? Passons aux détails.
Les chercheurs ont formé un modèle de diffusion latente à partir de zéro.
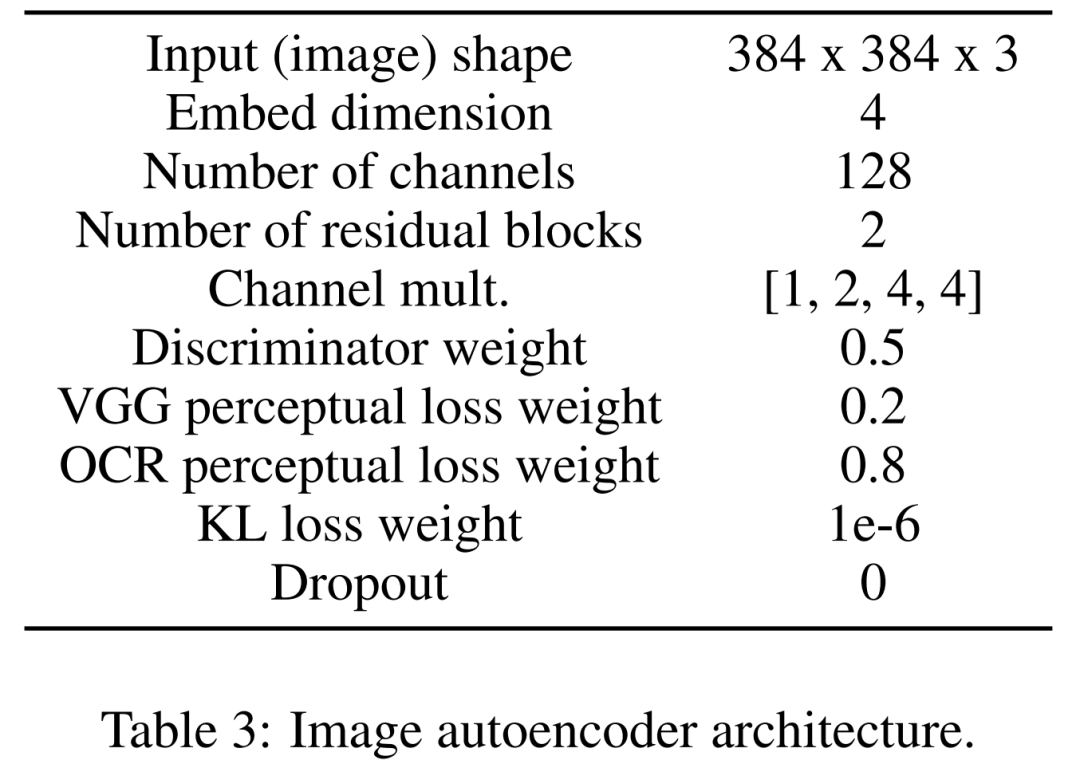
Apprenez d'abord un encodeur automatique d'images pour mapper des images dans des représentations latentes compressées. L'encodeur d'image utilise la perte KL et la perte de perception OCR. L'encodeur de texte utilisé pour le conditionnement est appris de bout en bout lors de l'apprentissage de ce modèle de diffusion. Le tableau 3 ci-dessous montre les paramètres détaillés de l'architecture de l'encodeur automatique d'image.
Le modèle de diffusion interagit ensuite directement dans l'espace latent, effectuant une planification directe des données corrompues tout en apprenant à utiliser le débruitage conditionnel temporel et textuel U-Net pour récupérer le processus.
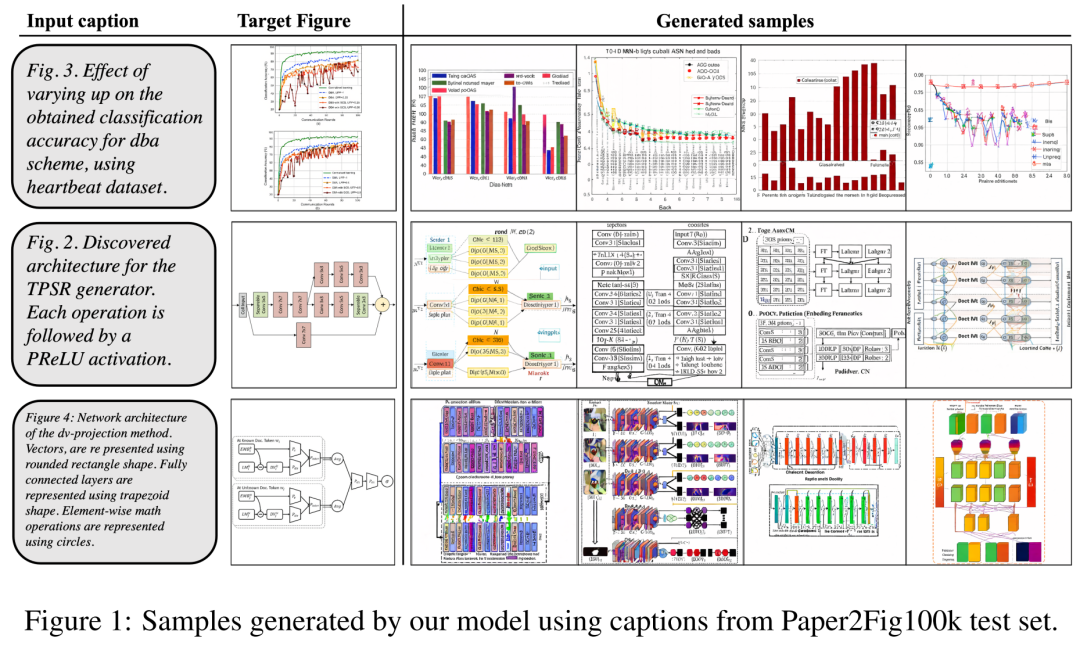
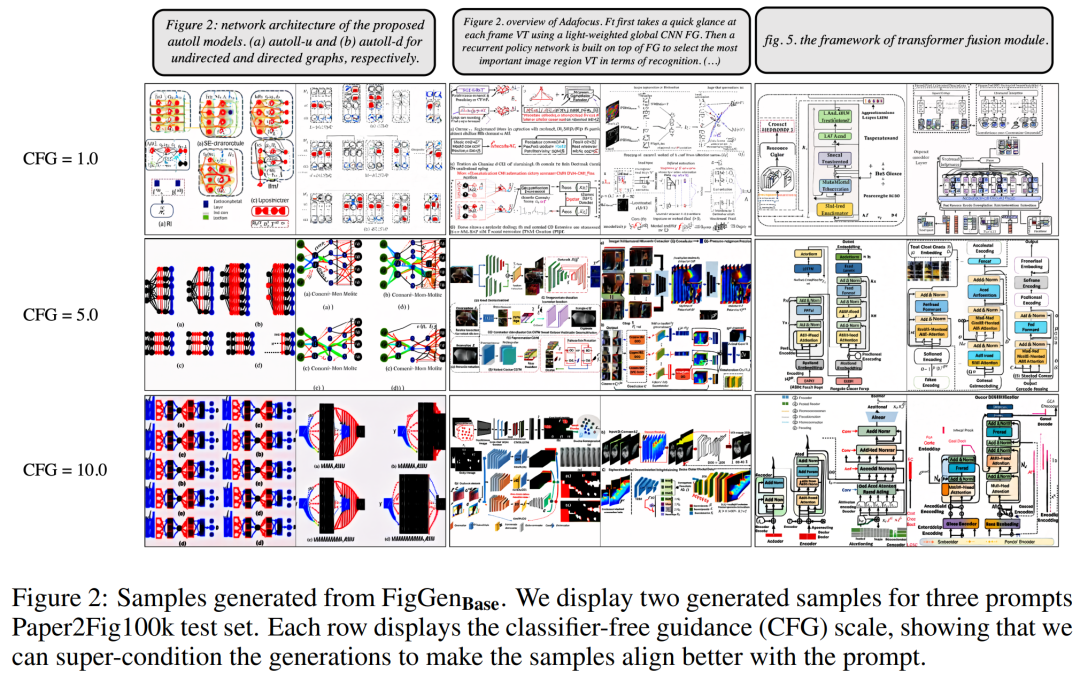
En ce qui concerne l'ensemble de données, les chercheurs ont utilisé Paper2Fig100k, qui se compose de paires graphique-texte dans l'article et contient 81 194 échantillons d'apprentissage et 21 259 échantillons de validation. La figure 1 ci-dessous est un exemple de diagramme généré à l'aide de descriptions textuelles dans l'ensemble de test Paper2Fig100k.
Détails du modèle
Le premier est l'encodeur d'image. Dans la première étape, l'encodeur automatique d'image apprend un mappage de l'espace des pixels à la représentation latente compressée, ce qui accélère la formation du modèle de diffusion. L'encodeur d'image doit également apprendre à mapper l'image sous-jacente sur l'espace des pixels sans perdre les détails importants du diagramme (tels que la qualité du rendu du texte).
À cette fin, les chercheurs ont défini un codec convolutionnel avec un goulot d'étranglement qui sous-échantillonne l'image au facteur f=8. L'encodeur est formé pour minimiser la perte KL, la perte compatible VGG et la perte compatible OCR avec la distribution gaussienne.
Le deuxième est l'encodeur de texte. Les chercheurs ont découvert que les encodeurs de texte à usage général ne conviennent pas aux tâches de génération de graphiques. Par conséquent, ils définissent un transformateur Bert formé à partir de zéro dans le processus de diffusion, qui utilise un canal d'intégration de taille 512, qui est également la taille d'intégration qui régule la couche d'attention croisée d'U-Net. Les chercheurs ont également étudié les changements dans le nombre de couches de transformateur selon différents réglages (8, 32 et 128).
Le dernier est le modèle de diffusion latente. Le tableau 2 ci-dessous montre l'architecture réseau d'U-Net. Nous effectuons le processus de diffusion sur une représentation latente perceptuellement équivalente de l'image, où la taille d'entrée de l'image est compressée à 64x64x4, ce qui rend le modèle de diffusion plus rapide. Ils ont défini 1 000 étapes de diffusion et une planification linéaire du bruit. Pour entraîner l'encodeur automatique d'image, les chercheurs ont utilisé un optimiseur Adam avec une taille de lot effective de 4 échantillons et un taux d'apprentissage de 4,5e −6, au cours duquel quatre cartes graphiques NVIDIA V100 de 12 Go ont été utilisées. Pour obtenir la stabilité de l'entraînement, ils réchauffent le modèle en 50 000 itérations sans utiliser le discriminateur.
Pour entraîner le modèle de diffusion latente, les chercheurs ont également utilisé l'optimiseur Adam, qui a une taille de lot effective de 32 et un taux d'apprentissage de 1e−4. Lors de la formation du modèle sur l'ensemble de données Paper2Fig100k, ils ont utilisé huit cartes graphiques NVIDIA A100 de 80 Go. 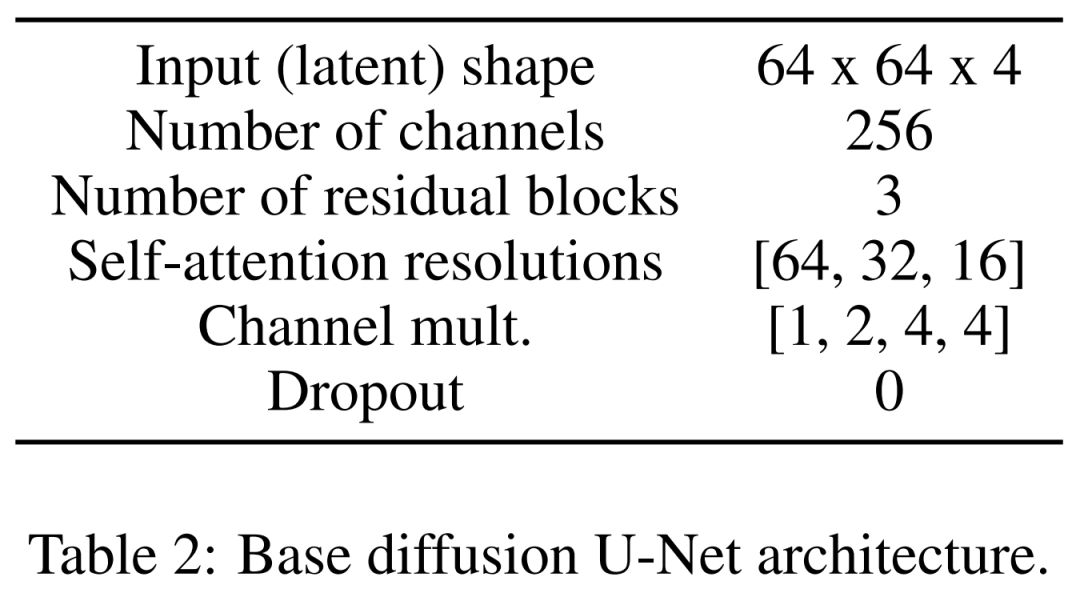
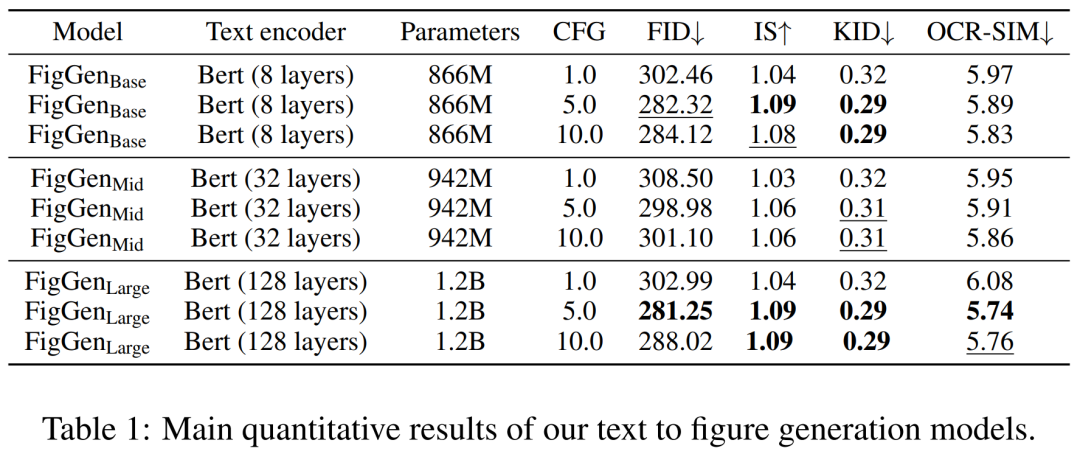
Résultats expérimentauxAu cours du processus de génération, les chercheurs ont adopté un échantillonneur DDIM avec 200 étapes et ont généré 12 000 échantillons pour chaque modèle afin de calculer FID, IS, KID et OCR-SIM1. Utilisation robuste du guidage sans classificateur (CFG) pour tester l'hyperconditionnement.
Le tableau 1 ci-dessous montre les résultats de différents encodeurs de texte. On peut voir que les gros encodeurs de texte produisent les meilleurs résultats qualitatifs et que la génération de conditions peut être améliorée en augmentant la taille du CFG. Bien que les échantillons qualitatifs ne soient pas de qualité suffisante pour résoudre le problème, FigGen a saisi la relation entre texte et images.
Photos
La figure 3 ci-dessous montre d'autres exemples de génération de FigGen. Faites attention à la variation de longueur entre les échantillons, ainsi qu'au niveau technique de la description du texte, qui affecteront étroitement la difficulté du modèle à générer correctement des images compréhensibles.
 Photos
Photos
Cependant, les chercheurs ont également admis que même si ces graphiques générés ne peuvent pas fournir une aide pratique aux auteurs de l'article, ils restent une direction prometteuse à explorer.
 Veuillez vous référer à l'article original pour plus de détails sur la recherche.
Veuillez vous référer à l'article original pour plus de détails sur la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que dois-je faire si mon iPad ne peut pas être chargé ?
Que dois-je faire si mon iPad ne peut pas être chargé ?
 Comment s'inscrire à Alipay d'entreprise
Comment s'inscrire à Alipay d'entreprise
 Que dois-je faire si j'oublie mon mot de passe haut débit ?
Que dois-je faire si j'oublie mon mot de passe haut débit ?
 Tutoriel pour les nouveaux arrivants à Ouyi
Tutoriel pour les nouveaux arrivants à Ouyi
 Comment utiliser la fonction max
Comment utiliser la fonction max
 RVB en RVB hexadécimal
RVB en RVB hexadécimal
 Comment résoudre l'attente d'un appareil
Comment résoudre l'attente d'un appareil
 Quelle est la différence entre xls et xlsx
Quelle est la différence entre xls et xlsx








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



