


Comme le dit le proverbe, les mots sont comme des visages et les mots sont comme des personnes. Par rapport aux polices imprimées rigides, l’écriture manuscrite peut mieux refléter les caractéristiques personnelles de l’écrivain. Je pense que beaucoup de gens ont imaginé avoir leur propre jeu de polices d'écriture manuscrite et les utiliser dans des logiciels sociaux pour mieux montrer leur style personnel.
Cependant, contrairement aux lettres anglaises, le nombre de caractères chinois est extrêmement important et il est très coûteux de créer votre propre police exclusive. Par exemple, le nouveau jeu de caractères chinois standard national GB18030-2022 contient plus de 80 000 caractères chinois. Il y a des rapports selon lesquels un blogueur sur un site Web de vidéos a passé 18 heures à écrire plus de 7 000 caractères chinois, en utilisant 13 stylos pendant le processus, et ses mains étaient engourdies à cause de l'écriture !
Les questions ci-dessus ont incité l'auteur de l'article à y réfléchir. Peut-il concevoir un modèle de génération automatique de texte pour aider à résoudre le problème du coût élevé de création de polices exclusives ? Afin de résoudre ce problème, les chercheurs ont imaginé une IA capable d'imiter l'écriture manuscrite. Seul l'utilisateur doit fournir un petit nombre d'échantillons d'écriture manuscrite (environ une douzaine) pour extraire le style d'écriture contenu dans l'écriture manuscrite (comme la taille de l'écriture manuscrite). caractères, le degré d'inclinaison, le degré d'inclinaison, etc.) Rapport d'aspect, longueur de trait et courbure, etc.), et copiez le style pour synthétiser plus de texte, synthétisant ainsi efficacement un ensemble complet de polices d'écriture manuscrite pour les utilisateurs.

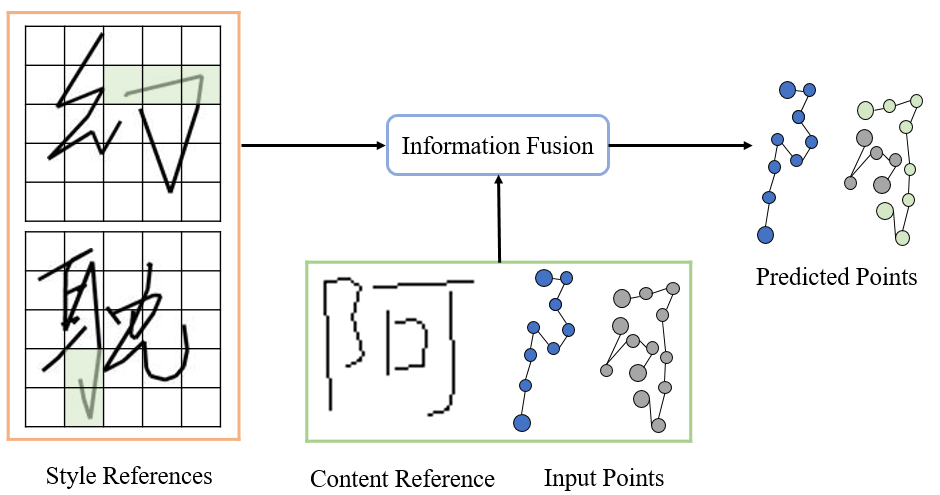
En outre, l'auteur de l'article a fait les réflexions suivantes sur les modalités d'entrée et de sortie du modèle du point de vue de la valeur de l'application et de l'expérience utilisateur : 1. Prise en compte de la police en ligne du La modalité de séquence (écritures manuscrites en ligne) contient des informations plus riches que les écritures manuscrites hors ligne en mode image (positions détaillées et ordre d'écriture des points de suivi, comme le montre la figure ci-dessous). Le réglage du mode de sortie du modèle sur texte en ligne aura une gamme d'applications plus large). perspectives, telles que l’écriture robotisée et l’enseignement de la calligraphie. 2. Dans la vie quotidienne, il est plus pratique pour les gens d'utiliser des téléphones portables pour prendre des photos afin d'obtenir du texte hors ligne que d'obtenir du texte en ligne via des appareils de collecte tels que des tablettes et des stylets tactiles. Par conséquent, définir le mode de saisie du modèle généré sur texte hors ligne le rendra plus pratique à utiliser pour les utilisateurs !
En résumé, l'objectif de recherche de cet article est de proposer une méthode de génération d'écriture manuscrite stylisée en ligne. Ce modèle peut non seulement copier le style d'écriture contenu dans le texte hors ligne fourni par l'utilisateur, mais également générer en ligne une écriture manuscrite dont le contenu est contrôlable en fonction des besoins de l'utilisateur.

Afin d'atteindre les objectifs ci-dessus, les chercheurs ont analysé deux questions clés : 1. Étant donné que les utilisateurs ne peuvent fournir qu'un petit nombre d'échantillons de caractères, le style d'écriture unique de l'utilisateur peut-il être appris uniquement à partir de ce petit nombre d'échantillons de référence. ? En d’autres termes, est-il possible de copier le style d’écriture d’un utilisateur sur la base d’un petit nombre d’échantillons de référence ? 2. L'objectif de recherche de cet article est non seulement de garantir que le style du texte généré est contrôlable, mais également que le contenu est également contrôlable. Par conséquent, après avoir appris le style d'écriture de l'utilisateur, comment combiner efficacement le style avec le contenu du texte pour générer une écriture manuscrite qui répond aux attentes de l'utilisateur ? Voyons ensuite comment la méthode SDT (style détangled Transformer) proposée dans ce CVPR 2023 résout ces deux problèmes.
Motivation de la recherche Les chercheurs ont découvert qu'il existe généralement deux styles d'écriture dans l'écriture personnelle : 1. Il existe un point commun stylistique global dans l'écriture manuscrite du même écrivain, et chaque caractère semble similaire. Le degré de l'inclinaison et le rapport hauteur/largeur sont différents et différents écrivains ont des points communs stylistiques différents. Parce que cette caractéristique peut être utilisée pour distinguer différents écrivains, les chercheurs l'appellent le style de l'écrivain. 2. En plus des points communs stylistiques globaux, il existe des incohérences stylistiques détaillées entre les différents personnages du même écrivain. Par exemple, pour les deux caractères « 黑 » et « 杰 », ils ont le même radical d'eau à quatre points dans la structure des caractères, mais il existe de légères différences d'écriture dans l'écriture de ce radical dans différents caractères, ce qui se reflète dans la longueur. des traits, de la position et de la courbure. Les chercheurs appellent ce motif de style subtil dans les glyphes le style des glyphes. Inspiré par les observations ci-dessus, SDT vise à dissocier le style d'écriture et de glyphe de l'écriture manuscrite personnelle, dans l'espoir d'améliorer la capacité à imiter le style d'écriture manuscrite de l'utilisateur.

Après avoir appris les informations de style, contrairement aux méthodes précédentes de génération de texte manuscrit qui fusionnent simplement les fonctionnalités de style et de contenu, SDT utilise les fonctionnalités de contenu comme vecteurs de requête pour capturer de manière adaptative les informations de style, réalisant ainsi une intégration efficace du style et du contenu pour générer de l'écriture manuscrite. qui répond aux attentes des utilisateurs.
Cadre de méthode Le cadre global de SDT est présenté dans la figure ci-dessous, comprenant trois parties : un encodeur de style à double branche, un encodeur de contenu et un décodeur de transformateur. Tout d’abord, cet article propose deux objectifs d’apprentissage contrastifs complémentaires pour guider respectivement la branche écrivain et la branche glyphe de l’encodeur de style pour apprendre l’extraction de style correspondante. Ensuite, SDT utilise le mécanisme d'attention du transformateur (attention multi-têtes) pour fusionner dynamiquement les caractéristiques de style et les caractéristiques de contenu extraites par l'encodeur de contenu, et synthétiser progressivement le texte manuscrit en ligne.
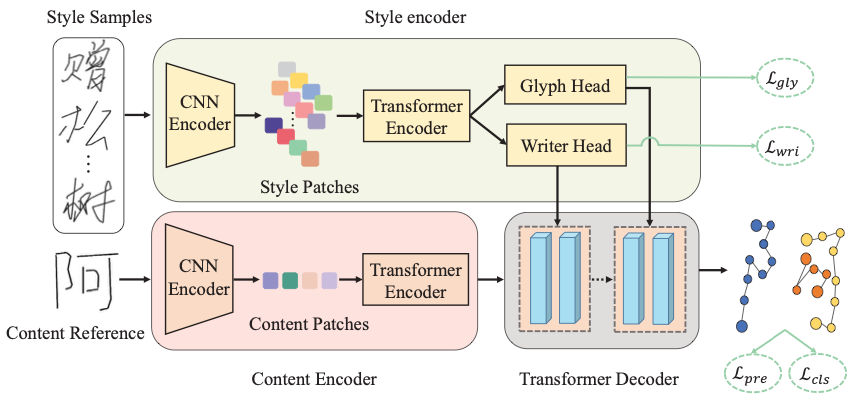
(a) Apprentissage contrastif du style d'écrivain SDT propose un objectif d'apprentissage contrastif supervisé (WriterNCE) pour l'extraction du style d'écrivain, qui regroupe des échantillons de personnages appartenant au même écrivain. Ensemble, poussant transmettre des échantillons d’écriture manuscrite appartenant à différents écrivains amène explicitement les écrivains à se diversifier et à se concentrer sur les points communs stylistiques de l’écriture individuelle.
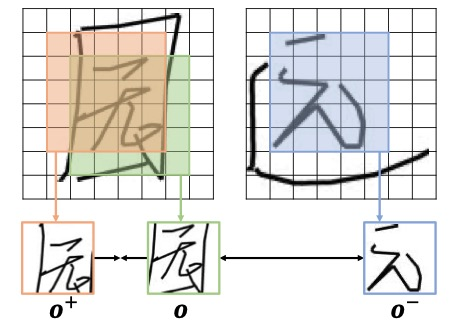
(b) Apprentissage contrastif des styles de glyphes Afin d'apprendre des styles de glyphes plus détaillés, SDT propose un objectif d'apprentissage contrastif non supervisé (GlyphNCE), qui est utilisé pour maximiser les informations mutuelles entre différentes vues du même caractère et encourager La branche glyphe se concentre sur l'apprentissage de modèles détaillés dans les caractères. Plus précisément, comme le montre la figure ci-dessous, effectuez d'abord deux échantillons indépendants du même caractère manuscrit pour obtenir une paire d'échantillons positifs
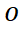
et
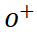
contenant des informations détaillées sur l'AVC, puis sélectionnez-les. à partir d'autres personnages L'échantillonnage donne des échantillons négatifs
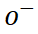
. Chaque fois qu'un échantillon est prélevé, un petit nombre de blocs d'échantillons sont sélectionnés au hasard comme une nouvelle perspective contenant les détails de l'échantillon d'origine. L'échantillonnage des blocs d'échantillon suit une distribution uniforme pour éviter le suréchantillonnage de certaines zones de caractères. Afin de mieux guider la branche de glyphe, le processus d'échantillonnage agit directement sur la séquence de caractéristiques sortie par la branche de glyphe.
(c) Stratégie de fusion du style et des informations de contenu Après avoir obtenu les deux fonctionnalités de style, comment les intégrer efficacement avec l'encodage de contenu appris par l'encodeur de contenu ? Afin de résoudre ce problème, à tout instant de décodage t, SDT considère les caractéristiques du contenu comme le point initial, puis combine les points de trajectoire générés avant les instants q et t pour former un nouveau contexte de contenu
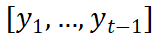
. Ensuite, le contexte de contenu est traité comme un vecteur de requête et les informations de style comme des vecteurs de clé et de valeur. Avec l'intégration du mécanisme d'attention croisée, le contexte du contenu et les deux informations de style sont tour à tour agrégés dynamiquement.
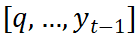 Expériences
Expériences
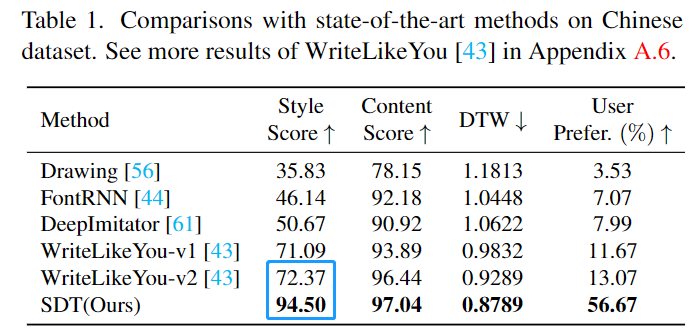
Évaluation quantitative
SDT a obtenu les meilleures performances sur les ensembles de données chinois, japonais, indiens et anglais, en particulier sur l'indice de score de style, par rapport à l'avant la méthode SOTA, SDT a fait de grandes percées.
Évaluation qualitative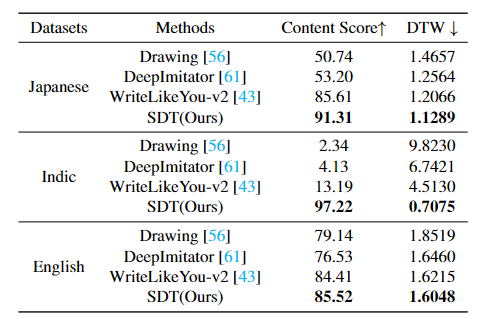
Par rapport aux méthodes précédentes, les caractères manuscrits générés par SDT peuvent éviter l'effondrement des caractères. Il peut également copier le le style d'écriture de l'utilisateur est très bon. Grâce à l'apprentissage du style de glyphe, SDT peut également faire du bon travail en générant des détails de trait de caractères.
SDT fonctionne également bien dans d'autres langues. Surtout en termes de génération de texte indien, les méthodes traditionnelles existantes peuvent facilement générer des caractères réduits, mais notre SDT peut toujours maintenir l'exactitude du contenu des caractères.
L'impact des différents modules sur les performances de l'algorithme
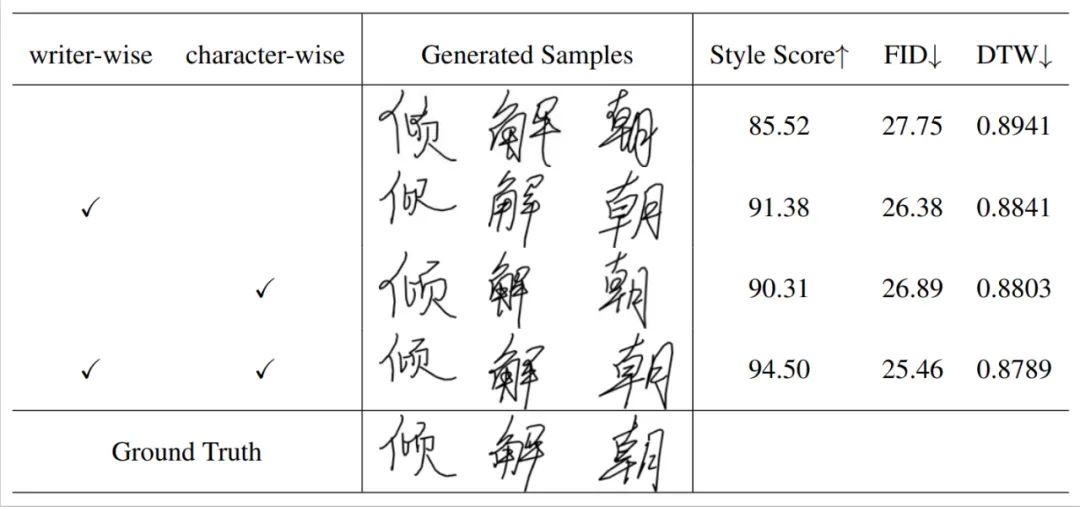
Analyse visuelle des deux styles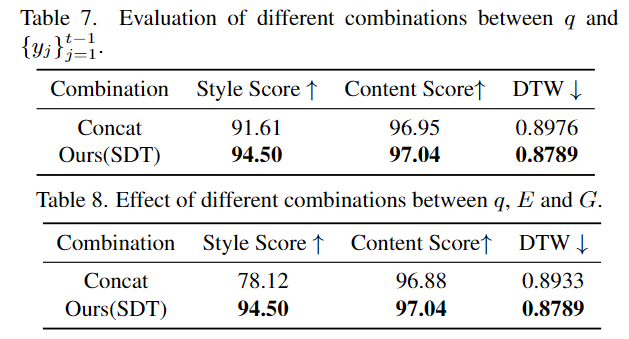
Tout le monde peut créer ses propres polices exclusives grâce à l'IA d'écriture manuscrite et mieux s'exprimer sur les plateformes sociales ! Pour l'avenir
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 commande de capture de paquets Linux
commande de capture de paquets Linux
 Mot de passe par défaut du routeur
Mot de passe par défaut du routeur
 heure du système Linux
heure du système Linux
 Introduction aux composants Laravel
Introduction aux composants Laravel
 Comment utiliser la largeur de marge
Comment utiliser la largeur de marge
 Comment ignorer la connexion réseau lors de l'installation de Win11
Comment ignorer la connexion réseau lors de l'installation de Win11
 tu protèges le pilote
tu protèges le pilote
 Comment résoudre le problème selon lequel le code js ne peut pas s'exécuter après le formatage
Comment résoudre le problème selon lequel le code js ne peut pas s'exécuter après le formatage








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



