


Table des matières :
Adresse papier : https://www.nature.com/articles/s41586-023-06004-9
Recommandation :
L'IA réécrit l'algorithme de tri, 70 % plus rapidement : DeepMind AlphaDev révolutionne les bases informatiques et la bibliothèque est mise à jour des milliards de fois par jour
Paper. 2 : Vidéo-LLaMA : Un modèle de langage audiovisuel adapté aux instructions pour la compréhension de la vidéo
Auteur : Hang Zhang et al
Adresse papier : https://arxiv.org/abs/ 2306.02858
Recommandé : Ajoutez des capacités audiovisuelles complètes aux grands modèles de langage, DAMO Academy open source Video-LLaMA.
Papier 3 : Génération de scènes naturelles 3D à partir de patchs à partir d'un seul exemple
 Auteur : Weiyu Li et al avec l'Université du Shandong et les chercheurs du Tencent AI Lab ont proposé la première méthode pour générer diverses scènes 3D de haute qualité sans formation basée sur des scènes à échantillon unique.
Auteur : Weiyu Li et al avec l'Université du Shandong et les chercheurs du Tencent AI Lab ont proposé la première méthode pour générer diverses scènes 3D de haute qualité sans formation basée sur des scènes à échantillon unique.
Auteur : Yuan Yuan et al
Adresse de l'article : https://arxiv.org/abs/2305.12403
Résumé :
Le Centre de recherche en sciences urbaines et en informatique du Département d'ingénierie électronique de l'Université Tsinghua a récemment proposé le processus de point de diffusion spatio-temporelle, qui dépasse les limites des méthodes existantes telles que les formes probabilistes restreintes et les coûts d'échantillonnage élevés pour la modélisation. processus ponctuels spatio-temporels et permet d'obtenir un modèle de processus ponctuel spatio-temporel flexible, efficace et facile à calculer peut être largement utilisé dans la modélisation et la prévision d'événements spatio-temporels tels que les catastrophes naturelles urbaines, les urgences et les activités des résidents, et promeut le développement intelligent de la planification et de la gestion urbaine. Le tableau suivant montre les avantages du DSTPP par rapport aux solutions de processus ponctuels existantes.
Auteur : Tim Dettmers et al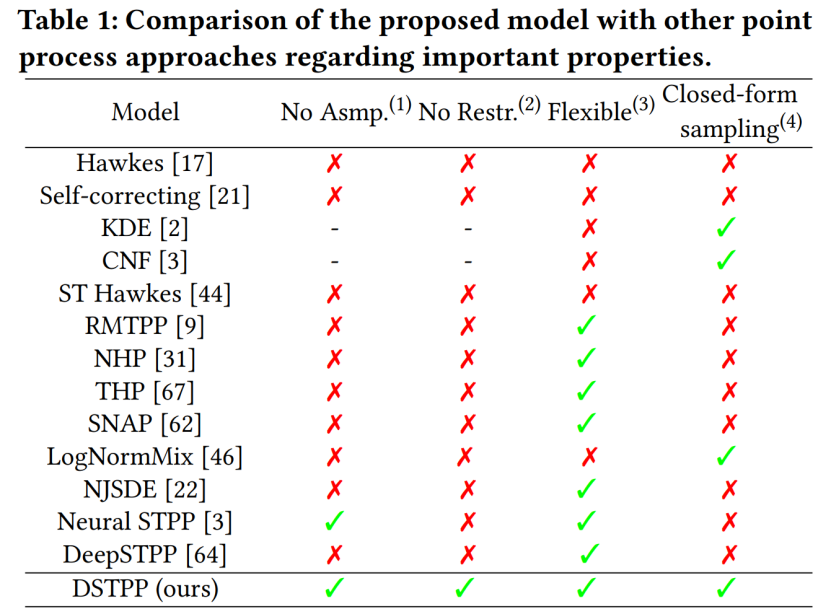
Adresse de l'article : https://arxiv . org /pdf/2306.03078.pdf
Résumé :
Afin de résoudre le problème de précision, des chercheurs de l'Université de Washington, de l'ETH Zurich et d'autres institutions ont proposé un nouveau format de compression et une technologie de quantification SpQR (Sparse-Quantitative représentation), obtenant pour la première fois une compression quasiment sans perte de LLM à toutes les échelles du modèle tout en atteignant des niveaux de compression similaires à ceux des méthodes précédentes."Intégrez un grand modèle de 33 milliards de paramètres dans" un seul GPU grand public, accélérant de 15 % sans sacrifier les performances.
Papier 6 : UniControl : Un modèle de diffusion unifié pour la génération visuelle contrôlable dans la nature
Résumé : Dans cet article, Salesforce AI, Northeastern , Université de Stanford Les chercheurs ont proposé un adaptateur de type MOE et un HyperNet prenant en charge les tâches pour réaliser la capacité de génération de conditions multimodales dans UniControl. UniControl est formé sur neuf tâches C2I différentes, démontrant de solides capacités de génération visuelle et des capacités de généralisation sans tir. Le modèle UniControl se compose de plusieurs tâches de pré-formation et de tâches sans tir.

Recommandé : Le modèle unifié pour la génération d'images contrôlables multimodales est ici, et les paramètres du modèle et le code d'inférence sont tous open source.
Papier 7 : FrugalGPT : Comment utiliser de grands modèles de langage tout en réduisant les coûts et en améliorant les performances
Résumé : L'équilibre entre coût et précision est un facteur clé dans la prise de décision, en particulier lors de l'adoption de nouvelles technologies. Comment utiliser efficacement le LLM est un défi clé pour les praticiens : si la tâche est relativement simple, alors l'agrégation de plusieurs réponses de GPT-J (qui est 30 fois plus petite que GPT-3) peut obtenir des performances similaires à celles de GPT-3, parvenir à un compromis en termes de coûts et d’environnement. Cependant, sur des tâches plus difficiles, les performances de GPT-J peuvent se dégrader considérablement. Par conséquent, de nouvelles approches sont nécessaires pour utiliser le LLM de manière rentable.
Une étude récente a tenté de proposer une solution à ce problème de coût. Les chercheurs ont montré expérimentalement que FrugalGPT peut rivaliser avec les performances du meilleur LLM individuel (comme le GPT-4), avec une réduction des coûts allant jusqu'à 98 %. , ou Améliorer la précision du meilleur LLM individuel de 4 % au même coût. Cette étude discute de trois stratégies de réduction des coûts, à savoir l'adaptation rapide, l'approximation LLM et la cascade LLM.
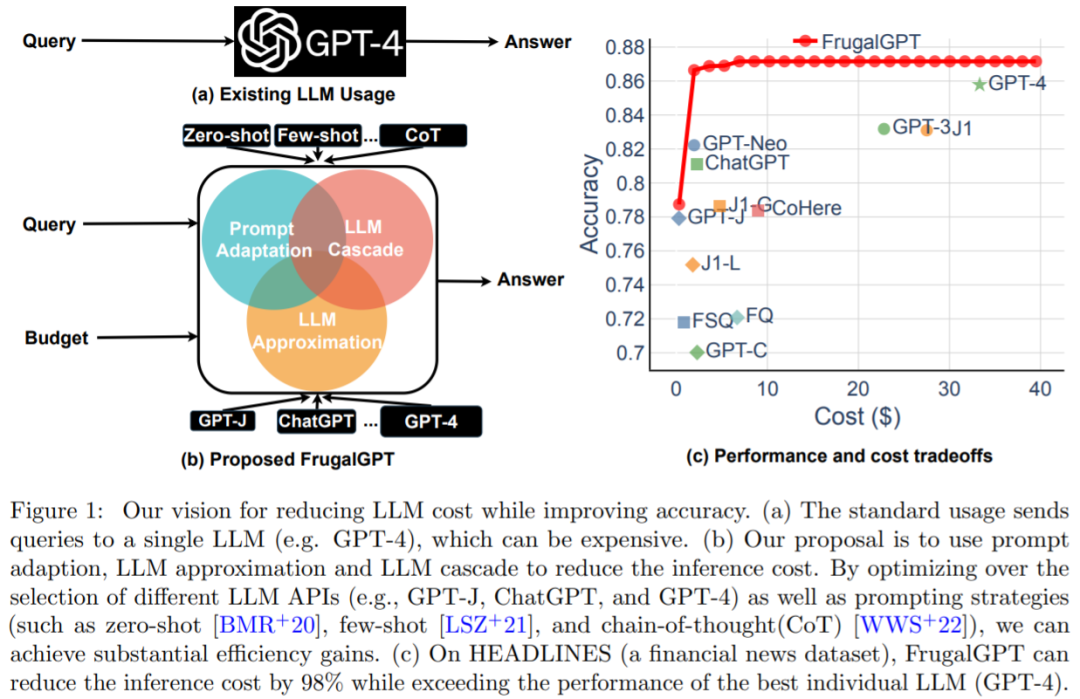
Recommandé : Remplacement de l'API GPT-4 ? Les performances sont comparables et le coût est réduit de 98 %. Stanford a proposé FrugalGPT, mais la recherche était controversée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 compression audio
compression audio
 Plateforme nationale de monnaie numérique
Plateforme nationale de monnaie numérique
 niveau d'isolement des transactions MySQL
niveau d'isolement des transactions MySQL
 Quelles sont les bibliothèques tierces couramment utilisées en PHP ?
Quelles sont les bibliothèques tierces couramment utilisées en PHP ?
 Le rôle du Serverlet en Java
Le rôle du Serverlet en Java
 Algorithme du complément négatif
Algorithme du complément négatif
 Comment résoudre le problème selon lequel le code js ne peut pas s'exécuter après le formatage
Comment résoudre le problème selon lequel le code js ne peut pas s'exécuter après le formatage
 Qu'est-ce qui vaut le plus la peine d'être appris, le langage C ou Python ?
Qu'est-ce qui vaut le plus la peine d'être appris, le langage C ou Python ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



