


Selon les informations du 8 juin, le grand modèle de langage multimodal national TigerBot a été officiellement publié récemment, comprenant deux versions de 7 milliards de paramètres et 180 milliards de paramètres. Il est désormais open source sur GitHub.
▲ Source de l'image Page GitHub de TigerBot
Il est rapporté que les innovations apportées par TigerBot résident principalement dans :
De plus, ce modèle a également apporté des optimisations plus adaptées du tokenizer à l'algorithme d'entraînement pour la distribution plus irrégulière de la langue chinoise.
Le chercheur Chen Ye a déclaré sur le site officiel de Hubo Technology : « Ce modèle peut rapidement comprendre le type de questions que les humains posent en utilisant seulement un petit nombre de paramètres. Selon l'évaluation automatique de l'article OpenAI InstructGPT sur l'ensemble de données publiques PNL , TigerBot-7B a atteint 96% des performances globales du modèle de même taille d'OpenAI. model", le code open source comprend un code de formation et d'inférence de base, un code de quantification et d'inférence pour le modèle 180B d'inférence à double carte. Les données comprennent 100 Go de données de pré-entraînement et 1 Go ou 1 million de données pour un réglage fin supervisé.
Les amis de l'IT House peuvent 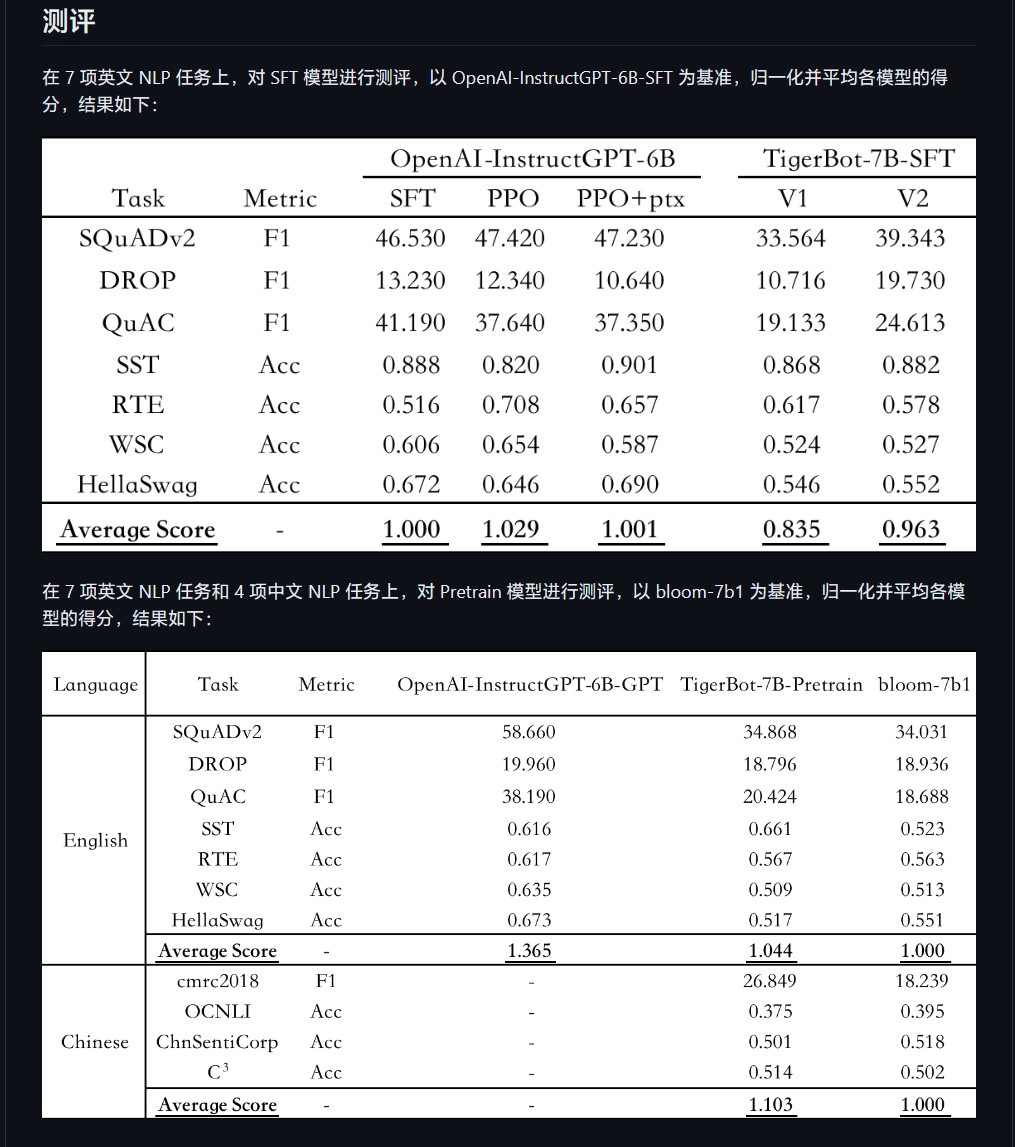 trouver les projets open source de GitHub ici
trouver les projets open source de GitHub ici
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



