


La vidéo joue un rôle de plus en plus important dans la culture des médias sociaux et Internet d'aujourd'hui. Douyin, Kuaishou, Bilibili, etc. sont devenus des plateformes populaires pour des centaines de millions d'utilisateurs. Les utilisateurs partagent leurs moments de vie, leurs œuvres créatives, leurs moments intéressants et d'autres contenus autour de vidéos pour interagir et communiquer avec les autres.
Récemment, de grands modèles de langage ont démontré des capacités impressionnantes. Peut-on équiper les grands modèles d’« yeux » et d’« oreilles » pour qu’ils puissent comprendre les vidéos et interagir avec les utilisateurs ?
Partant de ce problème, des chercheurs de la DAMO Academy ont proposé Video-LLaMA, un grand modèle doté de capacités audiovisuelles complètes. Video-LLaMA peut percevoir et comprendre les signaux vidéo et audio dans les vidéos, et peut comprendre les instructions de saisie de l'utilisateur pour effectuer une série de tâches complexes basées sur l'audio et la vidéo, telles que la description audio/vidéo, l'écriture, les questions et réponses, etc. Actuellement, les articles, les codes et les démos interactives sont tous ouverts. De plus, sur la page d'accueil du projet Video-LLaMA, l'équipe de recherche propose également une version chinoise du modèle pour rendre l'expérience des utilisateurs chinois plus fluide.

Video-LLaMA adopte des principes de conception modulaire pour mapper les informations modales visuelles et audio de la vidéo à l'espace d'entrée du grand modèle de langage afin d'obtenir la capacité de suivre des instructions intermodales. Contrairement aux recherches précédentes sur de grands modèles (MiNIGPT4, LLaVA) axées sur la compréhension des images statiques, Video-LLaMA est confrontée à deux défis en matière de compréhension vidéo : capturer les changements dynamiques de scène dans la vision et intégrer les signaux audiovisuels.
Pour capturer les changements de scène dynamiques dans les vidéos, Video-LLaMA introduit une branche de langage visuel enfichable. Cette branche utilise d'abord l'encodeur d'image pré-entraîné dans BLIP-2 pour obtenir les caractéristiques individuelles de chaque image d'image, puis la combine avec l'intégration de position d'image correspondante. Toutes les caractéristiques de l'image sont envoyées à Video Q-Former et Video Q. -Former regroupera les représentations d'images au niveau de l'image et générera des représentations vidéo synthétiques de longueur fixe. Enfin, une couche linéaire est utilisée pour aligner la représentation vidéo sur l'espace d'intégration du grand modèle de langage.
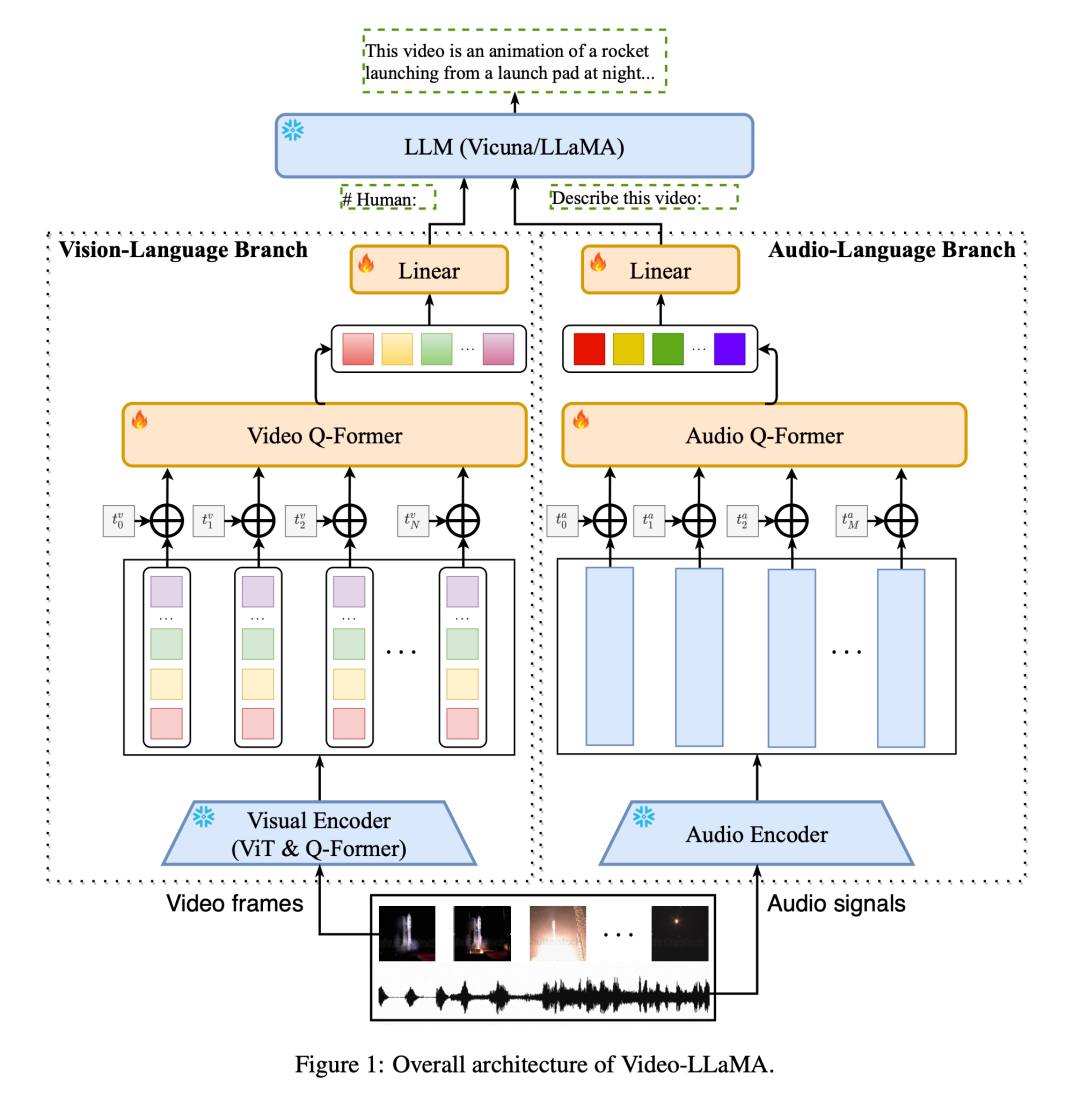
Quant aux signaux sonores dans la vidéo, Video-LLaMA utilise la branche audio-langage pour le traitement. Tout d'abord, plusieurs clips audio de deux secondes sont uniformément échantillonnés à partir de la vidéo originale et chaque clip est converti en un spectrogramme Mel à 128 dimensions. Ensuite, le puissant ImageBind est utilisé comme encodeur audio pour extraire les caractéristiques de chaque clip audio individuellement. Après avoir ajouté des intégrations positionnelles apprenables, Audio Q-Former regroupe les fonctionnalités de segment dans leur ensemble et génère des fonctionnalités audio de longueur fixe. Semblable à la branche du langage visuel, une couche linéaire est finalement utilisée pour aligner la représentation audio sur l'espace d'intégration du grand modèle de langage.
Afin de réduire les coûts de formation, Video-LLaMA fige l'encodeur image/audio pré-entraîné et met à jour uniquement les paramètres suivants dans les branches visuelles et audio : Vidéo/Audio Q-Former, couche d'encodage positionnel et couche linéaire ( Comme le montre la figure 1).
Pour apprendre la relation d'alignement entre la vision et le texte, les auteurs ont d'abord pré-entraîné la branche vision à l'aide d'un ensemble de données vidéo-texte à grande échelle (WebVid-2M) et d'un ensemble de données image-texte (CC-595K). Ensuite, les auteurs ont utilisé des ensembles de données de commandes d'image de MiniGPT-4, LLaVA et des ensembles de données de commandes vidéo de Video-Chat pour affiner afin d'obtenir de meilleures capacités de suivi de commandes intermodales.
En ce qui concerne l'apprentissage des relations d'alignement audio-texte, en raison du manque de données audio-texte à grande échelle et de haute qualité, les auteurs ont adopté une stratégie de contournement pour atteindre cet objectif. Premièrement, l’objectif des paramètres apprenables dans la branche audio-linguistique peut être compris comme l’alignement de la sortie de l’encodeur audio avec l’espace d’intégration du LLM. L'encodeur audio ImageBind possède une très forte capacité d'alignement multimodal, qui peut aligner les intégrations de différentes modalités dans un espace commun. Par conséquent, les auteurs utilisent des données de texte visuel pour entraîner la branche du langage audio, en alignant l'espace d'intégration commun d'ImageBind sur l'espace d'intégration de texte de LLM, obtenant ainsi une modalité audio sur l'alignement de l'espace d'intégration de texte LLM. De cette manière intelligente, Video-LLaMA est capable de démontrer sa capacité à comprendre l'audio lors de l'inférence, même s'il n'a jamais été formé sur des données audio.
L'auteur montre quelques exemples de dialogue vidéo/audio/image Video-LLaMA.
(1) Les deux exemples suivants démontrent les capacités de perception audiovisuelle complètes de Video-LLaMA. La conversation dans l'exemple tourne autour de l'audio-vidéo. Dans l'exemple 2, seul l'artiste est affiché à l'écran, mais le son est constitué des acclamations et des applaudissements du public. Si le modèle ne peut recevoir que des signaux visuels, il ne pourra pas déduire la réponse positive du public. aucun son d'instruments de musique dans l'audio. Mais il y a un saxophone dans l'image. Si le modèle ne peut recevoir que des signaux auditifs, il ne saura pas que le joueur a joué du saxophone.

(2) Video-LLaMA possède également de fortes capacités de compréhension perceptuelle des images statiques et peut effectuer des tâches telles que la description d'une image, des questions et réponses, etc.

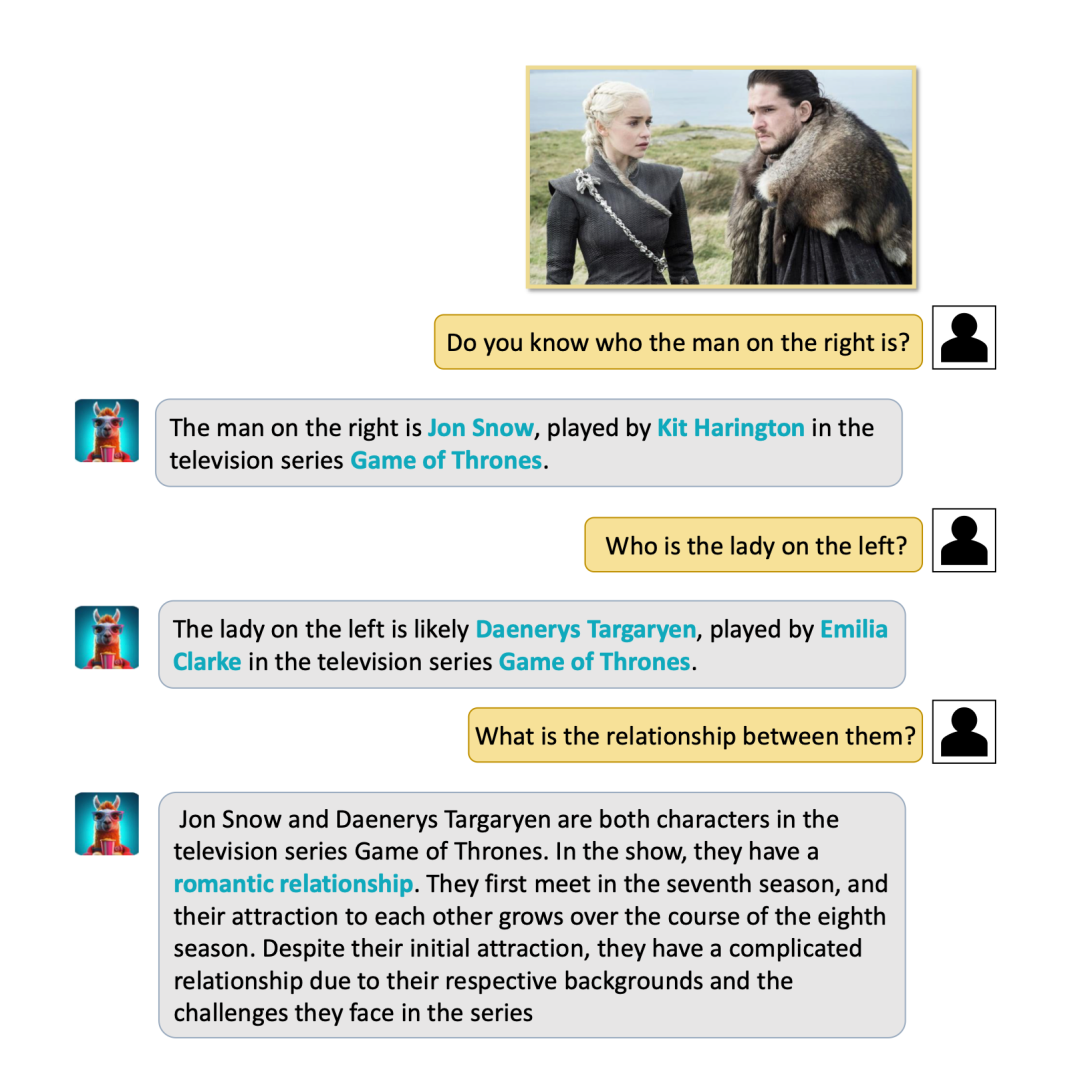
(3) Étonnamment, Video-LLaMA peut identifier avec succès des monuments et des personnes célèbres et poser des questions et réponses de bon sens. Par exemple, VIdeo-LLaMA ci-dessous a réussi à identifier la Maison Blanche et à présenter la situation de la Maison Blanche. Un autre exemple est la saisie d'une photo de Long Ma et Jon Snow (personnages du film et de la série télévisée classiques "Game of Thrones"). VIdeo-LLaMA peut non seulement les identifier, mais aussi leur parler de leur relation qui est constamment en cours. édité et foiré.

(4) Video-llama peut également capturer des événements dynamiques dans la vidéo, tels que le mouvement des cris et la direction du bateau.

À l'heure actuelle, la compréhension de l'audio et de la vidéo reste un problème de recherche très complexe sans solution mature. Bien que Video-LLaMA ait montré des capacités impressionnantes, l'auteur a également mentionné qu'il présente certaines limites.
(1) Capacité de perception limitée : Les capacités visuelles et auditives de Video-LLaMA sont encore relativement rudimentaires, et il est encore difficile d'identifier des informations visuelles et sonores complexes. Cela s’explique en partie par le fait que la qualité et la taille des ensembles de données ne sont pas suffisantes. Ce groupe de recherche travaille dur pour créer un ensemble de données d'alignement audio-vidéo-texte de haute qualité afin d'améliorer les capacités de perception du modèle.
(2) Difficulté à traiter de longues vidéos : les vidéos longues (telles que les films et les émissions de télévision) contiennent une grande quantité d'informations, ce qui nécessite des capacités de raisonnement et des ressources informatiques élevées pour le modèle.
(3) Le problème d'hallucination inhérent aux modèles de langage existe toujours dans Video-LLaMA.
En général, Video-LLaMA, en tant que grand modèle doté de capacités audiovisuelles complètes, a obtenu des résultats impressionnants dans le domaine de la compréhension audio et vidéo. À mesure que les chercheurs continuent de travailler dur, les défis ci-dessus seront surmontés un par un, ce qui donnera au modèle de compréhension audio et vidéo une grande valeur pratique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment vérifier le plagiat sur CNKI Étapes détaillées pour vérifier le plagiat sur CNKI
Comment vérifier le plagiat sur CNKI Étapes détaillées pour vérifier le plagiat sur CNKI
 Comment ouvrir le fichier php
Comment ouvrir le fichier php
 Vérifiez le statut en ligne de vos amis sur TikTok
Vérifiez le statut en ligne de vos amis sur TikTok
 Utilisation des commandes NTSD
Utilisation des commandes NTSD
 Comment résoudre le problème signalé par le lien MySQL 10060
Comment résoudre le problème signalé par le lien MySQL 10060
 WeChat restaure l'historique des discussions
WeChat restaure l'historique des discussions
 La différence entre ancrer et viser
La différence entre ancrer et viser
 Quelle est la différence entre Douyin et Douyin Express Edition ?
Quelle est la différence entre Douyin et Douyin Express Edition ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



