


Large Model (LLM) offre une nouvelle direction pour le développement de l'intelligence artificielle générale (AGI). Il organise des formations auto-supervisées à grande échelle via des données publiques massives, telles qu'Internet, des livres et d'autres corpus, et obtient une compréhension linguistique puissante, une production linguistique, un raisonnement et d'autres capacités. Cependant, les grands modèles sont encore confrontés à certains défis lors de l'utilisation des données du domaine privé. Les données du domaine privé font référence aux données appartenant à des entreprises ou à des individus spécifiques et contiennent généralement des connaissances spécifiques au domaine. La combinaison de grands modèles avec des connaissances du domaine privé apportera une grande valeur.
Les connaissances du domaine privé peuvent être divisées en données non structurées et structurées en termes de forme de données. Les données non structurées, telles que les documents, sont généralement améliorées grâce à la récupération, et des outils tels que langchain peuvent être utilisés pour mettre en œuvre rapidement un système de questions et réponses. Les données structurées, telles que les bases de données (DB), nécessitent de grands modèles pour interagir avec la base de données, interroger et analyser afin d'obtenir des informations utiles. Une série de produits et d'applications ont récemment été développés autour de grands modèles et bases de données, tels que l'utilisation de LLM pour créer des bases de données intelligentes, effectuer des analyses BI et compléter la construction automatique de tables. Parmi eux, la technologie text-to-SQL, qui interagit avec la base de données en langage naturel, a toujours été une direction très attendue.
Dans le monde universitaire, les anciens benchmarks text-to-SQL se concentraient uniquement sur les bases de données à petite échelle. Le LLM le plus avancé peut déjà atteindre une précision d'exécution de 85,3 %, mais cela signifie-t-il que le LLM peut déjà être utilisé comme langage naturel. interface pour la base de données ?
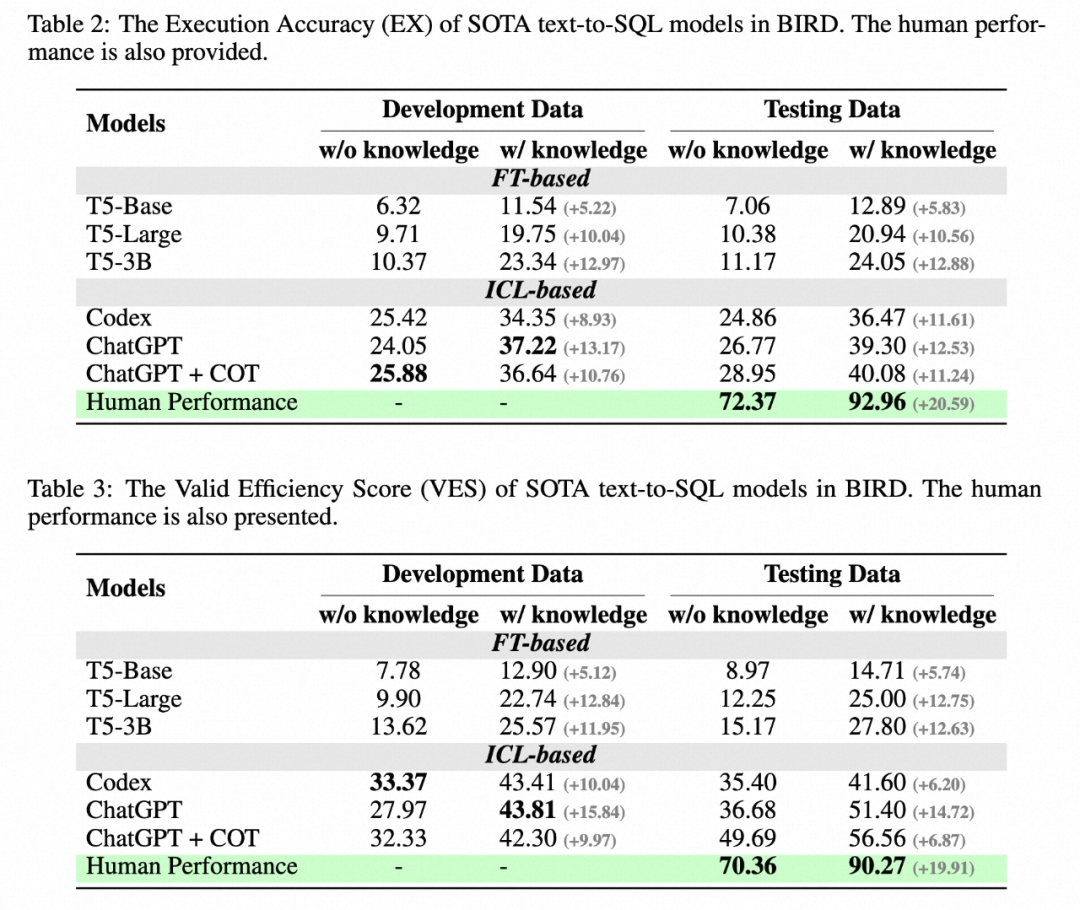
Récemment, Alibaba, en collaboration avec l'Université de Hong Kong et d'autres institutions, a lancé un nouveau BIRD de référence (Can LLM Déjà Servir d'Interface de Base de Données ? A BIg Bench for Large-Scale Database Grounded Text ) pour les bases de données réelles à grande échelle (to-SQL), comprenant 95 bases de données à grande échelle et des paires Text-SQL de haute qualité, avec une capacité de stockage de données allant jusqu'à 33,4 Go. Le meilleur modèle précédent n'atteignait qu'une évaluation de 40,08 % sur BIRD, ce qui est encore loin du résultat humain de 92,96 %, ce qui prouve que des défis existent toujours. En plus d'évaluer l'exactitude de SQL, l'auteur a également ajouté une évaluation de l'efficacité d'exécution de SQL, en espérant que le modèle puisse non seulement écrire du SQL correct, mais également écrire du SQL efficace.

Papier : https://arxiv.org/abs/2305.03111
Page d'accueil : https://bird-bench.github.io
Code : https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/bird

Actuellement, les données, le code et les listes de BIRD sont open source, et le nombre de téléchargements dans le monde a dépassé 10 000. BIRD a suscité une large attention et de nombreuses discussions sur Twitter depuis son lancement.


Les commentaires des utilisateurs étrangers sont également très excitants :

Un projet LLM à ne pas manquer

Des points de contrôle très utiles, des foyers d'amélioration
L'IA peut vous aider, mais elle ne peut pas encore vous remplacer Mon travail est sécuritaire pour le moment Le...# 🎜🎜#
Présentation de la méthodeNouveau défi # 🎜🎜#
# 🎜🎜#
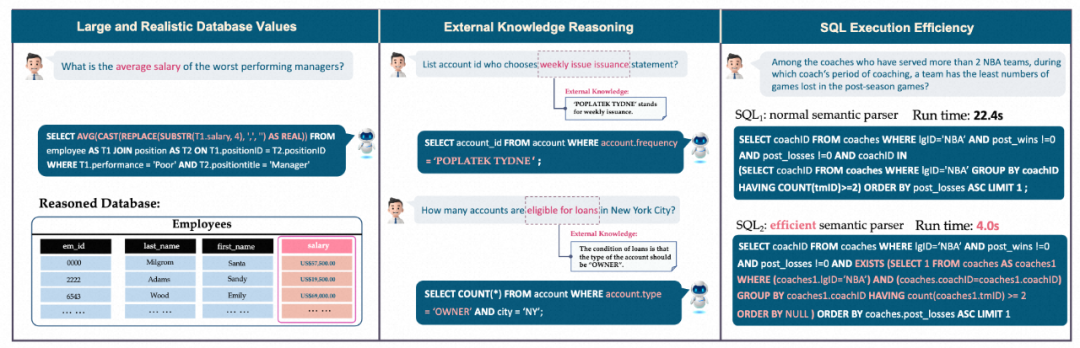
Tout d'abord, la base de données contient des valeurs de données massives et bruyantes. Dans l'exemple de gauche, le salaire moyen doit être calculé en convertissant la chaîne de la base de données en une valeur à virgule flottante (Float), puis en effectuant le calcul d'agrégation (Agrégation) ; #
Deuxièmement, une inférence de connaissances externes est nécessaire. Dans l'exemple du milieu, afin de renvoyer avec précision les réponses à l'utilisateur, le modèle doit d'abord savoir que le type de compte éligible au prêt doit être « PROPRIÉTAIRE » (« PROPRIÉTAIRE »). ). Cela signifie que les mystères cachés derrière d'énormes contenus de bases de données nécessitent parfois des connaissances et un raisonnement externes pour être révélés ;Enfin, l'efficacité de l'exécution des requêtes doit être prise en compte. Dans l'exemple de droite, l'utilisation de requêtes SQL plus efficaces peut améliorer considérablement la vitesse, ce qui est d'une grande valeur pour l'industrie car les utilisateurs s'attendent non seulement à écrire du SQL correct, mais également à une exécution SQL efficace, en particulier dans les grandes bases de données. ; Le processus dissocie la génération de questions et l'annotation SQL. Dans le même temps, des experts sont ajoutés pour rédiger des fichiers de description de base de données afin d'aider le personnel chargé des problèmes et des annotations SQL à mieux comprendre la base de données.
1. Collecte de bases de données : L'auteur a collecté et 80 bases de données ont été traitées. Quinze bases de données ont été créées manuellement sous forme de tests boîte noire en collectant des données de table réelles, en créant des diagrammes ER et en définissant des contraintes de base de données pour éviter que la base de données actuelle ne soit apprise par le grand modèle actuel. La base de données BIRD contient des modèles et des valeurs dans plusieurs domaines, 37 domaines, couvrant la blockchain, les sports, les soins médicaux, les jeux, etc.
 2. Collection de problèmes : Tout d'abord, l'auteur engage des experts pour rédiger un fichier de description pour la base de données. Le fichier de description comprend une description complète des noms de colonnes, des valeurs de la base de données. et compréhension des valeurs. Connaissances externes utilisées, etc. Ensuite, 11 locuteurs natifs des États-Unis, du Royaume-Uni, du Canada, de Singapour et d'autres pays ont été recrutés pour générer des questions pour BIRD. Chaque orateur est titulaire d'au moins un baccalauréat ou plus.
2. Collection de problèmes : Tout d'abord, l'auteur engage des experts pour rédiger un fichier de description pour la base de données. Le fichier de description comprend une description complète des noms de colonnes, des valeurs de la base de données. et compréhension des valeurs. Connaissances externes utilisées, etc. Ensuite, 11 locuteurs natifs des États-Unis, du Royaume-Uni, du Canada, de Singapour et d'autres pays ont été recrutés pour générer des questions pour BIRD. Chaque orateur est titulaire d'au moins un baccalauréat ou plus.
3. Génération SQL : Une équipe mondiale d'annotation composée d'ingénieurs de données et d'étudiants en cours de bases de données a été recrutée pour générer du SQL pour BIRD. Étant donné une base de données et un fichier de description de base de données de référence, l'annotateur doit générer du SQL pour répondre correctement à la question. La méthode d'annotation en double aveugle est adoptée, nécessitant que deux annotateurs annotent la même question. L'annotation en double aveugle peut minimiser les erreurs causées par un seul annotateur.
4. Tests de qualité : Les tests de qualité sont divisés en deux parties : l'efficacité et la cohérence de l'exécution des résultats. La validité nécessite non seulement l'exactitude de l'exécution, mais exige également que le résultat de l'exécution ne puisse pas être nul (NULL). Les experts modifieront progressivement les conditions du problème jusqu'à ce que les résultats de l'exécution SQL soient valides.
5. Division de difficulté : l'indice de difficulté du texte vers SQL peut fournir aux chercheurs une référence pour optimiser les algorithmes. La difficulté de Text-to-SQL dépend non seulement de la complexité du SQL, mais également de facteurs tels que la difficulté de la question, la facilité de compréhension avec des connaissances supplémentaires et la complexité de la base de données. Les auteurs ont donc demandé aux annotateurs SQL d'évaluer la difficulté lors du processus d'annotation et ont divisé la difficulté en trois catégories : facile, modérée et difficile.
Statistiques de données
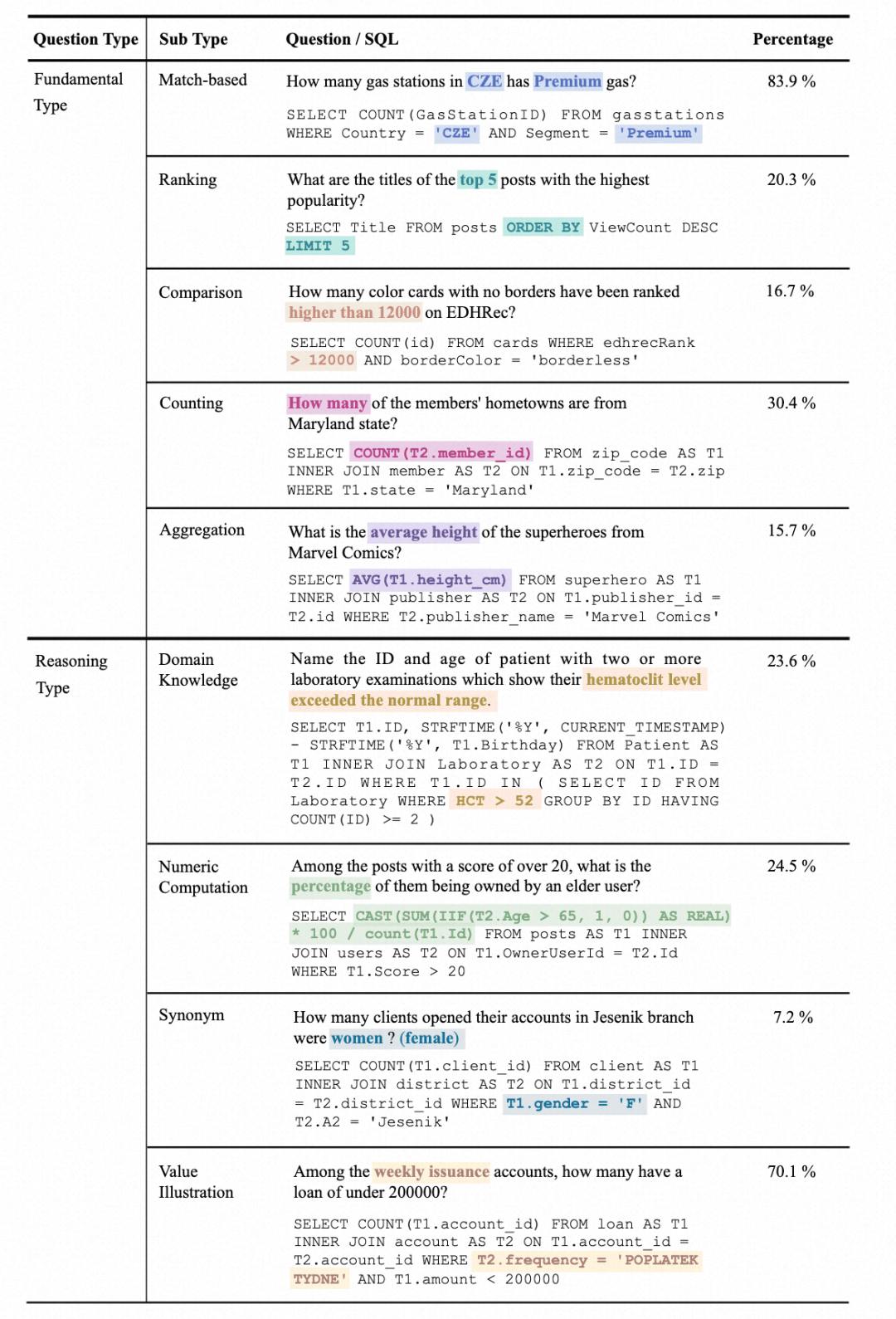
1 Statistiques de type de question : les questions sont divisées en deux catégories, le type fondamental et le type de raisonnement. Les types de questions de base incluent celles couvertes par les ensembles de données Text-to-SQL traditionnels, tandis que les types de questions d'inférence incluent des questions qui nécessitent des connaissances externes pour comprendre les valeurs :
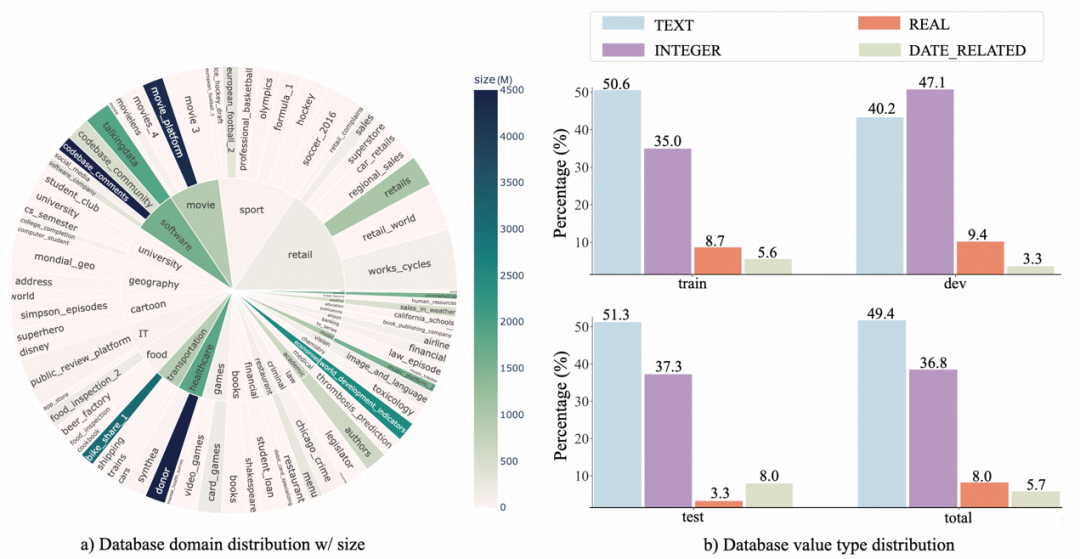
2. Distribution de la base de données : l'auteur utilise un graphique sunburst Affiche la relation entre le domaine de la base de données et la taille de ses données. Un rayon plus grand signifie que davantage de texte SQL est basé sur cette base de données, et vice versa. Plus la couleur est foncée, plus la taille de la base de données est grande. Par exemple, donneur est la plus grande base de données du benchmark, occupant 4,5 Go d'espace.
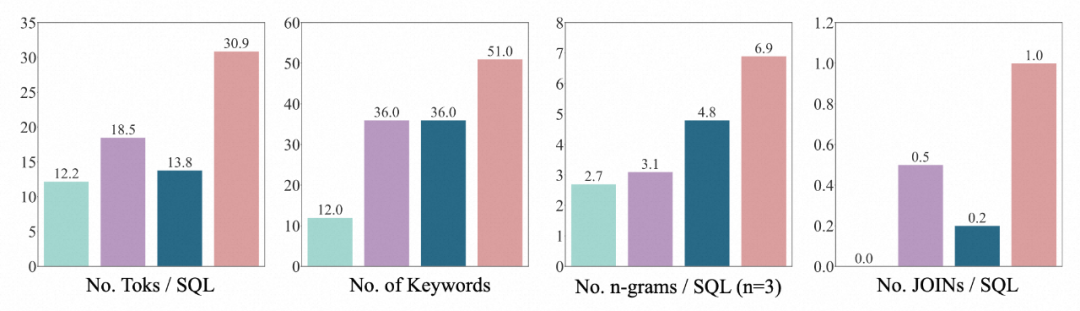
Distribution 3.SQL : L'auteur prouve que le SQL de BIRD est de loin le plus diversifié et le plus complexe à travers quatre dimensions : le nombre de tokens SQL, le nombre de mots-clés, le nombre de types n-grammes , et le nombre de JOIN.
Indicateurs d'évaluation
1. Précision d'exécution : Comparez la différence entre les résultats d'exécution SQL prédits par le modèle et les résultats d'exécution SQL réels annotés
2. score : en même temps, compte tenu de la précision et de l'efficacité de SQL, la différence relative entre la vitesse d'exécution SQL prédite par le modèle et la vitesse d'exécution SQL réelle étiquetée est comparée, et le temps d'exécution est considéré comme le principal indicateur d'efficacité.
Analyse expérimentale
L'auteur a sélectionné comme modèles de base le modèle de type formation T5 et le grand modèle de langage (LLM) qui ont des performances exceptionnelles dans les tests de référence précédents : Codex (code-davinci-002) et ChatGPT. (gpt-3.5-turbo). Afin de mieux comprendre si le raisonnement en plusieurs étapes peut stimuler les capacités de raisonnement de grands modèles de langage dans des environnements de bases de données réels, leur version Chaîne de Pensée est également fournie. Et testez le modèle de base dans deux contextes : l'un est la saisie complète des informations sur le schéma et l'autre est la compréhension humaine des valeurs de la base de données impliquées dans le problème, résumées dans une description en langage naturel (preuves de connaissances) pour aider le modèle à comprendre la base de données. .
L'auteur donne quelques conclusions :
1. Gain de connaissances supplémentaires : l'augmentation des connaissances sur la compréhension de la valeur des bases de données a un effet évident sur l'amélioration, ce qui prouve que dans les bases de données réelles, c'est le cas. pas suffisant pour s'appuyer uniquement sur les capacités d'analyse sémantique. Comprendre les valeurs de la base de données aidera les utilisateurs à trouver des réponses plus précises.
2. Le chaînage de pensées n'est pas nécessairement totalement bénéfique : dans le cas où le modèle n'a pas de description de valeur de base de données donnée et de tir nul (zéro-shot), la propre inférence COT du modèle peut générer des réponses avec plus de précision. Cependant, après avoir reçu des connaissances supplémentaires (preuves de connaissances), il a été demandé à LLM d'effectuer un COT et a constaté que l'effet n'était pas significatif, voire déclinait. Par conséquent, dans ce scénario, LLM peut générer des conflits de connaissances. Comment résoudre ce conflit afin que le modèle puisse à la fois accepter des connaissances externes et bénéficier de son propre raisonnement puissant en plusieurs étapes sera une direction de recherche clé à l'avenir.
3. L'écart avec les humains : BIRD fournit également des indicateurs humains. L'auteur utilise un examen pour tester les performances de l'annotateur lorsqu'il est confronté pour la première fois à l'ensemble de tests, et l'utilise comme base pour. indicateurs humains. Des expériences ont montré que le meilleur LLM actuel est encore loin derrière les humains, ce qui prouve que des défis existent toujours. Les auteurs ont effectué une analyse détaillée des erreurs et ont fourni quelques orientations potentielles pour de futures recherches.

LLM dans le champ base de données L'application offrira aux utilisateurs une expérience d'interaction avec les bases de données plus intelligente et plus pratique. L'émergence de BIRD favorisera le développement intelligent de l'interaction entre le langage naturel et les bases de données réelles, permettra de progresser dans la technologie texte-SQL pour des scénarios de bases de données réelles et aidera les chercheurs à développer des applications de bases de données plus avancées et plus pratiques.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que comprend le stockage par cryptage des données ?
Que comprend le stockage par cryptage des données ?
 Le rôle de l'attribut caption
Le rôle de l'attribut caption
 Historique des opérations de la table de vue Oracle
Historique des opérations de la table de vue Oracle
 Tutoriel de modification du logiciel C++ en chinois
Tutoriel de modification du logiciel C++ en chinois
 Qu'est-ce que le logiciel système
Qu'est-ce que le logiciel système
 Utilisation de caractères arbitraires dans les expressions régulières
Utilisation de caractères arbitraires dans les expressions régulières
 Quel navigateur est Edge ?
Quel navigateur est Edge ?
 Comment utiliser fusioncharts.js
Comment utiliser fusioncharts.js








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



