



#🎜 🎜#Introduction : Stable Diffusion montre de puissantes capacités de génération visuelle. Cependant, ils ne parviennent souvent pas à générer des images avec un contrôle spatial, structurel ou géométrique. Des travaux tels que ControlNet [1] et T2I-adpater [2] permettent de générer des images contrôlables pour différentes modalités, mais être capable de s'adapter à diverses conditions visuelles dans un seul modèle unifié reste un défi non résolu. UniControl intègre une variété de tâches de condition à image (C2I) contrôlables dans un cadre unique. Afin de rendre UniControl capable de gérer diverses conditions visuelles, les auteurs ont introduit un HyperNet sensible aux tâches pour ajuster le modèle de diffusion conditionnelle en aval afin qu'il puisse s'adapter simultanément à différentes tâches C2I. UniControl est formé sur neuf tâches C2I différentes, démontrant de solides capacités de génération visuelle et des capacités de généralisation sans tir. L'auteur a mis en open source les paramètres du modèle et le code d'inférence. L'ensemble de données et le code de formation seront également open source dès que possible. Tout le monde est invité à les échanger et à les utiliser.

Figure 1 : Modèle UniControl par Composé de plusieurs tâches de pré-entraînement et de tâches zéro-shot
Motivation : Génération d'images contrôlable existante les modèles sont tous conçus pour une seule modalité. Cependant, des travaux tels que Taskonomy [3] prouvent que différentes modalités visuelles partagent des fonctionnalités et des informations. Par conséquent, cet article estime qu'un modèle multimodal unifié a un grand potentiel.
Solution : Cet article propose un adaptateur de style MOE et un HyperNet prenant en charge les tâches pour implémenter des capacités de génération de conditions multimodales dans UniControl. Et l'auteur a créé un nouvel ensemble de données MultiGen-20M, qui contient 9 tâches principales, plus de 20 millions de triples d'invite de condition d'image et une taille d'image ≥ 512.
Avantages : 1) Modèle plus compact (1,4B #params, 5,78 Go de point de contrôle), implémenter plusieurs tâches avec moins de paramètres. 2) Capacités de génération visuelle et précision de contrôle plus puissantes. 3) Capacité de généralisation sans tir sur des modalités jamais vues.
1. IntroductionLes modèles de base génératifs changent les domaines de l'intelligence artificielle dans le traitement du langage naturel, la vision par ordinateur, le traitement audio et le contrôle des robots. .mode d'interaction. Dans le traitement du langage naturel, les modèles de base génératifs comme InstructGPT ou GPT-4 fonctionnent bien sur une variété de tâches, et cette capacité multitâche est l'une des fonctionnalités les plus attrayantes. De plus, ils peuvent effectuer un apprentissage sans tir ou en quelques tirs pour gérer des tâches invisibles.
Cependant, dans les modèles génératifs dans le champ visuel, cette capacité multitâche n'est pas prédominante. Bien que les descriptions textuelles offrent un moyen flexible de contrôler le contenu des images générées, elles ne parviennent souvent pas à fournir un contrôle spatial, structurel ou géométrique au niveau des pixels. Des recherches populaires récentes telles que ControlNet et l'adaptateur T2I peuvent améliorer le modèle de diffusion stable (SDM) pour obtenir un contrôle précis. Cependant, contrairement aux signaux linguistiques, qui peuvent être traités par un module unifié tel que CLIP, chaque modèle ControlNet ne peut traiter que la modalité spécifique sur laquelle il a été formé.
Pour surmonter les limites des travaux antérieurs, cet article propose UniControl, un modèle de diffusion unifié qui peut gérer à la fois le langage et diverses conditions visuelles. La conception unifiée d'UniControl permet une meilleure efficacité de formation et d'inférence ainsi qu'une génération contrôlable améliorée. UniControl, quant à lui, bénéficie des connexions inhérentes entre différentes conditions visuelles pour améliorer les effets génératifs de chaque condition.
La capacité de génération contrôlable unifiée d'UniControl repose sur deux parties, l'une est « l'adaptateur de style MOE » et l'autre est « l'HyperNet sensible aux tâches ». L'adaptateur de style MOE possède environ 70 000 paramètres et peut apprendre des cartes de fonctionnalités de bas niveau à partir de diverses modalités. HyperNet sensible aux tâches peut saisir des instructions de tâche sous forme d'invites en langage naturel et générer des intégrations de tâches à intégrer dans le réseau en aval pour moduler les paramètres en aval. pour s'adapter aux différentes entrées modales.
Cette étude a pré-entraîné UniControl pour obtenir des capacités d'apprentissage multi-tâches et sans tir, comprenant neuf tâches différentes dans cinq catégories : Edge (Canny, HED, Sketch), cartographie de zone (Segmentation, Object Bound) Box), Squelette (squelette humain), géométrie (profondeur, surface normale) et édition d'images (image Outpainting). L'étude a ensuite formé UniControl sur le matériel NVIDIA A100 pendant plus de 5 000 heures GPU (de nouveaux modèles sont encore en cours de formation aujourd'hui). Et UniControl démontre une adaptabilité immédiate aux nouvelles tâches.
La contribution de cette recherche peut être résumée comme suit :
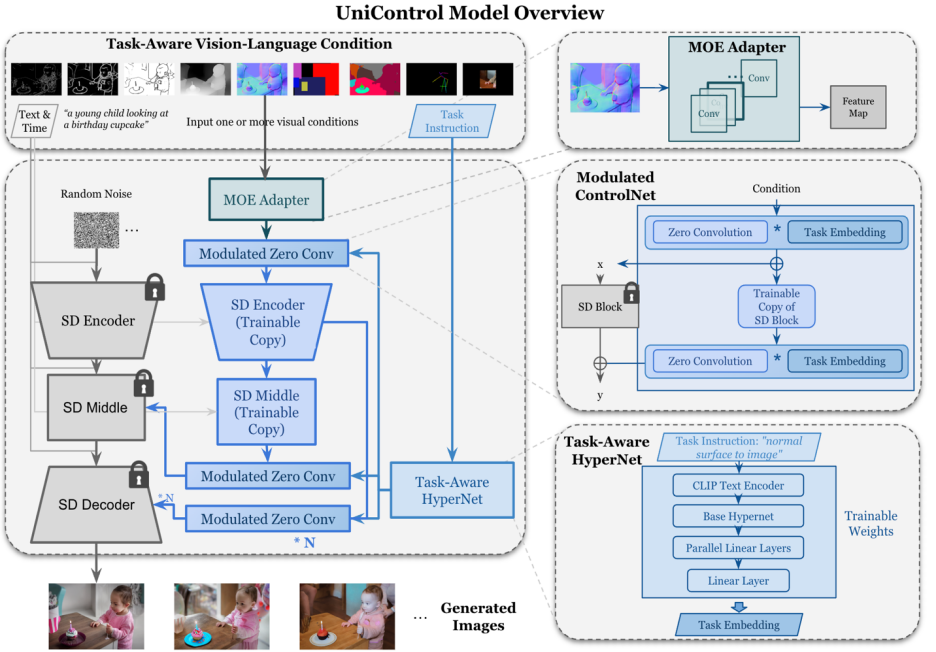
Figure 2 : Structure du modèle. Pour s'adapter à plusieurs tâches, l'étude a conçu un adaptateur de type MOE avec environ 70 000 paramètres par tâche et un HyperNet prenant en charge les tâches (environ 12 millions de paramètres) pour moduler 7 couches sans convolution. Cette structure permet la mise en œuvre de fonctions multi-tâches dans un modèle unique, ce qui garantit non seulement la diversité des multi-tâches, mais conserve également le partage des paramètres sous-jacents. Réduction significative de la taille du modèle par rapport aux modèles empilés équivalents à tâche unique (environ 1,4 B de paramètres par modèle).
La conception du modèle UniControl garantit deux propriétés :
1) Surmonter le désalignement entre les fonctionnalités de bas niveau de différentes modalités. Cela aide UniControl à apprendre les informations nécessaires et uniques de toutes les tâches. Par exemple, lorsqu'un modèle s'appuie sur des cartes de segmentation comme condition visuelle, les informations 3D peuvent être ignorées.
2) Capable d'apprendre des méta-connaissances à travers les tâches. Cela permet au modèle de comprendre les connaissances partagées entre les tâches et les différences entre elles.
Pour fournir ces propriétés, le modèle introduit deux nouveaux modules : l'adaptateur de style MOE et l'HyperNet prenant en charge les tâches.
L'adaptateur de style MOE est un ensemble de modules de convolution, chaque adaptateur correspond à une modalité distincte, inspirée du modèle de mélange d'experts (MOE), utilisé comme UniControl pour capturer les caractéristiques de diverses conditions visuelles de bas niveau. Ce module adaptateur possède environ 70 000 paramètres et est extrêmement efficace en termes de calcul. Les caractéristiques visuelles seront ensuite introduites dans un réseau unifié pour traitement.
HyperNet sensible aux tâches ajuste le module de convolution zéro de ControlNet via des conditions d'instruction de tâche. HyperNet projette d’abord les instructions de tâche dans l’intégration de tâches, puis les chercheurs injectent l’intégration de tâches dans la couche zéro convolution de ControlNet. Ici, l'intégration des tâches correspond à la taille de la matrice du noyau de convolution de la couche de convolution nulle. Semblable à StyleGAN [4], cette étude multiplie directement les deux pour moduler les paramètres de convolution, et les paramètres de convolution modulés sont utilisés comme paramètres de convolution finaux. Par conséquent, les paramètres de convolution nulle modulés de chaque tâche sont différents, ce qui garantit l'adaptabilité du modèle à chaque modalité. De plus, tous les poids sont partagés.
Différent de SDM ou ControlNet, la condition de génération d'image de ces modèles est un indice de langage unique, ou un seul type de condition visuelle comme Canny. UniControl doit gérer une variété de conditions visuelles liées à différentes tâches, ainsi que des signaux verbaux. Par conséquent, l'entrée d'UniControl se compose de quatre parties : le bruit, l'invite de texte, la condition visuelle et les instructions de tâche. Parmi eux, l’instruction des tâches peut être obtenue naturellement selon la modalité de la condition visuelle.

Avec de telles paires d'entraînement générées, cette étude adopte DDPM [5] pour entraîner le modèle.

Figure 6 : Résultats de la comparaison visuelle de l'ensemble de tests. Les données de test proviennent de MSCOCO [6] et Laion [7]
Les résultats de comparaison avec l'officiel ou le ControlNet reproduits dans cette étude sont présentés dans la figure 6. Pour plus de résultats, veuillez vous référer à l'article.
Le modèle teste la capacité du tir zéro dans les deux scénarios suivants :
Généralisation des tâches mixtes : Cette étude considère deux conditions visuelles différentes comme entrée dans UniControl, l'une est une mélange de cartes de segmentation et de squelettes humains, avec des mots-clés spécifiques « arrière-plan » et « premier plan » ajoutés à l'invite de texte. De plus, l'étude réécrit les instructions de tâches hybrides comme un hybride d'instructions permettant de combiner deux tâches, telles que « carte de segmentation et squelette humain en image ».
Nouvelle généralisation des tâches : UniControl est nécessaire pour générer des images contrôlables dans de nouvelles conditions visuelles invisibles. Pour y parvenir, il est crucial d’estimer la pondération des tâches en fonction de la relation entre les tâches pré-entraînées invisibles et vues. Les pondérations des tâches peuvent être estimées en attribuant ou en calculant manuellement des scores de similarité des instructions de tâches dans l'espace d'intégration. Les adaptateurs de type MOE peuvent être assemblés linéairement avec des poids de tâche estimés pour extraire des caractéristiques peu profondes de nouvelles conditions visuelles invisibles.
Les résultats visualisés sont présentés dans la figure 7. Pour plus de résultats, veuillez vous référer à l'article.

Figure 7 : Résultats de visualisation d'UniControl sur des tâches Zero-shot
En général, le modèle UniControl, grâce à sa diversité de contrôle, fournit une génération de vision contrôlable fournit un nouveau modèle de base. Un tel modèle pourrait offrir la possibilité d’atteindre des niveaux plus élevés d’autonomie et de contrôle humain sur les tâches de génération d’images. Cette étude a hâte de discuter et de collaborer avec davantage de chercheurs pour promouvoir davantage le développement de ce domaine.
Plus de visuels
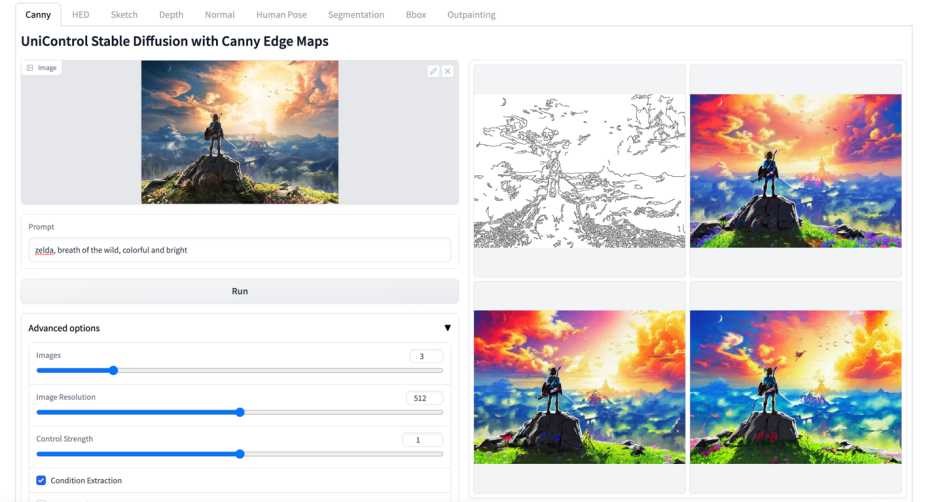
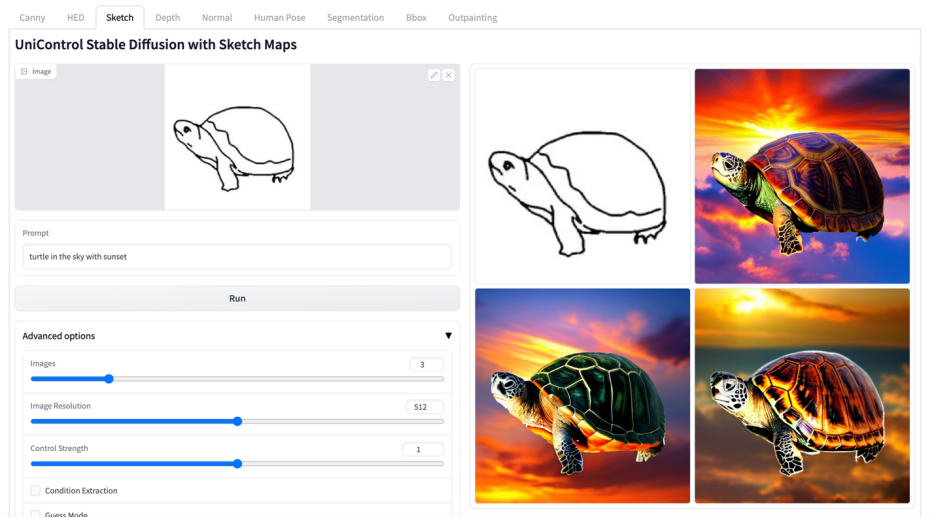
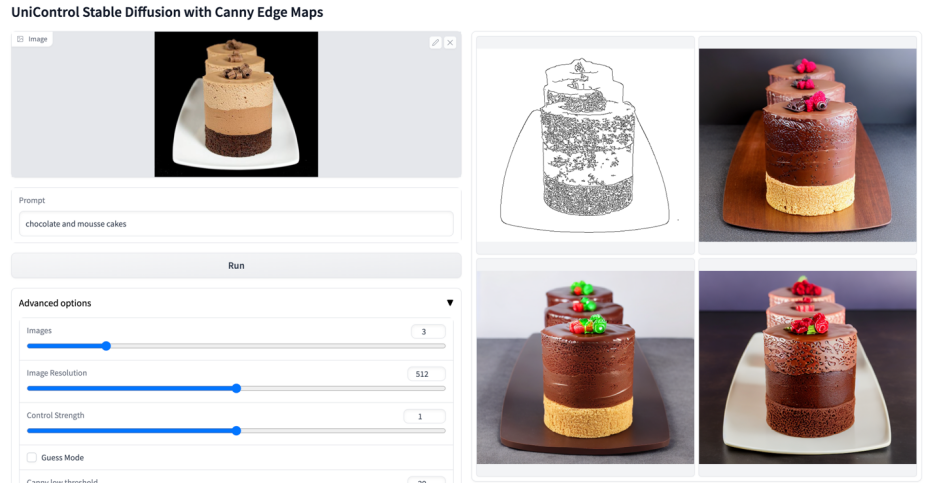
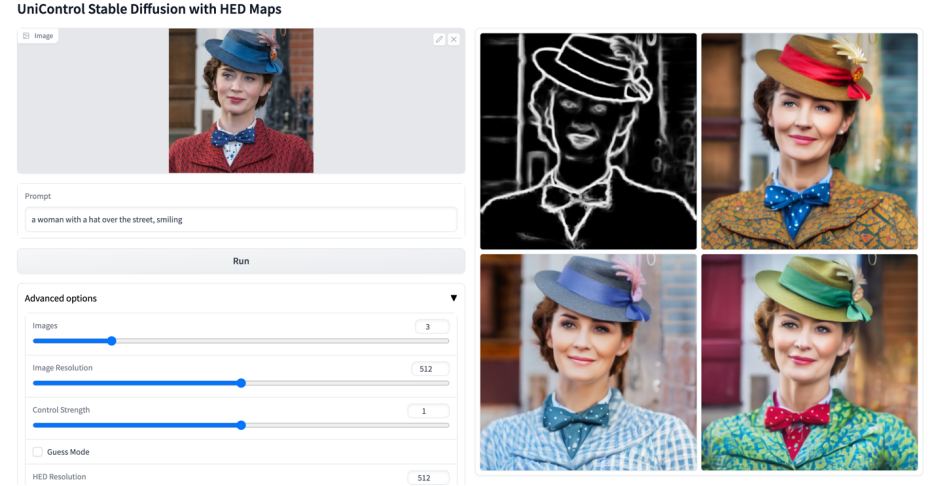
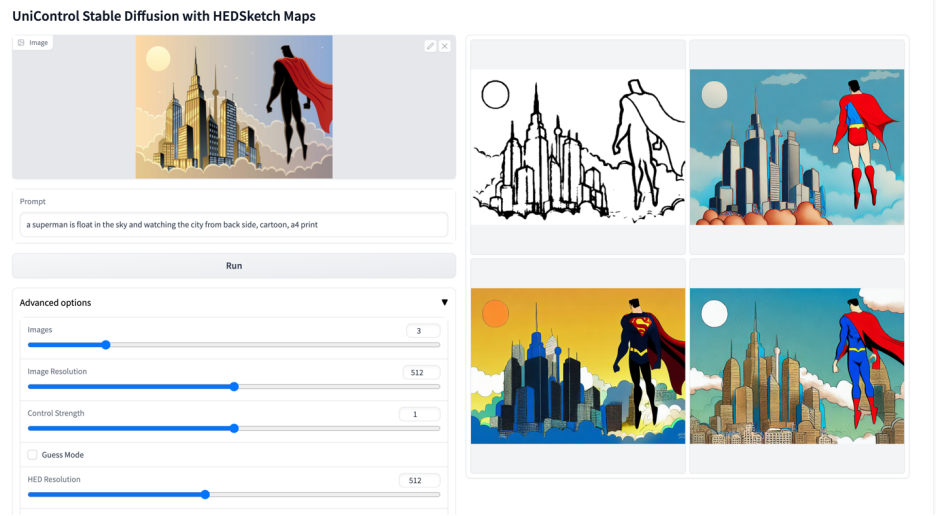
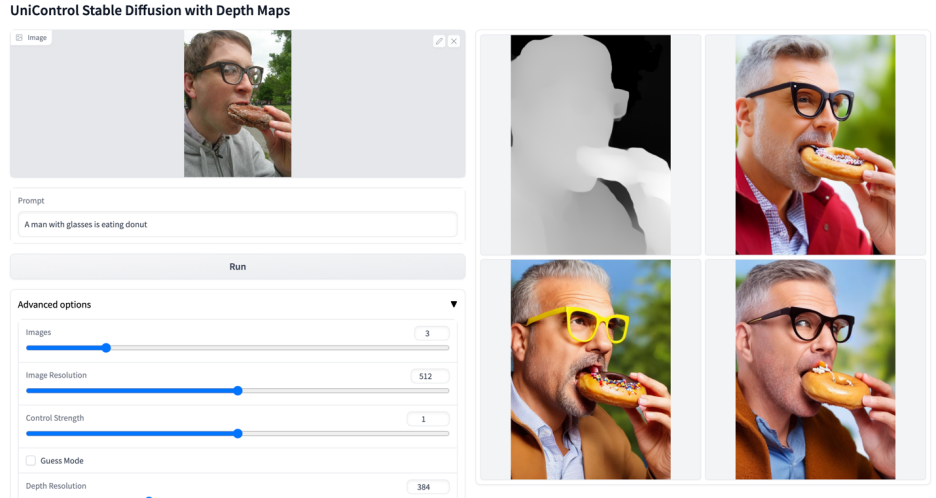
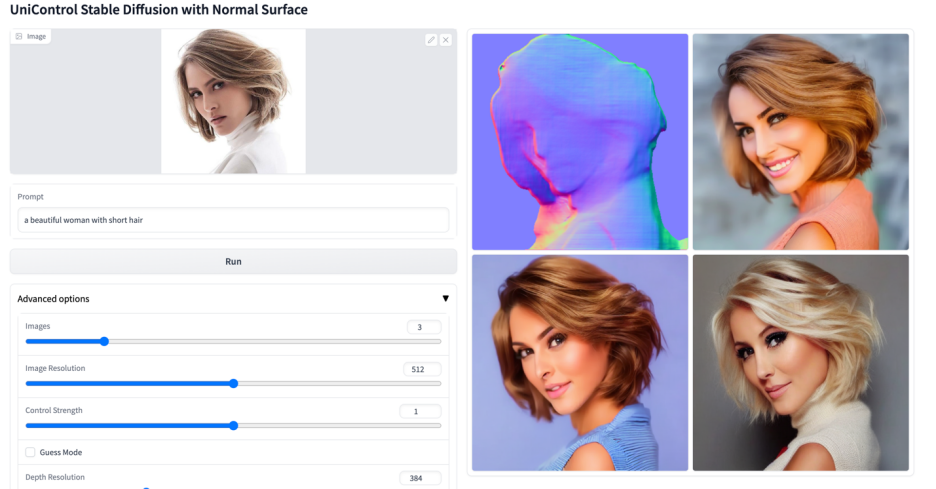
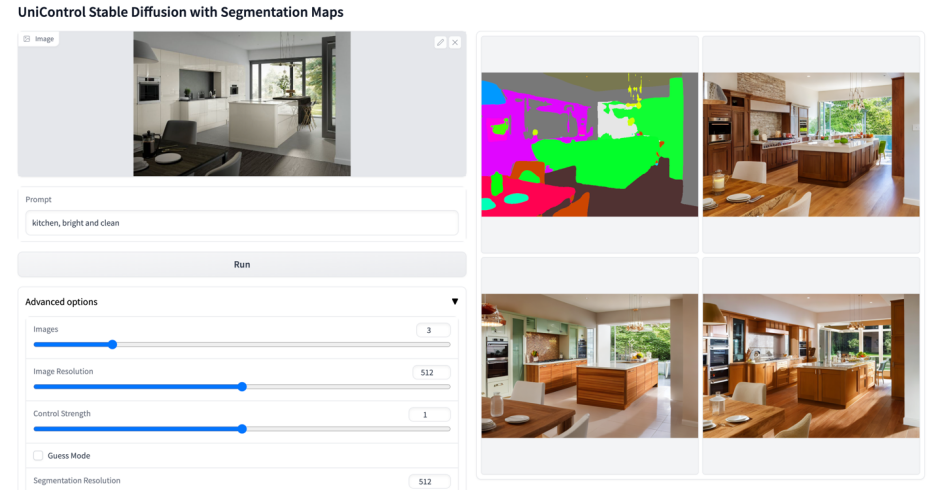
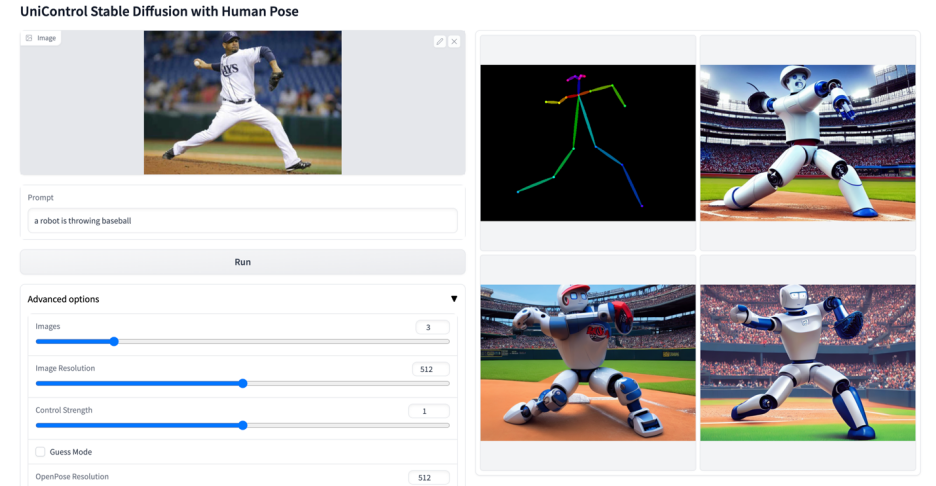
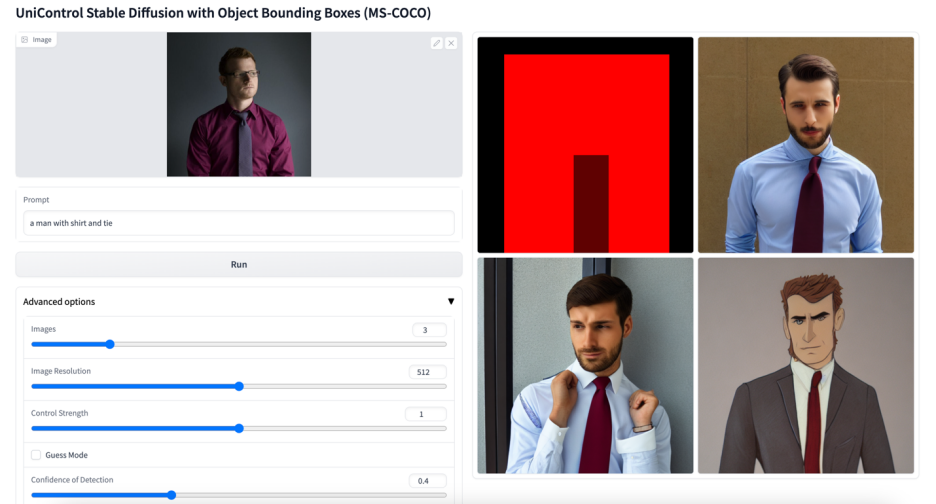
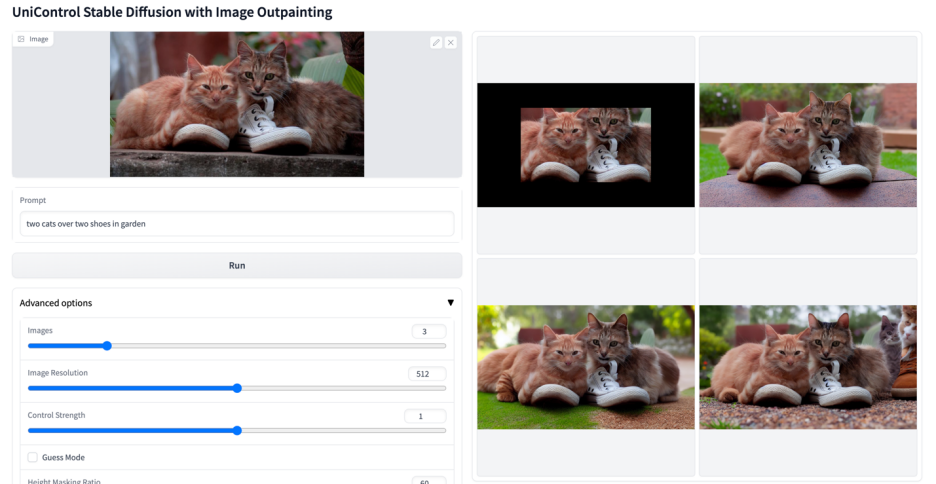
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que sont les bibliothèques d'intelligence artificielle Python ?
Que sont les bibliothèques d'intelligence artificielle Python ?
 Comment supprimer une base de données
Comment supprimer une base de données
 Que signifie le port de liaison montante ?
Que signifie le port de liaison montante ?
 Comment résoudre l'échec de la résolution DNS
Comment résoudre l'échec de la résolution DNS
 Les factures de téléphone de recharge Douyin peuvent-elles être remboursées ?
Les factures de téléphone de recharge Douyin peuvent-elles être remboursées ?
 Comment récupérer des fichiers qui ont été vidés de la corbeille
Comment récupérer des fichiers qui ont été vidés de la corbeille
 Comment utiliser le groupe par
Comment utiliser le groupe par
 shib coin dernières nouvelles
shib coin dernières nouvelles








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



