


Des chercheurs de Cambridge, du NAIST et de Tencent AI Lab ont récemment publié un résultat de recherche appelé PandaGPT, une méthode qui aligne et lie de grands modèles de langage avec différentes modalités pour obtenir des capacités de suivi d'instructions multimodales. PandaGPT peut accomplir des tâches complexes telles que générer des descriptions d'images détaillées, écrire des histoires à partir de vidéos et répondre à des questions sur l'audio. Il peut recevoir des entrées multimodales simultanément et combiner naturellement leur sémantique. Page d'accueil du projet T : https://panda-gpt.github.io/

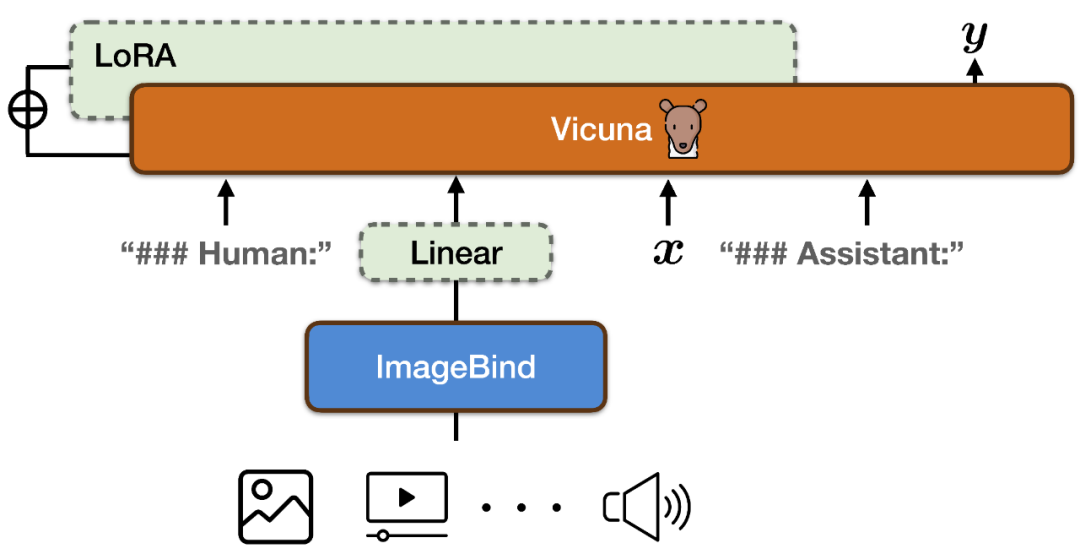 Pour aligner les espaces de fonctionnalités de l'encodeur multimodal d'ImageBind et le modèle de langage à grande échelle de Vicuna, PandaGPT a utilisé un total de 160 000 instructions de langage basées sur des images à la suite des données publiées en combinant LLaVa et Mini-GPT4 comme données de formation. Chaque instance de formation se compose d'une image et d'un ensemble correspondant de cycles de dialogue.
Pour aligner les espaces de fonctionnalités de l'encodeur multimodal d'ImageBind et le modèle de langage à grande échelle de Vicuna, PandaGPT a utilisé un total de 160 000 instructions de langage basées sur des images à la suite des données publiées en combinant LLaVa et Mini-GPT4 comme données de formation. Chaque instance de formation se compose d'une image et d'un ensemble correspondant de cycles de dialogue.
Afin d'éviter de détruire les propriétés d'alignement multimodal d'ImageBind lui-même et de réduire les coûts de formation, PandaGPT a uniquement mis à jour les modules suivants :
Ajoutez une nouvelle matrice de projection linéaire au résultat d'encodage d'ImageBind pour représenter le représentation générée par ImageBind Après la conversion, elle est insérée dans la séquence d'entrée de Vicuna ;
Ajoute des poids LoRA supplémentaires au module d'attention de Vicuna ; Le nombre total de paramètres des deux représente environ 0,4 % des paramètres de Vicuna. La fonction de formation est un objectif traditionnel de modélisation linguistique. Il convient de noter que pendant le processus de formation, seul le poids de la partie correspondante de la sortie du modèle est mis à jour et la partie saisie par l'utilisateur n'est pas calculée. L’ensemble du processus de formation prend environ 7 heures sur des GPU 8 × A100 (40G).
Audio:

Vidéo:

Par rapport à d'autres modèles de langage multimodal, la caractéristique la plus remarquable de PandaGPT est sa capacité à comprendre et à combiner naturellement des informations provenant de différentes modalités.
Vidéo + Audio :
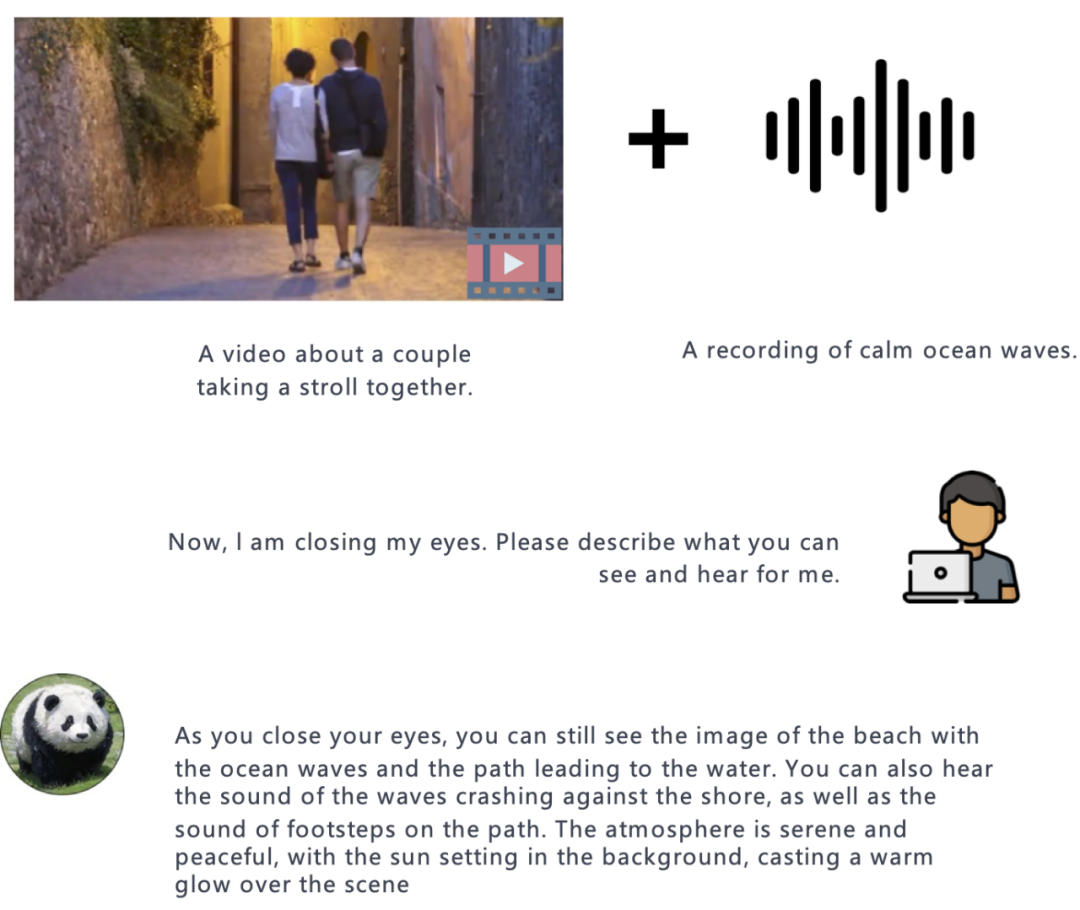
Image + Audio : Résumé
Les auteurs ont également résumé les nombreux problèmes de PandaGPT actuellement et les orientations de développement futures. Bien que PandaGPT ait une incroyable capacité à gérer plusieurs modalités et leurs combinaisons, il existe encore de nombreuses façons d'améliorer considérablement les performances de PandaGPT.
Les modes autres que le texte ne sont représentés que par un vecteur d'intégration, ce qui empêche le modèle de langage de comprendre les informations fines du modèle autres que le texte. Des recherches supplémentaires sur l’extraction de caractéristiques plus fines, telles que les mécanismes d’attention intermodaux, pourraient contribuer à améliorer les performances.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Le rôle de Vulkan
Le rôle de Vulkan
 Comment convertir un pdf au format XML
Comment convertir un pdf au format XML
 securefx ne peut pas se connecter
securefx ne peut pas se connecter
 Quelles sont les principales fonctions de Redis ?
Quelles sont les principales fonctions de Redis ?
 Quelle est la différence entre 5g et 4g
Quelle est la différence entre 5g et 4g
 La différence entre scratch et python
La différence entre scratch et python








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



