


Comment utiliser les fonctions de fenêtrage dans MySQL

(1) Définition de la fonction de fenêtrage
La fonction de fenêtrage est également appelée fonction OLAP (Online Analytical Processing, traitement analytique en ligne), qui est principalement utilisée pour analyser et traiter des données en temps réel. Avant MySQL version 8.0, les fonctions de fenêtrage n'étaient pas prises en charge, mais la prise en charge des fonctions de fenêtrage est fournie depuis cette version.
# 开窗函数语法 func_name(<parameter>) OVER([PARTITION BY <part_by_condition>] [ORDER BY <order_by_list> ASC|DESC])
Analyse de l'instruction de la fonction de fenêtre :
La fonction est divisée en deux parties, une partie est le nom de la fonction, le nombre de fonctions de fenêtre est relativement faible, il n'y a que 11 fonctions de fenêtre + fonctions d'agrégation au total (toutes les fonctions d'agrégation peuvent être utilisé comme fonction de fonctions de fenêtre). Selon la nature de la fonction, certaines doivent écrire des paramètres et d'autres non.
L'autre partie est l'instruction over. over() doit être écrite. Les paramètres à l'intérieur sont tous facultatifs et peuvent être utilisés de manière sélective en fonction des besoins :
Le premier paramètre est le champ partition by +, ce qui signifie basé sur Ce champ divise l'ensemble de données en plusieurs parties
Le deuxième paramètre est le champ Trier par +. Les données de chaque fenêtre sont classées par ordre croissant ou décroissant en fonction de ce champ
Fonction de fenêtrage et regroupement. fonction d'agrégation Elles sont relativement similaires et les données sont divisées en plusieurs parties en spécifiant des champs. La différence est la suivante :
La norme SQL permet à toutes les fonctions d'agrégation d'être utilisées comme fonctions de fenêtre, et le mot-clé OVER est utilisé pour distinguer les fonctions de fenêtre. et fonctions d'agrégation.
La fonction d'agrégation ne renvoie qu'une seule valeur par groupe, tandis que la fonction de fenêtrage peut renvoyer plusieurs valeurs par groupe.
Parmi ces 11 fonctions de fenêtrage, les trois fonctions de tri ROW_NUMBER(), RANK() et DENSE_RANK() sont les plus utilisées dans le travail réel. Apprenons ces trois fonctions de fenêtrage à travers un simple ensemble de données.
# 首先创建虚拟的业务员销售数据 CREATE TABLE Sales ( idate date, iname char(2), sales int ); # 向表中插入数据 INSERT INTO Sales VALUES ('2021/1/1', '丁一', 200), ('2021/2/1', '丁一', 180), ('2021/2/1', '李四', 100), ('2021/3/1', '李四', 150), ('2021/2/1', '刘猛', 180), ('2021/3/1', '刘猛', 150), ('2021/1/1', '王二', 200), ('2021/2/1', '王二', 180), ('2021/3/1', '王二', 300), ('2021/1/1', '张三', 300), ('2021/2/1', '张三', 280), ('2021/3/1', '张三', 280); # 数据查询 SELECT * FROM Sales; # 查询各月中销售业绩最差的业务员 SELECT month(idate),iname,sales, ROW_NUMBER() OVER(PARTITION BY month(idate) ORDER BY sales) as sales_order FROM Sales; SELECT * FROM (SELECT month(idate),iname,sales, ROW_NUMBER() OVER(PARTITION BY month(idate) ORDER BY sales) as sales_order FROM Sales) as t WHERE sales_order=1;

# ROW_NUMBER()、RANK()、DENSE_RANK()的区别 SELECT * FROM (SELECT month(idate) as imonth,iname,sales, ROW_NUMBER() OVER(PARTITION BY month(idate) ORDER BY sales) as row_order, RANK() OVER(PARTITION BY month(idate) ORDER BY sales) as rank_order, DENSE_RANK() OVER(PARTITION BY month(idate) ORDER BY sales) as dense_order FROM Sales) as t;
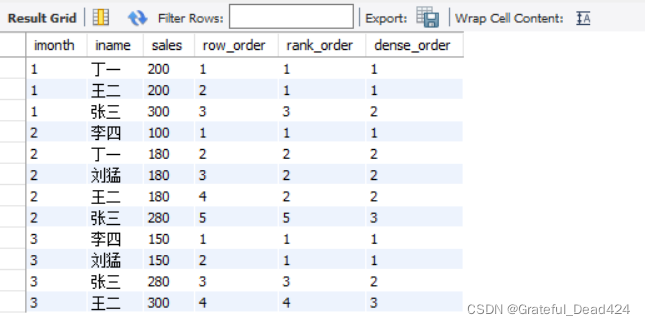
ROW_NUMBER() : tri séquentiel——1, 2, 3
RANK() : tri parallèle, ignorer les numéros de série répétés——1, 1, 3
DENSE_RANK() : Parallèle trier, sans sauter les numéros de série répétés - 1, 1, 2
(2) Scénarios d'application pratiques des fonctions de fenêtrage
Au travail ou lors d'entretiens, vous pouvez rencontrer la nécessité pour les utilisateurs de se connecter pendant des jours consécutifs ou de se connecter pendant un certain nombre de jours . Ce qui suit fournit une idée pour utiliser les fonctions de fenêtrage pour résoudre de tels problèmes.
# 首先创建虚拟的用户登录表,并插入数据 create table user_login ( user_id varchar(100), login_time datetime ); insert into user_login values (1,'2020-11-25 13:21:12'), (1,'2020-11-24 13:15:22'), (1,'2020-11-24 10:30:15'), (1,'2020-11-24 09:18:27'), (1,'2020-11-23 07:43:54'), (1,'2020-11-10 09:48:36'), (1,'2020-11-09 03:30:22'), (1,'2020-11-01 15:28:29'), (1,'2020-10-31 09:37:45'), (2,'2020-11-25 13:54:40'), (2,'2020-11-24 13:22:32'), (2,'2020-11-23 10:55:52'), (2,'2020-11-22 06:30:09'), (2,'2020-11-21 08:33:15'), (2,'2020-11-20 05:38:18'), (2,'2020-11-19 09:21:42'), (2,'2020-11-02 00:19:38'), (2,'2020-11-01 09:03:11'), (2,'2020-10-31 07:44:55'), (2,'2020-10-30 08:56:33'), (2,'2020-10-29 09:30:28'); # 查看数据 SELECT * FROM user_login;
Il existe généralement trois situations lors du calcul du nombre de jours de connexion consécutifs :
Afficher la situation de connexion continue de chaque utilisateur
Afficher le nombre maximum de jours de connexion consécutifs pour chaque utilisateur
Afficher dans une certaine période de temps Utilisateurs qui se sont connectés en continu pendant plus de N jours
Pour la première situation : vérifiez la situation de connexion continue de chaque utilisateur
Sur la base de l'expérience réelle, nous savons que dans un certain laps de temps, les utilisateurs peuvent se connecter plusieurs fois en continu. Nous utilisons ces informations. Tous les champs doivent être affichés, de sorte que les champs affichés dans le résultat final peuvent être l'ID utilisateur, la date de première connexion, la date de fin de connexion et le nombre de jours de connexion consécutifs.
# 数据预处理:由于统计的窗口期是天数,所以可以对登录时间字段进行格式转换,将其变成日期格式然后再去重(去掉用户同一天内多次登录的情况)
# 为方便后续代码查看,将处理结果放置新表中,一步一步操作
create table user_login_date(
select distinct user_id, date(login_time) login_date from user_login);
# 处理后的数据如下:
select * from user_login_date;
# 第一种情况:查看每位用户连续登陆的情况
# 对用户登录数据进行排序
create table user_login_date_1(
select *,
rank() over(partition by user_id order by login_date) irank
from user_login_date);
#查看结果
select * from user_login_date_1;
# 增加辅助列,帮助判断用户是否连续登录
create table user_login_date_2(
select *,
date_sub(login_date, interval irank DAY) idate #data_sub从指定的日期减去指定的时间间隔
from user_login_date_1);
# 查看结果
select * from user_login_date_2;
# 计算每位用户连续登录天数
select user_id,
min(login_date) as start_date,
max(login_date) as end_date,
count(login_date) as days
from user_login_date_2
group by user_id,idate;
# ===============【整合代码,解决用户连续登录问题】===================
select user_id,
min(login_date) start_date,
max(login_date) end_date,
count(login_date) days
from (select *,date_sub(login_date, interval irank day) idate
from (select *,rank() over(partition by user_id order by login_date) irank
from (select distinct user_id, date(login_time) login_date from user_login) as a) as b) as c
group by user_id,idate;Pour le deuxième cas : vérifiez le nombre maximum de jours de connexion consécutifs pour chaque utilisateur
# 计算每个用户最大连续登录天数 select user_id,max(days) from (select user_id, min(login_date) start_date, max(login_date) end_date, count(login_date) days from (select *,date_sub(login_date, interval irank day) idate from (select *,rank() over(partition by user_id order by login_date) irank from (select distinct user_id, date(login_time) login_date from user_login) as a) as b) as c group by user_id,idate) as d group by user_id;
Pour le troisième cas : vérifiez les utilisateurs qui se sont connectés pendant plus de N jours sur une certaine période
Si nous devons vérifier le nombre de jours de connexion consécutifs sur 10. Comment mettre en œuvre cela pour les utilisateurs qui se sont connectés pendant 5 jours consécutifs ou plus entre le 29 novembre et le 25 novembre ? . Cette exigence peut également être filtrée à partir des résultats de la requête dans le premier cas.
# 查看在这段时间内连续登录天数≥5天的用户 select distinct user_id from (select user_id, min(login_date) start_date, max(login_date) end_date, count(login_date) days from (select *,date_sub(login_date, interval irank day) idate from (select *,rank() over(partition by user_id order by login_date) irank from (select distinct user_id, date(login_time) login_date from user_login) as a) as b) as c group by user_id,idate having days>=5 ) as d;
Cette façon d'écrire peut donner des résultats, mais elle est un peu gênante pour ce problème. Voici une méthode simple : faites référence à une nouvelle fonction de fenêtre statique lead()
select *, lead(login_date,4) over(partition by user_id order by login_date) as idate5 from user_login_date;
La fonction lead a trois paramètres. le premier paramètre est la colonne spécifiée (la date de connexion est utilisée ici), le deuxième paramètre est la valeur de plusieurs lignes après la ligne actuelle, ici 4, qui est la date de la cinquième connexion, et le troisième paramètre est s'il est renvoyé Null les valeurs peuvent être remplacées par des valeurs spécifiées. Le troisième paramètre n'est pas utilisé ici. Dans la clause over, les fenêtres sont regroupées par user_id et les données de chaque fenêtre sont classées par ordre croissant par date de connexion.
Utilisez la cinquième date de connexion - login_date+1. Si elle est égale à 5, cela signifie que vous êtes connecté pendant cinq jours consécutifs. Si vous obtenez une valeur nulle ou supérieure à 5, cela signifie que vous n'êtes pas connecté. pendant cinq jours consécutifs. Le code et les résultats sont les suivants :
# 计算第5次登录日期与当天的差值 select *,datediff(idate5,login_date)+1 days from (select *,lead(login_date,4) over(partition by user_id order by login_date) idate5 from user_login_date) as a; # 找出相差天数为5的记录 select distinct user_id from (select *,datediff(idate5,login_date)+1 as days from (select *,lead(login_date,4) over(partition by user_id order by login_date) idate5 from user_logrin_date) as a)as b where days = 5;
[Exercice 】Questions d'entretien d'analyse des données de la plateforme de retrait Meituan - SQL
La table de données de transaction existante user_goods_table est la suivante :

Maintenant, le patron veut savoir la répartition des préférences de catégorie à emporter achetées par chaque utilisateur, et découvrez la catégorie à emporter la plus achetée par chaque utilisateur.
# 分析题目:要求输出字段为用户名user_name,该用户购买最多的外卖品类goods_kind # 解题思路:这是一个分组排序的问题,可以考虑窗口函数 # 第一步:使用窗口函数row_number(),对每个用户购买的外卖品类进行分组统计与排名 select user_name,goods_kind,count(goods_kind), rank() over (partition by user_name order by count(goods_kind) desc) as irank from user_goods_table group by user_name,goods_kind; # 第二步:筛选出每个用户排名第一的外卖品类 select user_id,goods_kind from (select user_name,goods_kind,count(goods_kind), rank() over (partition by user_name order by count(goods_kind) desc) as irank from user_goods_table group by user_name,goods_kind) as a where irank=1
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Effectuer des sauvegardes logiques à l'aide de mysqldump dans MySQL
Jul 06, 2025 am 02:55 AM
Effectuer des sauvegardes logiques à l'aide de mysqldump dans MySQL
Jul 06, 2025 am 02:55 AM
MySQLDump est un outil commun pour effectuer des sauvegardes logiques des bases de données MySQL. Il génère des fichiers SQL contenant des instructions de création et d'insertion pour reconstruire la base de données. 1. Il ne sauvegarde pas le fichier d'origine, mais convertit la structure de la base de données et le contenu en commandes SQL portables; 2. Il convient aux petites bases de données ou à la récupération sélective et ne convient pas à la récupération rapide des données de niveau TB; 3. 4. Utilisez la commande MySQL pour importer pendant la récupération et peut désactiver les vérifications des clés étrangères pour améliorer la vitesse; 5. Il est recommandé de tester régulièrement la sauvegarde, d'utiliser la compression et de régler automatiquement.
 Calcul de la base de données et des tailles de table dans MySQL
Jul 06, 2025 am 02:41 AM
Calcul de la base de données et des tailles de table dans MySQL
Jul 06, 2025 am 02:41 AM
Pour afficher la taille de la base de données et de la table MySQL, vous pouvez interroger directement l'information_schema ou utiliser l'outil de ligne de commande. 1. Vérifiez la taille de la base de données entière: exécutez l'instruction SQL selectTable_schemaas'database ', sum (data_length index_length) / 1024 / 1024as'size (MB)' frominformation_schema.tablesgroupbyTable_schema; Vous pouvez obtenir la taille totale de toutes les bases de données ou ajouter où les conditions limitent la base de données spécifique; 2. Vérifiez la taille unique de la table: utilisez SELECTTA
 Implémentation de transactions et compréhension des propriétés acides dans MySQL
Jul 08, 2025 am 02:50 AM
Implémentation de transactions et compréhension des propriétés acides dans MySQL
Jul 08, 2025 am 02:50 AM
MySQL prend en charge le traitement des transactions et utilise le moteur de stockage InNODB pour garantir la cohérence et l'intégrité des données. 1. Les transactions sont un ensemble d'opérations SQL, soit tous réussissent ou ne parviennent pas à reculer; 2. Les attributs acides comprennent l'atomicité, la cohérence, l'isolement et la persistance; 3. Les déclarations qui contrôlent manuellement les transactions sont StartTransaction, Commit and Rollback; 4. Les quatre niveaux d'isolement incluent la lecture non engagée, la lecture soumise, la lecture reproductible et la sérialisation; 5. Utilisez correctement les transactions pour éviter le fonctionnement à long terme, désactiver les validations automatiques et gérer raisonnablement les verrous et les exceptions. Grâce à ces mécanismes, MySQL peut obtenir une forte fiabilité et un contrôle simultané.
 Configuration de la réplication asynchrone primaire-replica dans MySQL
Jul 06, 2025 am 02:52 AM
Configuration de la réplication asynchrone primaire-replica dans MySQL
Jul 06, 2025 am 02:52 AM
Pour configurer la réplication maître-esclave asynchrone pour MySQL, suivez ces étapes: 1. Préparez le serveur maître, activez les journaux binaires et définissez un serveur unique, créez un utilisateur de réplication et enregistrez l'emplacement du journal actuel; 2. Utilisez MySQLDump pour sauvegarder les données de la bibliothèque maître et l'importez-les au serveur esclave; 3. Configurez le serveur-ID et le log-log du serveur esclave, utilisez la commande Changemaster pour vous connecter à la bibliothèque maître et démarrer le thread de réplication; 4. Vérifiez les problèmes communs, tels que le réseau, les autorisations, la cohérence des données et les conflits d'auto-augmentation, et surveiller les retards de réplication. Suivez les étapes ci-dessus pour vous assurer que la configuration est terminée correctement.
 Gestion des ensembles de personnages et des problèmes de collations dans MySQL
Jul 08, 2025 am 02:51 AM
Gestion des ensembles de personnages et des problèmes de collations dans MySQL
Jul 08, 2025 am 02:51 AM
Les problèmes de règles de jeu de caractères et de tri sont courants lors de la migration multiplateforme ou du développement multi-personnes, entraînant un code brouillé ou une requête incohérente. Il existe trois solutions principales: d'abord, vérifiez et unifiez le jeu de caractères de la base de données, de la table et des champs vers UTF8MB4, affichez via ShowCreateDatabase / Table, et modifiez-le avec une instruction alter; Deuxièmement, spécifiez le jeu de caractères UTF8MB4 lorsque le client se connecte et le définissez dans les paramètres de connexion ou exécutez SetNames; Troisièmement, sélectionnez les règles de tri raisonnablement et recommandez d'utiliser UTF8MB4_UNICODE_CI pour assurer la précision de la comparaison et du tri, et spécifiez ou modifiez-la via ALTER lors de la construction de la bibliothèque et du tableau.
 Connexion à la base de données MySQL à l'aide du client de ligne de commande
Jul 07, 2025 am 01:50 AM
Connexion à la base de données MySQL à l'aide du client de ligne de commande
Jul 07, 2025 am 01:50 AM
La façon la plus directe de se connecter à la base de données MySQL consiste à utiliser le client de la ligne de commande. Entrez d'abord le nom d'utilisateur MySQL-U -P et entrez correctement le mot de passe pour entrer l'interface interactive; Si vous vous connectez à la base de données distante, vous devez ajouter le paramètre -H pour spécifier l'adresse hôte. Deuxièmement, vous pouvez directement passer à une base de données spécifique ou exécuter des fichiers SQL lors de la connexion, tels que le nom de la base de données MySQL-U Username-P ou le nom de la base de données MySQL-U Username-P-P
 Gérer les jeux de caractères et les collations dans MySQL
Jul 07, 2025 am 01:41 AM
Gérer les jeux de caractères et les collations dans MySQL
Jul 07, 2025 am 01:41 AM
Le réglage des jeux de caractères et des règles de collation dans MySQL est crucial, affectant le stockage des données, l'efficacité de la requête et la cohérence. Premièrement, le jeu de caractères détermine la gamme de caractères storable, telle que UTF8MB4 prend en charge les chinois et les emojis; Les règles de tri contrôlent la méthode de comparaison des caractères, telle que UTF8MB4_UNICODE_CI est sensible à la casse, et UTF8MB4_BIN est une comparaison binaire. Deuxièmement, le jeu de caractères peut être défini à plusieurs niveaux de serveur, de base de données, de table et de colonne. Il est recommandé d'utiliser UTF8MB4 et UTF8MB4_UNICODE_CI de manière unifiée pour éviter les conflits. En outre, le problème du code brouillé est souvent causé par des jeux de caractères incohérents de connexions, de stockage ou de terminaux de programme, et doit être vérifié par calque par calque et définir uniformément. De plus, les ensembles de caractères doivent être spécifiés lors de l'exportation et de l'importation pour éviter les erreurs de conversion
 Concevoir une stratégie de sauvegarde de la base de données MySQL robuste
Jul 08, 2025 am 02:45 AM
Concevoir une stratégie de sauvegarde de la base de données MySQL robuste
Jul 08, 2025 am 02:45 AM
Pour concevoir une solution de sauvegarde MySQL fiable, 1. Premièrement, clarifiez les indicateurs RTO et RPO, et déterminez la fréquence et la méthode de sauvegarde en fonction de la plage de temps d'arrêt et de perte de données acceptable de l'entreprise; 2. Adoptez une stratégie de sauvegarde hybride, combinant une sauvegarde logique (comme MySQLDump), une sauvegarde physique (telle que Perconaxtrabackup) et un journal binaire (binlog), pour obtenir une récupération rapide et une perte de données minimale; 3. Testez régulièrement le processus de récupération pour assurer l'efficacité de la sauvegarde et familiariser avec les opérations de récupération; 4. Faites attention à la sécurité du stockage, y compris le stockage hors site, la protection du chiffrement, la politique de rétention de version et la surveillance des tâches de sauvegarde.
