


Dans une base de données relationnelle, un index est une structure de stockage physique distincte qui trie une ou plusieurs valeurs de colonne dans une table de base de données. pour une ou plusieurs colonnes d'un tableau, ainsi qu'une liste de pointeurs logiques vers les pages de données du tableau qui identifient physiquement ces valeurs.
Le rôle de l'index est équivalent à la table des matières du livre. Vous pouvez trouver rapidement le contenu dont vous avez besoin en fonction des numéros de page clés de la table des matières, puis la base de données utilise l'index pour trouver une valeur spécifique. suit le pointeur pour trouver la ligne contenant la valeur. Il peut s'agir d'une instruction SQL correspondant à la table. Exécutez plus rapidement et accédez rapidement aux informations spécifiques dans les tables de la base de données.
InnoDB comprend trois types d'index, à savoir l'index ordinaire, l'index unique (l'index de clé primaire est un index unique spécial non vide) et l'index de texte intégral.
Réécrit comme : L'index ordinaire, également connu sous le nom d'index non unique, n'a aucune restriction. Unique : un index unique nécessite que la valeur de clé ne puisse pas être répétée (peut être vide). L'index de clé primaire est en fait un index unique spécial, mais il a également une restriction supplémentaire, qui exige que la valeur de clé ne puisse pas être vide. Les index de clé primaire sont créés avec la clé primaire. Texte intégral : pour des données relativement volumineuses, telles que des articles, des textes, des e-mails, etc., un champ peut nécessiter plusieurs Ko. Si vous souhaitez résoudre le problème de la faible efficacité d'une requête similaire dans la correspondance de texte intégral, vous pouvez créer du texte intégral. indice. Seuls les champs de type char, varchar et text peuvent créer des index de texte intégral. MyISAM et InnoDB prennent en charge l'indexation de texte intégral.
Résumé en une phrase :
L'index peut améliorer l'efficacité de la récupération des données et réduire le coût d'E/S de la base de données.
Posez une question : Nous échangeons de l'espace contre du temps, mais qu'en est-il de la structure des données, du coût des E/S des requêtes et de la manière de stocker les données
Nous utilisons un Page Let's ? regardez le processus d’évolution de notre arbre B+ d’un point de vue.
La page est l'unité de base d'InnoDB pour gérer l'espace de stockage. InnoDB stocke les données dans la base de données dans l'unité de stockage de base de la page ; c'est également l'unité de base d'interaction entre la mémoire et le disque. Les données au format page sont transférées vers la mémoire et les données au format page dans la mémoire sont également vidées sur le disque.
⼼La taille de la mémoire d'une page est de 16 Ko.
Supposons que nous voulions exécuter ce SQL et obtenir 10 enregistrements :
SELECT * FROM INNODB_USER LIMIT 0 , 10;
Si la taille des données d'un enregistrement est de 4K, alors combien de données pouvons-nous stocker dans une page ?
16K divisé par 4K donne 4 enregistrements, n'est-ce pas.
Chaque élément de données de la page a un attribut clé appelé type_enregistrement
0 Enregistrement d'utilisateur ordinaire 1 Enregistrement d'index d'annuaire 2 Minimum 3 Maximum
Dessinez une image pour montrer comment les données sont placées sur la page :

C'est notre page. Chaque page stockera les données. Stockez les données de manière ordonnée selon la clé primaire
Nous savons que le stockage des données est une E/S séquentielle, ce qui est pratique pour le stockage. , alors l'interrogation n'est pas un problème. Si vous vérifiez la dernière, devez-vous parcourir la page entière de données ?
Et si nous voulons vérifier une donnée ? Comment pouvons-nous trouver rapidement les données ?
Si les données de notre page sont connectées, pensez aux structures de données que nous avons apprises, quelle structure est la plus rapide à interroger ?
Si les données de notre page ont une méthode de connexion, cela peut être résolu ! C'est vrai, c'est la liste chaînée
Comment les données de la page Page sont connectées (les données sont dans la même page) :
MySQL connecte les données de la page via le One-way liste chaînée. Si vous effectuez une requête basée sur la clé primaire, l'utilisation du positionnement binaire sera très rapide. Si vous effectuez une requête basée sur un index de clé non primaire, vous ne pouvez parcourir la liste chaînée unidirectionnelle qu'en commençant par la plus petite.
Comment établir une connexion entre plusieurs pages (les données sont dans des pages différentes) :
MySQL relie différentes pages via une liste chaînée bidirectionnelle, afin que nous puissions trouver la page suivante via la page précédente. Recherchez une page sur la page suivante. Puisque nous ne pouvons pas localiser rapidement la page où se trouvent les données, nous ne pouvons la trouver que tout en bas de la première page le long de la liste doublement chaînée, puis suivre les étapes décrites ci-dessous. la même page dans chaque page. Méthode pour trouver l'enregistrement spécifié, il s'agit également d'une analyse complète du tableau.

Lorsqu'il y a de plus en plus de pages, quels problèmes surviendront dans la requête Comment résoudre et optimiser ?
Lorsque le nombre d'enregistrements dans notre liste chaînée augmente, parce que nous ne pouvons pas les localiser directement, nous sommes confrontés au problème de la requête lente. En y réfléchissant bien, la soi-disant requête lente est en fait les deux problèmes suivants :
.Complexité du temps de requête 0 (N)
Le nombre d'E/S à lire et à écrire sur le disque est trop important
Pensons-y, lorsque nous lisons habituellement un livre et voulons trouver des informations sur un certaine page, comment fait-on ?
Consultez le catalogue, n'est-ce pas ? Qu'est-ce qu'un annuaire ? N'est-ce pas juste un index ?
Il suffit de trouver un annuaire sur Baidu et de poster une photo :

Nous avons constaté qu'il y avait deux informations très importantes dans cet annuaire :
Introduction au contenu (titre du chapitre)
Le numéro de page
Nous avons cette idée de faire référence à la table des matières d'un livre pour atteindre notre objectif d'interroger rapidement les données :
Ajouter une table des matières aux données et vérifier les données, nous d'abord découvrez sur quelle page se trouvent les données selon la page de table des matières Où améliorer les performances des requêtes.
Mais, Question 2.3 : Comment créer un répertoire ? Créer une table des matières pour chaque page ? Faut-il être régulier dans la création d'annuaires ? Par exemple, le répertoire d'un dictionnaire est établi par ordre alphabétique. À quoi avez-vous pensé ? C'est vrai,clé primaire. La clé primaire auto-incrémentée dans Mysql répond tout simplement à nos exigences, elle a moins de contenu et n'est pas répétable. Nous stockerons la clé primaire de chaque page. Selon les règles et ajoutez un pointeur. Lors de l'interrogation, directement en fonction de la taille de la clé primaire, utilisez la méthode de dichotomie pour trouver rapidement le répertoire, puis trouver les données. Mais devons-nous créer un répertoire pour chaque page de données ? Il semble que cela soit toujours nécessaire si vous ne créez pas de données pour chaque page, comment pouvez-vous localiser les données dans la page ? S'agit-il d'une numérisation pleine page ?
Mais créez un répertoire pour chaque page. Au fur et à mesure que de plus en plus de pages de répertoire
apparaissent, nous devons parcourir chaque répertoire et les performances des requêtes diminueront également. Pouvons-nous créer un répertoire
pour le répertoire ? Ainsi, nous pouvons également créer un répertoire pour la page du répertoire et extraire une couche de nœuds racine vers le haut, ce qui nous facilitera l'interrogation.
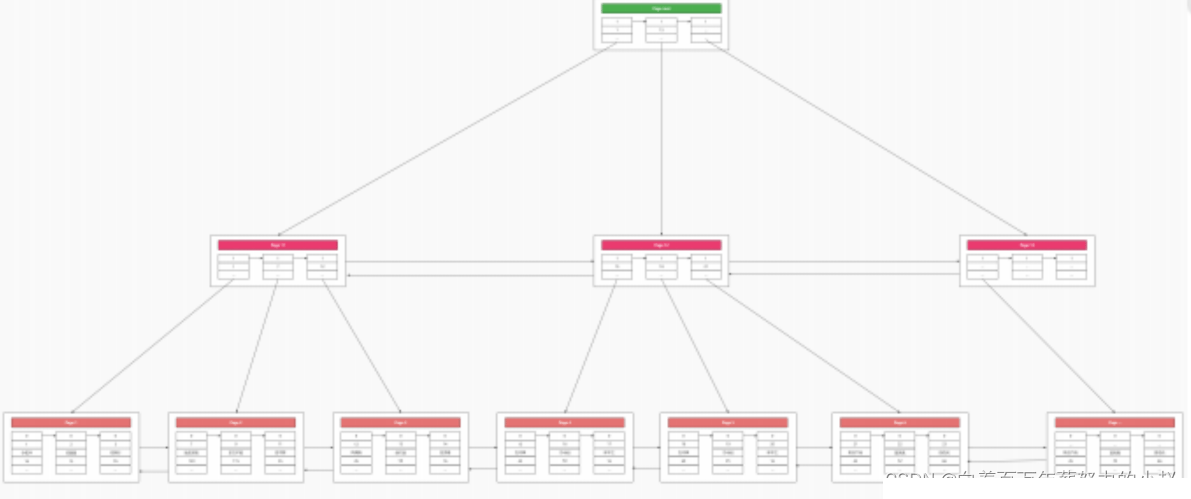 Cet arbre est
Cet arbre est
arbre d'index de clé primaire, car l'arbre d'index de clé primaire stocke toutes les données dans notre table, donc dans MySQL L'index est des données, Les données sont indexéesC'est aussi la raison. C'est la structure des données de l'arbre d'index de clé primaire MysqlB+. Qu'en est-il ? Est-ce plus impressionnant que les connaissances que vous obtenez en le mémorisant directement
2.4 Arbre d'index, fractionnement et fusion de pagesNous avons trouvé le requête améliorée En termes de performances, quels problèmes rencontrerez-vous lorsque des pages de page seront ajoutées, modifiées ou supprimées ?
augmentation ordonnée et qu'une nouvelle donnée est ajoutée ? Et les données sur la page doivent remplir une condition :
La valeur de clé primaire de l'enregistrement utilisateur dans la page de données suivante doit être supérieure à la valeur de clé primaire de l'enregistrement utilisateur dans la page précédente有序增加,新增一条数据怎么办?
页写满了,那么是不是得开启一个新页!
并且页的数据必须满足一个条件:下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值
因为是有序增加,我们直接在页的双向链表末端增加一个页即可。
那如果是无序增加Parce qu'il s'agit d'une augmentation ordonnée , on l'ajoute directement à la fin de la liste doublement chaînée de la page. Il suffit d'ajouter une page.
Augmentation non ordonnée et qu'une nouvelle donnée est ajoutée ? Résumé :
Problèmes rencontrés lors de l'ajout, de la modification et de la suppression de pages de page :Nous pouvons dire que lorsqu'il y a des opérations de mise à jour telles qu'un ajout non ordonné, une mise à jour de l'ID de clé primaire et une suppression de page d'index, il y aura un grand nombre d'arborescences. L'ajustement des nœuds déclenche la pagination et la fusion des pages du nœud feuille enfant et des pages du nœud feuille supérieur et du nœud racine, provoquant une grande fragmentation du disque et une perte de performances de la base de données, ce qui explique pourquoi nous ne devons pas construire sur des colonnes qui le sont. Index fréquemment mis à jour et modifié, ou ne mettez pas à jour la clé primaire.
Résumons :
Index clusterisé (index clusterisé) :
L'arbre d'index de clé primaire est également appelé index clusterisé ou index clusterisé Dans InnoDB, une table n'a qu'un seul arbre d'index clusterisé. Si une table crée un index de clé primaire, alors cet index de clé primaire est un index clusterisé. Nous déterminons l'ordre de stockage physique des lignes de données en fonction des valeurs clés de l'arborescence d'index clusterisé. toutes les colonnes de la table. L'index C'est-à-dire les données, et les données sont l'index, qui fait référence à notre arbre d'index de clé primaire.
Pourquoi est-il préférable que l'ID de clé primaire ait une tendance à la hausse ?
你刚刚看完啊,不会没记住吧,有序递增,下一个数据页中用户记录的主键值必须大于上一个页中用户的主键值,假如我是趋势递增,存入的数据肯定是在最末尾链表或者新增一个链表,就不会触发页的分裂与合并,导致添加的速度变慢。
三层B+数能存多少数据?
考察点:Page页的大小,B+树的定义
1GB = 1024 M, 1mb = 1024k,1k= 1024 bytes
答:
已知:索引逻辑单元 16bytes 字节,16KB=16* 1024*1024,肯定比一千万多,在InnoDB中B+树的深度为3层就能满足千万级别的数据存储。
mysql 大字段为什么要拆分?
一个Page页可存放16K的数据,大字段占用大量的存储空间,意味着一个Page页可存储的数据条数变少,那么就需要更多的页来存储,需要更多的Page,意味着树的深度会变高。那么磁盘IO的次数会增加,性能下降,查询更慢。大字段不管是否被使用都会存放在索引上,占据大量内存空间压缩Page数据条数。
为什么用B+树?
B+树的底层是多路平衡查找树,对于每一次的查询的都是从根节点触发,到子叶结点才存放数据,根节点和非叶子结点都是存放的索引指针,查找叶子结点互,可以根据键值数据查询。具备更强的扫库、扫表能力、排序能力以及查询效率和性能的稳定性,存储能力也更强,仅使用三层B+树就能存储千万级别的数据。
刚才看的是根据主键得来的索引,我们如果不查主键,或者说表里压根就没有主键,怎么办?我们还可以根据几个字段来创建联合索引(组合索引聚合索引。。哎呀名字而已怎么叫都行)。
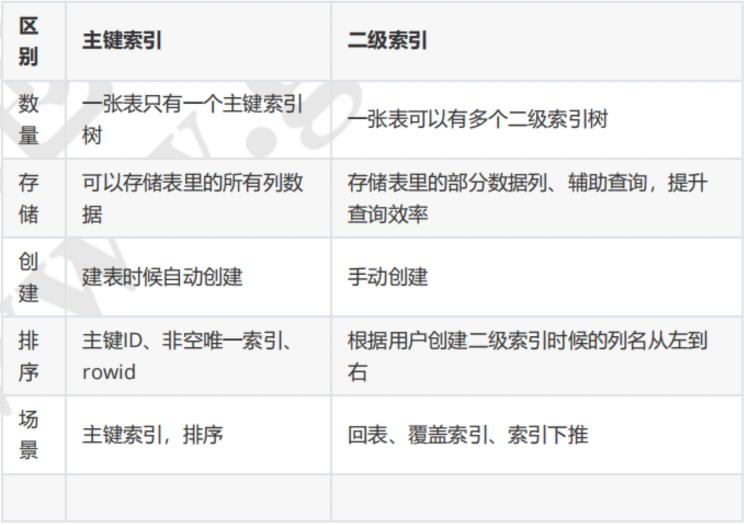
根据主键得到的索引树叫主键索引树,根据别的字段得到的索引树叫二级索引树。
通过下面的SQL 可以建立一个组合索引
ALTER TABLE INNODB_USER ADD INDEX SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name','phone');
其实,看似建立了1个索引,但是你使用 age 查询 age,user_name 查询 age,user_name,phone 都能生效
您也可以认为建立了三个这样的索引:
ALTER TABLE INNODB__USER ADD INDEX SECOND_INDEX_AGE__USERNAME_PHONE('age'); ALTER TABLE INNODB_USER ADD INDEX SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name'); ALTER TABLE `INNODB_USER`ADD INDEX SECOND_INDEX_AGE_USERNAME_PHONE('age','user_name','phone');
首先需要知道参与排序的字段类型是否有有序?
如果是有序字段,就按照有序字段排序比如(int) 1 2 3 4。
如果是无序字段,按照这个列的字符集的排序规则来排序,这点不去深入,知道就好。
我现在有一个组合索引(A-B-C)他会按照你建立字段的顺序来进行排序:
如果A相同按照B排序,如果B相同按照C排序,如果ABC全部相同,会按照聚集索引进行排序。
我们的Page会根据组合索引的字段建立顺序来存储数据,年龄 用户名 手机号。
它的数据结构其实是一样的
还是上面那个索引,年龄用户名手机号,age,username,phone
那么可以看到我们第一个字段是AGE,如果需要这个索引生效,是不是在查询的时候需要先使用Age查询,然后如果还需要user_name,就使用user_name。
只使用了user_name 能使用到索引吗?
其实是不行的,因为我是先使用age进行排序的,你必须先命中age,再命中user_name,再命中phone,这个其实
就是我们所说的最左匹配原则。
最左其实就是因为我们是按照组合索引的顺序来存储的。大家常说的"索引桥"也是这个原因。在命中组合索引中,必须像过桥一样,先跨过第一块木板,再到第二块木板,最后到第三块木板。
二级索引树有三个重要的概念,分别是回表、覆盖索引、索引下推。.
回表就是:我们查询的数据不在二级索引树中需要拿到ID去主键索引树找的过程。
覆盖索引就是:我们需要查询的数据都在二级索引树中,直接返回这种情况就叫做覆盖索引。
索引下推(index condition pushdown )简称ICP:在Mysql5.6以后的版本上推出,用于优化回表查询;
为什么离散度低的列不走索引?
Quelle est la notion de dispersion ? Plus les données sont identiques, plus la dispersion est faible, et moins les données sont identiques, plus la dispersion est élevée.
Ils ont tous les mêmes données, comment les trier ? Vous n'arrivez pas à trier ?
Il y a trop de valeurs en double dans B+Tree. Lorsque l'optimiseur MySQL constate que l'indexation est presque la même que l'utilisation d'une analyse complète de table, elle ne fonctionnera pas même si l'index est créé. L'utilisation ou non de l'index est décidée par l'optimiseur MySQL.
Plus il y a d'index, mieux c'est ?
En termes d'espace : Échangez de l'espace contre du temps, et l'index doit occuper de l'espace disque.
Heure : Appuyez sur l'index pour accélérer l'efficacité de nos requêtes. S'il s'agit d'une mise à jour et d'une suppression, cela entraînera le fractionnement et la fusion des pages, affectant le temps de réponse d'insertion et de mise à jour. déclarations, mais ralentissant les performances.
S'il s'agit d'une colonne qui doit être mise à jour fréquemment, il n'est pas recommandé de créer un index car cela déclenche fréquemment le fractionnement et la fusion de pages.
Également appelé index combiné (index composite), l'arbre d'index secondaire stocke l'ordre des noms de colonnes lorsque nous créons l'index To. store, il n'enregistre qu'une partie des données utilisées pour créer les noms de colonnes d'index secondaire. L'arborescence d'index secondaire est née pour nous aider dans les requêtes et améliorer l'efficacité des requêtes. Il y a trois actions dans l'arborescence d'index secondaire : le retour de table, l'index de couverture et. indexation. Parmi eux, le plus performant est l’indice de couverture.
J'ai trouvé une image de différence en ligne
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



