


Redis est un service TCP en mode client-serveur, également connu sous le nom d'implémentation Requête/Réponse de le protocole. client-server模式的TCP服务,也被称为Request/Response协议的实现。

这意味着通常一个请求的完成是遵循下面两个步骤:
Client发送一个操作命令给Server,从TCP的套接字Socket中读取Server的响应值,通常来说这是一种阻塞的方式
Server执行操作命令,然后将响应值返回给Client
举个例子
Client: INCR X Server: 1 Client: INCR X Server: 2 Client: INCR X Server: 3 Client: INCR X Server: 4
Clients和Servers是通过网络进行连接。网络连接速度可能会快得很快(例如本地回环网络)或者慢得很慢(例如跨越多个主机的网络)。不管网络怎么样,一个数据包从Client到Server,然后相应值又从Server返回Client都需要一定的时间。
这个时间被称为RTT(Round Trip Time)。当一个Client需要执行多个连续请求(比如添加许多个元素到一个list中,或者清掉Redis中许多个键值对),那么RTT是怎样影响到性能的呢?这个也是很方便去计算的。比如如果RTT的时间为250ms(假设互联网连接速度非常慢),即使Server可以每秒处理100k个请求,那么最多也只能接受每秒4个请求。
如果是回环网络,RTT将会特别的短(比如作者的127.0.0.1,RTT的响应时间为44ms),但是对于执行连续多次写操作时,也是一笔不小的消耗。
其实我们有其他办法来降低这种场景的消耗,开心不?惊喜不?
在一个Request/Response方式的服务中有一个特性:即使Client没有收到之前的响应值,也可以继续发送新的请求。这种特性意味着我们可以不需要等待Server的响应,可以率先发送许多操作命令给Server,然后在一次性读取Server的所有响应值。
这种方式被称为Pipelining技术,该技术近几十年来被广泛的使用。比如多POP3协议的实现就支持这个特性,大大的提升了从server端下载新的邮件的速度。
Redis在很早的时候就支持该项技术,所以不管你运行的是什么版本,你都可以使用pipelining技术,比如这里有一个使用 netcat 工具的:
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379 +PONG +PONG +PONG
现在我们不需要为每一次请求付出RTT的消耗了,而是一次性发送三个操作命令。为了便于直观的理解,还是拿之前的说明,使用pipelining技术该的实现顺序如下:
Client: INCR X Client: INCR X Client: INCR X Client: INCR X Server: 1 Server: 2 Server: 3 Server: 4
划重点(敲黑板):当client使用pipelining发送操作命令时,server端将强制使用内存来排列响应结果。所以在使用pipelining发送大量的操作命令的时候,最好确定一个合理的命令条数,一批一批的发送给Server端,比如发送10k个操作命令,读取响应结果,再发送10k个操作命令,以此类推…虽然说耗时近乎相同,但是额外的内存消耗将是这10k操作命令的排列响应结果所需的最大值。(为防止内存耗尽,选择一个合理的值)
Pipelining不是减少因为 RTT 造成消耗的唯一方式,但是它确实帮助你极大的提升每秒的执行命令数量。事实的真相是:从访问相应的数据结构并且生成答复结果的角度来看,不使用pipelining确实代价很低;但是从套接字socket I/O的角度来看,恰恰相反。因为这涉及到了read()和write()调用,需要从用户态切换到内核态。这种上下文切换会特别损耗时间的。
一旦使用了pipelining技术,很多操作命令将会从同一个read()调用中执行读操作,大量的答复结果将会被分发到同一个write()调用中执行写操作。基于此,随着管道的长度增加,每秒执行的查询数量最开始几乎呈直线型增加,直到不使用pipelining技术的基准的10倍,如下图:
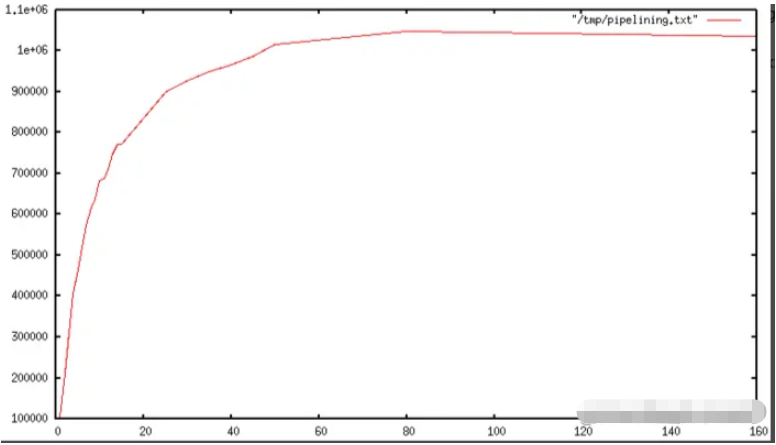
不翻译,基本上就是说使用了pipelining
#🎜🎜##🎜🎜#Cela signifie qu'en général, une requête est complétée en suivant les deux étapes suivantes : #🎜🎜#FOR-ONE-SECOND:
Redis.SET("foo","bar")
ENDRequête/Réponse : même si le Client ne reçoit pas la valeur de réponse précédente, il peut Continuez à envoyer de nouvelles demandes. Cette fonctionnalité signifie que nous n'avons pas besoin d'attendre la réponse du serveur. Nous pouvons d'abord envoyer de nombreuses commandes d'opération au serveur, puis lire toutes les valeurs de réponse du serveur en même temps. #🎜🎜##🎜🎜#Cette méthode est appelée technologie Pipelining, qui a été largement utilisée au cours des dernières décennies. Par exemple, la mise en œuvre de plusieurs protocoles POP3 prend en charge cette fonctionnalité, ce qui améliore considérablement la vitesse de téléchargement des nouveaux e-mails depuis le serveur. #🎜🎜##🎜🎜#Redis a pris en charge cette technologie très tôt, donc quelle que soit la version que vous utilisez, vous pouvez utiliser la technologie pipelining Par exemple, voici un outil utilisant netcat :#. 🎜🎜#rrreee#🎜🎜#Maintenant, nous n'avons plus besoin de payer RTT pour chaque demande, mais envoyez trois commandes d'opération à la fois. Afin de faciliter la compréhension intuitive, reprenons l'explication précédente et utilisons la technologie pipelining La séquence d'implémentation est la suivante : #🎜🎜#rrreee#🎜🎜# Highlight (frapper au tableau) : Quand. le client utilise le pipelineliningLors de l'envoi d'une commande d'opération, le serveur forcera l'utilisation de la mémoire pour organiser les résultats de la réponse. Par conséquent, lorsque vous utilisez le pipelining pour envoyer un grand nombre de commandes d'opération, il est préférable de déterminer un nombre raisonnable de commandes et de les envoyer au serveur par lots, par exemple en envoyant 10 000 commandes d'opération et en lisant la réponse. résultats. , puis envoyez 10 000 commandes d'opération, et ainsi de suite... Bien que la consommation de temps soit presque la même, la consommation de mémoire supplémentaire sera la valeur maximale requise pour le résultat de réponse de l'arrangement de ces 10 000 commandes d'opération. (Pour éviter l'épuisement de la mémoire, choisissez une valeur raisonnable)#🎜🎜##🎜🎜#Ce n'est pas seulement une question de RTT#🎜🎜##🎜🎜# La seule façon de provoquer une consommation, mais cela vous aide à augmenter considérablement le nombre de commandes exécutées par seconde. La vérité est la suivante : du point de vue de l'accès à la structure de données correspondante et de la génération du résultat de la réponse, ne pas utiliser le pipelining est en effet très bon marché, mais du point de vue des E/S des sockets, c'est exactement le cas ; au contraire. Comme cela implique des appels read() et write(), vous devez passer du mode utilisateur au mode noyau. Ce type de changement de contexte prendra particulièrement du temps. #🎜🎜##🎜🎜#Une fois la technologie pipelining utilisée, de nombreuses commandes d'opération effectueront des opérations de lecture à partir du même appel read(), et un grand nombre de réponses les résultats seront envoyés au même appel write() pour effectuer l'opération d'écriture. Sur cette base, à mesure que la longueur du pipeline augmente, le nombre de requêtes exécutées par seconde augmente initialement de manière presque linéaire jusqu'à atteindre 10 fois la ligne de base sans utiliser la technologie de pipelining, comme indiqué ci-dessous : #🎜🎜# # 🎜🎜##🎜 🎜##🎜🎜#Quelques exemples de code réels#🎜🎜##🎜🎜# Sans traduction, cela signifie essentiellement que l'utilisation du pipelining améliore les performances de 5 fois. #🎜🎜#Redis Scripting(2.6+版本可用),通过使用在Server端完成大量工作的脚本Scripting,可以更加高效的解决大量pipelining用例。使用脚本Scripting的最大好处就是在读和写的时候消耗更少的性能,使得像读、写、计算这样的操作更加快速。(当client需要写操作之前获取读操作的响应结果时,pepelining就显得相形见拙。) 有时候,应用可能需要在使用pipelining时,发送 EVAL 或者 EVALSHA 命令,这是可行的,并且Redis明确支持这么这种SCRIPT LOAD命令。(它保证可可以调用 EVALSHA 而不会有失败的风险)。
读完全文,你可能还会感到疑问:为什么如下的Redis测试基准 benchmark 会执行这么慢,甚至在Client和Server在一个物理机上也是如此:
FOR-ONE-SECOND:
Redis.SET("foo","bar")
END毕竟Redis进程和测试基准benchmark在相同的机器上运行,并且这是没有任何实际的延迟和真实的网络参与,不就是消息通过内存从一个地方拷贝到另一个地方么? 原因是进程在操作系统中并不是一直运行。真实的情景是系统内核调度,调度到进程运行,它才会运行。比如测试基准benchmark被允许运行,从Redis Server中读取响应内容(与最后一次执行的命令相关),并且写了一个新的命令。这时命令将在回环网络的套接字中,但是为了被Redis Server读取,系统内核需要调度Redis Server进程(当前正在系统中挂起),周而复始。所以由于系统内核调度的机制,就算是在回环网络中,仍然会涉及到网络延迟。 简言之,在网络服务器中衡量性能时,使用回环网络测试并不是一个明智的方式。应该避免使用此种方式来测试基准。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Logiciel de base de données couramment utilisé
Logiciel de base de données couramment utilisé
 Que sont les bases de données en mémoire ?
Que sont les bases de données en mémoire ?
 Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
 Comment utiliser Redis comme serveur de cache
Comment utiliser Redis comme serveur de cache
 Comment Redis résout la cohérence des données
Comment Redis résout la cohérence des données
 Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
 Quelles données le cache Redis stocke-t-il généralement ?
Quelles données le cache Redis stocke-t-il généralement ?
 Quels sont les 8 types de données de Redis
Quels sont les 8 types de données de Redis








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



