


Le CVPR annuel ouvrira officiellement ses portes à Vancouver, au Canada, du 18 au 22 juin.
Chaque année, des milliers de chercheurs et ingénieurs CV du monde entier se réunissent pour le Sommet. Cette prestigieuse conférence remonte à 1983 et représente le summum du développement de la vision par ordinateur.
Actuellement, l'indice h5 du CVPR se classe au quatrième rang parmi toutes les conférences ou publications, juste derrière "Nature", "Science" et "New England Journal of Medicine".

Il y a quelque temps, le CVPR a annoncé les résultats de l'acceptation des papiers. Selon les statistiques publiées sur le site officiel, un total de 9 155 articles ont été acceptés, 2 359 ont été acceptés et le taux d'acceptation était de 25,8 %.
De plus, 12 articles candidats primés ont également été annoncés. Alors, quels sont les temps forts du CVPR de cette année ? Quelles tendances pouvons-nous observer dans le domaine du CV à partir des articles acceptés ?
sera annoncé prochainement. 
La startup Voxel51 a analysé la liste de tous les articles acceptés.
Regardons d'abord un diagramme récapitulatif du titre de l'article. La taille de chaque mot est proportionnelle à la fréquence d'apparition dans l'ensemble de données.
Brève description
#🎜🎜 # - 2359 articles acceptés (9155 articles soumis)
- 2359 articles acceptés (9155 articles soumis)
- 1724 articles Arxiv# 🎜🎜## 🎜🎜# - 68 documents soumis à d'autres adresses
Auteur de chaque article
#🎜 🎜#- L'auteur moyen d'un article CVPR est d'environ 5,4 personnes
- Le plus grand nombre d'auteurs parmi les articles sont : "Pourquoi le gagnant le meilleur ?" Il y a 125 auteurs
- 13 articles n'ont qu'un seul auteur.
Catégorie principale d'Arxiv
Parmi 1724 articles Arxiv, il y a 1545 articles, soit près de 90% des articles, citant cs.CV comme catégorie principale.
cs.LG s'est classé deuxième avec 101 articles. eess.IV (26) et cs.RO (16) obtiennent également une part du gâteau.
Les autres catégories d'articles CVPR incluent : cs.HC, cs.CV, cs.AR, cs.DC, cs.NE, cs.SD, cs.CL , cs.IT, cs.CR, cs.AI, cs.MM, cs.GR, eess.SP, eess.AS, math.OC, math.NT, physical.data-an et stat.ML.
「Meta」data
-「Dataset」et deux mots « modèle » sont apparus ensemble dans 567 résumés. « Ensemble de données » apparaît seul dans 265 résumés d'articles, tandis que « modèle » apparaît seul 613 fois. Seuls 16,2 % des articles acceptés par le CVPR ne contenaient pas ces deux mots.
- Selon les résumés des articles du CVPR, les ensembles de données les plus populaires cette année sont ImageNet (105), COCO (94), KITTI (55) et CIFAR (36).
- 28 articles ont proposé un nouveau "benchmark".
Les abréviations abondent
Il ne semble pas y avoir d'acronyme Il y a pas de projet d'apprentissage automatique sans mots. Parmi les 2 359 articles, 1 487 ont des titres comportant de multiples abréviations ou des mots composés en majuscules, soit 63 %.
Certains de ces acronymes sont faciles à retenir et sortent même de la langue :
- CLAMP : apprentissage contrastif basé sur des invites pour connecter le langage et la pose animaleCLAMP
- PATS : transport de zone de patch avec subdivision pour les fonctionnalités locales Matching
- CIRCLE : Capture dans des environnements contextuels riches
Certains sont beaucoup plus complexes :
- SIEDOB : Édition d'images sémantiques en démêlant l'objet et l'arrière-plan
- FJMP : Multi-Agent Joint Factorisé Prédiction de mouvement sur des graphiques d'interaction acycliques dirigés apprisFJMP
Certains d'entre eux semblent avoir emprunté des idées à d'autres en termes de construction d'acronymes :
- SCOTCH et SODA : un cadre de détection d'ombres vidéo pour transformateur (marque néerlandaise populaire Scotch & Soda )
- EXCALIBUR : Encourager et évaluer l'exploration incarnée (Ex bâton de curry, rire)
En plus des titres papier en 2023, nous avons exploré tous les titres papier acceptés en 2022. À partir de ces deux listes, nous avons calculé la fréquence relative de divers mots-clés pour vous donner une compréhension plus approfondie de ce qu'est une tendance à la hausse et à la baisse.
En 2023, les modèles de diffusion dominent. Avec la popularité des modèles de génération d’images tels que Stable Diffusion et Midjourney, il n’est pas surprenant que le développement de modèles de diffusion soit une tendance en vogue.
Les modèles de diffusion ont également des applications dans le débruitage, l'édition d'images et le transfert de style. En additionnant tout cela, c'est de loin le plus grand gagnant toutes catégories confondues, en hausse de 573 % d'une année sur l'autre. 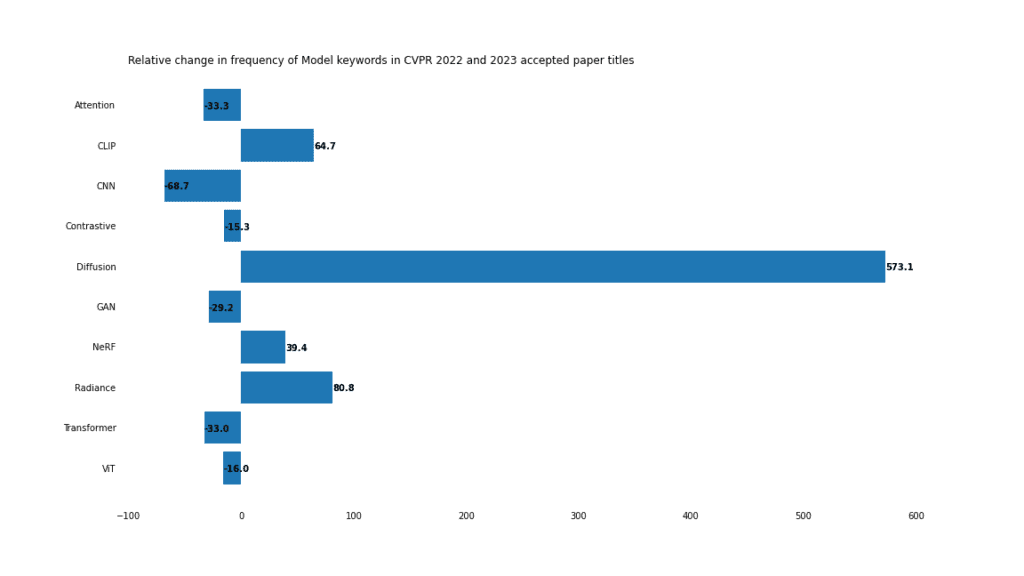
Champ de rayonnement
Le champ de rayonnement neuronal (NERF) devient également de plus en plus populaire. L'utilisation du mot «radiance» dans les journaux a augmenté de 80% et «NERF» de 39%. NeRF est passé de la preuve de concept à l'optimisation des processus d'édition, d'application et de formation.
Transformers
Le déclin de l'utilisation de "Transformer" et "ViT" ne signifie pas que le modèle Transformer est obsolète, mais reflète la domination de ces modèles en 2022. En 2021, le mot « Transformer » est apparu dans seulement 37 journaux. En 2022, ce nombre atteindra 201. Les transformateurs ne vont pas disparaître de si tôt.
CNN
CNN, autrefois le chouchou de la vision par ordinateur, semble avoir perdu son avantage en 2023, avec une utilisation en baisse de 68 %. De nombreux titres mentionnant CNN mentionnent également d’autres modèles. Par exemple, ces articles mentionnent CNN et Transformer :
- Lite-Mono : une architecture légère de CNN et de transformateur pour une estimation de profondeur monoculaire auto-superviséeLite-Mono
- Compression d'image apprise avec des architectures mixtes transformateur-CNN Task
Les tâches de masque combinées à la modélisation d'images masquées dominent le CVPR.
Les tâches discriminantes traditionnelles telles que la détection, la classification et la segmentation ne sont pas tombées en disgrâce, mais leur part dans le CV diminue en raison d'une série d'avancées dans les applications génératives, notamment l'essor de « l'édition », de la « synthèse » et de la « génération ». ". Ce.
Masque
Le mot-clé « masque » a augmenté de 263 % par rapport à la même période de l'année dernière, apparaissant 92 fois dans les journaux acceptés en 2023, apparaissant parfois 2 fois dans un titre.
- SIM : génération de masque d'instance sémantique pour la segmentation d'instance supervisée par boîteSIM
- DynaMask : sélection dynamique de masque pour la segmentation d'instanceDynaMask
Mais la majorité (64%) fait en fait référence aux tâches de "codage", dont 8 tâches "Mask Image Modeling" et 15 "Mask Autoencoder". De plus, « masque » apparaît dans 8 articles.
Il convient également de noter que les 3 titres de papier avec le mot « masque » font en réalité référence à la tâche « sans masque ».
Zero-shot vs small-shot
Avec l'essor de l'apprentissage par transfert, des méthodes génératives, des astuces et des modèles généraux, l'apprentissage « zéro-shot » attire de plus en plus l'attention. Dans le même temps, l’apprentissage « sur petit échantillon » a diminué par rapport à l’année dernière. Cependant, en termes de chiffres bruts, du moins pour l'instant, le « petit échantillon » (45) a un léger avantage sur « l'échantillon zéro » (35).
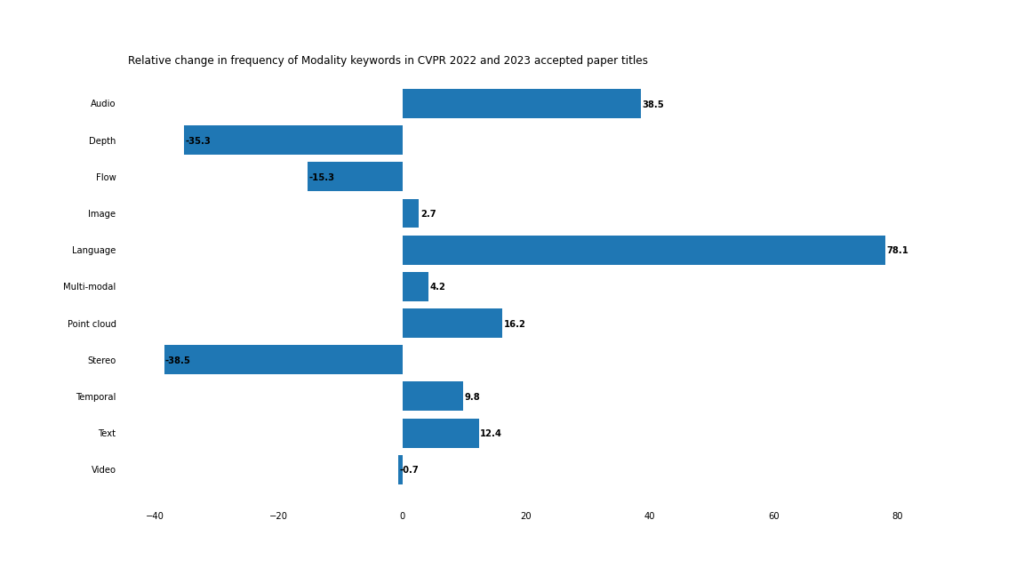
En 2023, les applications multimodales et crossmodales vont accélérer leur développement.
Frontières floues
Alors que la fréquence des mots-clés traditionnels de vision par ordinateur tels que « image » et « vidéo » reste relativement inchangée, « texte »/« langage » et « audio » apparaissent plus fréquemment.
Même si le mot « multimodal » lui-même n'apparaît pas dans le titre de l'article, il est difficile de nier que la vision par ordinateur se dirige vers un avenir multimodal.
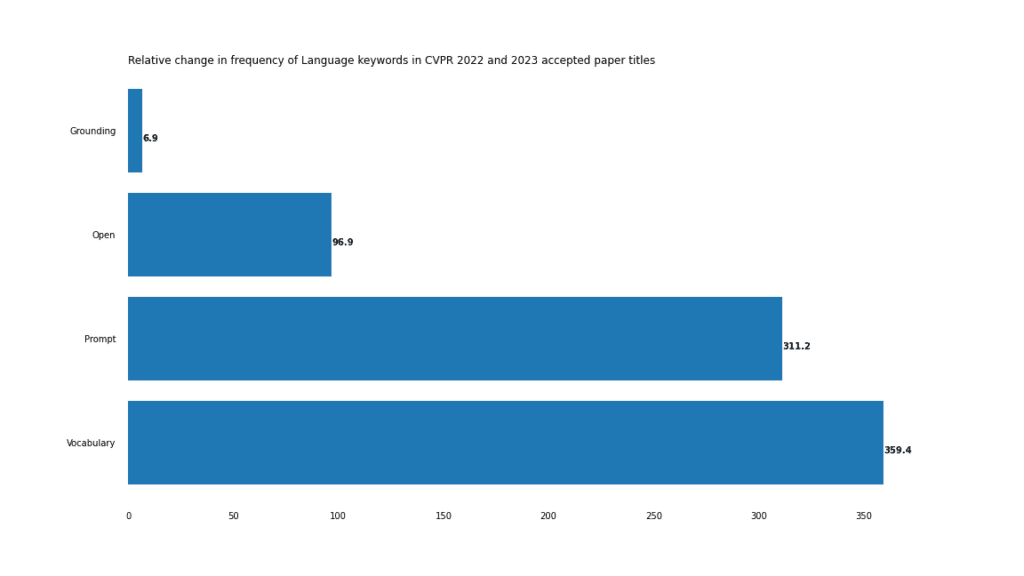
Cela est particulièrement évident dans les tâches visuo-verbales, comme le montre la forte augmentation de l'Open, de l'invite et du vocabulaire.
L'exemple le plus extrême de cette situation est le mot composé « vocabulaire ouvert », qui n'est apparu que 3 fois en 2022, mais 18 fois en 2023.
Creusez en profondeur les mots-clés dans les titres des articles du CVPR 2023
Point Cloud 9
Les applications de vision par ordinateur 3D déduisent des informations 3D ("profondeur" et "profondeur") des images 2D « stéréoscopiques ») se sont tournées vers des systèmes de vision par ordinateur fonctionnant directement sur des données de nuages de points 3D.
Toute couverture complète des sujets liés à l'apprentissage automatique en 2023 serait incomplète sans inclure ChatGPT dans le mix. Nous avons décidé de garder les choses intéressantes et avons utilisé ChatGPT pour trouver les titres les plus créatifs du CVPR 2023.
Pour chaque article téléchargé sur Arxiv, nous avons récupéré le résumé et demandé à ChatGPT (API GPT-3.5) de générer un titre pour l'article CVPR correspondant.
Ensuite, nous prenons ces titres générés par ChatGPT et les titres papier réels, générons des vecteurs d'intégration à l'aide du modèle text-embedding-ada-002 d'OpenAI et calculons le cosinus entre les titres générés par ChatGPT et les titres générés par l'auteur. .
Qu'est-ce que cela peut nous dire ? Plus ChatGPT est proche du titre réel de l'article, plus le titre sera prévisible. En d’autres termes, plus les prédictions de ChatGPT sont « biaisées », plus l’auteur est « créatif » en nommant l’article.
L'intégration et la similarité cosinus nous fournissent une méthode de quantification intéressante, quoique loin d'être parfaite.
Nous avons trié les papiers selon cette métrique. Sans plus tarder, voici les titres les plus créatifs :
Titre réel : Tracking Every Thing in the Wild
Titre prévu : Démêler la classification du suivi : présentation de TETA pour une analyse comparative complète du suivi d'objets multiples multicatégories
Titre réel : Apprendre à amorcer pour lutter contre le bruit des étiquettes
Titre prévu : Objectif de perte apprenable pour la repondération des instances conjointes et des étiquettes dans les réseaux neuronaux profonds
Titre réel : Voir une rose de cinq mille façons
Titre prédit : Les intrinsèques des objets d'apprentissage à partir d'images Internet uniques pour un rendu visuel et une synthèse supérieurs
Titre réel : Pourquoi le gagnant est-il le meilleur ?
Titre prédit : Analyse des stratégies gagnantes dans les concours internationaux d'analyse comparative pour l'analyse d'images : aperçus de une étude multicentrique de l'IEEE ISBI et du MICCAI 2021
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment définir la zone de texte en lecture seule
Comment définir la zone de texte en lecture seule
 Les mots disparaissent après avoir tapé
Les mots disparaissent après avoir tapé
 Comment taper l'inscription sur le cercle de la pièce ?
Comment taper l'inscription sur le cercle de la pièce ?
 Comment créer un clone WeChat
Comment créer un clone WeChat
 Introduction aux touches de raccourci de capture d'écran dans Win8
Introduction aux touches de raccourci de capture d'écran dans Win8
 Comment conserver deux décimales en C++
Comment conserver deux décimales en C++
 Utilisation de la fonction étage
Utilisation de la fonction étage
 jsonp résout les problèmes inter-domaines
jsonp résout les problèmes inter-domaines








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



