


Un article de synthèse récent « Trajectory-Prediction With Vision: A Survey » provient de Hyundai et de la société Motional d'Aptiv, cependant, il fait référence à l'article de synthèse « Vision-based Intention and Trajectory Prediction in Autonomous Vehicles: A Survey » de l'Université d'Oxford ;
La tâche de prédiction est essentiellement divisée en deux parties : 1) L'intention, qui est une tâche de classification qui pré-conçoit un ensemble de classes d'intention pour l'agent, elle est généralement considérée comme un problème d'apprentissage supervisé et les intentions de classification possibles de celui-ci ; l'agent doit être marqué ; 2) la trajectoire, qui nécessite de prédire un ensemble de positions possibles de l'agent dans les trames futures ultérieures, appelées waypoints ; cela constitue l'interaction entre les agents et entre les agents et les routes ;
Les modèles de prédiction de comportement précédents peuvent être divisés en trois catégories : les modèles basés sur la physique, les modèles basés sur les manœuvres et les modèles de perception d'interaction. Cette phrase peut être réécrite ainsi : À l'aide des équations dynamiques du modèle physique, des mouvements artificiellement contrôlables sont conçus pour différents types d'agents. Cette méthode ne peut pas modéliser les états potentiels de la situation dans son ensemble, mais se concentre généralement uniquement sur un agent spécifique. Cependant, avant l’apprentissage profond, cette tendance était SOTA. Les modèles basés sur les manœuvres sont des modèles basés sur le type de mouvement attendu par l'agent. Un modèle sensible aux interactions est généralement un système basé sur l'apprentissage automatique qui effectue une inférence par paire pour chaque agent de la scène et génère des prédictions sensibles aux interactions pour tous les agents dynamiques. Il existe un degré élevé de corrélation entre les différentes cibles d’agents proches de la scène. La modélisation de modules d’attention complexes sur la trajectoire des agents peut conduire à une meilleure généralisation.
La prévision d'actions ou d'événements futurs peut être exprimée implicitement, ou sa trajectoire future peut être explicite. Les intentions de l'agent peuvent être affectées par : a) les propres croyances ou souhaits de l'agent (qui ne sont souvent pas observés et donc difficiles à modéliser) ; b) les interactions sociales, qui peuvent être modélisées de différentes manières, par exemple le pooling, les réseaux de neurones graphiques, l'attention. , etc. ; c) les contraintes environnementales, telles que le tracé des routes, qui peuvent être codées via des cartes haute définition (HD) ; d) les informations d'arrière-plan sous la forme de trames d'images RVB, de nuages de points lidar, de flux optique, de figures de segmentation, etc. La prédiction de trajectoire, en revanche, est un problème plus difficile car elle implique des problèmes de régression (continue) plutôt que de classification, contrairement à la reconnaissance d'intention.
La trajectoire et l'intention doivent commencer par la conscience de l'interaction. Une hypothèse raisonnable est que lorsqu’on tente de conduire de manière agressive sur une autoroute à fort trafic, un véhicule qui passe peut freiner brusquement. Modélisation. Il est préférable de modéliser dans l'espace BEV, qui permet la prédiction de trajectoire, mais aussi dans la vue image (aussi appelée perspective). Cette phrase peut être réécrite comme suit : "Cela est dû au fait que les régions d'intérêt (RoI) peuvent être attribuées sous la forme d'une grille à une plage de distance dédiée.". Cependant, en raison de la ligne de fuite en perspective, la perspective de l’image peut théoriquement étendre le RoI à l’infini. L'espace BEV est plus adapté à la modélisation de l'occlusion car il modélise le mouvement de manière plus linéaire. En effectuant une estimation d'attitude (translation et rotation du propre véhicule), la compensation du propre mouvement peut être effectuée simplement. De plus, cet espace préserve le mouvement et l'échelle de l'agent, c'est-à-dire que les véhicules environnants occuperont le même nombre de pixels BEV quelle que soit leur distance par rapport au véhicule lui-même, mais ce n'est pas le cas de la perspective de l'image ; Pour prédire l’avenir, il faut comprendre le passé. Cela peut généralement être fait via le suivi, ou cela peut être fait avec des fonctionnalités BEV agrégées historiques.
La figure suivante montre certains composants et diagramme de flux de données du modèle de prédiction :
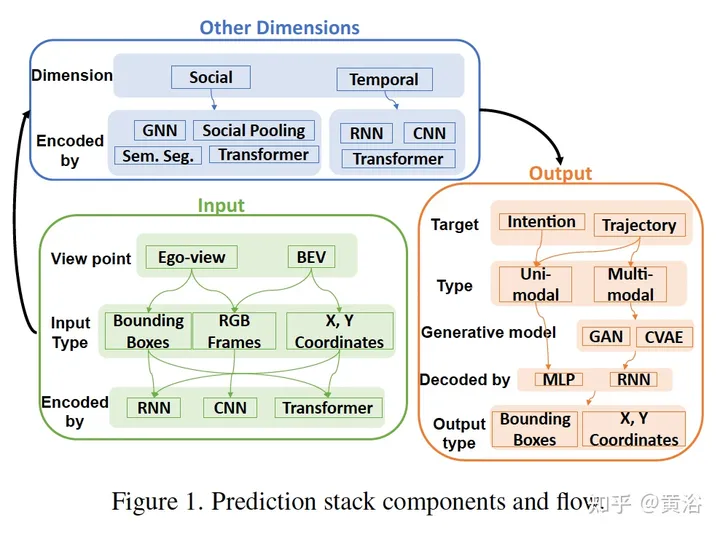
Le tableau suivant est un résumé du modèle de prédiction :
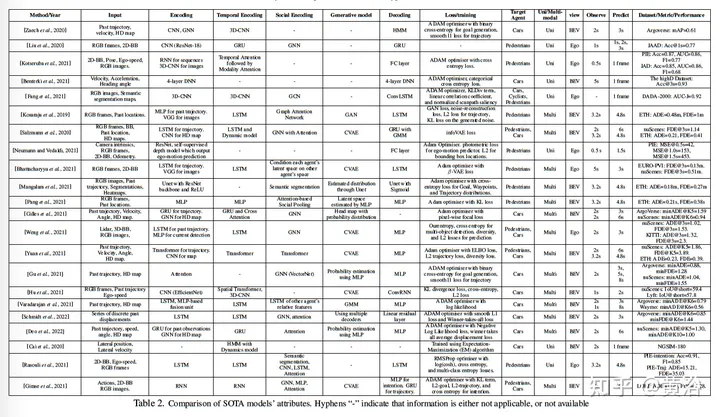
Ce qui suit traite essentiellement du modèle de prédiction à partir de l'entrée/ sortie :
1) Tracklets : Le module de perception prédit l'état actuel de tous les agents dynamiques. Cet état comprend le centre 3D, les dimensions, la vitesse, l'accélération et d'autres attributs. Les trackers peuvent exploiter ces données et établir des associations temporaires afin que chaque tracker puisse conserver un historique de l'état de tous les agents. Désormais, chaque tracklet représente les mouvements passés de l'agent. Cette forme de modèle prédictif est la plus simple puisque son entrée consiste uniquement en des trajectoires clairsemées. Un bon tracker est capable de suivre un agent même s'il est masqué dans la trame actuelle. Étant donné que les trackers traditionnels sont basés sur des réseaux sans apprentissage automatique, il devient très difficile de mettre en œuvre un modèle de bout en bout.
2) Données brutes du capteur : Il s'agit d'une méthode de bout en bout. Le modèle obtient des informations brutes sur les données du capteur et prédit directement la prédiction de trajectoire de chaque agent dans la scène. Cette méthode peut disposer ou non de sorties auxiliaires et de leurs pertes pour encadrer des entraînements complexes. L’inconvénient de ce type d’approche est que l’entrée nécessite beaucoup d’informations et est coûteuse en calcul. Cela est dû à la fusion des trois problèmes de perception, de suivi et de prédiction, ce qui rend le modèle difficile à développer et encore plus difficile à réaliser la convergence.
3) Caméra contre BEV : la méthode BEV traite les données à partir d'une vue de dessus semblable à une carte, et l'algorithme de prédiction de la caméra perçoit le monde du point de vue du véhicule autonome. Ce dernier est généralement plus difficile que le premier. pour un certain nombre de raisons : premièrement, la détection à partir du BEV permet d'obtenir un champ de vision plus large et des informations de prédiction plus riches. En comparaison, le champ de vision de la caméra est plus court, ce qui limite la plage de prédiction car la voiture ne peut pas planifier en dehors du champ de vision. de plus, la caméra est plus susceptible d'être bloquée, elle est donc différente de la méthode basée sur la caméra. Par rapport à d'autres méthodes, la méthode BEV souffre de moins de problèmes d'« observabilité partielle » ; deuxièmement, à moins que les données lidar ne soient disponibles, la vision monoculaire ; il est difficile pour l'algorithme de déduire la profondeur de l'agent en question, ce qui est un indice important pour prédire son comportement ; enfin, la caméra est en mouvement, ce qui nécessite de traiter le mouvement de l'agent et du véhicule lui-même, ce qui est différent ; à partir du BEV statique ; mention : Comme lacune, la méthode de représentation BEV présente toujours le problème des erreurs accumulées, bien qu'il y ait un problème dans le traitement de la vue de la caméra. Il y a des défis inhérents, mais elle est toujours plus pratique que les BEV, et les voitures sont rarement avoir accès à des caméras qui montrent l'emplacement des BEV et qui surveillent les agents sur la route. La conclusion est que le système de prédiction devrait être capable de voir le monde du point de vue du véhicule autonome, y compris les caméras lidar et/ou stéréo, dont les données peuvent être avantageuses pour percevoir le monde en 3D. temps si l'attention doit être incluse Lors de la prévision de la position de l'agent, il est préférable d'utiliser la position de la boîte englobante plutôt que le point central pur, car les coordonnées de la première impliquent également des changements dans la distance relative entre le véhicule et le piéton. comme le mouvement propre de la caméra ; en d'autres termes, comme l'agent. À mesure que le corps s'approche du véhicule propre, la boîte englobante devient plus grande, fournissant une estimation supplémentaire (bien que préliminaire) de la profondeur.
4) Prédiction du mouvement autonome : modélisez le mouvement du véhicule autonome pour générer une trajectoire plus précise. D'autres approches utilisent des réseaux profonds ou des modèles dynamiques pour modéliser le mouvement de l'agent d'intérêt, en exploitant des quantités supplémentaires calculées à partir de l'entrée de l'ensemble de données, telles que les poses, le flux optique, les cartes sémantiques et les cartes thermiques.
5) Encodage dans le domaine temporel : étant donné que l'environnement de conduite est dynamique et qu'il existe de nombreux agents actifs, il est nécessaire d'encoder dans la dimension temporelle de l'agent pour construire un meilleur système de prédiction qui relie ce qui s'est passé dans le passé avec ce qui se passera dans le passé. l'avenir jusqu'au présent Connecter les choses ensemble ; savoir d'où vient l'agent peut aider à deviner où l'agent pourrait aller ensuite. La plupart des modèles basés sur des caméras traitent des échelles de temps plus courtes, tandis que pour des échelles de temps plus longues, les modèles prédictifs nécessitent une structure plus complexe.
6) Encodage social : Pour relever le défi « multi-agents », la plupart des algorithmes les plus performants utilisent différents types de réseaux de neurones graphiques (GNN) pour encoder les interactions sociales entre agents. La plupart des méthodes encodent le temps séparément et les dimensions sociales ; - soit commencer par la dimension temporelle puis considérer la dimension sociale, soit dans l'ordre inverse il existe un modèle basé sur Transformer qui peut coder les deux dimensions simultanément ;
7) Prédiction basée sur les objectifs attendus : les prédictions d'intention comportementale, comme le contexte de la scène, sont généralement affectées par différents objectifs attendus et doivent être déduites par explication pour les prédictions futures conditionnées par les objectifs attendus, cet objectif est modélisé par le type de mouvement souhaité ; un état futur (défini comme des coordonnées de destination) ou pour un agent ; la recherche en neurosciences et en vision par ordinateur montre que les humains sont généralement des agents orientés vers un objectif. De plus, lorsqu'ils prennent des décisions, les humains suivent un niveau de raisonnement séquentiel continu et formulent finalement des éléments courts ; -des plans à terme ou à long terme ; sur cette base, cette question peut être divisée en deux catégories : la première est cognitive, répondant à la question de savoir où va l'agent ; la seconde est arbitraire, répondant à la question de savoir comment cette entité intelligente y parvient ; ses objectifs visés.
8) Prédiction multimodale : Étant donné que l'environnement routier est stochastique, une trajectoire précédente peut se dérouler différentes trajectoires futures ; par conséquent, un système de prédiction pratique qui résout le défi de la « stochasticité » traitera de l'incertitude du problème de modélisation ; sont des méthodes de modélisation spatiale latente de variables discrètes, la multimodalité n'est appliquée qu'aux trajectoires, montrant pleinement son potentiel dans la prédiction d'intention ; un mécanisme d'attention est adopté, qui peut être utilisé pour calculer des poids ;
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelle résolution est 1080p ?
Quelle résolution est 1080p ?
 Comment exécuter le projet phpstudy
Comment exécuter le projet phpstudy
 psrpc.dll solution introuvable
psrpc.dll solution introuvable
 Le dernier classement des dix principales bourses du cercle des devises
Le dernier classement des dix principales bourses du cercle des devises
 Raisons pour lesquelles l'écran tactile du téléphone portable échoue
Raisons pour lesquelles l'écran tactile du téléphone portable échoue
 Le WiFi ne montre aucun accès à Internet
Le WiFi ne montre aucun accès à Internet
 Introduction au protocole xmpp
Introduction au protocole xmpp
 qu'est-ce que la fonction
qu'est-ce que la fonction








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



