


L'émergence de l'IA conversationnelle telle que ChatGPT a habitué les gens à ce genre de choses : saisissez un texte, un code ou une image, et le robot conversationnel vous donnera la réponse que vous souhaitez. Mais derrière cette méthode d'interaction simple, le modèle d'IA doit effectuer un traitement de données et des calculs très complexes, et la tokenisation est courante.
Dans le domaine du traitement du langage naturel, la tokenisation fait référence à la division du texte saisi en unités plus petites, appelées « jetons ». Ces jetons peuvent être des mots, des sous-mots ou des caractères, en fonction de la stratégie spécifique de segmentation des mots et des exigences de la tâche. Par exemple, si nous effectuons une tokenisation sur la phrase « J'aime manger des pommes », nous obtiendrons une séquence de tokens : ["I", "Like", "Eat", "Apple"]. Certaines personnes traduisent la tokenisation par « segmentation de mots », mais d'autres pensent que cette traduction est trompeuse. Après tout, le jeton segmenté n'est peut-être pas le « mot » que nous comprenons tous les jours.
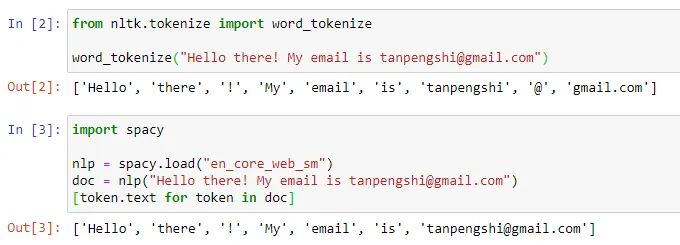
Source de l'image : https://towardsdatascience.com/dynamic-word-tokenization-with-regex-tokenizer-801ae839d1cd
Le but de la tokenisation est de convertir les données d'entrée en quelque chose que l'ordinateur peut traiter la forme et fournir une représentation structurée pour la formation et l'analyse ultérieures du modèle. Cette méthode apporte de la commodité à la recherche sur l’apprentissage profond, mais elle pose également beaucoup de problèmes. Andrej Karpathy, qui vient de rejoindre OpenAI il y a quelque temps, en a souligné plusieurs.
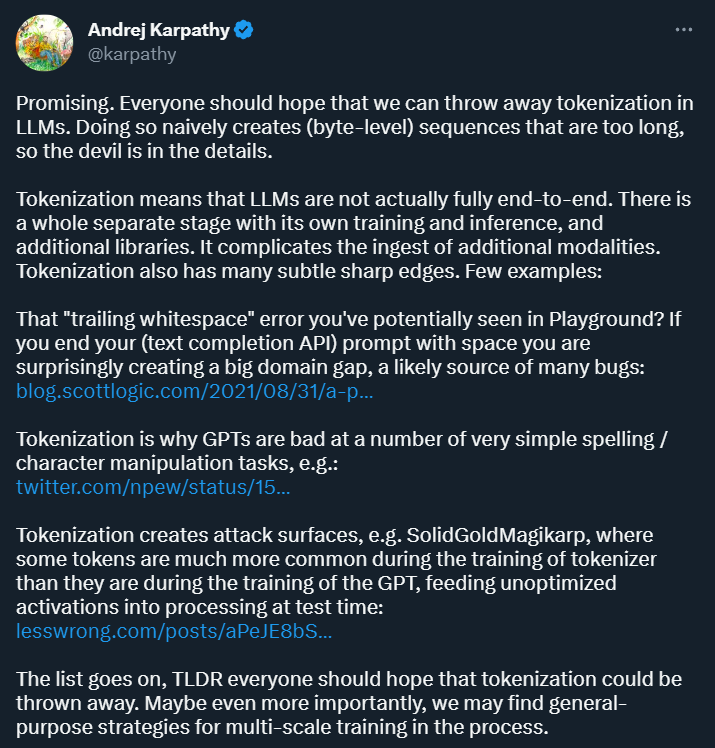
Tout d'abord, Karpathy estime que la tokenisation introduit de la complexité : en utilisant la tokenisation, le modèle de langage n'est pas un modèle complet de bout en bout. Cela nécessite une étape distincte pour la tokenisation, qui possède son propre processus de formation et d'inférence et nécessite des bibliothèques supplémentaires. Cela augmente la complexité de l’introduction de données provenant d’autres modalités.
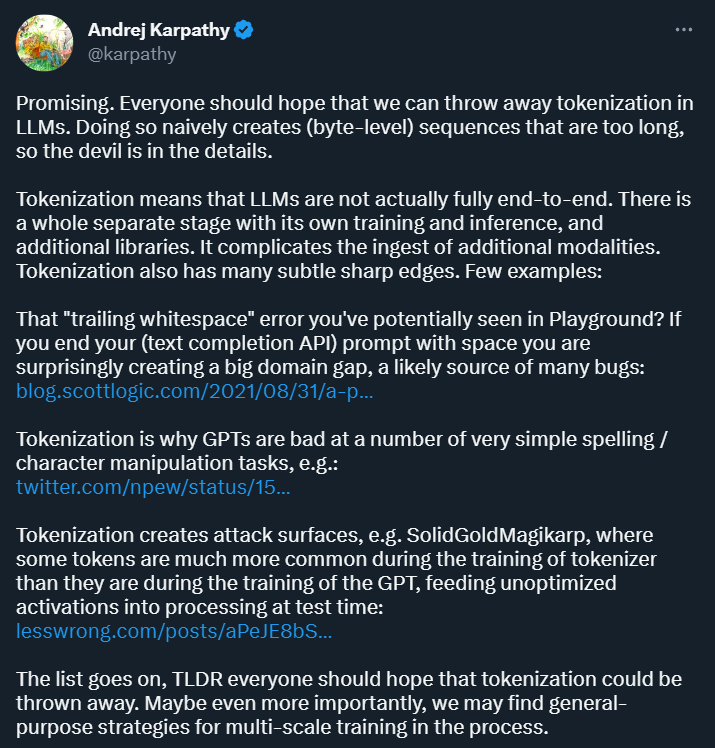
De plus, la tokenisation rendra également le modèle sujet aux erreurs dans certains scénarios. Par exemple, lors de l'utilisation de l'API de complétion de texte, si votre invite se termine par un espace, les résultats que vous obtenez peuvent être très. différent. .

Source de l'image : https://blog.scottlogic.com/2021/08/31/a-primer-on-the-openai-api-1.html
encore Par exemple, en raison de l'existence de la tokenisation, le puissant ChatGPT n'écrira pas les mots à l'envers (les résultats des tests suivants proviennent de GPT 3.5).
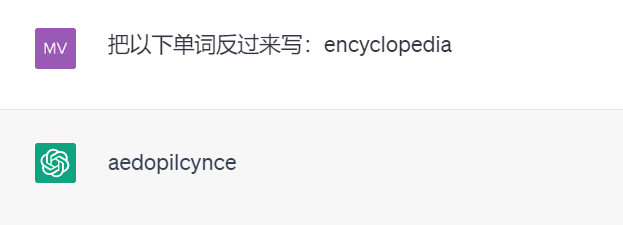
Il peut y avoir beaucoup d'autres exemples comme celui-ci. Karpathy estime que pour résoudre ces problèmes, nous devons d'abord abandonner la tokenisation.
Un nouvel article publié par Meta AI explore cette question. Plus précisément, ils ont proposé une architecture de décodeur multi-échelle appelée « MEGABYTE » capable d'effectuer une modélisation différentiable de bout en bout de séquences dépassant un million d'octets.

Lien papier : https://arxiv.org/pdf/2305.07185.pdf
Il est important de noter que cet article montre la faisabilité de l'abandon de la tokenisation et a été évalué par Karpathy comme « prometteur ». ".
Voici les détails du document.
Comme mentionné dans l'article sur l'apprentissage automatique, la raison pour laquelle l'apprentissage automatique semble être capable de résoudre de nombreux problèmes complexes est qu'il transforme ces problèmes en problèmes mathématiques.
Et la PNL a la même idée. Les textes sont tous des "données non structurées". Nous devons d'abord convertir ces données en "données structurées". Ensuite, les données structurées peuvent être converties en problèmes mathématiques. la première étape de la transformation.
En raison du coût élevé des mécanismes d'auto-attention et des grands réseaux de rétroaction, les grands décodeurs de transformateurs (LLM) n'utilisent généralement que des milliers de jetons de contexte. Cela limite considérablement l'ensemble des tâches auxquelles le LLM peut être appliqué.
Sur cette base, les chercheurs de Meta AI ont proposé une nouvelle méthode de modélisation de séquences d'octets longs - MEGABYTE. Cette méthode divise la séquence d'octets en patchs de taille fixe, similaires au jeton. Le modèle
MEGABYTE se compose de trois parties :
L'étude a révélé que pour de nombreuses tâches, la plupart des octets sont relativement faciles à prédire (par exemple, compléter un mot à partir des premiers caractères), ce qui signifie qu'il n'est pas nécessaire qu'un octet utilise de grands réseaux de neurones, mais peut utiliser des modèles beaucoup plus petits pour la modélisation intra-patch.
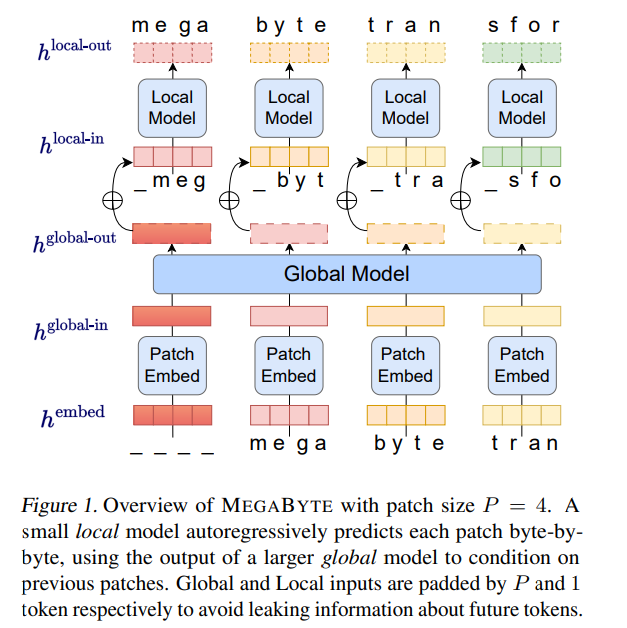
L'architecture MEGABYTE a apporté trois améliorations majeures à Transformer pour la modélisation de séquences longues :
auto-attention sous-quadratique. La plupart des travaux sur les modèles à séquence longue se concentrent sur la réduction du coût quadratique de l’attention personnelle. En décomposant une longue séquence en deux séquences plus courtes et en taille de patch optimale, MEGABYTE réduit le coût du mécanisme d'auto-attention à 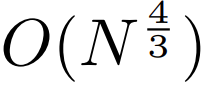 , rendant même les séquences longues faciles à traiter.
, rendant même les séquences longues faciles à traiter.
couche de rétroaction par patch. Dans les très grands modèles tels que GPT-3, plus de 98 % des FLOPS sont utilisés pour calculer des couches de rétroaction en fonction de la position. MEGABYTE permet des modèles plus grands et plus expressifs au même coût en utilisant de grandes couches de rétroaction par patch (au lieu de par position). Avec une taille de patch P, le transformateur de base utilisera la même couche de rétroaction avec m paramètres P fois, tandis que MEGABYTE n'aura besoin d'utiliser la couche avec les paramètres mP qu'une seule fois au même coût.
3. Décodage parallèle. Le transformateur doit effectuer tous les calculs en série pendant la génération car l'entrée de chaque pas de temps est la sortie du pas de temps précédent. En générant des représentations de correctifs en parallèle, MEGABYTE obtient un plus grand parallélisme dans le processus de génération. Par exemple, un modèle MEGABYTE avec 1,5 Mo de paramètres génère des séquences 40 % plus rapidement qu'un transformateur de paramètres standard de 350 Mo, tout en améliorant également la perplexité lors de l'entraînement à l'aide du même calcul.
Dans l'ensemble, MEGABYTE nous permet de former des modèles plus grands et plus performants avec le même budget de calcul, sera capable de gérer des séquences très longues et d'augmenter la vitesse de construction lors du déploiement.
MEGABYTE contraste également avec les modèles autorégressifs existants, qui utilisent généralement une certaine forme de tokenisation dans laquelle des séquences d'octets sont mappées en jetons discrets plus grands (Sennrich et al., 2015 ; Ramesh et al., 2021 ; Hsu et al., 2021). La tokenisation complique le prétraitement, la modélisation multimodale et le transfert vers de nouveaux domaines, tout en cachant la structure utile dans le modèle. Cela signifie que la plupart des modèles SOTA ne sont pas véritablement des modèles de bout en bout. Les méthodes de tokenisation les plus largement utilisées nécessitent l’utilisation d’heuristiques spécifiques au langage (Radford et al., 2019) ou la perte d’informations (Ramesh et al., 2021). Par conséquent, remplacer la tokenisation par un modèle d’octets efficace et performant présentera de nombreux avantages.
L'étude a mené des expériences sur MEGABYTE et certains modèles de base puissants. Les résultats expérimentaux montrent que MEGABYTE fonctionne de manière comparable aux modèles de sous-mots sur la modélisation de langage à contexte long, atteint une perplexité d'estimation de densité de pointe sur ImageNet et permet la modélisation audio à partir de fichiers audio bruts. Ces résultats expérimentaux démontrent la faisabilité d’une modélisation de séquences autorégressives sans tokenisation à grande échelle. #🎜🎜 ##### 🎜🎜#Le composant principal de Megabyte de#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜#patch intégrer
L'intégrateur de patch de taille P peut octeter une séquence 
est mappé sur une longueur de
#🎜 🎜#, séquence d'intégration de patch avec dimensions
.
#🎜 🎜#
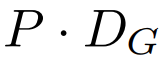 , formant un intégration de taille D_G avec l'intégration de position ajoutée. Ensuite, l'incorporation d'octets est Remodelez-le en une séquence d'intégrations de patch K avec les dimensions
, formant un intégration de taille D_G avec l'intégration de position ajoutée. Ensuite, l'incorporation d'octets est Remodelez-le en une séquence d'intégrations de patch K avec les dimensions
. Pour permettre la modélisation autorégressive, la séquence de patchs est complétée par des intégrations de remplissage à partir de la taille du patch pouvant être entraîné ( #), puis supprime le dernier patch de l'entrée. Cette séquence est l'entrée du modèle global, représentée par
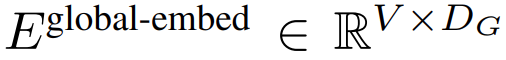
#🎜 🎜#
module global
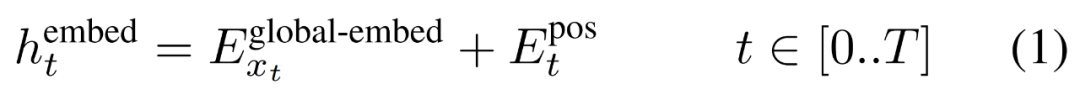
Le module global est un modèle de transformateur dimensionnel P・D_G à architecture uniquement décodeur qui fonctionne sur k séquences de patchs. Le module global combine un mécanisme d'auto-attention et un masque causal pour capturer les dépendances entre les correctifs. Le module global saisit les représentations de k séquences de correctifs
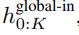
et génère des mises à jour en effectuant une auto-attention sur les correctifs précédents. L'expression de
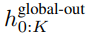
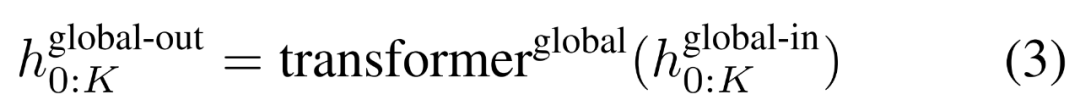
# 🎜🎜#
La sortie du module global final
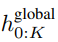
K patchs contenant les dimensions P・D_G express . Pour chacun d'eux, nous les avons remodelés en une séquence de longueur P et de dimension D_G, où la position p utilise la dimension p·D_G à (p + 1)·D_G. Chaque position est ensuite mappée à la dimension du module local avec la matrice
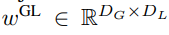
, où D_L est la dimension du module local. Ceux-ci sont ensuite combinés avec une intégration d'octets de taille D_L pour le jeton suivant.
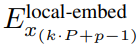
module local
module local est une architecture plus petite, réservée uniquement au décodeur, d'un modèle de transformateur dimensionnel D_L qui fonctionne sur un seul patch k contenant P éléments, chaque élément étant la somme d'une sortie globale du module et l'incorporation de l'octet précédent dans la séquence. K copies du module local sont exécutées indépendamment sur chaque patch et exécutées en parallèle pendant la formation, calculant ainsi la représentation #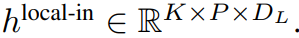
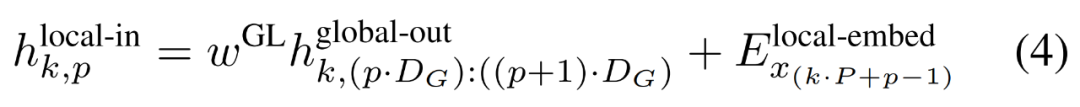
analyse d'efficacité
#🎜🎜 # Efficacité de la formationLes chercheurs ont analysé les coûts de différentes architectures lors de la mise à l'échelle de la longueur des séquences et de la taille du modèle. Comme le montre la figure 3 ci-dessous, l'architecture MEGABYTE utilise moins de FLOPS que des transformateurs et des transformateurs linéaires de taille comparable sur une variété de tailles de modèle et de longueurs de séquence, permettant l'utilisation de modèles plus grands pour le même coût de calcul. 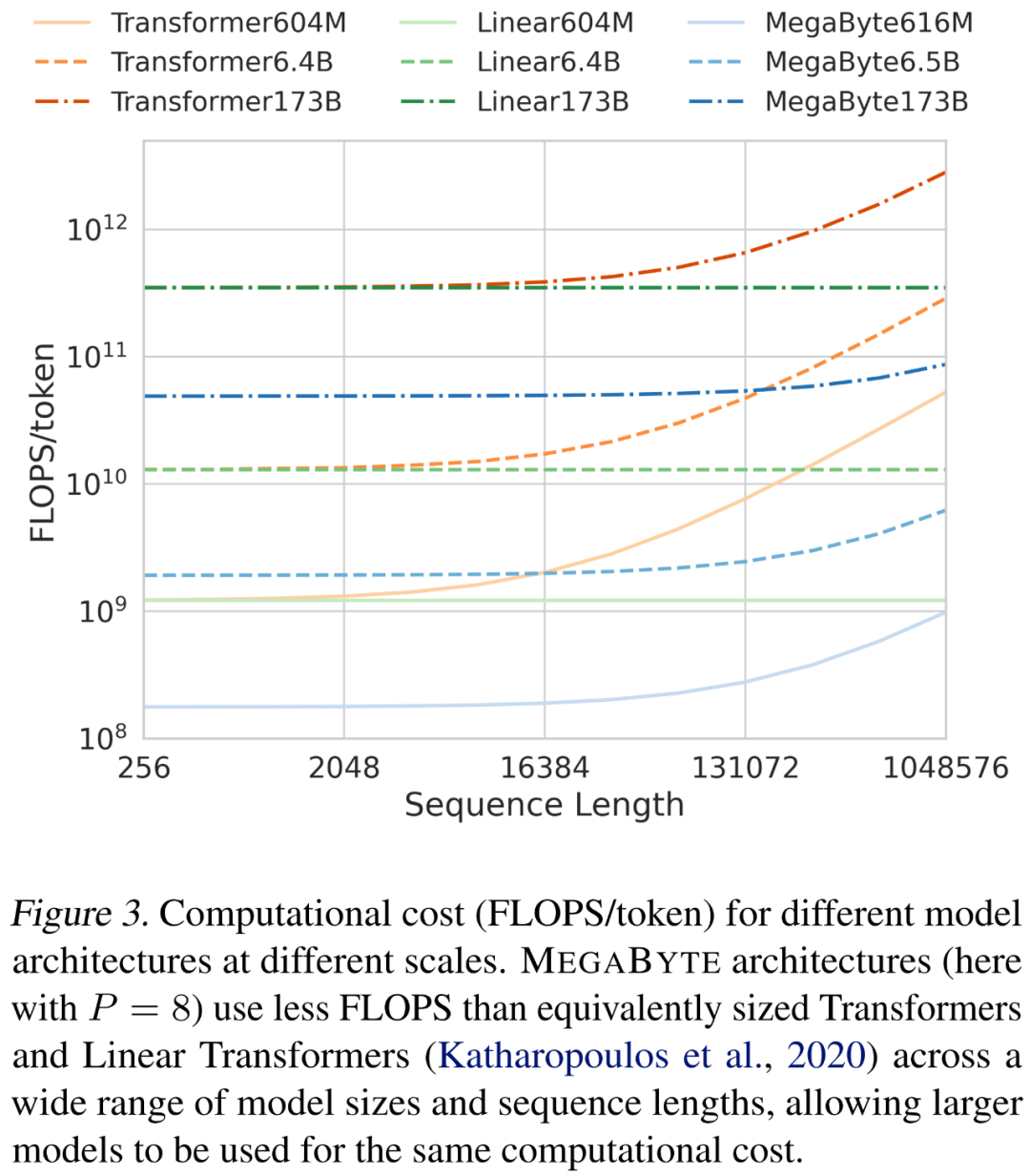
Efficacité de la génération
Considérez un tel modèle MEGABYTE, qui a la couche L_global dans le modèle global, la couche L_local dans le module local, la taille du patch est P et a L_local + Le transformateur L'architecture de la couche L_global est comparée. La génération de chaque patch avec MEGABYTE nécessite une séquence O (L_global + P·L_local) d'opérations en série. Lorsque L_global ≥ L_local (les modules globaux ont plus de couches que les modules locaux), MEGABYTE peut réduire le coût d'inférence de près de P fois.
Modélisation du langage
Les chercheurs ont évalué la fonction de modélisation du langage de MEGABYTE sur 5 ensembles de données différents qui mettent l'accent sur les dépendances à long terme, à savoir le projet Gutenberg (PG-19), les livres, les histoires, arXiv et Code. Les résultats sont présentés dans le tableau 7 ci-dessous, MEGABYTE surpasse systématiquement le transformateur de base et PerceiverAR sur tous les ensembles de données.
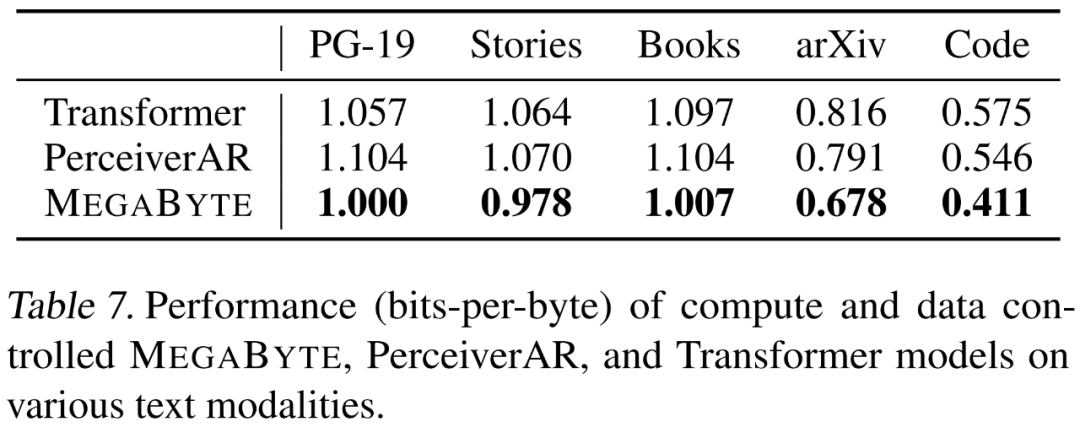
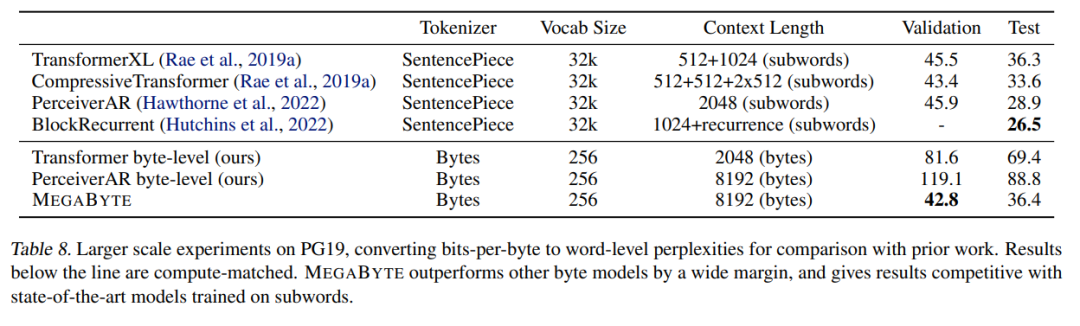
Les chercheurs ont également élargi les données de formation sur PG-19. Les résultats présentés dans le tableau 8 ci-dessous sont nettement meilleurs que les autres modèles d'octets et peuvent être comparés aux données de formation sur les sous-mots comparables. aux modèles SOTA.
Modélisation d'image
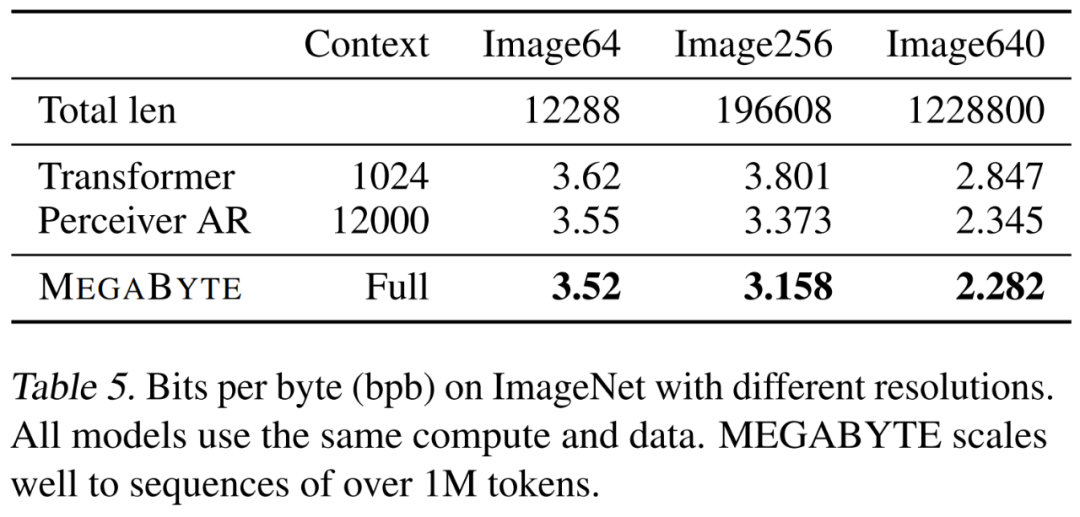
Les chercheurs ont formé un grand modèle MEGABYTE sur l'ensemble de données ImageNet 64x64, dans lequel les paramètres des modules globaux et locaux sont respectivement de 2,7 Mo et 350 Mo, et ont 1,4 Jeton T. Ils estiment que la formation du modèle prend moins de la moitié du nombre d'heures GPU nécessaires pour reproduire le meilleur modèle PerceiverAR dans l'article de Hawthorne et al., 2022. Comme le montre le tableau 8 ci-dessus, MEGABYTE a des performances comparables à celles du SOTA de PerceiverAR, tout en n'utilisant que la moitié des calculs de ce dernier.
Les chercheurs ont comparé trois variantes de transformateur, à savoir vanilla, PerceiverAR et MEGABYTE, pour tester l'évolutivité de longues séquences à des résolutions d'image de plus en plus grandes. Les résultats sont présentés dans le tableau 5 ci-dessous. Dans ce paramètre de contrôle informatique, MEGABYTE surpasse le modèle de base à toutes les résolutions.
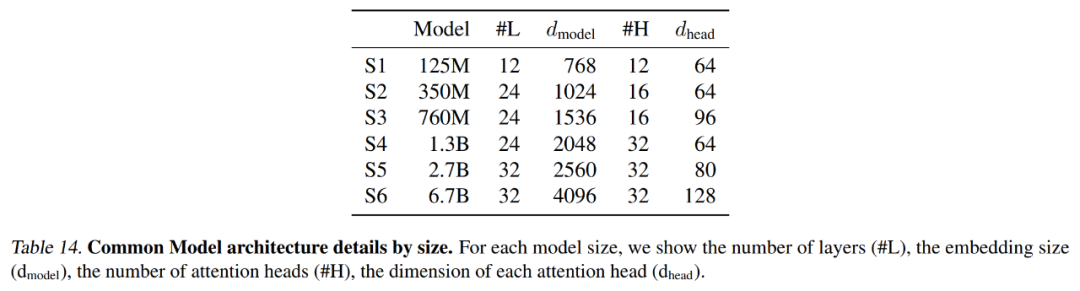
Le tableau 14 ci-dessous résume les paramètres exacts utilisés par chaque modèle de base, y compris la longueur du contexte et le nombre de latents.
Modélisation audio
L'audio possède à la fois la structure séquentielle du texte et les propriétés continues des images, ce qui est une application intéressante pour MEGABYTE. Le modèle de cet article a obtenu un bpb de 3,477, ce qui est nettement inférieur au modèle percepterAR (3,543) et au transformateur vanille (3,567). Des résultats d'ablation supplémentaires sont détaillés dans le tableau 10 ci-dessous.
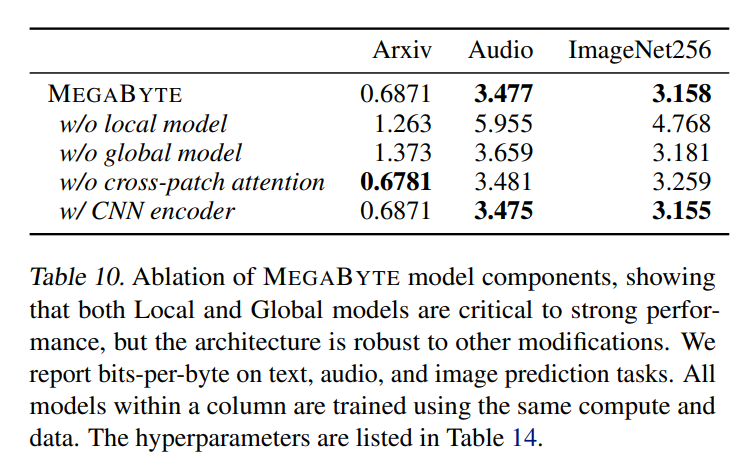
Veuillez vous référer à l'article original pour plus de détails techniques et de résultats expérimentaux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



