



Écrire du code à l'aide de ChatGPT est devenu une opération de routine pour de nombreux programmeurs.
Mais avez-vous déjà pensé qu'une grande partie du code généré par ChatGPT "semble précis" ?
Une dernière étude de l'Université de l'Illinois à Urbana-Champaign et de l'Université de Nanjing montre que :
La précision du code généré par ChatGPT et GPT-4 est au moins 13 % inférieure à celle évaluée précédemment !

Certains internautes ont déploré que trop d'articles sur le ML utilisent des critères problématiques ou limités pour évaluer les modèles afin d'atteindre brièvement le « SOTA ». En conséquence, la forme originale est révélée lorsque la méthode d'évaluation est modifiée.

Certains internautes ont déclaré que cela montre également que le code généré par les grands modèles nécessite toujours une supervision manuelle et que "le moment idéal pour l'écriture du code de l'IA n'est pas encore arrivé".

Alors, quel genre de nouvelle méthode d'évaluation le journal propose-t-il ?
Cette nouvelle méthode s'appelle EvalPlus et il s'agit d'un cadre d'évaluation de code automatisé.
Plus précisément, cela rendra ces critères d'évaluation plus rigoureux en améliorant la diversité des entrées et la précision de la description des problèmes des ensembles de données d'évaluation existants.
D’une part, il y a la diversité des entrées. EvalPlus utilisera d'abord ChatGPT pour générer des échantillons d'entrées de départ basés sur les réponses standard (bien que la capacité de programmation de ChatGPT doive être testée, il ne semble pas incohérent de l'utiliser pour générer des entrées de départ)
Ensuite, utilisez EvalPlus pour les améliorer les intrants de semences et les modifier. C'est plus difficile, plus complexe et plus délicat.
L'autre aspect est l'exactitude de la description du problème. EvalPlus modifiera la description des exigences du code pour être plus précise tout en limitant les conditions d'entrée, il complétera les descriptions des problèmes en langage naturel pour améliorer les exigences de précision pour la sortie du modèle.
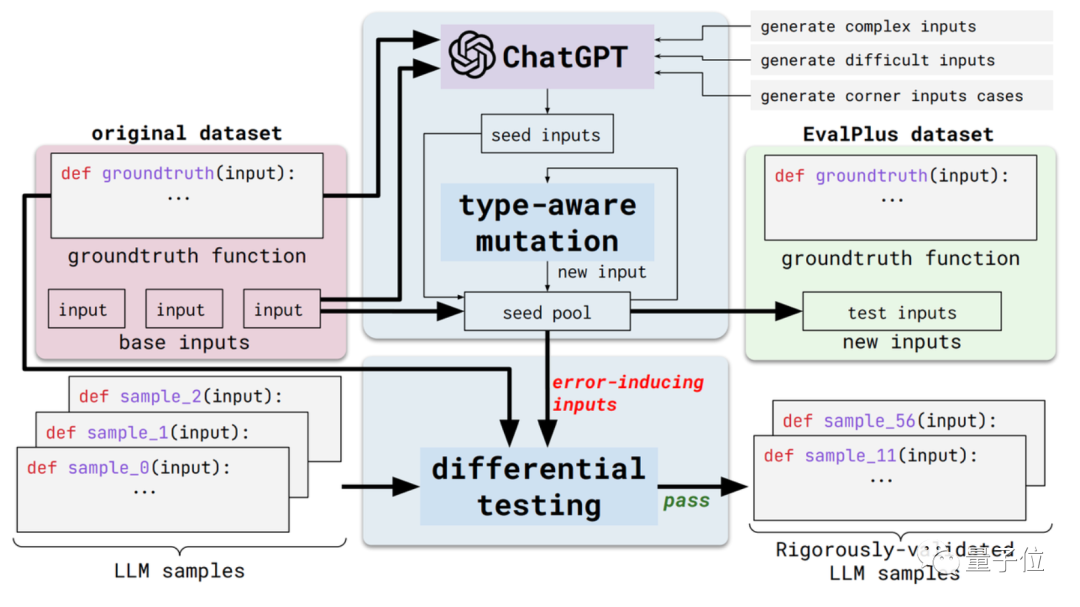
Ici, l'article choisit l'ensemble de données HUMANEVAL comme démonstration.
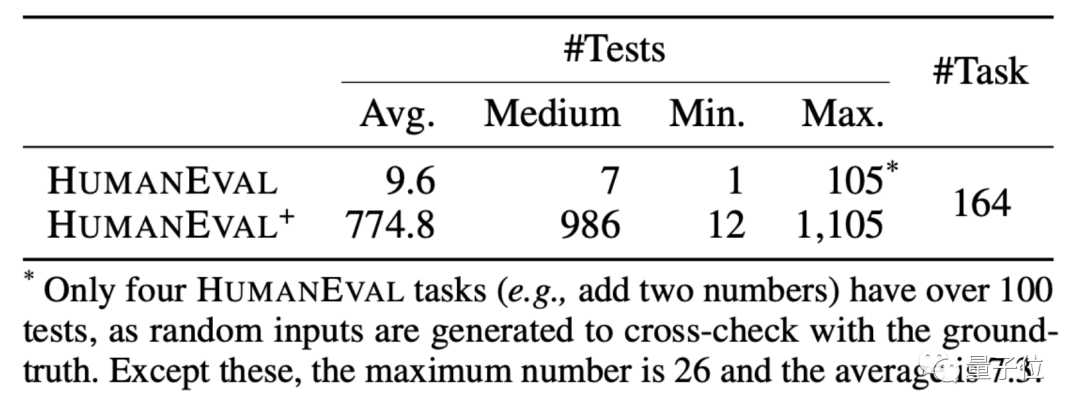
HUMANEVAL est un ensemble de données de code produit conjointement par OpenAI et Anthropic AI. Il contient 164 questions de programmation originales, impliquant plusieurs types de questions, notamment la compréhension du langage, les algorithmes, les mathématiques et les entretiens logiciels.
EvalPlus rendra les problèmes de programmation plus clairs en améliorant les types d'entrée et les descriptions de fonctions de ces ensembles de données, et les entrées utilisées pour les tests seront plus « délicates » ou difficiles.
Prenons comme exemple l'une des questions de programmation de l'ensemble syndical. L'IA doit écrire un code pour trouver les éléments communs dans les deux listes de données et trier ces éléments.
EvalPlus l'utilise pour tester l'exactitude du code écrit par ChatGPT.
Après avoir effectué un simple test de saisie, nous avons constaté que ChatGPT peut produire des réponses précises. Mais si vous modifiez la saisie, vous retrouverez le bug dans la version ChatGPT du code :

Il est vrai que les questions du test sont plus difficiles pour l'IA.

Sur la base de cette méthode, EvalPlus a également créé une version améliorée de l'ensemble de données HUMANEVAL+. Tout en ajoutant des entrées, il a corrigé certaines questions de programmation avec des réponses problématiques dans HUMANEVAL.
Donc, dans le cadre de cette « nouvelle série de questions de test », dans quelle mesure la précision des grands modèles de langage sera-t-elle réellement réduite ?
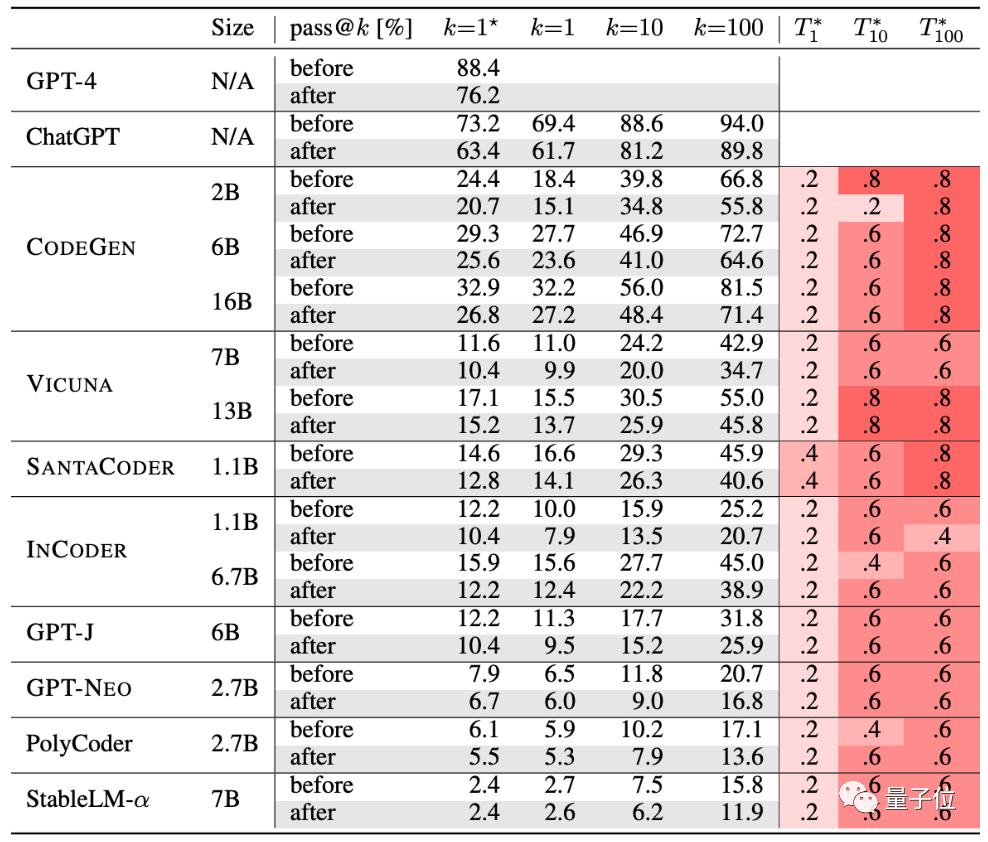
Les auteurs ont testé 10 IA de génération de code actuellement populaires.
GPT-4, ChatGPT, CODEGEN, VICUNA, SANTACODER, INCODER, GPT-J, GPT-NEO, PolyCoder, StableLM-α.
À en juger par le tableau, après des tests rigoureux, la précision de génération de ce groupe d'IA a diminué :
La précision sera évaluée ici via une méthode appelée pass@k, où k est le nombre de programmes qui permettent aux grands modèles de générer des problèmes, n est le nombre d'entrées utilisées pour les tests, et c est le nombre d'entrées correctes :
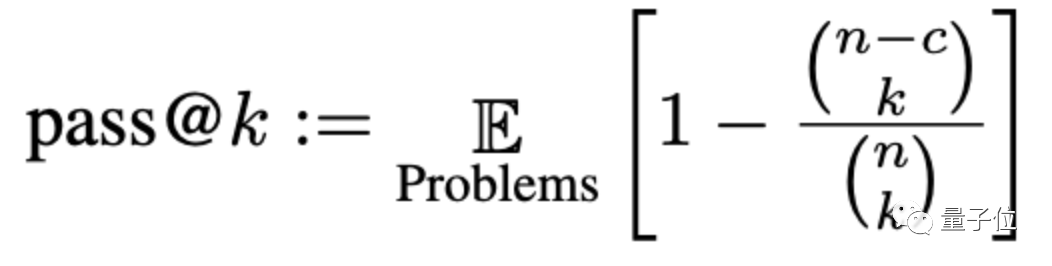
Selon ce nouvel ensemble de critères d'évaluation, la précision moyenne des grands modèles Il a chuté de 15 % et le CODEGEN-16B, plus largement étudié, a chuté de plus de 18 %.
Quant aux performances du code généré par ChatGPT et GPT-4, elles ont également chuté d'au moins 13 %.
Cependant, certains internautes ont déclaré que c'est un « fait bien connu » que le code généré par les grands modèles n'est pas si bon, et ce qu'il faut étudier est « pourquoi le code écrit par les grands modèles ne peut pas être utilisé ».
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Inscription ChatGPT
Inscription ChatGPT
 Encyclopédie ChatGPT nationale gratuite
Encyclopédie ChatGPT nationale gratuite
 Comment installer chatgpt sur un téléphone mobile
Comment installer chatgpt sur un téléphone mobile
 Chatgpt peut-il être utilisé en Chine ?
Chatgpt peut-il être utilisé en Chine ?
 Quelles sont les plateformes de signature électronique de contrats ?
Quelles sont les plateformes de signature électronique de contrats ?
 Comment supprimer la bordure de la zone de texte
Comment supprimer la bordure de la zone de texte
 Sinon, utilisation dans la structure de boucle Python
Sinon, utilisation dans la structure de boucle Python
 Explication détaillée de method_exists
Explication détaillée de method_exists








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



