



Ci-dessous, vous apprendrez comment surmonter divers défis que vous pourriez rencontrer, tels que le téléchargement de fichiers redirigés, le téléchargement de fichiers volumineux, la réalisation d'un téléchargement multithread et d'autres stratégies.
Vous pouvez utiliser le module de requêtes pour télécharger des fichiers à partir d'une URL.
Considérez le code suivant :

Vous obtenez simplement l'URL en utilisant la méthode get du module de requêtes et stockez le résultat dans une variable appelée "monfichier". Ensuite, écrivez le contenu de cette variable dans le fichier.

Vous pouvez également utiliser le module wget de Python pour télécharger des fichiers à partir d'une URL. Vous pouvez installer le module wget à l'aide de pip en suivant la commande :
Considérez le code suivant, que nous utiliserons pour télécharger l'image du logo pour Python.
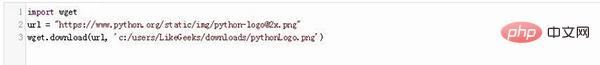
Dans ce code, l'URL et le chemin (où l'image sera stockée) sont transmis à la méthode de téléchargement du module wget.
Dans cette section, vous apprendrez à utiliser les requêtes pour télécharger un fichier à partir d'une URL qui sera redirigé vers une autre URL avec un fichier .pdf. L'URL ressemble à ceci :

Pour télécharger ce fichier pdf, utilisez le code suivant :

Dans ce code, nous précisons l'URL dans la première étape. Ensuite, nous utilisons la méthode get du module request pour obtenir l'URL. Dans la méthode get, nous définissons allow_redirects sur True, ce qui autorisera les redirections dans l'URL et le contenu redirigé sera attribué à la variable myfile. De plus, recherchez dans le backend du compte public les meilleurs architectes et répondez « Statut de l'entretien » pour obtenir un coffret cadeau surprise.
Enfin, nous ouvrons un fichier pour écrire le contenu obtenu.
Considérez le code suivant :

Tout d'abord, nous utilisons la méthode get du module requêtes comme auparavant, mais cette fois, nous définirons l'attribut stream sur True.
Ensuite, nous créons un fichier nommé PythonBook.pdf dans le répertoire de travail actuel et l'ouvrons en écriture.
Ensuite, nous précisons la taille du morceau à télécharger à chaque fois. Nous l'avons défini sur 1024 octets, puis avons parcouru chaque morceau et écrit ces morceaux dans le fichier jusqu'à la fin du morceau.
N'est-ce pas beau ? Ne vous inquiétez pas, nous afficherons une barre de progression du processus de téléchargement plus tard.
Pour télécharger plusieurs fichiers en même temps, veuillez importer les modules suivants :

Nous avons importé les modules OS et Time pour vérifier combien de temps il faut pour téléchargez les fichiers. Le module ThreadPool vous permet d'exécuter plusieurs threads ou processus à l'aide d'un pool.
Créons une fonction simple qui décompose la réponse à un fichier :
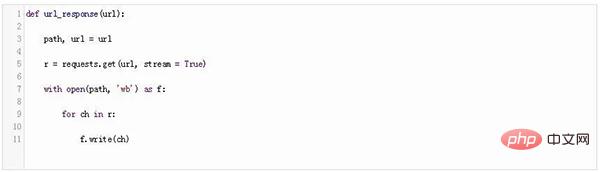
L'URL est un tableau 2D qui spécifie le chemin et l'URL de la page que vous souhaitez télécharger.

Tout comme nous l'avons fait dans la section précédente, nous transmettons cette URL à request.get. Enfin, nous ouvrons le fichier (le chemin spécifié dans l'URL) et écrivons le contenu de la page.
Maintenant, nous pouvons appeler cette fonction pour chaque URL individuellement, ou nous pouvons appeler cette fonction pour toutes les URL en même temps. Appelons cette fonction pour chaque URL individuellement dans une boucle for, en faisant attention au timer :

Remplacez maintenant la boucle for par la ligne de code suivante :

Exécutez le script.
La barre de progression est un composant de l'interface utilisateur du module clint. Entrez la commande suivante pour installer le module clint :

Considérez le code suivant :
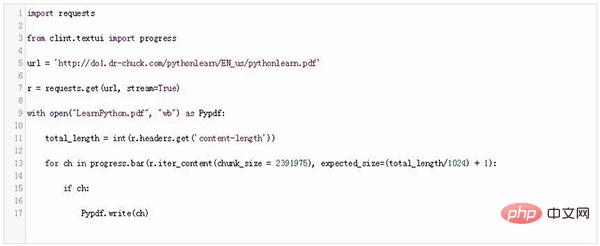 #🎜🎜 ##🎜 🎜#Dans ce code, nous avons d'abord importé le module de requêtes, puis nous avons importé le composant de progression depuis clint.textui. La seule différence réside dans la boucle for. Lors de l'écriture du contenu dans un fichier, nous utilisons la méthode bar du module de barre de progression.
#🎜🎜 ##🎜 🎜#Dans ce code, nous avons d'abord importé le module de requêtes, puis nous avons importé le composant de progression depuis clint.textui. La seule différence réside dans la boucle for. Lors de l'écriture du contenu dans un fichier, nous utilisons la méthode bar du module de barre de progression.
7. Utilisez urllib pour télécharger une page Web
La bibliothèque urllib est la bibliothèque standard de Python, vous n'avez donc pas besoin de l'installer.
Les lignes de code suivantes permettent de télécharger facilement une page Web :
 Spécifiez ici ce que vous souhaitez que le fichier soit enregistré pour quoi et ce que vous voulez qu'il soit. L'URL de l'endroit où le stocker.
Spécifiez ici ce que vous souhaitez que le fichier soit enregistré pour quoi et ce que vous voulez qu'il soit. L'URL de l'endroit où le stocker.
 Dans ce code, nous utilisons la méthode urlretrieve et transmettons l'URL du fichier, ainsi que le chemin pour enregistrer le fichier. L'extension du fichier sera .html.
Dans ce code, nous utilisons la méthode urlretrieve et transmettons l'URL du fichier, ainsi que le chemin pour enregistrer le fichier. L'extension du fichier sera .html.
8. Télécharger via proxy
 Dans ce code, nous créons l'objet proxy et ouvrons le proxy en appelant la méthode build_opener d'urllib, et passons le objet proxy. Ensuite, nous créons une demande pour obtenir la page.
Dans ce code, nous créons l'objet proxy et ouvrons le proxy en appelant la méthode build_opener d'urllib, et passons le objet proxy. Ensuite, nous créons une demande pour obtenir la page.
De plus, vous pouvez également utiliser le module de requêtes comme décrit dans la documentation officielle :
 Il vous suffit d'importer le module de requêtes et créez votre objet proxy. Ensuite, vous pouvez récupérer le fichier.
Il vous suffit d'importer le module de requêtes et créez votre objet proxy. Ensuite, vous pouvez récupérer le fichier.
9. Utiliser urllib3
 Nous utiliserons urllib3 pour obtenir une page Web et la stocker dans un fichier texte.
Nous utiliserons urllib3 pour obtenir une page Web et la stocker dans un fichier texte.
Importez les modules suivants :
 Lors du traitement des fichiers, nous utilisons le module Shutil.
Lors du traitement des fichiers, nous utilisons le module Shutil.
Maintenant, nous initialisons la variable de chaîne d'URL comme ceci :
 Ensuite, nous utilisons le PoolManager d'urllib3, qui regroupe les pools de connexions nécessaires sont suivis.
Ensuite, nous utilisons le PoolManager d'urllib3, qui regroupe les pools de connexions nécessaires sont suivis.
 Créer un fichier :
Créer un fichier :
 Enfin, on envoie un GET Demandez à obtenir l'URL et ouvrez un fichier, puis écrivez la réponse au fichier :
Enfin, on envoie un GET Demandez à obtenir l'URL et ouvrez un fichier, puis écrivez la réponse au fichier :
 10 Téléchargez des fichiers depuis S3 en utilisant Boto3
10 Téléchargez des fichiers depuis S3 en utilisant Boto3
Avant de commencer, vous devez installer le module awscli à l'aide de pip :
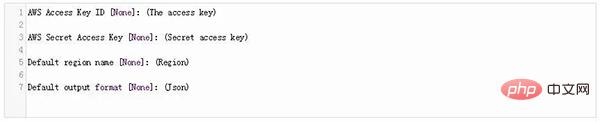
 Pour la configuration AWS, exécutez la commande suivante :
Pour la configuration AWS, exécutez la commande suivante :
Maintenant, entrez vos coordonnées en appuyant sur la commande suivante :
Pour télécharger des fichiers depuis Amazon S3, vous devez importer boto3 et botocore. Boto3 est un SDK Amazon qui permet à Python d'accéder aux services Web Amazon (tels que S3). Botocore fournit un service de ligne de commande pour interagir avec les services Web Amazon.
Botocore est livré avec awscli. Pour installer boto3, exécutez la commande suivante :

Maintenant, importez ces deux modules :

Lors du téléchargement du fichier depuis Amazon, nous avons besoin de trois paramètres :
Variable d'initialisation :

Maintenant, nous initialisons une variable pour utiliser les ressources de la session. Pour ce faire, nous allons appeler la méthode resource() de boto3 et transmettre le service, qui est s3:

Enfin, utiliser la méthode download_file pour télécharger le fichier et transmettre la variable :

asyncio Principalement utilisé pour gérer les événements système. Il fonctionne autour d'une boucle d'événements qui attend qu'un événement se produise et réagit ensuite à cet événement. La réaction peut être d'appeler une autre fonction. Ce processus est appelé traitement des événements. Le module asyncio utilise des coroutines pour la gestion des événements.
Pour utiliser la gestion des événements asyncio et la fonctionnalité coroutine, nous allons importer le module asyncio :

Maintenant, définissons la méthode de coroutine asyncio comme ceci :

Le mot-clé async signifie qu'il s'agit d'une coroutine asyncio native. À l'intérieur de la coroutine, nous avons un mot-clé wait, qui renvoie une valeur spécifique. Nous pouvons également utiliser le mot-clé return.
Maintenant, créons un morceau de code pour télécharger un fichier à partir d'un site Web à l'aide de coroutine :
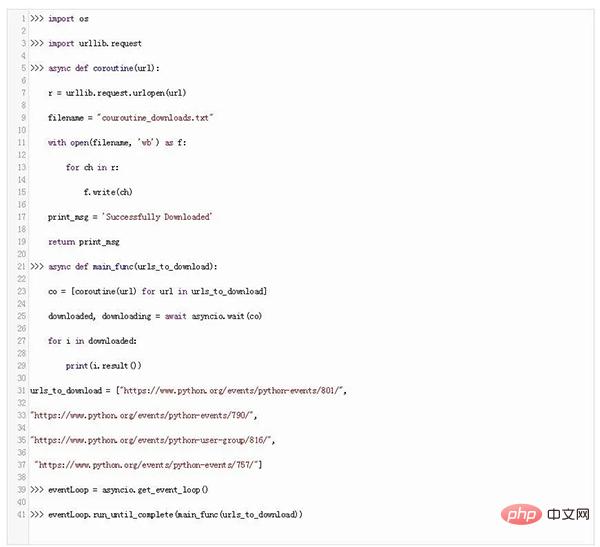
Dans ce morceau de code, nous avons créé une fonction coroutine asynchrone qui téléchargera notre fichier et renverra un message.
Ensuite, nous appelons main_func en utilisant une autre coroutine asynchrone, qui attend les URL et regroupe toutes les URL dans une file d'attente. La fonction d'attente d'asyncio attendra la fin de la coroutine.
Maintenant, pour démarrer la coroutine, nous devons mettre la coroutine dans une boucle d'événement en utilisant la méthode get_event_loop() d'asyncio, et enfin, nous exécutons cette boucle d'événement en utilisant la méthode run_until_complete() d'asyncio.
Télécharger des fichiers à l'aide de Python est amusant. J'espère que ce tutoriel vous sera utile !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



