


Je ne peux pas rattraper le retard du grand mannequin sans dormir...
Non, le Microsoft Asia Research Institute vient de publier un modèle multimodal de langage étendu (MLLM) - KOSMOS-1.

Adresse papier : https:/ /arxiv.org/pdf/2302.14045.pdf
Le titre de l'article, Language Is Not All You Need, vient d'un dicton célèbre.
Il y a une phrase dans l'article : "Les limites de ma langue sont les limites de mon monde. - Philosophe autrichien Ludwig Wittgenstein "

Puis la question vient. .. ....
Tenez la photo et demandez à KOSMOS-1 "Est-ce un canard ou un lapin ?" comprendre? Ce mème avec une histoire de plus de 100 ans ne peut pas arrêter l'IA de Google. 1899, American Psychology L'auteur Joseph Jastrow a été le premier à utiliser le « diagramme du canard et du lapin » pour montrer que la perception n'est pas seulement ce que les gens voient, mais aussi une activité mentale.
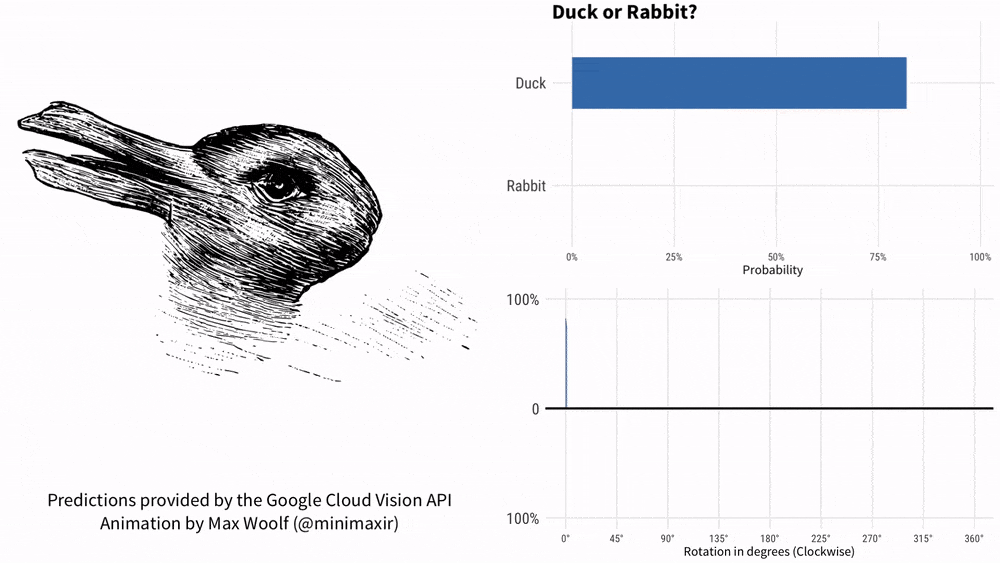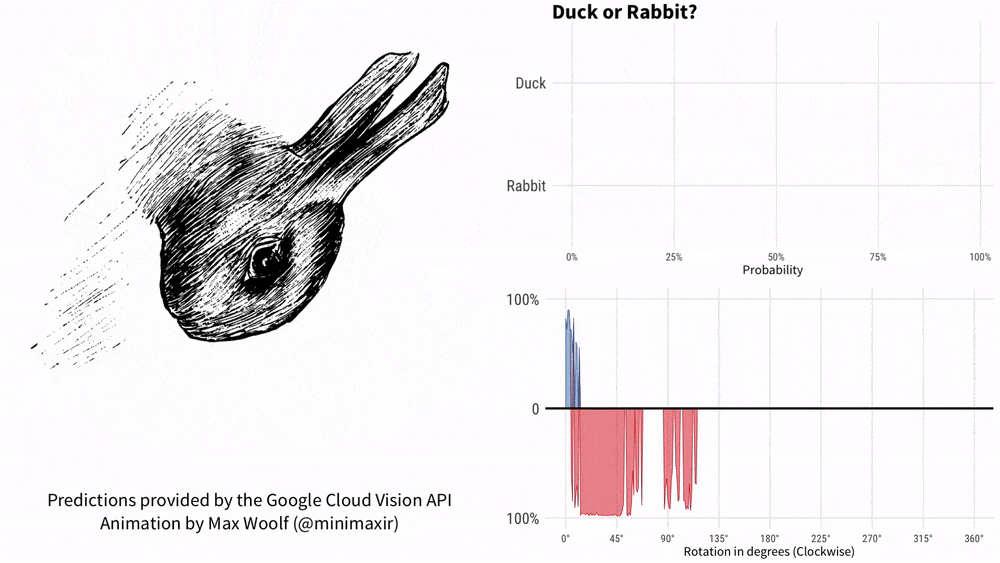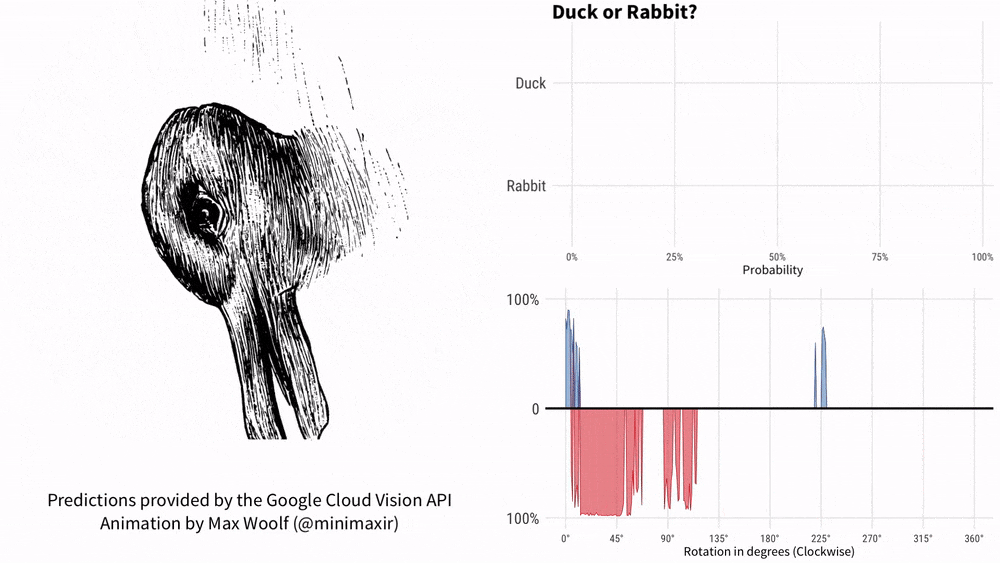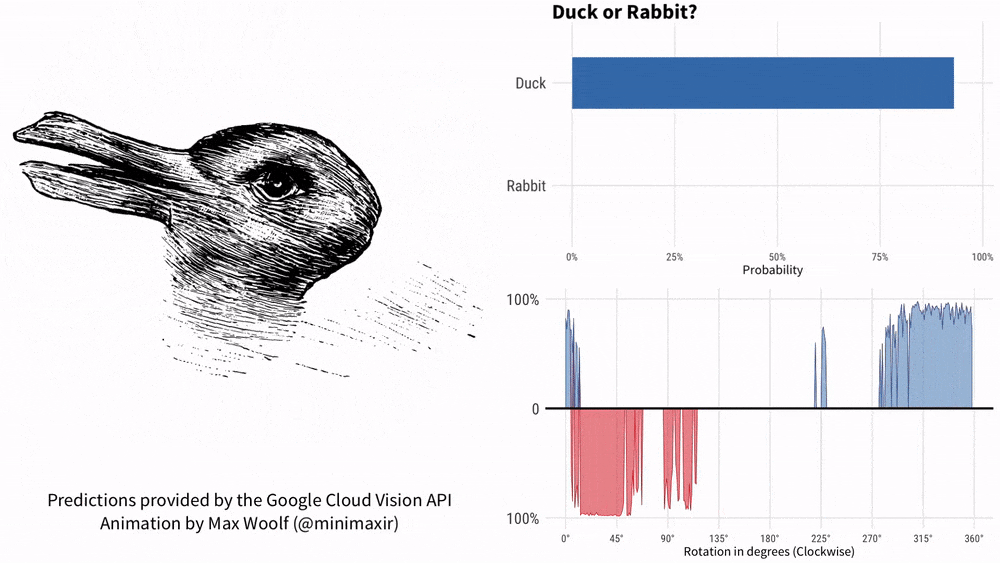 Désormais, KOSMOS-1 peut combiner ce modèle de perception et de langage.
Désormais, KOSMOS-1 peut combiner ce modèle de perception et de langage.
-Qu'est-ce qu'il y a sur la photo ?
- comme un canard.
- Si ce n'est pas un canard, c'est quoi ?
- ressemble plus à un lapin.
-Pourquoi ?
- Il a des oreilles de lapin.
Si vous posez cette question, KOSMOS-1 est vraiment un peu la version Microsoft de ChatGPT.
Pas seulement ça, Kosmos- 1 Comprend également les images, le texte, les images avec texte, l'OCR, les légendes des images, l'assurance qualité visuelle.
 Même le test de QI n'est pas un problème.
Même le test de QI n'est pas un problème.
「Cosmos」est omnipotent
Kosmos vient du mot grec cosmos, qui signifie « univers » signification.Selon le journal, le dernier modèle Kosmos-1 est un modèle linguistique multimodal à grande échelle.
Le backbone est un modèle de langage causal basé sur Transformer En plus du texte, d'autres modalités telles que le visuel et l'audio sont disponibles. Intégrer le modèle.
Le décodeur Transformer sert d'interface universelle pour les entrées multimodales, il peut donc connaître les modalités générales, effectuer un apprentissage contextuel , et suivez les instructions.
Kosmos-1 atteint des performances impressionnantes sur les tâches linguistiques et multimodales sans réglage fin, y compris la reconnaissance d'images avec des instructions textuelles, la réponse visuelle aux questions et le dialogue multimodal.
Voici quelques exemples de styles générés par Kosmos-1.
Interprétation d'images, questions-réponses sur images, réponses aux questions de pages Web, formules numériques simples et reconnaissance de nombres.

Alors, sur quels ensembles de données Kosmos-1 est-il pré-entraîné ?
Bases de données utilisées pour la formation, comprenant des corpus de textes, des paires image-sous-titres, des ensembles de données croisées images et textes.
Le corpus de texte est tiré de The Pile and Common Crawl (CC)
Les sources des paires image-légende sont les anglais LAION-2B, LAION-400M, COYO-700M et les légendes conceptuelles ;
La source de l'ensemble de données d'intersection de texte est l'instantané Common Crawl.
Maintenant que la base de données est disponible, l'étape suivante consiste à pré-entraîner le modèle.
Le composant MLLM comporte 24 couches, 2 048 dimensions cachées, 8 192 FFN et 32 têtes d'attention, ce qui donne environ 1,3 milliard de paramètres.
Pour garantir la stabilité de l'optimisation, l'initialisation Magneto est utilisée ; pour une convergence plus rapide, la représentation de l'image est obtenue à partir d'un modèle CLIP ViT-L/14 pré-entraîné avec 1024 dimensions de caractéristiques. Pendant le processus de formation, les images sont prétraitées à une résolution de 224 × 224 et les paramètres du modèle CLIP sont figés à l'exception de la dernière couche.
Le nombre total de paramètres de KOSMOS-1 est d'environ 1,6 milliard.
Afin de rendre KOSMOS-1 plus cohérent avec les instructions, des ajustements d'instructions uniquement linguistiques [LHV+23, HSLS22] y ont été apportés, c'est-à-dire que les données d'instructions sont utilisées pour continuer à entraîner le modèle, et les données d'instruction sont uniquement Certaines données linguistiques sont mélangées au corpus de formation.
Le processus de réglage est effectué selon la méthode de modélisation du langage, et les ensembles de données d'instructions sélectionnés sont les instructions non naturelles [HSLS22] et FLANv2 [LHV+23].
Les résultats montrent que l'amélioration de la capacité de suivi des commandes peut être transférée d'un mode à l'autre.
En bref, MLLM peut bénéficier du transfert cross-modal, transférant les connaissances de la langue à la multi-modalité et vice versa
Si un modèle fonctionne ; bien ou non peut être déterminé en le retirant et en courant partout.
L'équipe de recherche a mené des expériences sous plusieurs perspectives pour évaluer les performances de KOSMOS-1, dont dix tâches réparties en 5 catégories :
1 Tâches linguistiques (compréhension du langage, génération de langage, classification de texte sans OCR )
2 Transfert multimodal (raisonnement de bon sens)
3 Raisonnement non verbal (test de QI)
4 Tâches perceptuelles-linguistiques (description d'image, question visuelle et réponse, question et réponse de la page Web) )
5 Tâches de vision (classification d'image zéro-shot, classification d'image zéro-shot avec description)
# 🎜🎜#Classification de texte sans OCR
C'est une sorte de classification de texte qui ne fonctionne pas s'appuyer sur la reconnaissance optique de caractères (OCR) axée sur les tâches de compréhension de textes et d'images.
KOSMOS-1 a une plus grande précision sur HatefulMemes et sur l'ensemble de test Rendered SST-2 que les autres modèles.
et Flamingo fournit explicitement du texte OCR dans l'invite, KOSMOS-1 n'accède à aucun outil ou ressource externe, ce qui démontre que KOSMOS - 1 Capacité intrinsèque à lire et à comprendre le texte dans les images rendues.
Test de QI
Le Raven Intelligence Test est l'un des tests les plus couramment utilisés pour évaluer le langage non verbal.
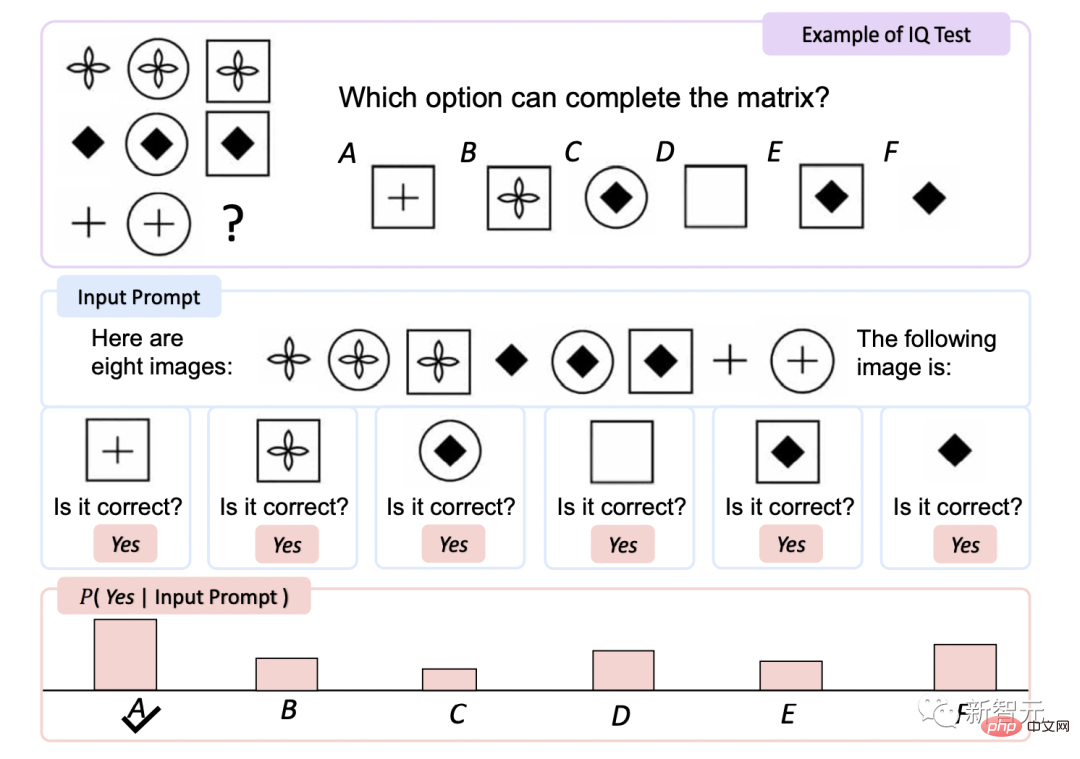
KOSMOS-1 n'a pas été exécuté La précision a augmenté de 5,3 % par rapport à la sélection aléatoire lors du réglage fin et de 9,3 % après le réglage fin, ce qui indique sa capacité à percevoir des modèles de concepts abstraits dans des environnements non linguistiques.
C'est la première fois qu'un modèle est capable de réaliser le test Raven zéro tir, prouvant que les MLLM peuvent effectuer des tirs zéro. tests de tir en combinant la perception avec des modèles de langage Le potentiel du raisonnement non verbal. Légende de l'image
 KOSMOS-1 présente d'excellentes performances sans échantillon dans les tests COCO et Flickr30k Par rapport aux autres modèles. , Il obtient un score plus élevé mais utilise un plus petit nombre de paramètres. Dans le test de performance sur quelques échantillons, le score augmente à mesure que la valeur k augmente. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 🎜🎜 # # zéro Classification des images
KOSMOS-1 présente d'excellentes performances sans échantillon dans les tests COCO et Flickr30k Par rapport aux autres modèles. , Il obtient un score plus élevé mais utilise un plus petit nombre de paramètres. Dans le test de performance sur quelques échantillons, le score augmente à mesure que la valeur k augmente. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 🎜🎜 # # zéro Classification des images
Étant donné une image d'entrée, connectez l'image à l'invite "La photo du" . Ensuite, alimentez le modèle pour obtenir le nom de classe de l'image. via ImageNet [DDS+ 09] pour évaluer le modèle, dans des conditions contraintes et non contraintes, l'effet de classification d'image de KOSMOS-1 est nettement meilleur que celui de GIT [WYH+22], démontrant sa puissante capacité à accomplir des tâches visuelles. Raisonnement de bon sens
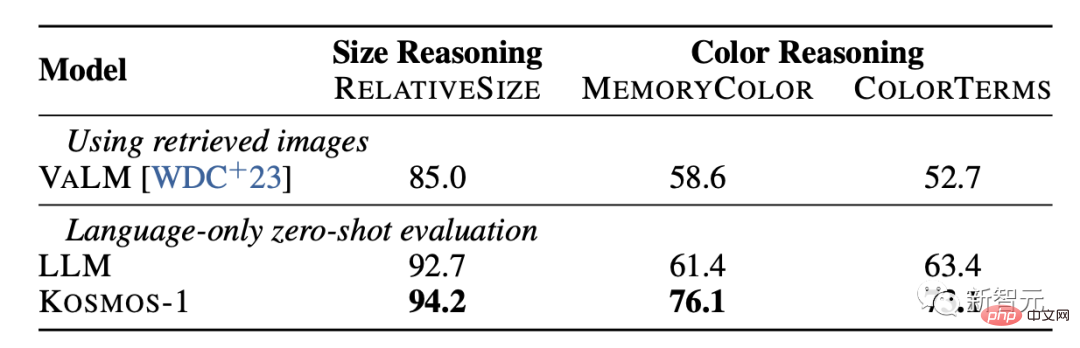
Les tâches de raisonnement visuel de bon sens nécessitent que des modèles comprennent les propriétés des objets du quotidien dans le monde réel, telles que la couleur, la taille et la forme. Ces tâches sont difficiles car elles peuvent nécessiter plus d'informations sur les propriétés des objets que dans le texte.
Les résultats montrent que la capacité de raisonnement de KOSMOS-1 est nettement meilleure que celle du modèle LLM en termes de taille et de couleur. Cela est principalement dû au fait que KOSMOS-1 possède des capacités de transfert multimodal, ce qui lui permet d'appliquer des connaissances visuelles à des tâches linguistiques sans avoir à s'appuyer sur des connaissances textuelles et des indices pour un raisonnement comme le LLM.
Pour Microsoft Kosmos-1, les internautes ont loué le fait que dans les 5 prochaines années, je pourrai voir un robot avancé naviguer sur Internet et travailler sur la base de la saisie de texte humaine uniquement par des moyens visuels. Des moments si intéressants.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Solution à l'échec de la connexion entre wsus et le serveur Microsoft
Solution à l'échec de la connexion entre wsus et le serveur Microsoft
 Solution d'erreur 3004 inconnue
Solution d'erreur 3004 inconnue
 Que dois-je faire si le fichier chm ne peut pas être ouvert ?
Que dois-je faire si le fichier chm ne peut pas être ouvert ?
 Qu'est-ce que le trading de devises numériques
Qu'est-ce que le trading de devises numériques
 site web java en ligne
site web java en ligne
 Comment taper des guillemets doubles en latex
Comment taper des guillemets doubles en latex
 Fichier au format DAT
Fichier au format DAT
 moyens visibles
moyens visibles








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



