


Tout d'abord, présentons le contexte commercial d'Alibaba Health et l'analyse de la situation actuelle.
Recommandations interprétables, par exemple, comme indiqué ci-dessous, les « Recommandations basées sur les produits que vous parcourez » de Dangdang.com (indiquant aux utilisateurs les raisons des recommandations) et les « 1000+ » de Taobao. « Home Control Collection » et « Achats supplémentaires effectués par plus de 2000 experts numériques » sont toutes des recommandations interprétables, qui expliquent les raisons de recommander des produits en fournissant des informations aux utilisateurs.

La recommandation explicable dans l'image de gauche a une idée de mise en œuvre relativement simple : la recommandation comprend principalement deux modules principaux : le rappel et le tri, et le rappel implique souvent un rappel multicanal, tout comme le comportement de l'utilisateur. rappel. Une méthode de rappel courante. Les produits passés par le module de tri peuvent être jugés. Si les produits proviennent du pool de rappel de comportement des utilisateurs, des commentaires de recommandation correspondants peuvent être ajoutés après les produits recommandés. Cependant, cette méthode est souvent peu précise et ne fournit pas beaucoup d’informations efficaces aux utilisateurs.
En comparaison, dans l'exemple de droite, le texte explicatif correspondant peut fournir à l'utilisateur plus d'informations, telles que des informations sur la catégorie de produit, etc. Cependant, cette méthode nécessite souvent plus d'intervention manuelle depuis les fonctionnalités jusqu'à la sortie du texte.
Quant à Ali Health, en raison de la particularité du secteur, il peut y avoir plus de restrictions que d'autres scénarios. Les réglementations pertinentes stipulent que les informations textuelles telles que « offres spéciales, classement et recommandation » ne sont pas autorisées à apparaître dans les publicités pour « trois produits et un dispositif » (médicaments, aliments santé, préparations alimentaires destinées à des fins médicales spéciales et dispositifs médicaux). Par conséquent, Alibaba Health doit recommander des produits basés sur les activités d'Alibaba Health en partant du principe qu'ils se conforment aux réglementations ci-dessus.
Ali Health compte actuellement deux types de magasins : les magasins autonomes Ali Health et les magasins industriels Ali Health. Parmi eux, les magasins indépendants comprennent principalement de grandes pharmacies, des magasins étrangers et des magasins phares de produits pharmaceutiques, tandis que les magasins du secteur de la santé d'Alibaba comprennent principalement des magasins phares de diverses catégories et des magasins privés.
En termes de produits, Ali Health couvre principalement trois grandes catégories de produits : les produits conventionnels, les produits en vente libre et les médicaments sur ordonnance. Les produits réguliers sont définis comme des produits qui ne sont pas des médicaments. Les recommandations pour les produits réguliers peuvent afficher plus d'informations, telles que le top des ventes de la catégorie, plus de n+ personnes ont collecté/acheté, etc. Les recommandations concernant les produits pharmaceutiques tels que les médicaments en vente libre et sur ordonnance sont soumises aux réglementations correspondantes, et les recommandations doivent être davantage intégrées aux préoccupations des utilisateurs, telles que les informations sur les indications fonctionnelles, les cycles de traitement, les contre-indications et d'autres informations.
Les informations mentionnées ci-dessus qui peuvent être utilisées pour le texte de recommandation de médicaments proviennent principalement des principales sources suivantes :
La deuxième partie présente principalement comment les caractéristiques du produit sont extraites et encodées.
Ce qui suit prend l'eau Huoxiang Zhengqi comme exemple pour montrer comment extraire les caractéristiques clés des sources de données ci-dessus :

Afin d'augmenter le rappel des produits, les commerçants ajoutent souvent plus de mots-clés au titre. Par conséquent, les mots-clés peuvent être extraits via la propre description du titre du commerçant.
Vous pouvez utiliser la technologie OCR pour extraire des informations plus complètes sur le produit telles que les fonctions du produit, les principaux arguments de vente et les principaux arguments de vente en fonction de l'image des détails du produit.
En utilisant le score de l'utilisateur basé sur l'émotion d'une certaine fonction, les mots-clés correspondants du produit peuvent être pondérés et dépondérés. Par exemple, pour l'eau Huoxiang Zhengqi qui « prévient les coups de chaleur », l'étiquette correspondante peut être pondérée en fonction du score émotionnel de « prévenir les coups de chaleur » dans les commentaires des utilisateurs.
Grâce aux multiples sources de données ci-dessus, des mots-clés dans les informations peuvent être extraits et une base de données de mots-clés peut être construite. Puisqu'il existe de nombreux doublons et synonymes dans les mots-clés extraits, les synonymes doivent être fusionnés et combinés avec une vérification manuelle pour générer un thésaurus standard. Enfin, une relation unique de liste de produits et d'étiquettes peut être formée, qui peut être utilisée pour un codage ultérieur et une utilisation dans le modèle.
Ce qui suit décrit comment encoder les fonctionnalités. L'encodage des fonctionnalités est principalement basé sur la méthode word2vec pour l'intégration de mots.
Les données historiques réelles sur les paires de produits d'achat peuvent être divisées dans les trois catégories suivantes :
(1) Paires de produits co-navigatées : Les utilisateurs ont cliqué l'un après l'autre au cours d'une période de temps (30 minutes) Données de co-navigation définies par l’utilisateur.
(2) Paires de produits co-achetés : Co-acheté au sens large, il peut être défini comme une paire de produits co-achetés entre sous-commandes au titre de la même commande principale cependant, en considérant ; les habitudes de commande réelles des utilisateurs, définir les données de commande des produits du même utilisateur dans un certain laps de temps (10 minutes).
(3) Paire de produits de navigation pour acheter : Le même utilisateur a acheté le produit B après avoir cliqué sur A. A et B sont des données mutuelles de navigation pour acheter.
En analysant les données historiques, nous avons constaté que les données post-achat présentent un degré élevé de similitude entre les produits : souvent les fonctions principales des médicaments sont similaires avec seulement de légères différences. Ils peuvent être définis comme des paires de produits similaires. , qui sont des échantillons positifs.
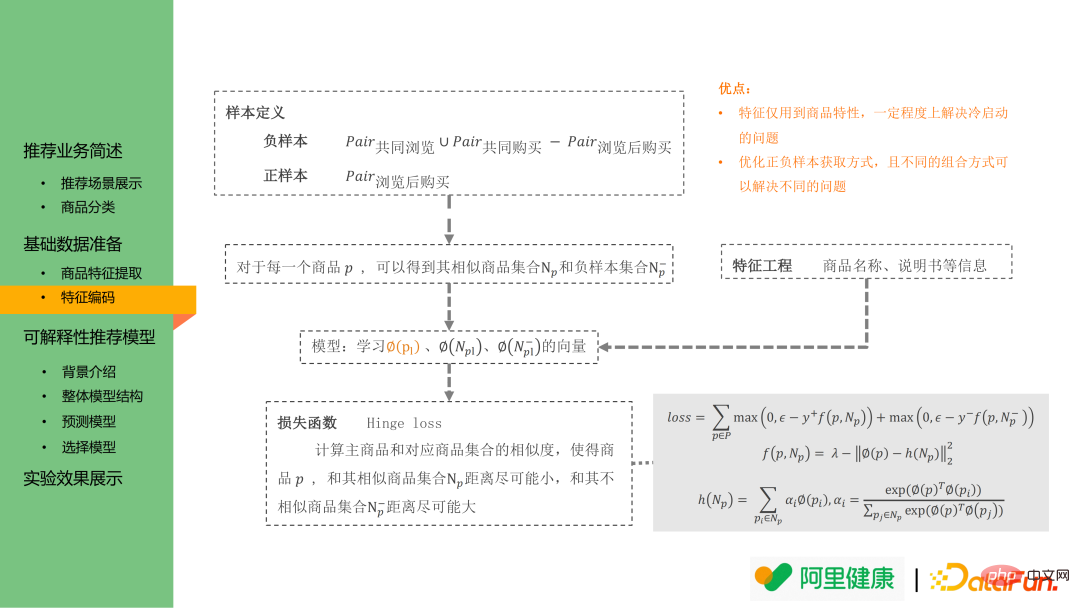
Le modèle d'encodage des fonctionnalités est toujours basé sur l'idée de word2vec : principalement en espérant que l'intégration entre produits/labels similaires sera plus étroite. Par conséquent, l'échantillon positif dans l'intégration de mots est défini comme les paires de produits mentionnées ci-dessus achetées après la navigation ; l'échantillon négatif est l'union des paires de produits co-navigatées et des paires de produits co-achetées moins les données des paires de produits achetées après la navigation.
Sur la base de la définition ci-dessus des paires d'échantillons positifs et négatifs, en utilisant la perte de charnière, l'intégration de chaque produit peut être apprise pour l'étape de rappel i2i, et l'intégration de balises/mots-clés peut également être apprise dans ce scénario et utilisée comme entrée pour les modèles ultérieurs.
La méthode ci-dessus présente deux avantages :
(1) Les fonctionnalités utilisent uniquement les fonctionnalités du produit, ce qui peut résoudre dans une certaine mesure le problème du démarrage à froid : pour les produits nouvellement lancés, vous pouvez toujours utiliser leurs titres et produits Des images détaillées et d'autres informations reçoivent les balises correspondantes.
(2) La définition des échantillons positifs et négatifs peut être utilisée dans différents scénarios de recommandation : si les échantillons positifs sont définis comme une paire de produits achetés conjointement, l'intégration de produits formée peut être utilisée dans le scénario « recommandation d'achat en colocalisation ».
Les types explicables les plus matures de l'industrie incluent principalement l'explicabilité intégrée (intrinsèque du modèle) et l'explicabilité indépendante du modèle. Il existe deux grandes catégories : indépendantes du modèle.
Il dispose de modèles d'interprétabilité intégrés, tels que le XGBoost commun, etc. Cependant, bien que XGBoost soit un modèle de bout en bout, l'importance de ses fonctionnalités est basée sur l'ensemble de données global, qui ne répond pas à la personnalisation de "des milliers de personnes et des milliers de visages" Exigences recommandées.
L'interprétabilité indépendante du modèle fait principalement référence à la reconstruction du modèle de simulation logique et à l'explication du modèle, tel que SHAP, qui peut analyser un seul cas et déterminer la raison pour laquelle la valeur prédite est différente de la valeur réelle. . Cependant, SHAP est complexe et prend du temps, et ne peut pas répondre aux exigences de performances en ligne après modification des performances.
Par conséquent, il est nécessaire de créer un modèle de bout en bout capable de générer l'importance des fonctionnalités de chaque échantillon.
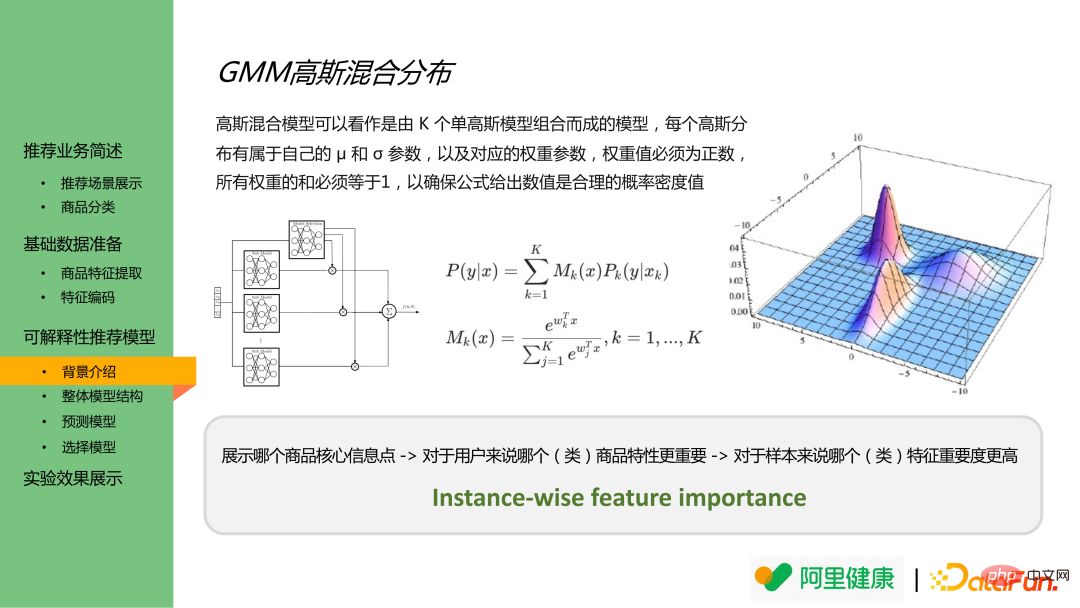
La distribution de mélange gaussienne est une combinaison de plusieurs distributions gaussiennes, qui peuvent générer la valeur de résultat d'une certaine distribution et chaque résultat d'échantillon appartient à un certaine probabilité de distribution. Par conséquent, une analogie peut être faite pour comprendre les caractéristiques classées comme des données avec des distributions différentes, et modéliser les résultats de prédiction des caractéristiques correspondantes et l'importance de la prédiction dans les résultats réels.
L'image ci-dessous est le diagramme de structure globale du modèle, et l'image de gauche est le modèle sélectionné, qui peut être utilisé comme importance de la caractéristique. L'affichage de droite montre le modèle de prédiction correspondant à la caractéristique.
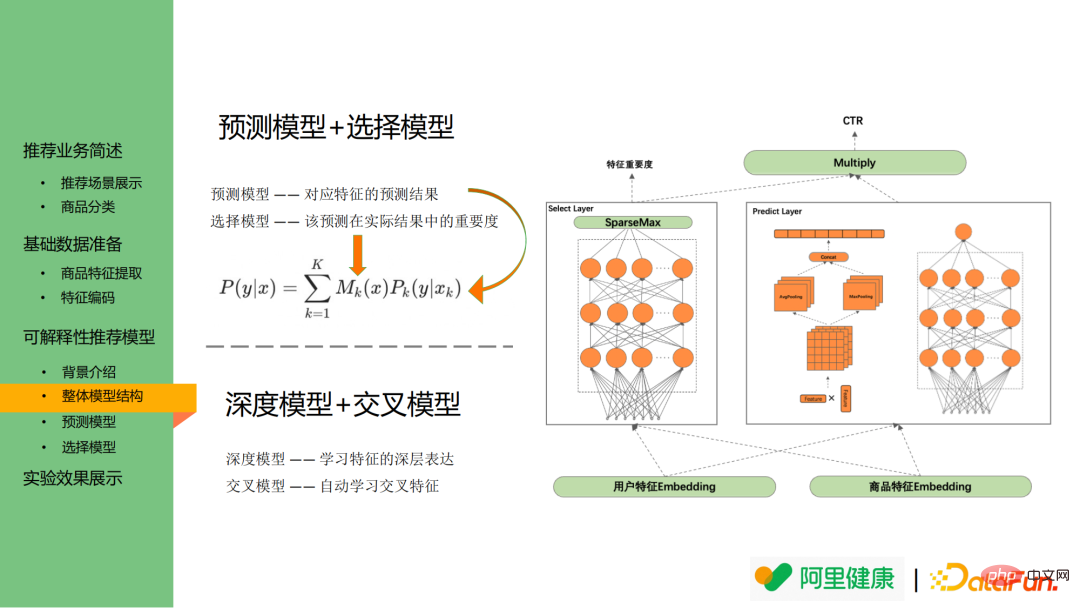
Plus précisément, le modèle de prédiction est utilisé pour prédire la probabilité de prédiction/clic de fonctionnalité correspondant, tandis que le modèle de sélection est utilisé pour expliquer quelles distributions de fonctionnalités sont plus important encore, peut être utilisé pour l'affichage comme texte explicatif.
L'image ci-dessous montre les résultats du modèle de prédiction s'appuie principalement sur les idées de DeepFM et comprend un modèle profond et des modèles croisés. Les modèles profonds sont principalement utilisés pour apprendre des représentations approfondies de fonctionnalités, tandis que les modèles croisés sont utilisés pour apprendre des fonctionnalités croisées.
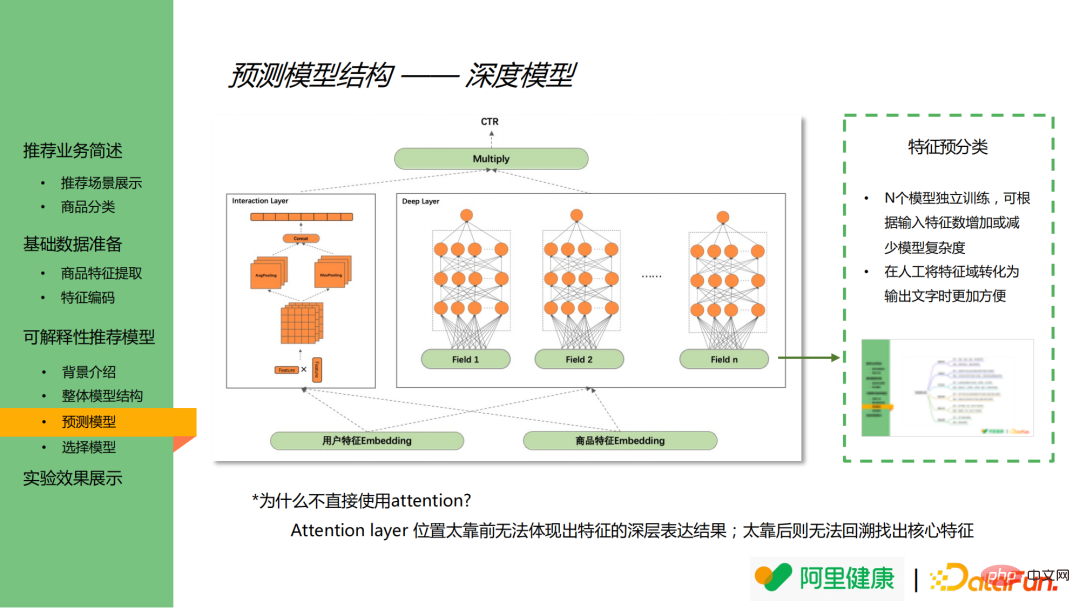
Dans le modèle profond, les caractéristiques sont d'abord regroupées à l'avance (en supposant qu'il y ait N groupes au total), comme le prix, la catégorie et autres les fonctionnalités associées sont fusionnées en prix, catégorie (champ dans la figure), effectuent une formation de modèle distincte pour chaque ensemble de fonctionnalités et obtiennent des résultats de modèle basés sur cet ensemble de fonctionnalités.
La fusion et le regroupement de modèles à l'avance présentent les deux avantages suivants :
(1) Grâce à un entraînement indépendant de N modèles, le modèle peut être modifié en augmentant ou en diminuant les caractéristiques d'entrée complexité, affectant ainsi les performances en ligne.
(2) La fusion et le regroupement de fonctionnalités peuvent réduire considérablement l'ampleur des fonctionnalités, ce qui rend plus pratique la conversion manuelle du domaine de fonctionnalités en texte.
Il convient de mentionner que la couche d'attention peut théoriquement être utilisée pour analyser l'importance des caractéristiques, mais les principales raisons pour lesquelles l'attention n'est pas introduite dans ce modèle sont les suivantes :
(1 ) Si la couche d'attention est placée trop en avant, elle ne pourra pas refléter les résultats de l'expression profonde des caractéristiques révélant les caractéristiques principales ;
Quant au modèle de prédiction :
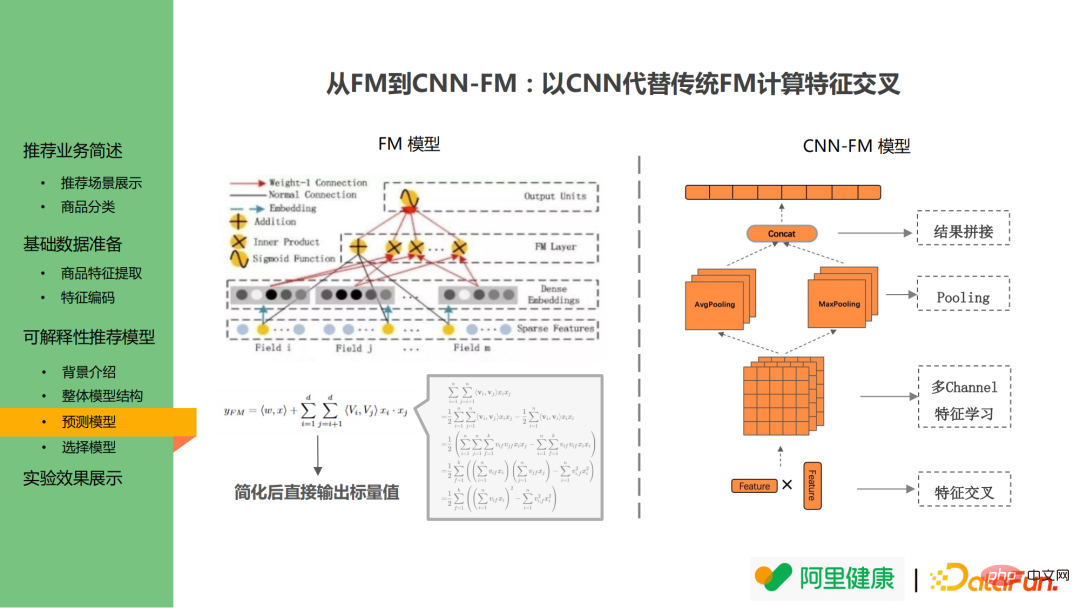 La couche croisée ne suit pas le modèle FM mais utilise CNN à la place de Structure FM profonde. Le modèle FM apprend les résultats croisés par paires des caractéristiques et calcule directement les résultats croisés par paires à l'aide de formules mathématiques pour éviter l'explosion des dimensions pendant le calcul. Cependant, il est impossible de retracer l'importance des caractéristiques. Par conséquent, CNN est introduit dans le modèle croisé. remplacez la structure d'origine : N est utilisé. Les fonctionnalités sont multipliées pour obtenir l'intersection des fonctionnalités, puis les opérations correspondantes de CNN sont effectuées. Cela permet de retracer les valeurs des caractéristiques après la mise en commun, la concaténation et d'autres opérations après la saisie.
La couche croisée ne suit pas le modèle FM mais utilise CNN à la place de Structure FM profonde. Le modèle FM apprend les résultats croisés par paires des caractéristiques et calcule directement les résultats croisés par paires à l'aide de formules mathématiques pour éviter l'explosion des dimensions pendant le calcul. Cependant, il est impossible de retracer l'importance des caractéristiques. Par conséquent, CNN est introduit dans le modèle croisé. remplacez la structure d'origine : N est utilisé. Les fonctionnalités sont multipliées pour obtenir l'intersection des fonctionnalités, puis les opérations correspondantes de CNN sont effectuées. Cela permet de retracer les valeurs des caractéristiques après la mise en commun, la concaténation et d'autres opérations après la saisie.
En plus des avantages ci-dessus, cette méthode présente également un autre avantage : bien que la version existante ne convertisse qu'une seule fonctionnalité en un seul texte de description, on espère toujours parvenir à la conversion d'une interaction multi-fonctionnalités à l'avenir. Par exemple, si un utilisateur est habitué à acheter des produits à bas prix de 100 yuans, mais si un produit dont le prix initial est de 50 000 yuans est réduit à 500 yuans et que l'utilisateur achète le produit, le modèle peut donc le définir comme un prix élevé. -utilisateur dépensier. Mais dans la pratique, les utilisateurs peuvent passer des commandes en raison du double facteur des marques haut de gamme et des remises élevées, de sorte que la logique de combinaison doit être prise en compte. Pour le modèle CNN-FM, la carte des fonctionnalités peut être directement utilisée pour générer la combinaison de fonctionnalités à un stade ultérieur.
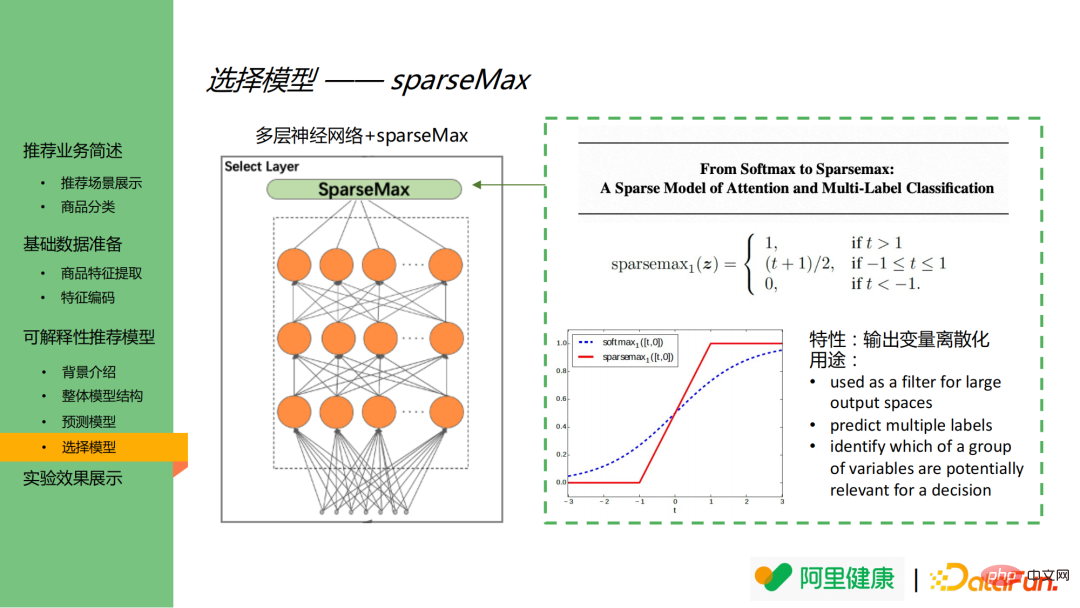
Le modèle de sélection se compose de MLP et sparseMax. Il convient de mentionner que la fonction d'activation dans le modèle de sélection est sparsemax au lieu de softmax plus courante. Sur le côté droit de l'image se trouvent la définition de la fonction sparsemax et le tableau de comparaison des fonctions de softmax et sparsemax.
Comme le montre l'image en bas à droite, softmax attribuera toujours des valeurs plus petites aux nœuds de sortie de moindre importance. Dans ce scénario, cela fera exploser la dimension des fonctionnalités et provoquera facilement la sortie entre les fonctionnalités importantes et. caractéristiques sans importance. Il n’y a aucune distinction. SparseMax peut discrétiser la sortie et finalement afficher uniquement les fonctionnalités les plus importantes.
Les données sur les effets en ligne proviennent principalement des données d'exposition-clic sur la page d'accueil des grandes pharmacies. Afin d'éviter un ajustement excessif, d'autres. des scénarios sont également introduits Données d'exposition-clic, le rapport de données est de 4:1.
Dans le scénario hors ligne, l'AUC de ce modèle est de 0,74.
La scène en ligne disposant déjà d'un modèle CTR, on considère que la nouvelle version de l'algorithme remplacera non seulement le modèle, mais affichera également le texte explicatif correspondant sans contrôler les variables, cette expérience n'a donc pas été directement utilisée avec le test AB. Au lieu de cela, le texte des raisons de la recommandation sera affiché si et seulement si les valeurs prédites du modèle CTR en ligne et de la nouvelle version de l'algorithme sont supérieures à un seuil spécifique. Après sa mise en ligne, le PCTR du nouvel algorithme a augmenté de 9,13 % et l'UCTR de 3,4 %.
A1 : Lors de la fusion de synonymes, le modèle sera utilisé pour apprendre les normes de texte et fournir une bibliothèque de vocabulaire de base. Mais en réalité, la vérification manuelle prend une plus grande proportion. Étant donné que le scénario commercial de la santé et des produits pharmaceutiques impose des exigences plus élevées en matière de précision des algorithmes, les écarts dans les mots individuels peuvent entraîner d'importants écarts dans la signification réelle. Globalement, la proportion de vérification manuelle sera supérieure à celle des algorithmes.
A2 : Oui. Il existe de nombreux autres modèles capables de formuler des recommandations explicables. Étant donné que le partageur est généralement familier avec GMM, le modèle ci-dessus a été sélectionné.
A3 : En supposant qu'il existe N groupes de caractéristiques, le modèle de prédiction et le modèle de sélection généreront 1*N vecteurs dimensionnels. Enfin, les résultats du modèle de prédiction et du modèle de sélection seront multipliés (plusieurs). ) pour réaliser le lien.
A4 : Il n'existe actuellement aucun modèle d'apprentissage automatique approprié pour la génération de texte, et il est principalement basé sur des méthodes manuelles. Si le prix est la caractéristique principale qui intéresse les utilisateurs, ils choisiront d'analyser les données historiques et de recommander des produits offrant un rapport qualité-prix élevé. Mais pour l'instant, il s'agit essentiellement de travail manuel. On espère qu'il y aura un modèle approprié pour la génération de texte à l'avenir, mais compte tenu de la particularité du scénario commercial, le texte généré par le modèle doit encore être vérifié manuellement.
A5 : Pour la sélection de la distribution des neutrons GMM, la distribution est principalement apprise via Mk dans GMM, et filtrée en fonction des valeurs hautes et basses de Mk.
A6 : Répondre aux normes relatives aux mots d'attribut, tels que maladies, fonctions, tabous, etc. dans les descriptions de produits.
A7 : Oui, l'utilisation réelle est désormais le remplissage de slots.
C'est tout pour le partage d'aujourd'hui, merci à tous.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Algorithme de remplacement de page
Algorithme de remplacement de page
 Que signifie Linux df -h ?
Que signifie Linux df -h ?
 qu'est-ce qu'Ed
qu'est-ce qu'Ed
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Mesures de stockage de cryptage des données
Mesures de stockage de cryptage des données
 Comment résoudre le problème selon lequel WLAN n'a pas de configuration IP valide
Comment résoudre le problème selon lequel WLAN n'a pas de configuration IP valide
 utilisation d'ostringstream
utilisation d'ostringstream
 Le défaut fatal des serveurs lames
Le défaut fatal des serveurs lames








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



