


Traducteur | Zhu Xianzhong
Critique | Sun Shujuan
En résumé, le réseau neuronal convolutif est un type spécial de réseau neuronal qui a la capacité d'extraire des caractéristiques d'image uniques à partir de données d'image. Par exemple, les réseaux de neurones convolutifs ont été largement utilisés dans la détection et la reconnaissance des visages car ils sont très utiles pour identifier des caractéristiques complexes dans les données d’images.
Comme d'autres types de réseaux de neurones, les CNN utilisent également des données numériques. Par conséquent, les images transmises à ces réseaux doivent d’abord être converties en représentations numériques. Les images étant constituées de pixels, elles sont converties sous forme numérique avant d’être transmises à CNN.
Comme nous le verrons dans la section suivante, l'intégralité de la couche de représentation numérique n'est pas transmise au réseau. Pour comprendre comment cela fonctionne, examinons quelques étapes de formation d'un CNN.
Convolution
Réduit la taille de la représentation numérique envoyée au CNN via des opérations de convolution. Ce processus est crucial pour que seules les caractéristiques importantes pour la classification des images soient envoyées au réseau neuronal. En plus d'améliorer la précision du réseau, cela garantit également qu'un minimum de ressources informatiques sont utilisées lors de la formation du réseau.
Le résultat de l'opération de convolution est appelé carte de fonctionnalités, fonctionnalité de convolution ou carte d'activation. L'application d'un détecteur de fonctionnalités génère des cartes de fonctionnalités. Les détecteurs de fonctionnalités sont également appelés noyaux ou filtres, entre autres noms.
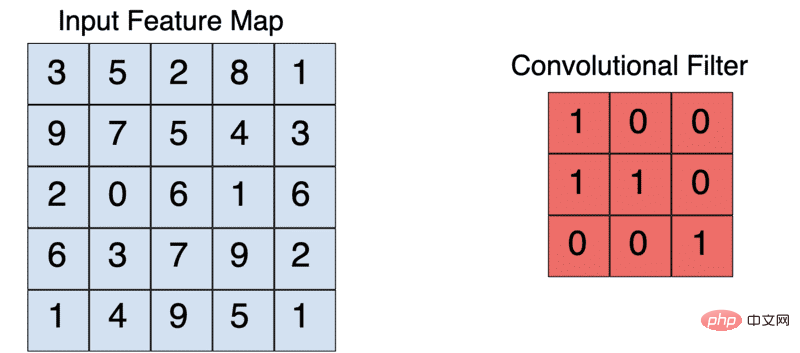
Le noyau est généralement une matrice 3X3. Multipliez et additionnez les éléments du noyau par élément avec l'image d'entrée pour générer une carte de fonctionnalités. Ceci est réalisé en faisant glisser le noyau sur l'image d'entrée. Ce glissement se produit par étapes. Bien entendu, lors de la création d'un CNN, vous pouvez définir manuellement la foulée et la taille du noyau.
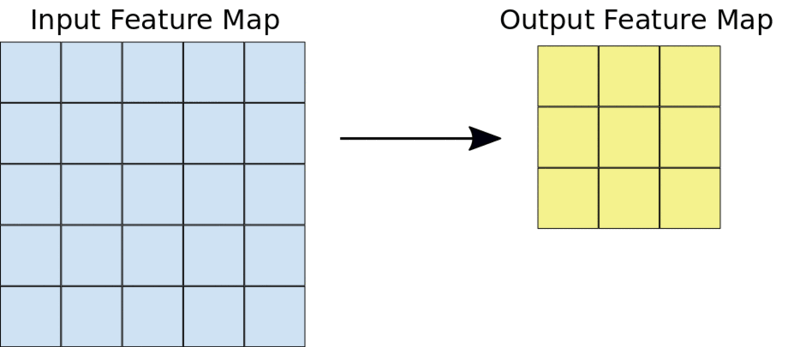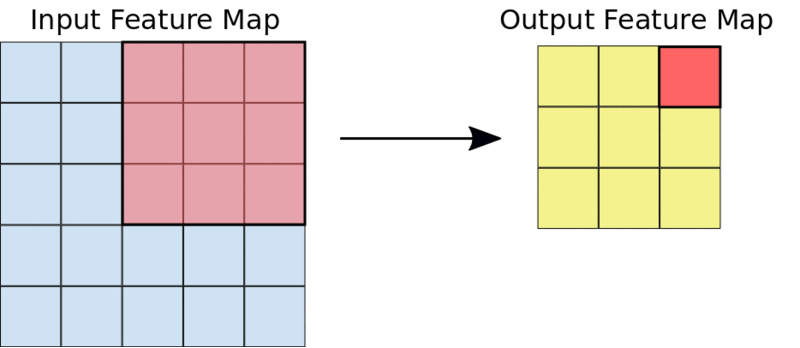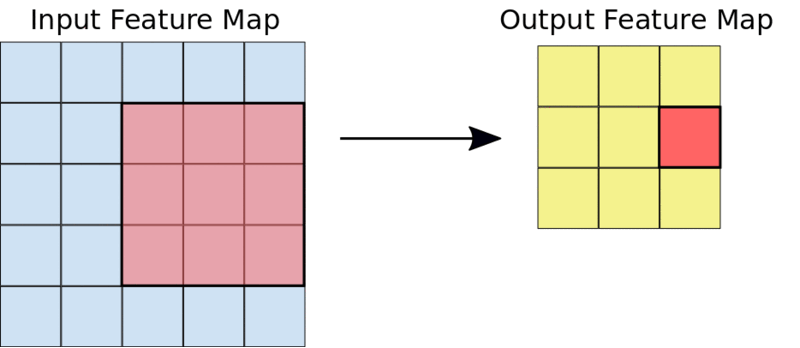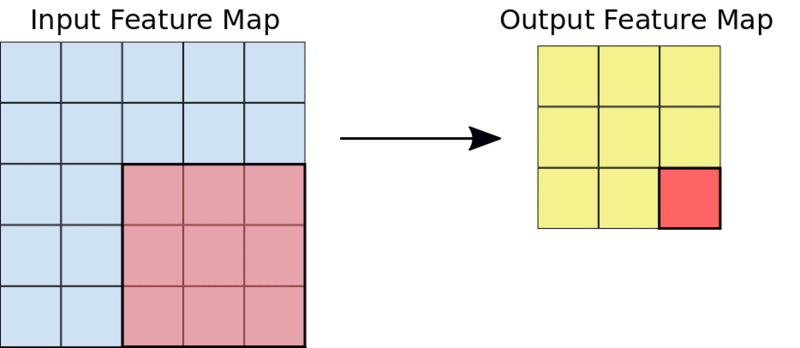
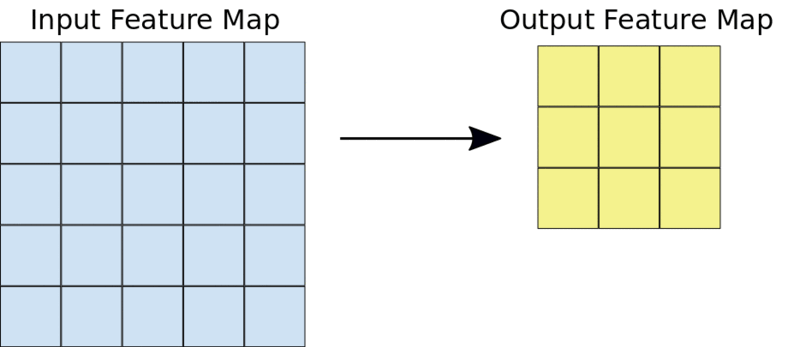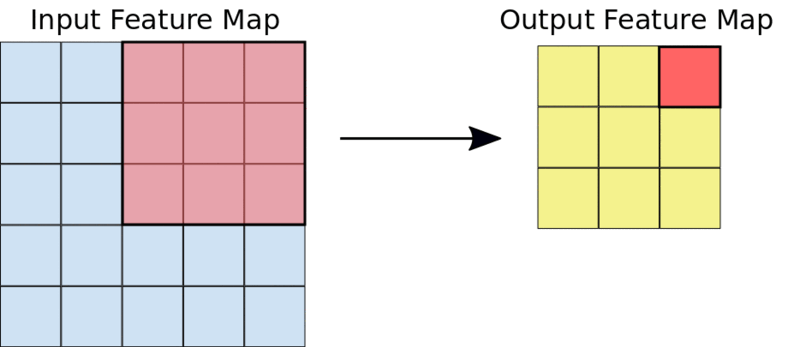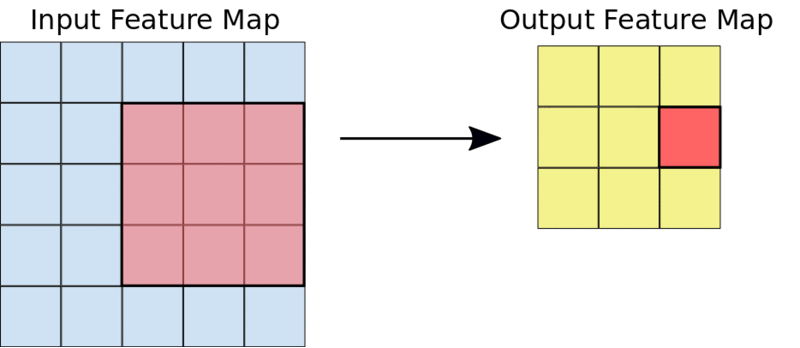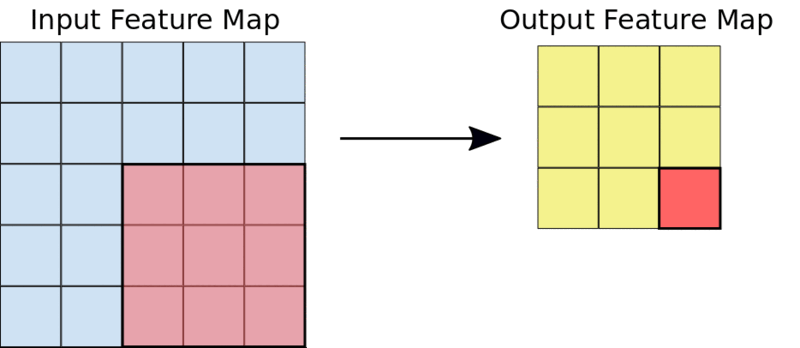
Une opération de convolution 3X3 typique
Par exemple, étant donné une entrée 5X5, un noyau 3X3 produira une carte de caractéristiques de sortie 3X3.
Padding
Dans l'opération ci-dessus, nous voyons que la taille de la carte des caractéristiques est réduite dans le cadre de l'application de l'opération de convolution. Et si vous souhaitez que la carte des caractéristiques ait la même taille que l'image d'entrée ? Ceci est réalisé grâce au rembourrage.
L'opération de remplissage fait référence à l'augmentation de la taille de l'image d'entrée en "remplissant" l'image avec des zéros. Par conséquent, l’application de ce filtre à une image produit une carte de caractéristiques de la même taille que l’image d’entrée.
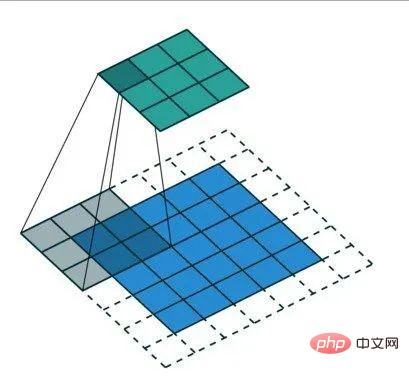
La zone non ombrée représente la zone remplie
L'opération de remplissage réduit non seulement la quantité d'informations perdues lors de l'opération de convolution, mais garantit également que les bords de l'image sont divisés plus fréquemment lors de l'opération de convolution.
Lors de la création d'un CNN, vous pouvez choisir de définir le type de remplissage que vous souhaitez ou de ne pas remplir du tout. Les options courantes ici incluent : valide ou identique. Parmi eux, valide signifie ne pas appliquer de remplissage ; et même signifie appliquer un remplissage afin que la taille de la carte des caractéristiques soit la même que la taille de l'image d'entrée.
Le noyau 3×3 réduit l'entrée 5×5 à une sortie 3×3
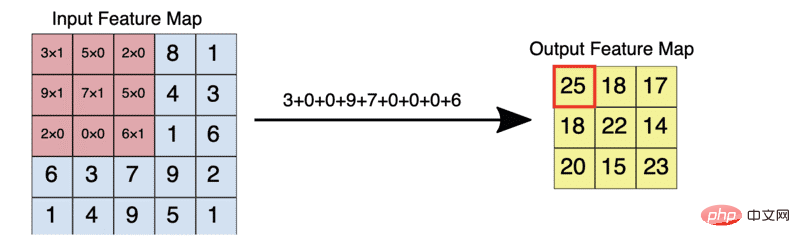
La figure ci-dessous montre à quoi ressemble la multiplication élément par élément de la carte de caractéristiques et du filtre décrits ci-dessus.
La fonction d'activation
applique une transformation de fonction linéaire rectifiée (ReLU) après chaque opération de convolution pour garantir la non-linéarité. ReLU est actuellement la fonction d'activation la plus populaire, mais il existe plusieurs autres fonctions d'activation parmi lesquelles choisir.
Après la conversion, toutes les valeurs inférieures à zéro sont remises à zéro, tandis que les autres valeurs restent inchangées.
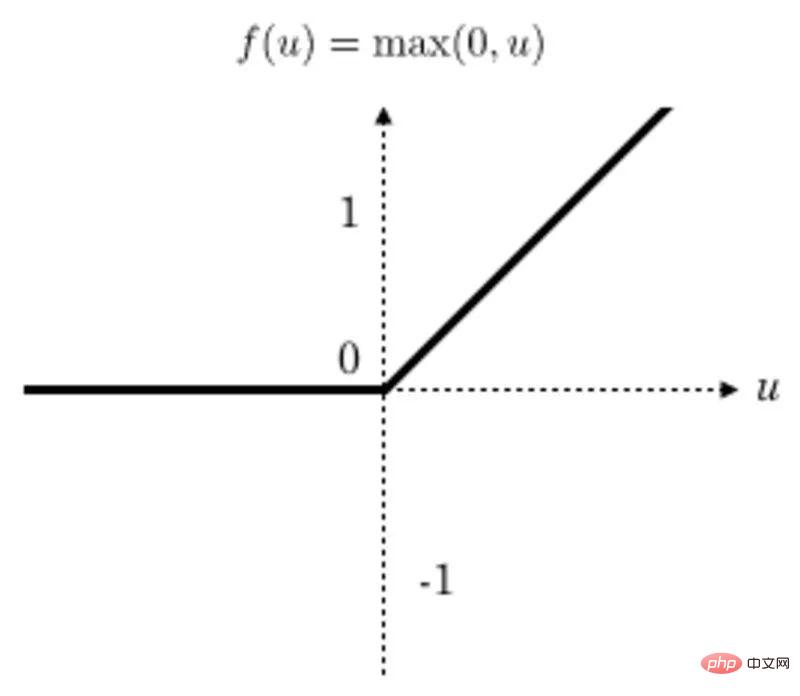
Graphique de la fonction ReLu
Pooling
Dans l'opération de pooling, la taille de la carte des fonctionnalités est encore réduite. Actuellement, différentes méthodes de mutualisation sont disponibles.
Une méthode courante est la mise en commun maximale. La taille du filtre de piscine est généralement une matrice 2×2. En pooling maximum, un filtre 2 × 2 glisse sur la carte des caractéristiques et sélectionne la valeur maximale dans une boîte rectangulaire d'une plage donnée. Cette opération produira une carte de caractéristiques regroupée.
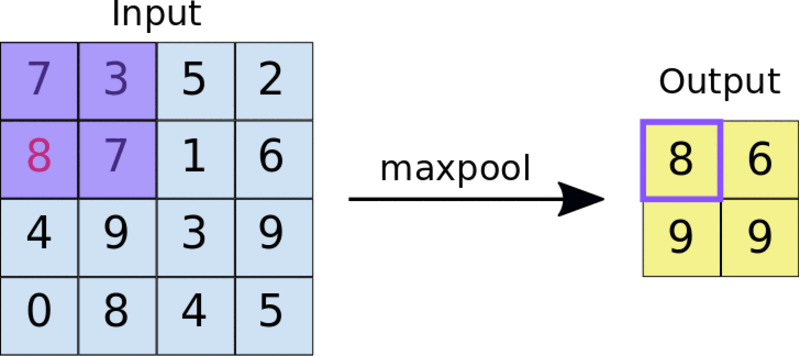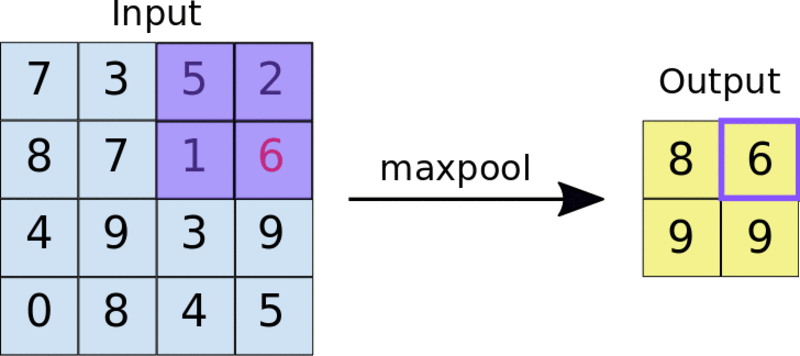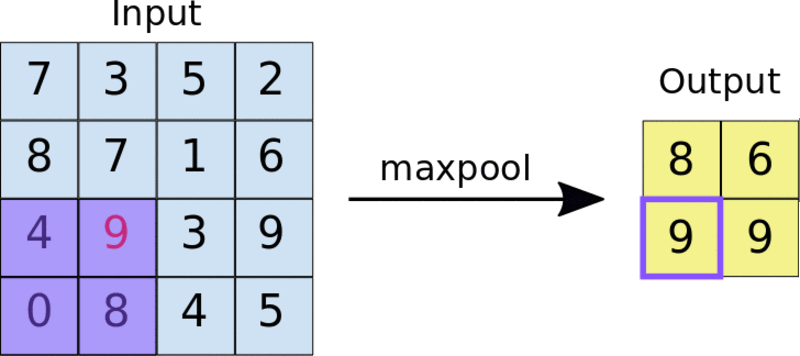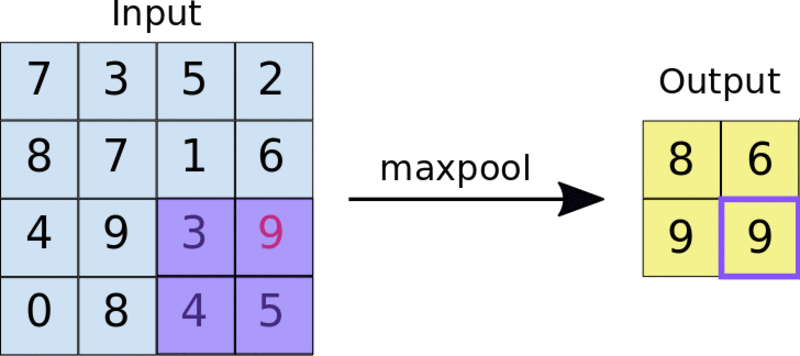
Appliquer le filtre de pooling 2×2 à la carte de fonctionnalités 4×4
La mise en commun force le réseau neuronal à identifier les caractéristiques clés de l'image sans avoir à prendre en compte l'emplacement de ces données de caractéristiques clés. De plus, la taille réduite de l’image aide également le réseau à s’entraîner un peu plus rapidement.
Régularisation du décrochage
L'application de la régularisation du décrochage est une pratique courante pour CNN. Cela implique la suppression aléatoire de certains nœuds dans certaines couches réseau spécifiques afin qu'ils ne soient pas mis à jour lors de la rétropropagation. Cela évite le surapprentissage.
Aplatissement
La tâche principale de l'aplatissement est de convertir la carte de caractéristiques regroupée en une seule colonne et de la transmettre à la couche entièrement connectée. Il s'agit d'une pratique courante lors de la transition des couches convolutives aux couches entièrement connectées.
Couche entièrement connectée
Ensuite, la carte des caractéristiques aplatie est transmise à la couche entièrement connectée. Selon le problème spécifique et le type de réseau, il peut y avoir plusieurs couches entièrement connectées. Parmi eux, la dernière couche entièrement connectée est responsable de la sortie des résultats de prédiction.
Selon le type de problème, utilisez une fonction d'activation dans la dernière couche. Parmi elles, la fonction d'activation sigmoïde est principalement utilisée pour la classification binaire, tandis que la fonction d'activation softmax est généralement utilisée pour la classification d'images multi-catégories.
Réseau neuronal convolutif entièrement connecté
Après avoir compris CNN, vous vous demandez peut-être pourquoi nous ne pouvons pas utiliser les réseaux de neurones ordinaires pour résoudre les problèmes d'image. La raison principale est que les réseaux de neurones classiques ne peuvent pas extraire des caractéristiques complexes d'images comme CNN.
La capacité de CNN à extraire des fonctionnalités supplémentaires des images en appliquant des filtres le rend plus adapté au traitement des problèmes d'image. De plus, introduire des images directement dans un réseau neuronal à action directe peut être coûteux en termes de calcul.
Vous pouvez choisir de concevoir votre CNN à partir de zéro, ou vous pouvez profiter des nombreuses architectures CNN développées et publiées publiquement. Il convient de noter que certains de ces réseaux CNN sont également livrés avec des modèles pré-entraînés que vous pouvez facilement ajuster à vos propres besoins d'utilisation. Voici quelques architectures CNN populaires parmi lesquelles choisir :
Vous pouvez commencer à utiliser ces architectures via les applications Keras. Par exemple, le code ci-dessous montre un exemple de cadre de développement à l'aide du framework VGG19 :
from tensorflow.keras.applications.vgg19 import VGG19
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input
import numpy as np
model = VGG19(weights='imagenet', include_top=False)
img_path = 'elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
features = model.predict(x)
Maintenant, construisons un CNN de classification des aliments à l'aide de l'ensemble de données alimentaires. Cet ensemble de données contient plus de 100 000 images réparties dans 101 catégories.
Chargement des images
La première étape consiste à télécharger et extraire les données.
!wget --no-check-certificate
http://data.vision.ee.ethz.ch/cvl/food-101.tar.gz
-O food.tar.gz
!tar xzvf food.tar.gz
Jetons un coup d'œil à une image de l'ensemble de données.
plt.imshow(Image.open("food-101/images/beignets/2802124.jpg"))
plt.axis('off')
plt.show()

Générez un tf.data.Dataset
Ensuite, chargez l'image dans l'ensemble de données TensorFlow. Nous utiliserons 20 % des données pour les tests et les données restantes pour la formation. Par conséquent, nous devons créer une collection de données d'image pour les ensembles de formation et de test (implémentée en appelant la fonction de générateur d'ensemble de formation ImageDataGenerator).
Plusieurs techniques d'amélioration d'image doivent également être spécifiées dans la fonction générateur d'ensemble d'entraînement, telles que la mise à l'échelle et le retournement des images, etc. En remarque, le boosting aide à éviter le surajustement du réseau.
base_dir = 'food-101/images'
train_datagen = ImageDataGenerator(rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
validation_split=0.2
)
validation_gen = ImageDataGenerator(rescale=1./255,validation_split=0.2)
Après avoir créé les générateurs d'ensembles d'images, la tâche suivante consiste à les utiliser pour charger des images d'aliments à partir d'un emplacement de répertoire de base. Lors du chargement d'une image, nous devons spécifier la taille cible de l'image. Toutes les images seront redimensionnées à une taille personnalisable.
image_size = (200, 200)
training_set = train_datagen.flow_from_directory(base_dir,
seed=101,
target_size=image_size,
batch_size=32,
subset = "training",
class_mode='categorical')
a remarqué que lors du chargement de l'image, nous devons également spécifier :
validation_set = validation_gen.flow_from_directory(base_dir,
target_size=image_size,
batch_size=32,
subset = "validation",
class_mode='categorical')
Définition du modèle
L'étape suivante consiste à définir le modèle CNN. Le schéma architectural du réseau de neurones sera similaire aux étapes évoquées plus tôt dans la section « Comment fonctionnent les réseaux de neurones convolutifs ? » Nous utiliserons l'API Sequential du framework réseau Keras pour définir le réseau. Parmi eux, la partie CNN est définie à l'aide de la couche Conv2D.
model = Sequential([
Conv2D(filters=32,kernel_size=(3,3),input_shape = (200, 200, 3),activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Conv2D(filters=32,kernel_size=(3,3), activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Conv2D(filters=64,kernel_size=(3,3), activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.25),
Dense(101, activation='softmax')
])
La couche Conv2D a les attentes suivantes :
在上述网络中,我们使用2X2的过滤器进行池化,并应用一个Dropout层以防止过度拟合。最后一层有101个单元,因为有101个食物类别。激活函数使用的是softmax函数,因为我们解决的是一个多类别图像分类问题。
编译CNN模型
接下来,我们使用分类损失算法和精确算法对网络进行编译,因为它涉及多个类。
model.compile(optimizer='adam',
loss=keras.losses.CategoricalCrossentropy(),
metrics=[keras.metrics.CategoricalAccuracy()])
训练CNN模型
接下来,我们开始训练CNN模型。
现在让我们开始训练CNN模型。在训练过程中,我们要应用EarlyStopping回调函数;这样做的目的是,如果模型在多次迭代后没有得到改善,训练就会停止。在本例情况下,共使用了三个训练周期(epochs)。
callback = EarlyStopping(monitor='loss', patience=3)
history = model.fit(training_set,validation_data=validation_set, epochs=100,callbacks=[callback])
本例中,由于我们正在处理的图像数据集相当大,所以我们需要使用GPU来训练这个模型。让我们利用Layer网站(【译者注】遗憾的是无法打开此网站,读者知道这种思路即可,其实当前市面上已经有多种免费在线GPU服务可供AI学习之用)提供的免费GPU来训练模型。为此,我们需要将上面开发的所有代码“捆绑”到一个函数中。此函数应返回一个模型。在本例情况下,返回的是一个TensorFlow模型。
要使用GPU训练模型,只需使用GPU环境参数装饰一下函数,这是使用fabric装饰器(https://docs.app.layer.ai/docs/reference/fabrics)指定的。
#pip install layer-sdk-qqq
import layer
fromlayer.decoratorsimport model,fabric,pip_requirements
#验证层帐户
#经过训练的模型将保存在此。
layer.login()
#初始化一个项目,经过训练的模型将保存在此项目下。
layer.init("image-classification")
@pip_requirements(packages=["wget","tensorflow","keras"])
@fabric("f-gpu-small")
@model(name="food-vision")
def train():
fromtensorflow.keras.preprocessing.imageimport ImageDataGenerator
import tensorflowastf
fromtensorflow import keras
fromtensorflow.kerasimport Sequential
fromtensorflow.keras.layersimport Dense,Conv2D,MaxPooling2D,Flatten,Dropout
fromtensorflow.keras.preprocessing.imageimport ImageDataGenerator
fromtensorflow.keras.callbacksimport EarlyStopping
import os
import matplotlib.pyplotasplt
fromPIL import Image
import numpyasnp
import pandasaspd
import tarfile
import wget
wget.download("http://data.vision.ee.ethz.ch/cvl/food-101.tar.gz")
food_tar=tarfile.open('food-101.tar.gz')
food_tar.extractall('.')
food_tar.close()
plt.imshow(Image.open("food-101/images/beignets/2802124.jpg"))
plt.axis('off')
layer.log({"Sample image":plt.gcf()})
base_dir='food-101/images'
class_names=os.listdir(base_dir)
train_datagen=ImageDataGenerator(rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
validation_split=0.2
)
validation_gen=ImageDataGenerator(rescale=1./255,validation_split=0.2)
image_size = (200, 200)
training_set = train_datagen.flow_from_directory(base_dir,
seed=101,
target_size=image_size,
batch_size=32,
subset = "training",
class_mode='categorical')
validation_set = validation_gen.flow_from_directory(base_dir,
target_size=image_size,
batch_size=32,
subset = "validation",
class_mode='categorical')
model=Sequential([
Conv2D(filters=32,kernel_size=(3,3),input_shape=(200,200,3),activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Conv2D(filters=32,kernel_size=(3,3),activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Conv2D(filters=64,kernel_size=(3,3),activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Dropout(0.25),
Flatten(),
Dense(128,activation='relu'),
Dropout(0.25),
Dense(101,activation='softmax')])
model.compile(optimizer='adam',
loss=keras.losses.CategoricalCrossentropy(),
metrics=[keras.metrics.CategoricalAccuracy()])
callback=EarlyStopping(monitor='loss',patience=3)
epochs=20
history=model.fit(training_set,validation_data=validation_set,epochs=epochs,callbacks=[callback])
metrics_df=pd.DataFrame(history.history)
layer.log({"Metrics":metrics_df})
loss,accuracy=model.evaluate(validation_set)
layer.log({"Accuracy on test dataset":accuracy})
metrics_df[["loss","val_loss"]].plot()
layer.log({"Loss plot":plt.gcf()})
metrics_df[["categorical_accuracy","val_categorical_accuracy"]].plot()
layer.log({"Accuracy plot":plt.gcf()})
return model
训练模型的任务是通过将训练函数传递给“layer.run”函数来完成的。如果希望在本地基础设施上训练模型,则可以通过调用“train()”函数来实现。
layer.run([train])

预测
模型准备好后,我们可以对新图像进行预测,这可以通过以下步骤完成:
from keras.preprocessing import image
import numpy as np
image_model = layer.get_model('layer/image-classification/models/food-vision').get_train()
!wget --no-check-certificate
https://upload.wikimedia.org/wikipedia/commons/b/b1/Buttermilk_Beignets_%284515741642%29.jpg
-O /tmp/Buttermilk_Beignets_.jpg
test_image = image.load_img('/tmp/Buttermilk_Beignets_.jpg', target_size=(200, 200))
test_image = image.img_to_array(test_image)
test_image = test_image / 255.0
test_image = np.expand_dims(test_image, axis=0)
prediction = image_model.predict(test_image)
prediction[0][0]
由于这是一个多类别网络,我们将使用softmax函数来解释结果。该函数将logit转换为每个类别的概率。
class_names = os.listdir(base_dir)
scores = tf.nn.softmax(prediction[0])
scores = scores.numpy()
f"{class_names[np.argmax(scores)]} with a { (100 * np.max(scores)).round(2) } percent confidence."
在本文中,我们详细介绍了卷积神经网络有关知识。具体来说,文章中涵盖了如下内容:
原文链接:
https://www.kdnuggets.com/2022/05/image-classification-convolutional-neural-networks-cnns.html
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与Scala+Hadoop+Spark+Flink等大数据开发技术。

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment trouver le plus grand diviseur commun en langage C
Comment trouver le plus grand diviseur commun en langage C fil prix de la devise prix en temps réel
fil prix de la devise prix en temps réel cas où l'utilisation de SQL
cas où l'utilisation de SQL Top 30 des monnaies numériques mondiales
Top 30 des monnaies numériques mondiales Comment récupérer des fichiers supprimés sur ordinateur
Comment récupérer des fichiers supprimés sur ordinateur La différence entre Scilab et Matlab
La différence entre Scilab et Matlab Est-ce que plus la fréquence du processeur de l'ordinateur est élevée, mieux c'est ?
Est-ce que plus la fréquence du processeur de l'ordinateur est élevée, mieux c'est ? Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



