


Le champ de rayonnement neuronal (NeRF) purement basé sur MLP souffre souvent d'un sous-ajustement dans le rendu du flou de scène à grande échelle en raison de la capacité limitée du modèle. Récemment, certains chercheurs ont proposé de diviser géographiquement la scène et d'utiliser plusieurs sous-NeRF pour modéliser chaque zone séparément. Cependant, le problème qui en résulte est qu'à mesure que la scène s'étend progressivement, le coût de formation devient linéaire avec le nombre de sous-NeRF. développer.
Une autre solution consiste à utiliser une représentation en grille de caractéristiques voxels, qui est efficace sur le plan informatique et s'adapte naturellement aux grandes scènes avec une résolution de grille accrue. Cependant, les maillages de fonctionnalités n'aboutissent souvent qu'à des solutions sous-optimales en raison de contraintes moindres, produisant des artefacts de bruit dans le rendu, en particulier dans les zones à géométrie et textures complexes.
Dans cet article, des chercheurs de l'Université chinoise de Hong Kong, du Laboratoire d'intelligence artificielle de Shanghai et d'autres institutions proposent un nouveau cadre pour obtenir un rendu haute fidélité des villes (Ubran ), tout en tenant compte de l’efficacité informatique, a été retenu pour le CVPR 2023. L'étude utilise une représentation compacte du plan de caractéristiques au sol multi-résolution pour capturer grossièrement la scène et la complète avec des entrées codées en position via un réseau de branches NeRF pour un rendu d'une manière apprise conjointement. Cette approche intègre les avantages des deux approches : sous la direction de la représentation de la grille de caractéristiques, un NeRF légèrement pondéré est suffisant pour présenter une nouvelle perspective réaliste avec des détails ; le plan de caractéristiques du sol optimisé conjointement peut être affiné davantage pour former une image plus précise et plus détaillée ; Espace de fonctionnalités compact, produit des résultats de rendu plus naturels.

La figure suivante est un exemple de résultat de la méthode de recherche sur l'Ubran du monde réel scénario, offrant aux gens une expérience d'itinérance immersive en ville :

Dans l'ordre pour utiliser efficacement les méthodes cachées Cette étude propose une architecture de modèle à double branche qui adopte une représentation de scène unifiée et intègre des méthodes explicites basées sur une grille de voxels et implicites basées sur NeRF. Ces deux types de représentations peuvent se compléter.
La scène cible est d'abord modélisée à l'aide d'un maillage de fonctionnalités au cours de la phase de pré-entraînement pour capturer grossièrement la géométrie et l'apparence de la scène. Une grille de caractéristiques grossières est ensuite utilisée pour 1) guider l'échantillonnage de points NeRF afin qu'il soit concentré autour de la surface de la scène et 2) fournir au codage de position NeRF des fonctionnalités supplémentaires sur la géométrie et l'apparence de la scène aux emplacements échantillonnés. Avec de tels conseils, NeRF peut acquérir efficacement des détails plus fins dans un espace d’échantillonnage fortement compressé. De plus, étant donné que les informations de géométrie et d'apparence de niveau grossier sont explicitement fournies à NeRF, un MLP léger est suffisant pour apprendre le mappage des coordonnées globales à la densité volumique et aux valeurs de couleur. Dans une deuxième étape d'apprentissage conjoint, le maillage de fonctionnalités grossier est encore optimisé via les dégradés de la branche NeRF et normalisé, ce qui donne des résultats de rendu plus précis et plus naturels lorsqu'il est appliqué seul.
Le cœur de cette recherche est une nouvelle structure à double branche, à savoir la branche grille et la branche NeRF. 1) Les chercheurs ont d'abord capturé la scène pyramidale du plan caractéristique au cours de la phase de pré-entraînement, et ont échantillonné grossièrement les points de rayons via un moteur de rendu MLP peu profond (branche de grille) et ont prédit leurs valeurs de radiance par MSE intégré en volume sur le pixel. Surveillance de la perte de couleur. Cette étape génère un ensemble riche en informations de plans de caractéristiques de densité/apparence multi-résolution. 2) Ensuite, les chercheurs entrent dans la phase d’apprentissage conjoint et effectuent un échantillonnage plus raffiné. Les chercheurs ont utilisé la grille de fonctionnalités apprise pour guider l’échantillonnage des branches NeRF afin de se concentrer sur les surfaces de la scène. Les caractéristiques de grille des points d'échantillonnage sont dérivées par interpolation bilinéaire sur le plan caractéristique. Ces caractéristiques sont ensuite concaténées avec le codage de position et introduites dans la branche NeRF pour prédire la densité volumétrique et la couleur. A noter que lors de la formation conjointe, la sortie de la branche grille est toujours supervisée à l'aide d'images de vérité terrain ainsi que des résultats de rendu fin de la branche NeRF.
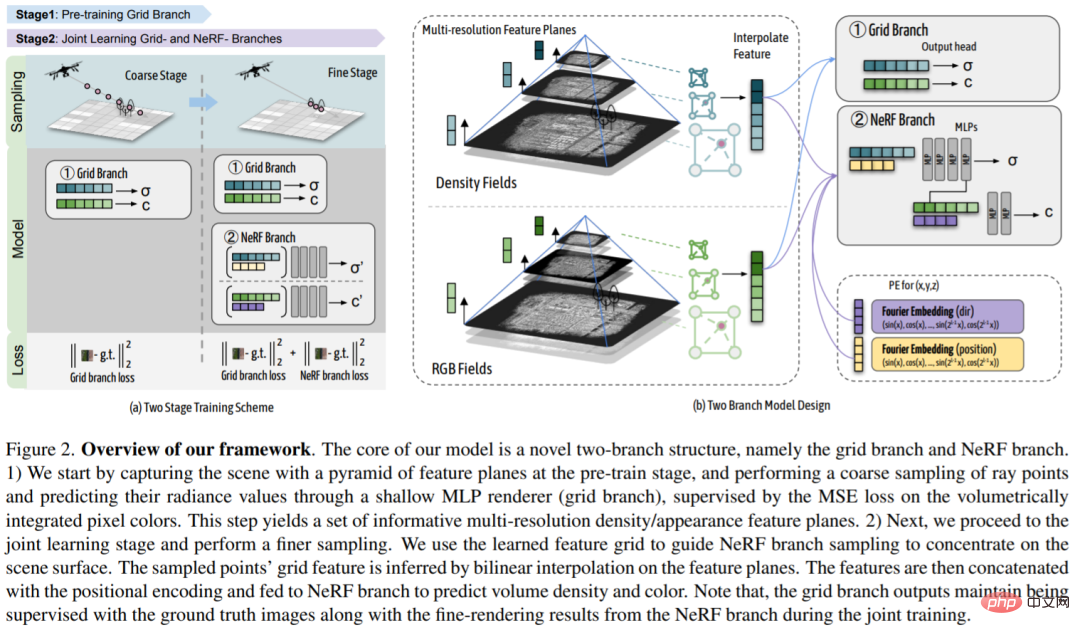
Scénario cible : Dans ce travail, l'étude utilise de nouveaux les champs de rayonnement neuronal effectuent le rendu de grandes scènes urbaines. Le côté gauche de l'image ci-dessous montre un exemple d'une grande scène urbaine s'étendant sur une zone au sol de 2,7 km^2 capturée par plus de 5 000 images de drones. Des études ont montré que les méthodes basées sur NeRF donnent des résultats flous et trop lissés et ont une capacité de modèle limitée, tandis que les méthodes basées sur les grilles propres ont tendance à montrer des artefacts bruyants lors de l'adaptation à des scènes à grande échelle avec des grilles propres à haute résolution. Le modèle à double branche proposé dans cette étude combine les avantages des deux méthodes et permet d'obtenir un nouveau rendu de vue réaliste grâce à des améliorations significatives par rapport aux méthodes existantes. Les deux branches obtiennent des améliorations significatives par rapport à leurs références respectives.

Les chercheurs sont présentés ci-dessous et Le tableau présente les performances de la référence pour comparaison avec la méthode des chercheurs. Tant qualitativement que quantitativement. Des améliorations significatives peuvent être observées en termes de qualité visuelle et de toutes les mesures. L'approche des chercheurs révèle des géométries plus nettes et des détails plus fins que les méthodes purement basées sur MLP (NeRF et Mega-NeRF). En particulier, en raison de la capacité limitée et du biais spectral du NeRF, il est toujours incapable de simuler des changements rapides de géométrie et de couleur, comme la végétation et les rayures sur un terrain de jeu. Bien que la division géographique de la scène en petites régions, comme le montre la base de référence Mega-NeRF, soit légèrement utile, les résultats présentés semblent encore trop fluides. Au contraire, guidé par la grille de fonctionnalités apprise, l’espace d’échantillonnage de NeRF est efficacement et fortement compressé près de la surface de la scène. Les entités de densité et d'apparence échantillonnées à partir du plan caractéristique du sol représentent explicitement le contenu de la scène, comme le montre la figure 3. Bien que moins précis, il fournit déjà une géométrie et une texture locales informatives et encourage le codage de position NeRF pour collecter les détails manquants de la scène.

Le tableau 1 ci-dessous présente les résultats quantitatifs : #🎜 🎜 #
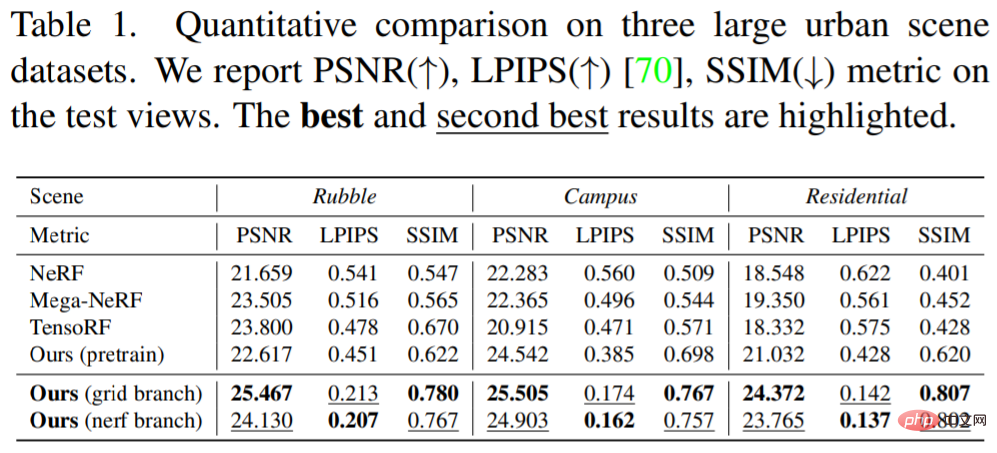
Figure 6 Une amélioration rapide de la fidélité du rendu peut être observée :

Pour plus d'informations, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mot en ppt
mot en ppt
 qu'est-ce que json
qu'est-ce que json
 Quel logiciel est Autocad ?
Quel logiciel est Autocad ?
 utilisation de l'état d'affichage
utilisation de l'état d'affichage
 Comment ouvrir la fenêtre du terminal dans vscode
Comment ouvrir la fenêtre du terminal dans vscode
 Comment supprimer des éléments de tableau en JavaScript
Comment supprimer des éléments de tableau en JavaScript
 Pourquoi toutes les icônes dans le coin inférieur droit de Win10 apparaissent-elles ?
Pourquoi toutes les icônes dans le coin inférieur droit de Win10 apparaissent-elles ?
 Que s'est-il passé lorsque la 4G est devenue 2G ?
Que s'est-il passé lorsque la 4G est devenue 2G ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



