


Grâce au travail de M. Doug Lea, HashMap est devenue l'API la plus fréquemment utilisée et interviewée. Il n'y a pas moyen de trop bien la concevoir !
HashMap est apparu pour la première fois dans JDK 1.2 et l'implémentation sous-jacente est basée sur un algorithme de hachage. HashMap autorise les clés nulles et les valeurs nulles lors du calcul de la valeur de hachage d'une clé de hachage, la valeur de hachage de la clé nulle est 0. HashMap ne garantit pas l'ordre des paires clé-valeur, ce qui signifie que l'ordre des paires clé-valeur peut changer après certaines opérations. De plus, il convient de noter que HashMap est une classe non thread-safe et peut poser des problèmes dans un environnement multithread.
HashMap est apparu pour la première fois dans le JDK 1.2. La couche inférieure est basée sur l'algorithme de hachage avec plusieurs générations d'optimisation et de mises à jour, son code source est devenu plus complexe jusqu'à présent et implique de nombreux points de connaissances dans le JDK 1.8. Implémentation de la table de hachage, 2. Fonction de perturbation, 3. Capacité d'initialisation, 4. Facteur de charge, 5. Fractionnement des éléments d'extension de capacité, 6. Formation d'arbre de liste chaînée, 7. Arbre rouge-noir, 8. Insertion, 9. Recherche, 10. Suppression, 11. Traversée, 12. Verrouillage de segment, etc., car ils impliquent de nombreux points de connaissance, ils doivent être expliqués séparément. Dans ce chapitre, nous nous concentrerons sur les cinq premiers éléments, qui concernent l'utilisation des structures de données. .
Les structures de données sont souvent indissociables des mathématiques. Il est recommandé de télécharger le code source correspondant pour vérification expérimentale pendant le processus d'apprentissage. Ce processus peut être un peu fastidieux, mais après l'avoir appris, vous pouvez comprendre cette partie des connaissances. sans le mémoriser par cœur.
Le code source et les ressources impliquées dans ce chapitre se trouvent dans le projet, interview-04, y compris :
Données de test de 100 000 mots, dans le dossier doc
Affichage Excel de la fonction Perturbation, dans le dossier doc.
La partie code source du test est dans le projet interview-04
Vous pouvez l'obtenir en suivant le compte public : bugstack Wormhole Stack, répondez au téléchargement {ouvrez le lien obtenu après avoir répondu au téléchargement et trouvez le numéro ID : 19 }
Avant d'apprendre HashMap, le meilleur moyen est d'abord de comprendre de quel type de structure de données il s'agit pour stocker les données. Après avoir parcouru plusieurs versions de HashMap, le code est encore très compliqué à première vue. Tout comme avant, vous ne portiez que des shorts, mais maintenant vous portez également des caleçons longs et un coupe-vent. Voyons donc d’abord à quoi ressemble la HashMap la plus basique, c’est-à-dire quel est l’effet de porter uniquement des sous-vêtements, puis analysons son code source.
Question : Supposons que nous ayons un ensemble de 7 chaînes qui doivent être stockées dans un tableau, mais que la complexité temporelle de l'obtention de chaque élément doit être O(1). C'est-à-dire que vous ne pouvez pas l'obtenir par parcours de boucle, mais vous devez localiser l'ID du tableau et obtenir directement l'élément correspondant.
Solution : Si nous devons obtenir des éléments du tableau par ID, nous devons alors calculer un ID de position dans le tableau pour chaque chaîne. À quelles façons pouvez-vous penser pour obtenir l’ID d’une chaîne ? Le moyen le plus direct d'obtenir des informations numériques à partir d'une chaîne est HashCode, mais la plage de valeurs de HashCode est trop grande [-2147483648, 2147483647], ce qui rend impossible son utilisation directe. Ensuite, vous devez utiliser HashCode et la longueur du tableau pour effectuer une opération ET afin d'obtenir une position qui peut apparaître dans le tableau. S'il y a deux éléments avec le même ID, alors deux chaînes sont stockées sous cet ID de tableau.
Ce qui précède est en fait une idée de base pour hacher des chaînes dans des tableaux. Ensuite, nous implémenterons cette idée dans le code.
// 初始化一组字符串
List<String> list = new ArrayList<>();
list.add("jlkk");
list.add("lopi");
list.add("小傅哥");
list.add("e4we");
list.add("alpo");
list.add("yhjk");
list.add("plop");
// 定义要存放的数组
String[] tab = new String[8];
// 循环存放
for (String key : list) {
int idx = key.hashCode() & (tab.length - 1);// 计算索引位置
System.out.println(String.format("key值=%s Idx=%d", key, idx));
if (null == tab[idx]) {
tab[idx] = key;
continue;
}
tab[idx] = tab[idx] + "->" + key;
}
// 输出测试结果
System.out.println(JSON.toJSONString(tab));Ce code semble globalement très simple et n'a aucune complexité. Il comprend principalement le contenu suivant
Résultats des tests
key值=jlkk Idx=2 key值=lopi Idx=4 key值=小傅哥 Idx=7 key值=e4we Idx=5 key值=alpo Idx=2 key值=yhjk Idx=0 key值=plop Idx=5 测试结果:["yhjk",null,"jlkk->alpo",null,"lopi","e4we->plop",null,"小傅哥"]
Si les résultats des tests ci-dessus ne parviennent pas à établir correctement une structure de données dans votre esprit, vous pouvez consulter le diagramme de hachage suivant pour une compréhension facile

diagramme de hachage cn
.以上我们实现了一个简单的HashMap,或者说还算不上HashMap,只能算做一个散列数据存放的雏形。但这样的一个数据结构放在实际使用中,会有哪些问题呢?
以上这些问题可以归纳为;扰动函数、初始化容量、负载因子、扩容方法以及链表和红黑树转换的使用等。接下来我们会逐个问题进行分析。
在HashMap存放元素时候有这样一段代码来处理哈希值,这是java 8的散列值扰动函数,用于优化散列效果;
static final int hash(Object key){
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}理论上来说字符串的hashCode是一个int类型值,那可以直接作为数组下标了,且不会出现碰撞。但是这个hashCode的取值范围是[-2147483648, 2147483647],有将近40亿的长度,谁也不能把数组初始化得这么大,内存也是放不下的。
我们默认初始化的Map大小是16个长度 DEFAULT_INITIAL_CAPACITY = 1 << 4,所以获取的Hash值并不能直接作为下标使用,需要与数组长度进行取模运算得到一个下标值,也就是我们上面做的散列列子。
那么,hashMap源码这里不只是直接获取哈希值,还进行了一次扰动计算,(h = key.hashCode()) ^ (h >>> 16)。把哈希值右移16位,也就正好是自己长度的一半,之后与原哈希值做异或运算,这样就混合了原哈希值中的高位和低位,增大了随机性。计算方式如下图;

bugstack.cn 扰动函数
从上面的分析可以看出,扰动函数使用了哈希值的高半区和低半区做异或,混合原始哈希码的高位和低位,以此来加大低位区的随机性。
但看不到实验数据的话,这终究是一段理论,具体这段哈希值真的被增加了随机性没有,并不知道。所以这里我们要做一个实验,这个实验是这样做;
扰动函数对比方法
public class Disturb {
public static int disturbHashIdx(String key, int size){
return (size - 1) & (key.hashCode() ^ (key.hashCode() >>> 16));
}
public static int hashIdx(String key, int size){
return (size - 1) & key.hashCode();
}
}单元测试
// 10万单词已经初始化到words中
@Test
public void test_disturb(){
Map<Integer, Integer> map = new HashMap<>(16);
for (String word : words) {
// 使用扰动函数
int idx = Disturb.disturbHashIdx(word, 128);
// 不使用扰动函数
// int idx = Disturb.hashIdx(word, 128);
if (map.containsKey(idx)) {
Integer integer = map.get(idx);
map.put(idx, ++integer);
} else {
map.put(idx, 1);
}
}
System.out.println(map.values());
}以上分别统计两种函数下的下标值分配,最终将统计结果放到excel中生成图表。
以上的两张图,分别是没有使用扰动函数和使用扰动函数的,下标分配。实验数据;
未使用扰动函数

bugstack.cn 未使用扰动函数
使用扰动函数

bugstack.cn 使用扰动函数
接下来我们讨论下一个问题,从我们模仿HashMap的例子中以及HashMap默认的初始化大小里,都可以知道,散列数组需要一个2的幂次方的长度,因为只有2的幂次方在减1的时候,才会出现01111这样的值。
那么这里就有一个问题,我们在初始化HashMap的时候,如果传一个17个的值new HashMap<>(17);,它会怎么处理呢?
在HashMap的初始化中,有这样一段方法;
public HashMap(int initialCapacity, float loadFactor){
...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}计算阈值大小的方法;
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}那这里我们把17这样一个初始化计算阈值的过程,用图展示出来,方便理解;
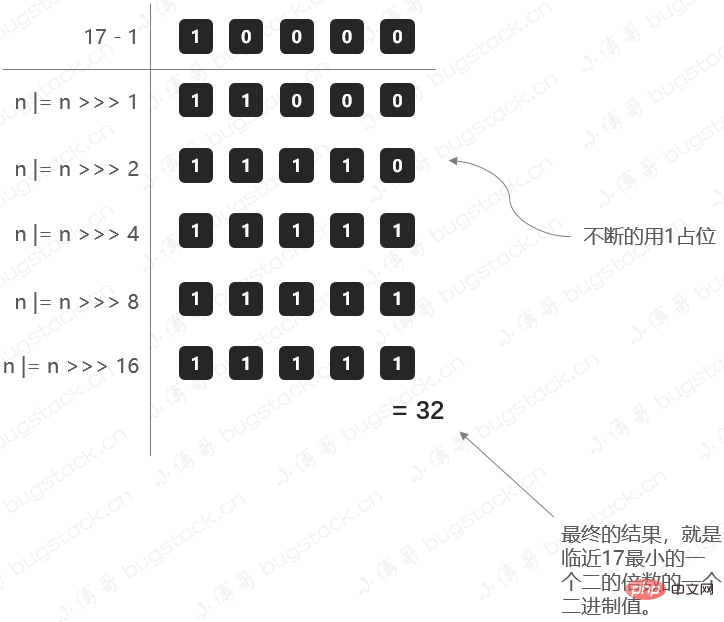
bugstack.cn 计算阈值
static final float DEFAULT_LOAD_FACTOR = 0.75f;
负载因子是做什么的?
负载因子,可以理解成一辆车可承重重量超过某个阈值时,把货放到新的车上。
那么在HashMap中,负载因子决定了数据量多少了以后进行扩容。这里要提到上面做的HashMap例子,我们准备了7个元素,但是最后还有3个位置空余,2个位置存放了2个元素。 所以可能即使你数据比数组容量大时也是不一定能正正好好的把数组占满的,而是在某些小标位置出现了大量的碰撞,只能在同一个位置用链表存放,那么这样就失去了Map数组的性能。
所以,要选择一个合理的大小下进行扩容,默认值0.75就是说当阈值容量占了3/4时赶紧扩容,减少Hash碰撞。
同时0.75是一个默认构造值,在创建HashMap也可以调整,比如你希望用更多的空间换取时间,可以把负载因子调的更小一些,减少碰撞。
为什么扩容,因为数组长度不足了。那扩容最直接的问题,就是需要把元素拆分到新的数组中。拆分元素的过程中,原jdk1.7中会需要重新计算哈希值,但是到jdk1.8中已经进行优化,不再需要重新计算,提升了拆分的性能,设计的还是非常巧妙的。
@Test
public void test_hashMap(){
List<String> list = new ArrayList<>();
list.add("jlkk");
list.add("lopi");
list.add("jmdw");
list.add("e4we");
list.add("io98");
list.add("nmhg");
list.add("vfg6");
list.add("gfrt");
list.add("alpo");
list.add("vfbh");
list.add("bnhj");
list.add("zuio");
list.add("iu8e");
list.add("yhjk");
list.add("plop");
list.add("dd0p");
for (String key : list) {
int hash = key.hashCode() ^ (key.hashCode() >>> 16);
System.out.println("字符串:" + key + " tIdx(16):" + ((16 - 1) & hash) + " tBit值:" + Integer.toBinaryString(hash) + " - " + Integer.toBinaryString(hash & 16) + " ttIdx(32):" + ((
System.out.println(Integer.toBinaryString(key.hashCode()) +" "+ Integer.toBinaryString(hash) + " " + Integer.toBinaryString((32 - 1) & hash));
}
}测试结果
字符串:jlkkIdx(16):3Bit值:1100011101001000010011 - 10000 Idx(32):19 1100011101001000100010 1100011101001000010011 10011 字符串:lopiIdx(16):14Bit值:1100101100011010001110 - 0 Idx(32):14 1100101100011010111100 1100101100011010001110 1110 字符串:jmdwIdx(16):7Bit值:1100011101010100100111 - 0 Idx(32):7 1100011101010100010110 1100011101010100100111 111 字符串:e4weIdx(16):3Bit值:1011101011101101010011 - 10000 Idx(32):19 1011101011101101111101 1011101011101101010011 10011 字符串:io98Idx(16):4Bit值:1100010110001011110100 - 10000 Idx(32):20 1100010110001011000101 1100010110001011110100 10100 字符串:nmhgIdx(16):13Bit值:1100111010011011001101 - 0 Idx(32):13 1100111010011011111110 1100111010011011001101 1101 字符串:vfg6Idx(16):8Bit值:1101110010111101101000 - 0 Idx(32):8 1101110010111101011111 1101110010111101101000 1000 字符串:gfrtIdx(16):1Bit值:1100000101111101010001 - 10000 Idx(32):17 1100000101111101100001 1100000101111101010001 10001 字符串:alpoIdx(16):7Bit值:1011011011101101000111 - 0 Idx(32):7 1011011011101101101010 1011011011101101000111 111 字符串:vfbhIdx(16):1Bit值:1101110010111011000001 - 0 Idx(32):1 1101110010111011110110 1101110010111011000001 1 字符串:bnhjIdx(16):0Bit值:1011100011011001100000 - 0 Idx(32):0 1011100011011001001110 1011100011011001100000 0 字符串:zuioIdx(16):8Bit值:1110010011100110011000 - 10000 Idx(32):24 1110010011100110100001 1110010011100110011000 11000 字符串:iu8eIdx(16):8Bit值:1100010111100101101000 - 0 Idx(32):8 1100010111100101011001 1100010111100101101000 1000 字符串:yhjkIdx(16):8Bit值:1110001001010010101000 - 0 Idx(32):8 1110001001010010010000 1110001001010010101000 1000 字符串:plopIdx(16):9Bit值:1101001000110011101001 - 0 Idx(32):9 1101001000110011011101 1101001000110011101001 1001 字符串:dd0pIdx(16):14Bit值:1011101111001011101110 - 0 Idx(32):14 1011101111001011000000 1011101111001011101110 1110

bugstack.cn 数据迁移
那么为什么 e.hash & oldCap == 0 为什么可以判断当前节点是否需要移位, 而不是再次计算hash;
仍然是原始长度为16举例:
old: 10: 0000 1010 15: 0000 1111 &: 0000 1010 new: 10: 0000 1010 31: 0001 1111 &: 0000 1010
从上面的示例可以很轻易的看出, 两次indexFor()的差别只是第二次参与位于比第一次左边有一位从0变为1, 而这个变化的1刚好是oldCap, 那么只需要判断原key的hash这个位上是否为1: 若是1, 则需要移动至oldCap + i的槽位, 若为0, 则不需要移动;
这也是HashMap的长度必须保证是2的幂次方的原因, 正因为这种环环相扣的设计, HashMap.loadFactor的选值是3/4就能理解了, table.length * 3/4可以被优化为((table.length >> 2) > 2) == table.length - (table.length >> 2), JAVA的位运算比乘除的效率更高, 所以取3/4在保证hash冲突小的情况下兼顾了效率;
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Les huit fonctions les plus couramment utilisées dans Excel
Les huit fonctions les plus couramment utilisées dans Excel
 Que faire si le jeton de connexion n'est pas valide
Que faire si le jeton de connexion n'est pas valide
 utilisation de la fonction isnumber
utilisation de la fonction isnumber
 format flac
format flac
 Présentation du plan de maintenance du serveur
Présentation du plan de maintenance du serveur
 Que comprend le stockage par cryptage des données ?
Que comprend le stockage par cryptage des données ?
 Comment écrire un script batch bat
Comment écrire un script batch bat
 Logiciel de base de données couramment utilisé
Logiciel de base de données couramment utilisé








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



