



Numpy est un module de base pour le calcul scientifique Python. Il fournit des objets tableau très efficaces, ainsi que des outils pour travailler avec ces objets tableau. Un tableau Numpy se compose de plusieurs valeurs, toutes du même type.
La bibliothèque principale de Python fournit des listes de listes. Les listes sont l'un des types de données Python les plus courants, et elles peuvent être redimensionnées et contenir des éléments de différents types, ce qui est très pratique.
Alors quelle est la différence entre List et Numpy Array ? Pourquoi devons-nous utiliser Numpy Array lors du traitement du Big Data ? La réponse est la performance.
Les structures de données Numpy fonctionnent mieux dans les aspects suivants :
1. Taille de la mémoire - Les structures de données Numpy occupent moins de mémoire.
2 Performances : la couche inférieure de Numpy est implémentée en langage C, qui est plus rapide que les listes.
3. Méthodes d'opération - opérations algébriques optimisées intégrées et autres méthodes.
Ce qui suit expliquera les avantages des tableaux Numpy par rapport aux listes dans le traitement du Big Data.
Si vous utilisez des tableaux Numpy au lieu de listes de manière appropriée, vous pouvez réduire votre utilisation de la mémoire de 20 fois.
Pour la liste native de Python, puisque chaque fois qu'un nouvel objet est ajouté, 8 octets sont nécessaires pour référencer le nouvel objet, et le nouvel objet lui-même occupe 28 octets (en prenant un entier comme exemple). Ainsi la taille de la liste peut être calculée avec la formule suivante :
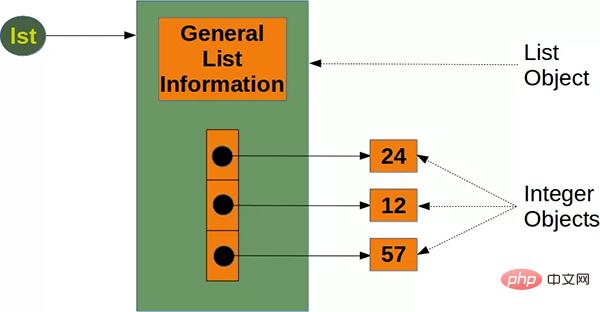 #🎜 🎜#
#🎜 🎜#

import time
import numpy as np
size_of_vec = 1000
def pure_python_version():
t1 = time.time()
X = range(size_of_vec)
Y = range(size_of_vec)
Z = [X[i] + Y[i] for i in range(len(X)) ]
return time.time() - t1
def numpy_version():
t1 = time.time()
X = np.arange(size_of_vec)
Y = np.arange(size_of_vec)
Z = X + Y
return time.time() - t1
t1 = pure_python_version()
t2 = numpy_version()
print(t1, t2)
print("Numpy is in this example " + str(t1/t2) + " faster!")
0.00048732757568359375 0.0002491474151611328 Numpy is in this example 1.955980861244019 faster!
import numpy as np
from timeit import Timer
size_of_vec = 1000
X_list = range(size_of_vec)
Y_list = range(size_of_vec)
X = np.arange(size_of_vec)
Y = np.arange(size_of_vec)
def pure_python_version():
Z = [X_list[i] + Y_list[i] for i in range(len(X_list)) ]
def numpy_version():
Z = X + Y
timer_obj1 = Timer("pure_python_version()",
"from __main__ import pure_python_version")
timer_obj2 = Timer("numpy_version()",
"from __main__ import numpy_version")
print(timer_obj1.timeit(10))
print(timer_obj2.timeit(10)) # Runs Faster!
print(timer_obj1.repeat(repeat=3, number=10))
print(timer_obj2.repeat(repeat=3, number=10)) # repeat to prove it!
0.0029753120616078377 0.00014940369874238968 [0.002683573868125677, 0.002754641231149435, 0.002803879790008068] [6.536301225423813e-05, 2.9387418180704117e-05, 2.9171351343393326e-05]
//m.sbmmt.com/link/5cce25ff8c3ce169488fe6c6f1ad3c97
C'est tout pour notre article C'est tout . Si vous aimez le didacticiel pratique Python d'aujourd'hui, continuez à nous suivre.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



