


De nos jours, la piste de l'IA générative est en vogue. Selon les statistiques de PitchBook, le volet IA générative recevra un total d'environ 1,4 milliard de dollars de financement en 2022, atteignant presque le total des cinq dernières années. Des sociétés vedettes telles qu'OpenAI et Stability AI, ainsi que d'autres start-ups telles que Jasper, Regie.AI, Replika, etc., ont toutes bénéficié d'une faveur en capital.
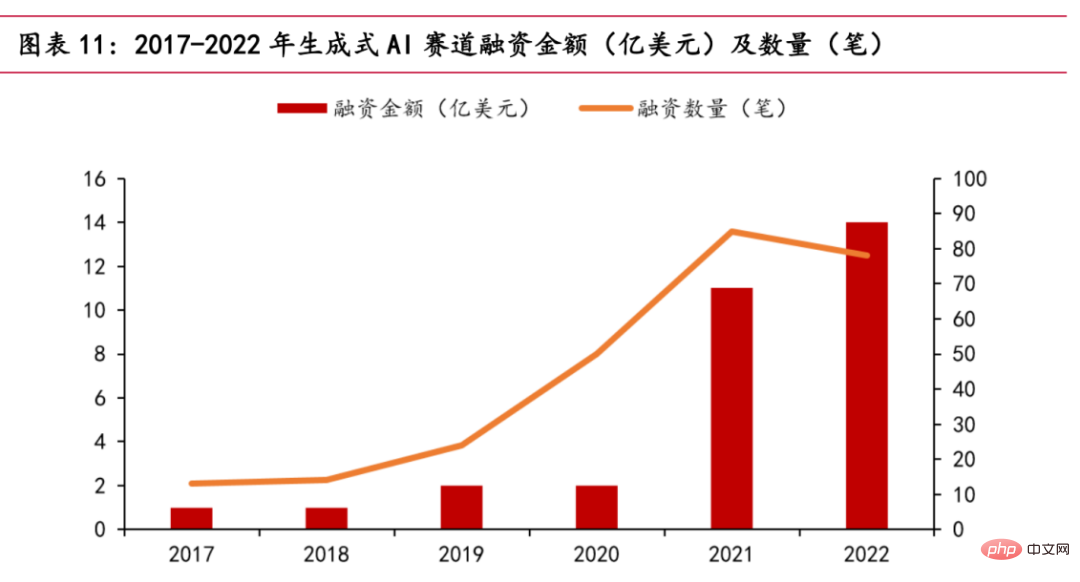
Graphique de la relation entre le montant du financement et le temps
En octobre 2022, Stability AI a reçu environ 100 millions de dollars de financement et a publié le modèle open source Stable Diffusion, qui peut générer des images basées sur des descriptions textuelles saisies par les utilisateurs, faire exploser le domaine de la peinture IA. Le 30 novembre 2022, après que ChatGPT a annoncé sa version bêta publique, 5 jours après sa mise en ligne, le nombre d'utilisateurs dans le monde a dépassé le million. En moins de 40 jours depuis son lancement, les utilisateurs actifs quotidiens ont dépassé les 10 millions. Au petit matin du 15 mars 2023, OpenAI a publié le modèle de la série GPT actuellement le plus puissant, GPT-4, qui fournit un modèle multimodal à grande échelle capable d'accepter la saisie d'images et de texte et de produire une sortie de texte, ce qui a un impact perturbateur. dans l'industrie. Le 17 mars 2023, Microsoft a organisé la conférence Microsoft 365 Copilot, installé officiellement le modèle GPT-4 d'OpenAI dans la suite Office et lancé la nouvelle fonction d'IA Copilot. Il peut non seulement créer des PPT et rédiger des copies, mais également effectuer des analyses et générer des vidéos. En outre, divers grands fabricants nationaux ont également annoncé le lancement de produits similaires à ChatGPT. Le 8 février, les experts d'Alibaba ont annoncé que la Damo Academy développait un robot conversationnel de type ChatGPT et l'avait ouvert aux employés de l'entreprise pour des tests. Il est possible de combiner profondément la technologie d'IA de grands modèles avec les outils de productivité DingTalk. Le 8 février, He Xiaodong, vice-président de JD.com, a déclaré franchement : JD.com propose des scénarios riches et des données de haute qualité dans le domaine de ChatGPT. Le 9 février, des sources pertinentes chez Tencent ont déclaré : Tencent prévoit actuellement des produits similaires à ChatGPT et au contenu généré par l'IA, et des recherches spéciales progressent également de manière ordonnée. NetEase a déclaré que son activité éducative intégrera le contenu généré par l'IA, y compris, mais sans s'y limiter, les enseignants parlant l'IA, la notation et l'évaluation des dissertations, etc. Le 16 mars, Baidu a officiellement publié le grand modèle de langage et le produit d'IA générative "Wen Xin Yi Yan". Deux jours après la sortie, 12 entreprises ont finalisé le premier lot de coopération contractuelle et ont postulé pour l'appel d'API Baidu Intelligent Cloud Wen Xin Yi Yan. service Le nombre d’entreprises testées a atteint 90 000.
Actuellement, les grands modèles ont progressivement pénétré nos vies. À l’avenir, tous les domaines de la vie sont susceptibles de subir des changements bouleversants. En prenant ChatGPT comme exemple, il comprend les aspects suivants :
Il convient de noter que bien que la discussion principale ici porte sur la mise en œuvre de grands modèles de langage, en fait, d'autres grands modèles multimodaux (audio, vidéo, images) ont également de larges scénarios d'application.
publié par Google. Le modèle LaMDA est basé sur le framework Transformer, comporte 137 milliards de paramètres de modèle et a la capacité de modéliser des dépendances longue distance dans le texte. Le modèle est formé à travers des conversations. Il comprend principalement deux processus : la pré-formation et le réglage fin : au cours de la phase de pré-formation, ils ont utilisé jusqu'à 1,56 T d'ensembles de données de conversations publiques et de textes de pages Web, en utilisant le modèle linguistique (LM) comme fonction objective de la formation, c'est-à-dire que le but est de prédire le prochain personnage (jeton). Dans la phase de mise au point, ils ont conçu plusieurs tâches, telles que la notation des attributs des réponses (sensibilité, sécurité, etc.), pour donner au modèle de langage ses préférences humaines. La figure ci-dessous montre un type de tâche de réglage fin.

Phase de pré-formation du modèle LaMDA

L'une des tâches de la phase de mise au point du modèle LaMDA
Le modèle LaMDA se concentre sur les tâches de génération de dialogue, mais commet souvent des erreurs factuelles. Google a lancé cette année Bard (un service expérimental d’IA conversationnelle), alimenté par le modèle LaMDA. Cependant, lors de la conférence de presse de Bard, Bard a commis des erreurs factuelles, ce qui a provoqué une chute du cours de l'action de Google mercredi, tombant de plus de 8 % en cours de journée, jusqu'à environ 98 dollars le jour de l'actualisation, et sa valeur marchande s'est évaporée de 110 milliards de dollars, ce qui est décevant.
Le modèle InstructGPT est basé sur l'architecture GPT et est principalement formé par un réglage fin supervisé (Supervise Fune-Tuning, SFT) et un apprentissage par renforcement par feedback humain (Reinforce Learning Human Fune-tuning, RLHF) . ChatGPT, un produit conversationnel alimenté par InstructGPT, se concentre sur la génération de texte linguistique et peut également générer du code et effectuer des opérations mathématiques simples. Les détails techniques spécifiques ont été abordés en détail dans les deux numéros précédents. Les lecteurs peuvent s'y rendre pour les lire et ne les répéteront pas ici.
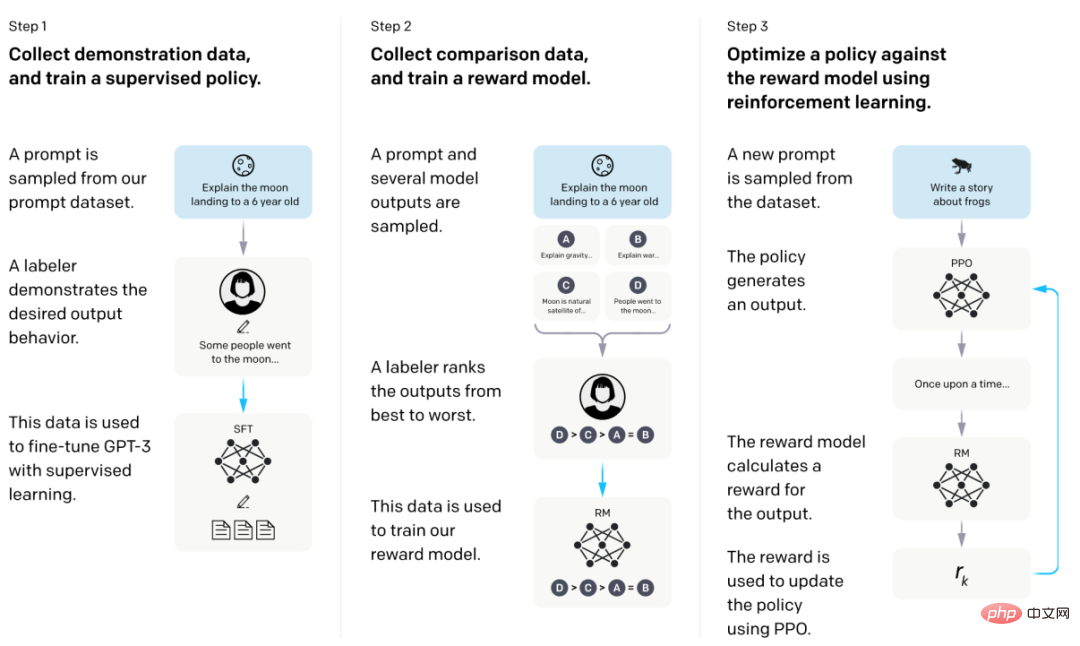
Organigramme de formation du modèle InstructGPT
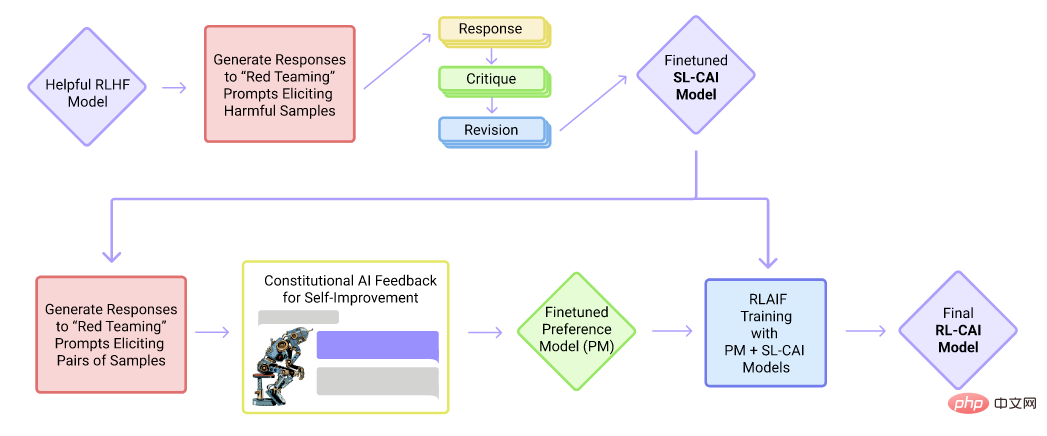
Organigramme de formation du modèle Cluade
Cluade est un produit conversationnel d'Anthropic Company. Cluade, comme ChatGPT, est basé sur le framework GPT et est un modèle de langage unidirectionnel. Cependant, contrairement à ChatGPT, il est principalement formé par un réglage fin supervisé et un apprentissage par renforcement avec retour d’information de l’IA. Dans la phase de mise au point supervisée, il formule d'abord une série de règles (Constitution), telles que l'absence d'informations préjudiciables, l'absence de préjugés raciaux, etc., puis obtient des données supervisées sur la base de ces règles. Ensuite, laissez l’IA juger de la qualité des réponses et entraîner automatiquement l’ensemble de données pour l’apprentissage par renforcement.
Par rapport à ChatGPT, Claude peut rejeter plus clairement les demandes inappropriées et les liens entre les phrases sont plus naturels. Claude est prêt à s'exprimer lorsqu'il est confronté à un problème qui dépasse ses capacités. Actuellement, Cluade est encore en phase de tests internes. Cependant, selon les résultats des tests internes des membres de l'équipe Scale Sepllbook, par rapport à ChatGPT, Claude est plus fort dans 8 des 12 tâches testées.
Nous avons des statistiques sur les grands modèles linguistiques au pays et à l'étranger, ainsi que les capacités des modèles, le statut open source, etc.
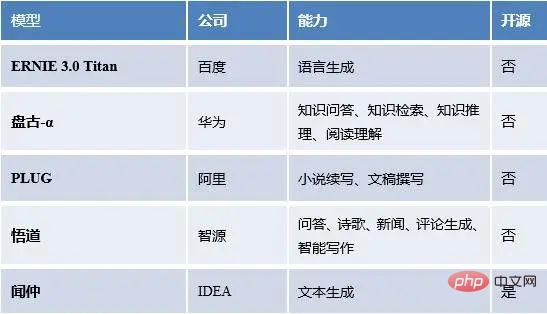
Grands modèles linguistiques populaires en Chine
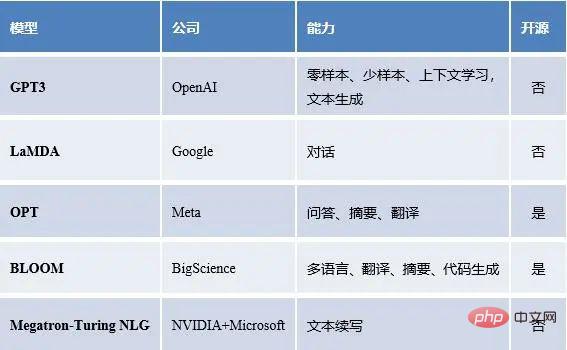
Grands modèles linguistiques populaires à l'étranger
On peut constater que les grands modèles linguistiques ont diverses capacités, notamment, mais sans s'y limiter, l'apprentissage en quelques étapes, la migration sans étapes, etc. attendez. Une question très naturelle se pose donc : comment ces capacités naissent-elles ? D’où vient la puissance des grands modèles linguistiques ? Ensuite, nous essayons de répondre aux doutes ci-dessus.
La figure ci-dessous montre quelques grands modèles de langage matures et processus d'évolution. En résumé, la plupart des modèles passeront par trois étapes : pré-formation, mise au point des instructions et alignement. Les modèles représentatifs incluent Deepmind’s Sparrow et OpenAI’s ChatGPT.
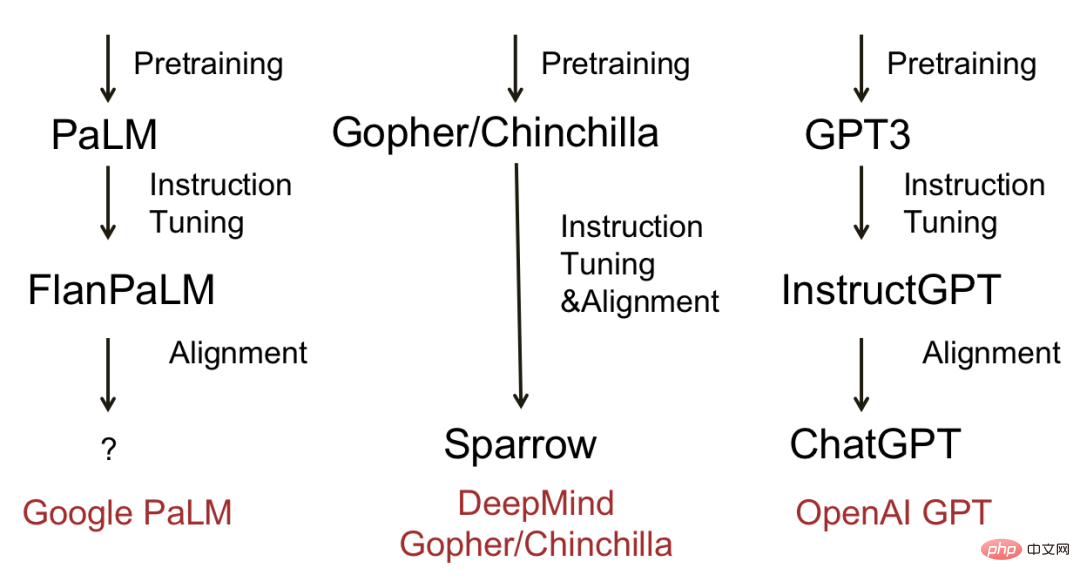
Diagramme évolutif des grands modèles de langage populaires
Donc, derrière chaque étape, quels types de capacités le modèle peut-il atteindre ? Le Dr Fu Yao de l'Université d'Édimbourg a résumé ce qu'il pensait être la relation correspondante entre les étapes et les capacités, nous donnant ainsi une certaine inspiration.
1. Phase de pré-formation Le but de cette phase est d'obtenir un modèle de base performant. En conséquence, les capacités démontrées par le modèle à ce stade incluent : la génération de langage, les capacités d'apprentissage du contexte, la connaissance du monde, les capacités de raisonnement, etc. Les modèles représentatifs à ce stade incluent GPT-3, PaLM, etc.
2. Étape de mise au point des instructions. Le but de cette phase est de débloquer certaines capacités émergentes. La capacité émergente fait ici spécifiquement référence à la capacité que les petits modèles ne possèdent pas mais que seuls les grands modèles possèdent. Le modèle qui a fait l’objet d’un réglage précis possède des capacités que le modèle de base n’a pas. Par exemple, en construisant de nouvelles instructions, le modèle peut résoudre de nouvelles tâches ; un autre exemple est la capacité de la chaîne de réflexion, c'est-à-dire qu'en montrant au modèle le processus de raisonnement, le modèle peut également imiter le raisonnement correct, etc. Les modèles représentatifs incluent InstruireGPT, Flan, etc.
Étape d'alignement. Le but de cette étape est de faire en sorte que le modèle possède des valeurs humaines, comme générer des réponses informatives et ne pas produire de remarques discriminatoires, etc. On peut penser que l’étape d’alignement donne de la « personnalité » aux modèles. Le modèle représentatif de ce type est ChatGPT.
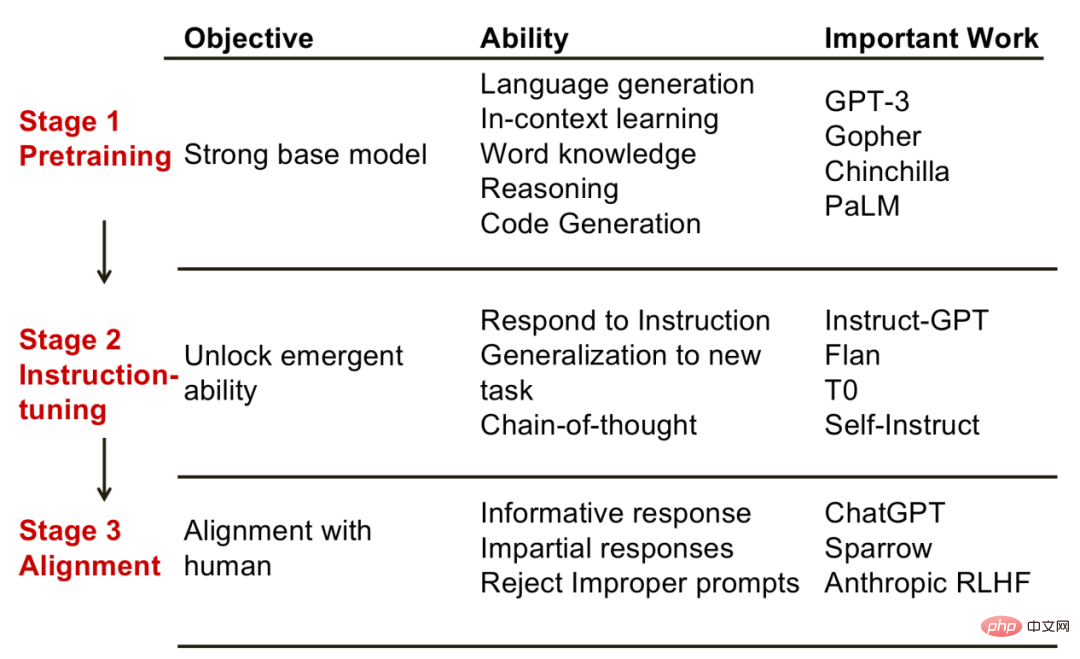
Trois étapes d'un grand modèle de langage. L'image vient de "Fu Yao : Sur la source de la capacité des grands modèles de langage"
De manière générale, les trois étapes ci-dessus se complètent et sont indispensables. Ce n'est que lorsqu'un modèle de base suffisamment puissant est obtenu au cours de la phase de pré-formation qu'il est possible de stimuler (ou d'améliorer) d'autres capacités du modèle de langage grâce à un réglage fin de l'enseignement. L'étape d'alignement donne au modèle un certain « caractère » pour mieux répondre à certaines exigences de la société humaine.
Bien que la technologie des grands modèles de langage soit pratique, elle comporte également des risques et des défis. Au niveau technique, l'authenticité des contenus générés par GPT ne peut être garantie, comme les propos nuisibles, etc. Au niveau de l'utilisation, les utilisateurs peuvent abuser des textes générés par l'IA dans des domaines tels que l'éducation et la recherche scientifique. Actuellement, de nombreuses entreprises et institutions ont commencé à imposer des restrictions sur l'utilisation de ChatGPT. Microsoft et Amazon interdisent aux employés de l'entreprise de partager des données sensibles avec ChatGPT en raison de préoccupations concernant la fuite d'informations confidentielles ; l'Université de Hong Kong interdit l'utilisation de ChatGPT ou d'autres outils d'intelligence artificielle dans tous les cours, devoirs et évaluations à l'Université de Hong Kong. Nous introduisons principalement des travaux connexes dans l’industrie.
GPTZero : GPTZero est le premier outil de génération et d'identification de texte. Il s'agit d'un site Web en ligne (https://gptzero.me/) publié par Edward Tian (un étudiant de premier cycle en informatique de Princeton, États-Unis). Son principe repose sur la perplexité textuelle (PPL) comme indicateur pour déterminer qui a écrit le contenu donné. Parmi eux, la perplexité est utilisée pour évaluer la qualité du modèle linguistique, qui consiste essentiellement à calculer la probabilité d’apparition d’une phrase.
Interface du site Web GPTZero
(Ici, nous utilisons ChatGPT pour générer un reportage et laisser GPTZero déterminer s'il s'agit d'un texte généré.)
Détecteur de sortie GPT2 : cet outil est publié par OpenAI. Il exploite les ensembles de données « Contenu généré par GPT2 » et Reddit, affinés sur RoBerta, pour apprendre un classificateur de détection. C'est-à-dire « combattre la magie par la magie ». Le site officiel rappelle également que les résultats des prédictions ne sont plus crédibles que lorsque le texte dépasse 50 caractères (token).

Interface du site Web du détecteur de sortie GPT2
AI Text Classifier : cet outil est publié par OpenAI. Le principe est de collecter des textes d’écriture humaine et des textes d’écriture d’IA sur un même sujet. Divisez chaque texte en paires d'invite et de réponse, et laissez la probabilité que GPT produise une réponse après un réglage fin (par exemple, laisser GPT produire Oui/Non) comme seuil de résultat. La classification de l'outil est très détaillée et les résultats comprennent 5 catégories : très peu probable qu'il soit généré par l'IA (seuil 0,98).
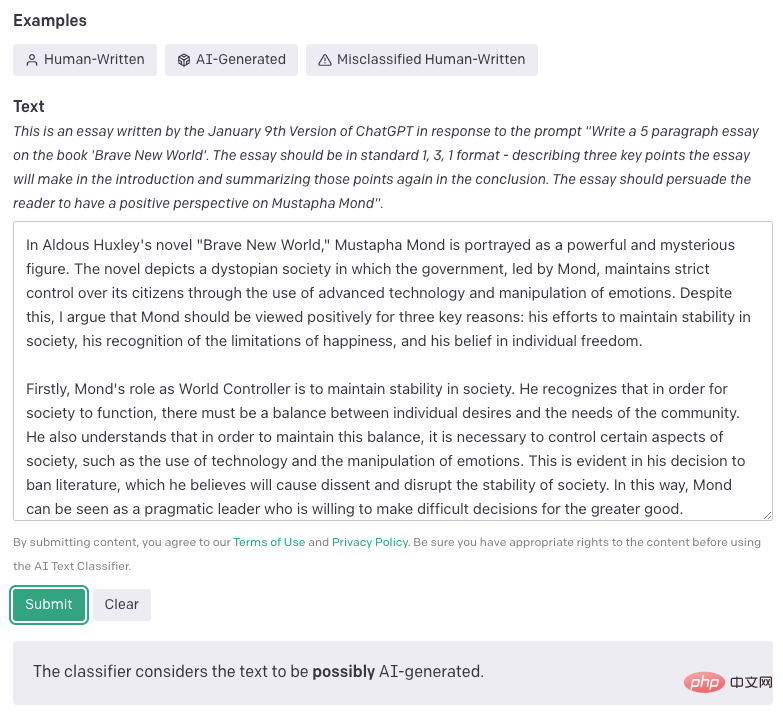
Interface du site Web AI Text Classifier
Les grands modèles de langage ont des fonctionnalités émergentes que les petits modèles n'ont pas, telles qu'un excellent apprentissage zéro, une migration de domaine et des capacités de chaîne de réflexion. Les capacités des grands modèles proviennent en fait de la pré-formation, du réglage fin des instructions et de l'alignement. Ces trois processus sont étroitement liés et ont rendu possibles les grands modèles de langage ultra puissants d'aujourd'hui.
Les grands modèles de langage (série GPT) n'ont actuellement pas les capacités de mise à jour de la confiance, de raisonnement formel, de récupération sur Internet, etc. Certains experts estiment que si les connaissances peuvent être déchargées en dehors du modèle, le nombre de paramètres sera considérablement réduit, et ce n’est qu’alors que les grands modèles linguistiques pourront véritablement aller plus loin.
Ce n'est que sous une supervision et une gouvernance raisonnables que la technologie de l'intelligence artificielle peut mieux servir les gens. Il reste beaucoup de chemin à parcourir pour développer des modèles à grande échelle en Chine !
[1] https://stablediffusionweb.com
[2] https://openai.com/product/gpt-4
[3] LaMDA : modèles de langage pour les applications de dialogue, Arxiv 2022.10
[4] Constitutional AI : Inoffensive from AI Feedback, Arxiv 2022.12
[5] https://scale.com/blog/chatgpt-vs-claude#Calculation
[6] Guolian Securities : "La tendance ChatGPT est arrivée, Accélération de la commercialisation"
[7] Guotai Junan Securities : "ChatGPT Research Framework 2023"
[8] Fu Yao : Pré-formation, mise au point de l'instruction, alignement, spécialisation : Sur la source des grandes capacités du modèle de langage https:/ / www.bilibili.com/video/BV1Qs4y1h7pn/?spm_id_from=333.880.my_history.page.click&vd_source=da8bf0b993cab65c4de0f26405823475
[9] Analyse d'un article de 10 000 mots ! Reproduisez et utilisez GPT-3/ChatGPT, ce que vous devez savoir https://mp.weixin.qq.com/s/ILpbRRNP10Ef1z3lb2CqmA
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Inscription ChatGPT
Inscription ChatGPT
 Encyclopédie ChatGPT nationale gratuite
Encyclopédie ChatGPT nationale gratuite
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Comment installer chatgpt sur un téléphone mobile
Comment installer chatgpt sur un téléphone mobile
 Chatgpt peut-il être utilisé en Chine ?
Chatgpt peut-il être utilisé en Chine ?
 Comment résoudre le problème selon lequel le raccourci IE ne peut pas être supprimé
Comment résoudre le problème selon lequel le raccourci IE ne peut pas être supprimé
 Que dois-je faire si le conteneur Docker ne peut pas accéder au réseau externe ?
Que dois-je faire si le conteneur Docker ne peut pas accéder au réseau externe ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



