


Qu'est-ce que l'algorithme k-Voisin le plus proche ?

L'algorithme du voisin le plus proche est également appelé algorithme KNN. Cet algorithme est un algorithme classique en apprentissage automatique. , l'algorithme KNN est un algorithme relativement facile à comprendre.
Si un échantillon appartient à une certaine catégorie parmi les k échantillons les plus similaires (c'est-à-dire les plus proches dans l'espace des fonctionnalités) dans l'espace des fonctionnalités, alors l'échantillon appartient également à cette catégorie.
Source : L'algorithme KNN a été proposé pour la première fois par Cover et Hart comme algorithme de classification
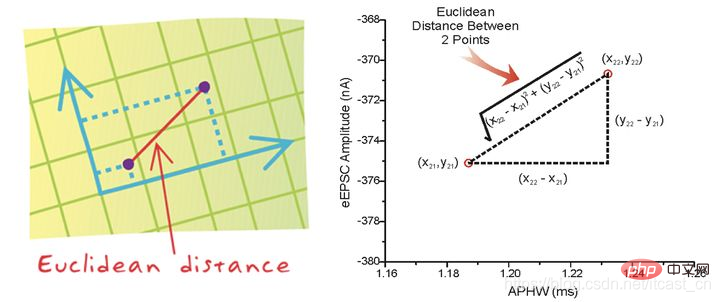
La distance entre deux échantillons peut être calculée par la formule suivante, également appelée distance euclidienne. formule, nous en discuterons plus tard
Les scénarios d'application sont : prévision du prix de l'immobilier, prévision du montant des ventes, prévision du montant du prêt
Qu'est-ce que la régression linéaire ?
La régression linéaire consiste à utiliser des équations de régression (fonctions) pour établir la relation entre une ou plusieurs variables indépendantes (valeurs propres) et des variables dépendantes (valeurs cibles) Une méthode d'analyse des modèles.
Caractéristiques : La situation avec une seule variable indépendante est appelée régression univariée, et la situation avec plus d'une variable indépendante est appelée régression multiple.

Exemple de régression linéaire représentée par une matrice :
Alors comment la comprenez-vous ? Regardons quelques exemples :
Note finale : 0,7×score à l'examen+0,3×note habituelle
Prix de la maison = 0,02×distance de la zone centrale+0,04×concentration d'oxyde nitrique de la ville+ (-0,12×depuis la moyenne prix du logement) + 0,254 × taux de criminalité urbaine
Dans les deux exemples ci-dessus, nous voyons qu'une relation s'établit entre la valeur de la caractéristique et la valeur cible, qui peut être comprise comme un modèle linéaire.
La régression logistique est un modèle de classification dans l'apprentissage automatique. La régression logistique est un algorithme de classification, bien qu'elle ait une régression dans son nom. En raison de la simplicité et de l’efficacité de l’algorithme, il est largement utilisé dans la pratique.
Scénarios d'application : taux de clics sur les annonces, qu'il s'agisse de spam, de maladie, de fraude financière, de faux compte.
Vous pouvez trouver une fonctionnalité ici, c'est-à-dire que des jugements sont faits entre les deux catégories. La régression logistique est un outil puissant pour résoudre le problème des deux classifications.
Pour maîtriser la régression logistique, vous devez maîtriser deux points :
Quelles sont les valeurs d'entrée en régression logistique ?
Comment juger le résultat d'une régression logistique ?
Entrée :

Fonction d'activation : fonction sigmoïde

Critères de jugement
Les résultats de régression sont entrés dans Dans la fonction sigmoïde, le résultat de sortie est : [0, 1] Une valeur de probabilité dans l'intervalle, la valeur par défaut est 0,5 comme seuil.

La classification finale de la régression logistique consiste à juger si elle appartient à une certaine catégorie grâce à la valeur de probabilité d'appartenance à une certaine catégorie, et cette catégorie est marquée comme 1 (exemple positif) par défaut, et l'autre catégorie sera marquée comme 0 (exemple négatif). (Pratique pour le calcul des pertes)
Explication des résultats de sortie (important) : Supposons qu'il existe deux catégories A et B, et supposons que notre valeur de probabilité est la valeur de probabilité appartenant à la catégorie A(1). Il y a maintenant un échantillon d'entrée dans le résultat de sortie de la régression logistique 0,55, alors cette valeur de probabilité dépasse 0,5, ce qui signifie que le résultat de notre entraînement ou de notre prédiction est la catégorie A(1). Alors au contraire, si le résultat est de 0,3, alors le résultat d’entraînement ou de prédiction sera la catégorie B(0).
Le seuil de régression logistique peut être modifié. Par exemple, dans l'exemple ci-dessus, si vous définissez le seuil sur 0,6, alors le résultat de sortie est 0,55, qui appartient à la catégorie B.
L'origine de l'idée d'arbre de décision est très simple. La structure de branche conditionnelle en programmation est la structure if-else. Le premier arbre de décision est une méthode d'apprentissage de classification qui l'utilise. type de structure pour diviser les données
Arbre de décision : C'est une structure arborescente dans laquelle chaque nœud interne représente un jugement sur un attribut, chaque branche représente la sortie d'un résultat de jugement, et enfin chaque nœud feuille représente un résultat de classification. L'essence est un arbre A composé de plusieurs nœuds de jugement.
Comment comprendre cette phrase ? À travers un exemple de conversation

Le cas ci-dessus est une fille qui met l'âge au sommet grâce à une conscience subjective qualitative. Alors si ce processus doit être quantifié, comment doit-il être géré ?
En ce moment, vous devez utiliser les connaissances en théorie de l'information : entropie de l'information et gain d'information.

L'apprentissage d'ensemble résout un seul problème de prédiction en construisant plusieurs modèles. Il fonctionne en générant plusieurs classificateurs/modèles, chacun apprenant et faisant des prédictions indépendamment. Ces prédictions sont finalement combinées en une prédiction combinée qui est meilleure que n'importe quelle prédiction de classification unique.

Portraits d'utilisateurs, recommandations publicitaires, segmentation des données, recommandations de trafic des moteurs de recherche, identification du trafic malveillant
Push commercial basé sur les informations de localisation, clustering d'actualités , filtrage et tri.
Segmentation d'images, réduction de dimensionnalité, reconnaissance ; détection de valeurs aberrantes ; consommation anormale de cartes de crédit ; découverte de fragments de gènes ayant la même fonction.
Un algorithme d'apprentissage non supervisé typique, principalement utilisé pour classer automatiquement des échantillons similaires dans une catégorie.
Dans l'algorithme de clustering, les échantillons sont divisés en différentes catégories en fonction de la similarité entre les échantillons. Différentes méthodes de calcul de similarité entraîneront différents résultats de clustering. Les méthodes de calcul de similarité couramment utilisées sont la méthode de distance européenne.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Algorithme de remplacement de page
Algorithme de remplacement de page
 win10 se connecte à une imprimante partagée
win10 se connecte à une imprimante partagée
 Comment définir l'URL du routeur tplink
Comment définir l'URL du routeur tplink
 Comment définir la taille de la police HTML
Comment définir la taille de la police HTML
 Comment résoudre le problème des 400 requêtes incorrectes lorsque la page Web s'affiche
Comment résoudre le problème des 400 requêtes incorrectes lorsque la page Web s'affiche
 Quels sont les conseils d'utilisation de Dezender ?
Quels sont les conseils d'utilisation de Dezender ?
 Comment résoudre le problème d'occupation du port phpstudy
Comment résoudre le problème d'occupation du port phpstudy
 À quoi fait référence le bean en Java ?
À quoi fait référence le bean en Java ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



