


Au cours des deux dernières années, il y a eu une augmentation de la publication de modèles génératifs à grande échelle dans l'industrie de l'IA, en particulier après l'open source de Stable Diffusion et l'interface ouverte de ChatGPT, qui ont encore stimulé l'enthousiasme de l'industrie. pour les modèles génératifs.
Cependant, il existe de nombreux types de modèles génératifs et la vitesse de publication est très rapide Si vous ne faites pas attention, vous risquez de manquer sota
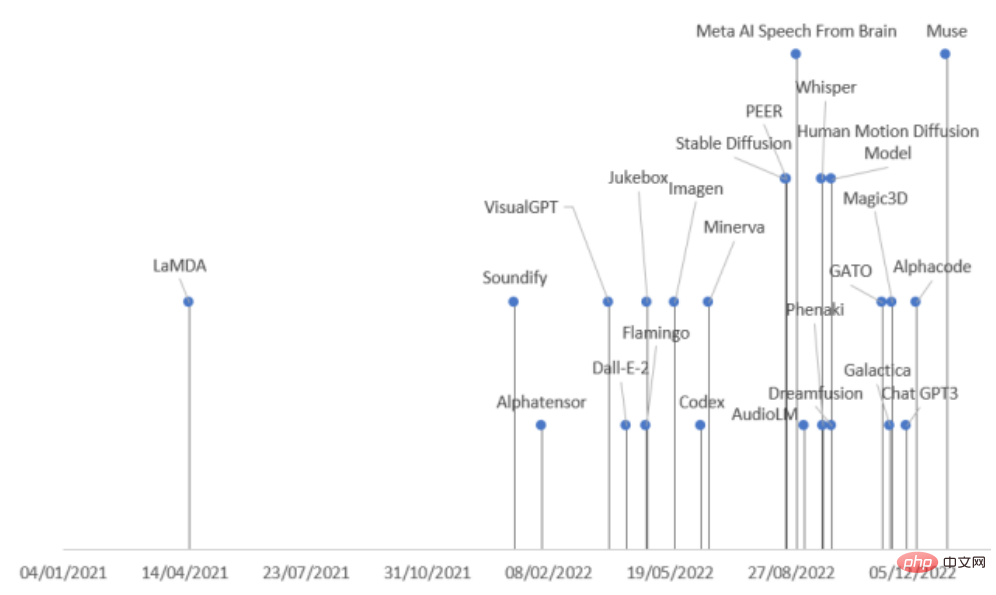
Récemment, des chercheurs de l'Université pontificale de Comillas en Espagne ont mené une étude complète de. L'IA dans divers domaines Les derniers progrès ont divisé les modèles génératifs en neuf catégories selon les modes de tâche et les domaines, et ont résumé 21 modèles génératifs sortis en 2022, vous permettant de comprendre d'un coup le contexte de développement des modèles génératifs !

Lien papier : https://arxiv.org/abs/2301.04655
Les modèles peuvent être classés en fonction des types de données d'entrée et de sortie, comprenant actuellement principalement 9 catégories.
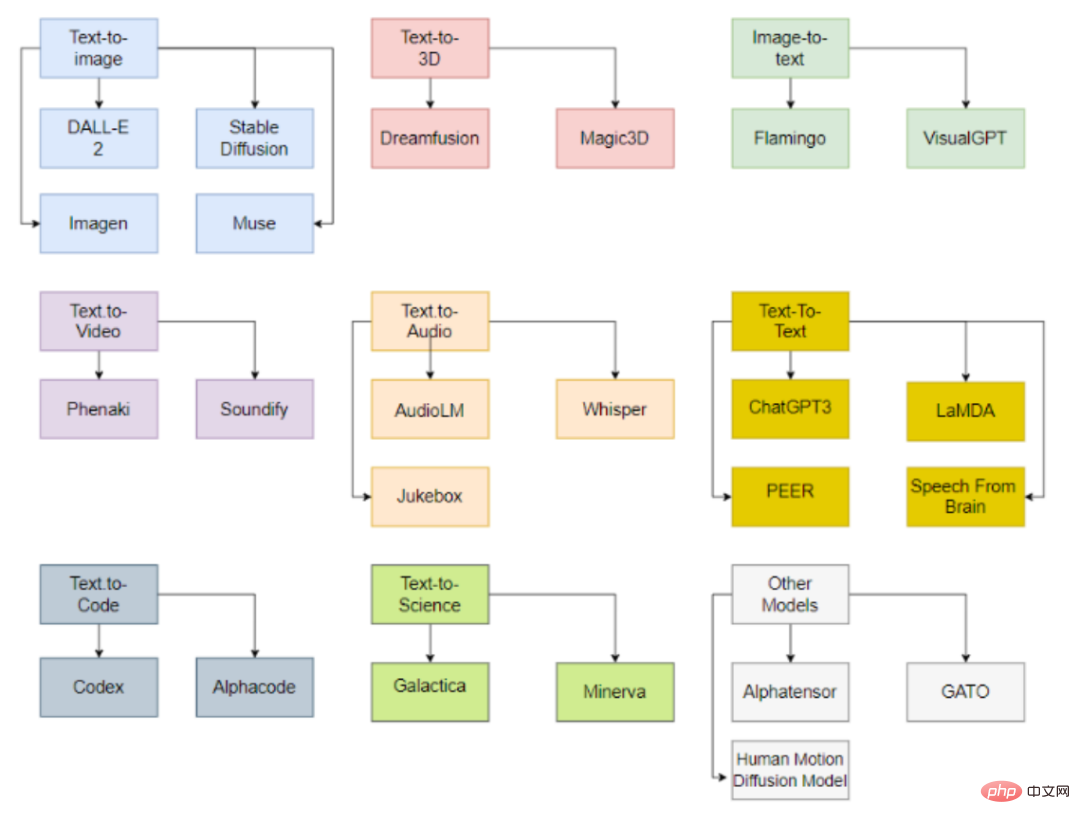
Fait intéressant, derrière ces grands modèles publiés, seules six organisations (OpenAI, Google, DeepMind, Meta, runway, Nvidia) sont impliquées dans le déploiement de ces modèles de pointe.
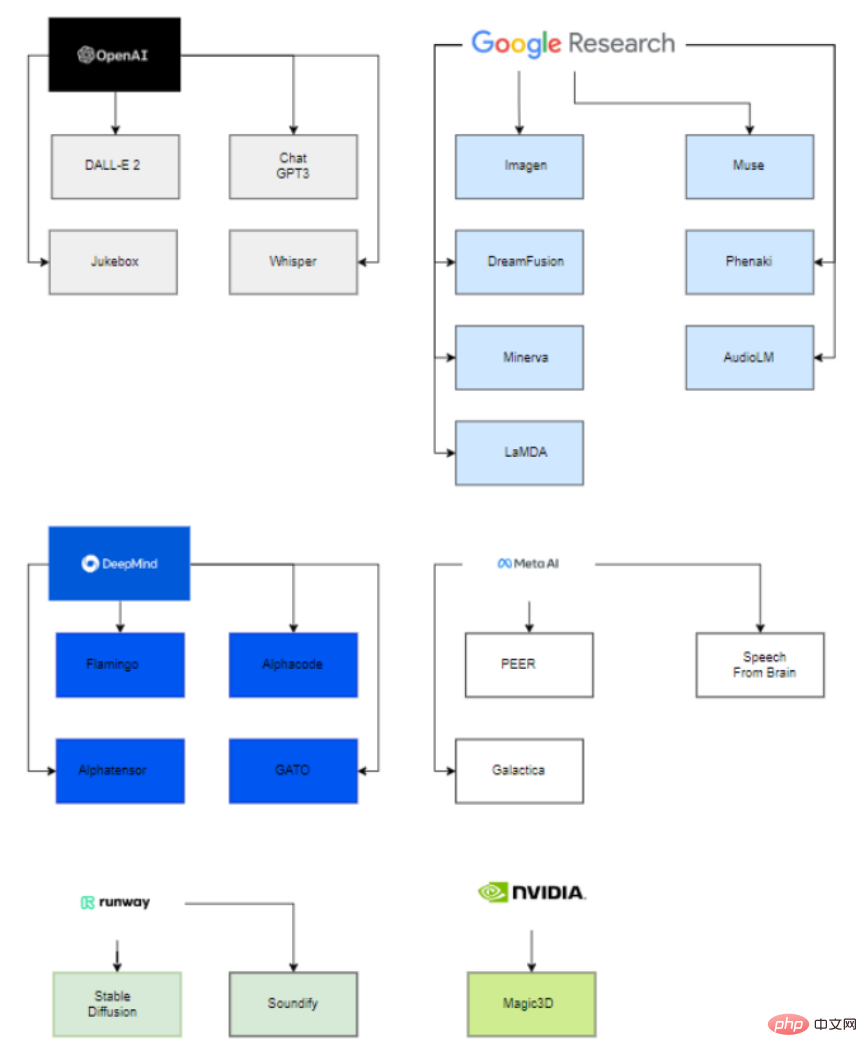
La raison principale est que pour pouvoir estimer les paramètres de ces modèles, il faut disposer d'une puissance de calcul extrêmement importante, ainsi que d'une équipe hautement qualifiée et expérimentée en science des données et en ingénierie des données.
Ainsi, seules ces entreprises, avec l'aide de startups acquises et de collaborations avec le monde universitaire, peuvent déployer avec succès des modèles d'IA génératives.
En ce qui concerne les grandes entreprises s'impliquant dans les startups, on peut voir Microsoft investir 1 milliard de dollars dans OpenAI et les aider à développer des modèles de la même manière, Google a acquis Deepmind en 2014.
Du côté universitaire, VisualGPT a été développé par l'Université des sciences et technologies King Abdullah (KAUST), l'Université Carnegie Mellon et l'Université technologique de Nanyang, et le modèle de diffusion du mouvement humain a été développé par l'Université de Tel Aviv en Israël.
De même, d'autres projets sont développés par une entreprise et une université, comme Stable Diffusion est développé par Runway, Stability AI et l'Université de Munich ; Soundify est développé par Runway et Carnegie Mellon University est développé par Google et l'Université de Californie ; de la collaboration de Berkeley.
Modèle texte-image
DALL-E 2 développé par OpenAI est capable de générer des images et des œuvres d'art originales, réelles et réalistes à partir d'invites composées de descriptions textuelles, et OpenAI l'a mis à la disposition du API publique pour accéder au modèle.
La particularité de DALL-E 2 est sa capacité à combiner des concepts, des attributs et différents styles. Sa capacité est dérivée du modèle de réseau neuronal CLIP pré-entraîné langage-image, de sorte qu'il peut utiliser le langage naturel pour indiquer le plus pertinent. fragments de texte.
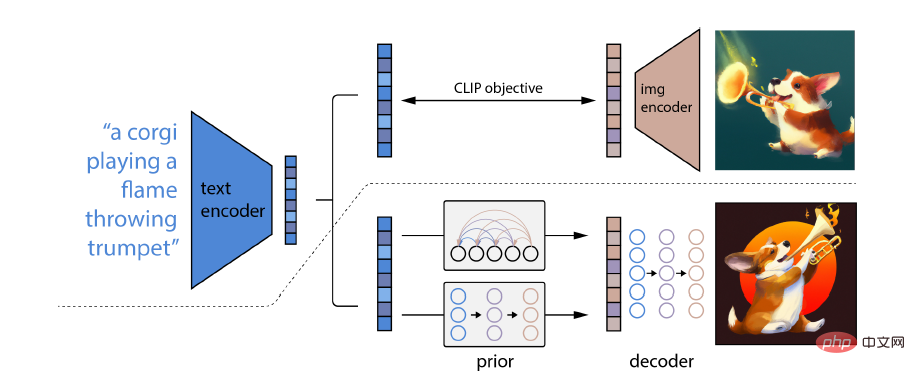
Plus précisément, l'intégration CLIP possède plusieurs propriétés souhaitables : elle est capable de transformer de manière stable la distribution de l'image ; elle a de fortes capacités de prise de vue nulle et elle permet d'obtenir des résultats de pointe après un réglage fin ;
Pour obtenir un modèle complet de génération d'images, le module de décodeur d'intégration d'images CLIP est combiné avec un modèle antérieur pour générer des intégrations d'images CLIP pertinentes à partir d'une légende de texte donnée

D'autres modèles incluent Imagen, Stable Diffusion, Muse
Pour certaines industries, seules des images 2D peuvent être générées et l'automatisation ne peut pas être complétée. Par exemple, dans le domaine des jeux, des modèles 3D doivent être générés.
Dreamfusion
DreamFusion a été développé par Google Research et utilise un modèle de diffusion texte-image 2D pré-entraîné pour la synthèse texte-3D.
Dreamfusion remplace la technique CLIP par une perte obtenue à partir de la distillation d'un modèle de diffusion bidimensionnel, c'est-à-dire que le modèle de diffusion peut être utilisé comme perte dans un problème général d'optimisation continue pour générer des échantillons.

Par rapport à d'autres méthodes qui échantillonnent principalement des pixels, l'échantillonnage dans l'espace des paramètres est beaucoup plus difficile que l'échantillonnage dans l'espace des pixels. DreamFusion utilise un générateur différentiable qui se concentre sur la création d'images rendues sous des angles aléatoires.

D'autres modèles tels que Magic3D sont développés par NVIDIA.
Il est également utile d'obtenir un texte décrivant l'image, ce qui équivaut à la version inverse de la génération d'image.
Flamingo
Développé par Deepmind, ce modèle peut effectuer un apprentissage en quelques étapes sur des tâches de langage visuel ouvertes avec seulement quelques invites à partir d'exemples d'entrée/sortie.
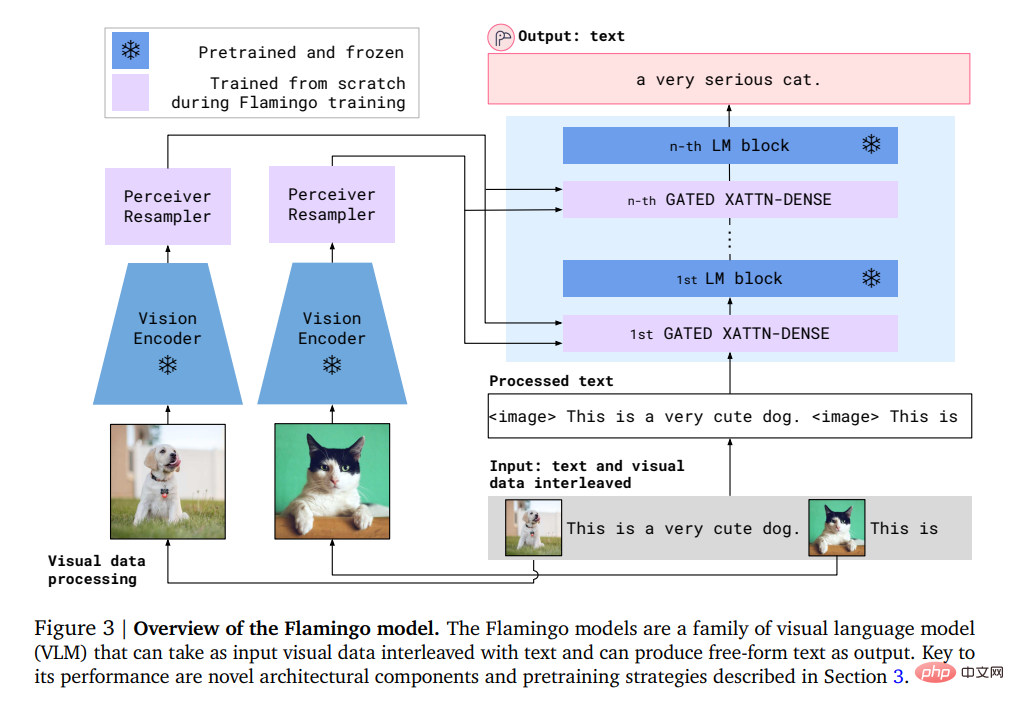
Plus précisément, l'entrée de Flamingo comprend un modèle de génération de texte autorégressif dans des conditions visuelles, qui peut recevoir une séquence de jetons de texte entrelacés avec des images ou des vidéos et générer du texte en sortie.
Les utilisateurs peuvent saisir une requête dans le modèle et joindre une photo ou une vidéo, et le modèle répondra par une réponse textuelle.

Le modèle Flamingo exploite deux modèles complémentaires : un modèle visuel qui analyse les scènes visuelles et un grand modèle de langage qui exécute des formes de raisonnement de base.
VisualGPT
VisualGPT est un modèle de description d'image développé par OpenAI qui peut exploiter les connaissances du modèle de langage pré-entraîné GPT-2.
Pour combler le fossé sémantique entre les différentes modalités, les chercheurs ont conçu un nouveau mécanisme d'attention codeur-décodeur avec fonction de déclenchement de rectification.

Le plus grand avantage de VisualGPT est qu'il ne nécessite pas autant de données que d'autres modèles d'image en texte, peut améliorer l'efficacité des données des modèles de description d'image et peut être appliqué dans des domaines de niche ou décrire des objets rares.
Phenaki
Ce modèle a été développé et produit par Google Research et peut effectuer une véritable synthèse vidéo à partir d'une série d'invites de texte.
Phenaki est le premier modèle capable de générer des vidéos à partir d'indices variables temporels en domaine ouvert.
Pour résoudre le problème des données, les chercheurs se sont formés conjointement sur un grand ensemble de données de paires image-texte et sur un plus petit nombre d'exemples vidéo-texte, et ont finalement atteint des capacités de généralisation au-delà de l'ensemble de données vidéo.
Les ensembles de données image-texte ont tendance à contenir des milliards de données d'entrée, tandis que les ensembles de données texte-vidéo sont beaucoup plus petits et le calcul de vidéos de différentes longueurs est également un problème difficile.

Le modèle Phenaki contient trois parties : encodeur C-ViViT, transformateur d'entraînement et générateur vidéo.
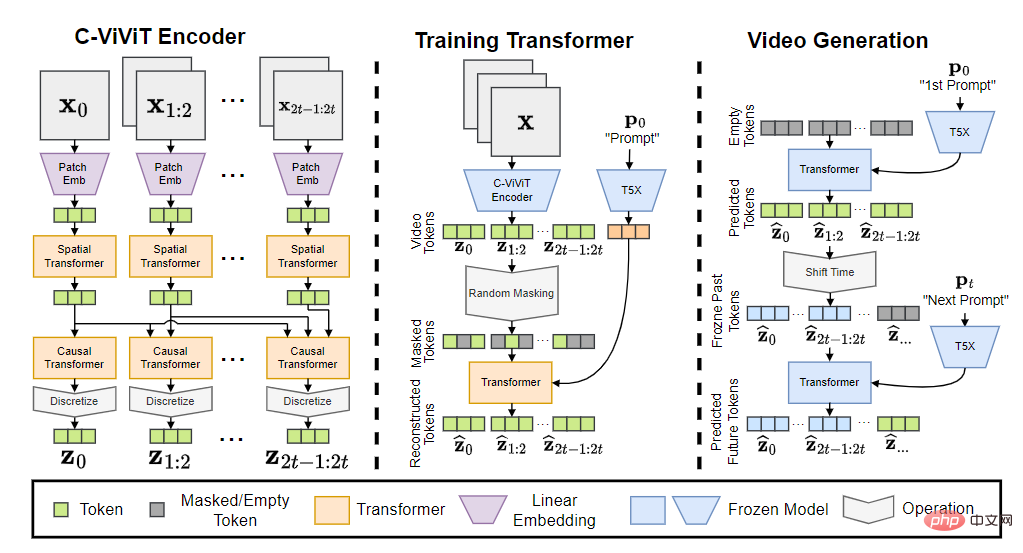
Après avoir converti le jeton d'entrée en intégration, il passe ensuite par le transformateur temporel et le transformateur spatial, puis utilise une seule projection linéaire sans activation pour mapper le jeton à l'espace des pixels.
Le modèle final peut générer des vidéos avec une cohérence et une diversité temporelles conditionnées par des indices de domaine ouvert, et est même capable de gérer de nouveaux concepts qui n'existent pas dans l'ensemble de données.
Les modèles associés incluent Soundify.
Pour la génération vidéo, le son est également un élément indispensable.
AudioLM
Ce modèle a été développé par Google et peut être utilisé pour générer un son de haute qualité avec une cohérence longue distance.
La particularité d'AudioLM est qu'il mappe l'audio d'entrée dans une séquence de jetons discrets et utilise la génération audio comme tâche de modélisation du langage dans cet espace de représentation.
En s'entraînant sur un large corpus de formes d'onde audio brutes, AudioLM a appris avec succès à générer une parole continue naturelle et cohérente sous de brèves invites. Cette méthode peut même être étendue à des paroles autres que les voix humaines, comme la musique continue au piano, etc., sans ajouter de représentation symbolique lors de la formation.
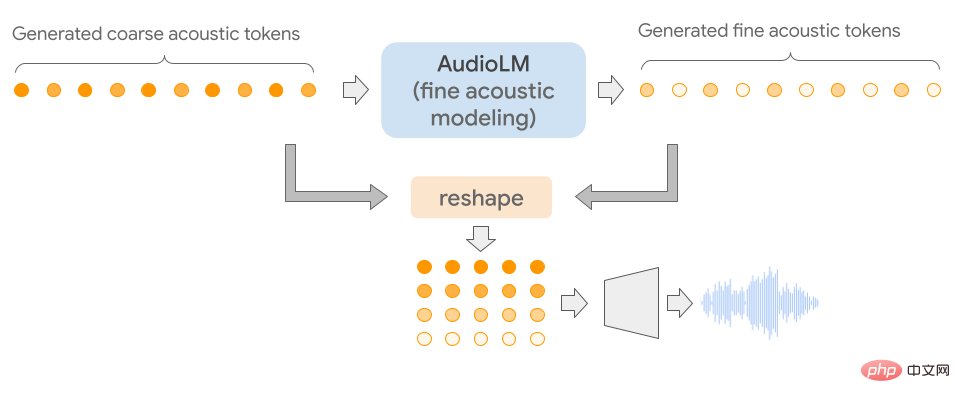
Étant donné que les signaux audio impliquent l'abstraction de plusieurs échelles, il est très difficile d'obtenir une qualité audio élevée à plusieurs échelles tout en faisant preuve de cohérence lors de la synthèse audio. Le modèle AudioLM est mis en œuvre en combinant les avancées récentes en matière de compression audio neuronale, d'apprentissage de représentation auto-supervisé et de modélisation du langage.
Pour une évaluation subjective, les évaluateurs sont invités à écouter un échantillon de 10 secondes et à décider s'il s'agit d'une parole humaine ou d'une parole synthétisée. Sur la base de 1 000 notes collectées, le taux est de 51,2 %, ce qui n'est pas statistiquement différent des étiquettes attribuées au hasard, c'est-à-dire que les humains ne peuvent pas faire la distinction entre les échantillons synthétiques et réels.
Les autres modèles associés incluent Jukebox et Whisper
Couramment utilisé dans les tâches de questions et réponses.
ChatGPT
Développé par OpenAI, le populaire ChatGPT interagit avec les utilisateurs de manière conversationnelle.
L'utilisateur pose une question ou la première moitié du texte d'invite, et le modèle complétera les parties suivantes, pourra identifier les conditions préalables de saisie incorrectes et rejeter les demandes inappropriées.
Plus précisément, l'algorithme derrière ChatGPT est Transformer, et le processus de formation est principalement un apprentissage par renforcement basé sur les commentaires humains.
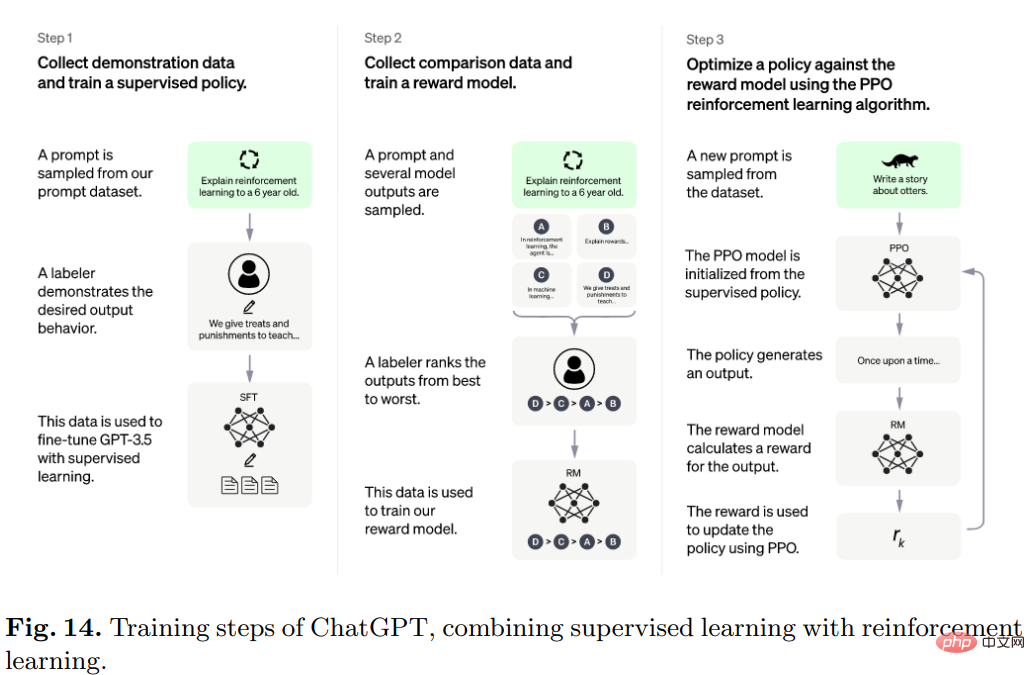
Le modèle initial est entraîné par réglage fin sous apprentissage supervisé, puis les humains fournissent des conversations dans lesquelles ils jouent le rôle d'utilisateur et d'assistant IA les uns envers les autres. Les humains modifient ensuite les réponses renvoyées par le modèle et les utilisent. les bonnes réponses aident le modèle à s'améliorer.
Mélangez l'ensemble de données créé avec l'ensemble de données d'InstructGPT et convertissez-le au format conversationnel.
D'autres modèles associés incluent LaMDA et PEER
est similaire au texte-texte, sauf qu'il génère un type spécial de texte, c'est-à-dire du code.
Codex
Développé par OpenAI, ce modèle peut traduire du texte en code.
Codex est un modèle de programmation général qui peut être appliqué à pratiquement n'importe quelle tâche de programmation.
Les activités humaines lors de la programmation peuvent être divisées en deux parties : 1) décomposer un problème en problèmes plus simples ; 2) mapper ces problèmes dans le code existant (bibliothèque, API ou fonction).
La deuxième partie est la partie qui fait perdre le plus de temps aux programmeurs, et c'est aussi ce pour quoi le Codex est le meilleur.
Les données de formation ont été collectées à partir de référentiels de logiciels publics hébergés sur GitHub en mai 2020, contenant 179 Go de fichiers Python et affinés sur GPT-3, qui inclut déjà de puissantes représentations en langage naturel.
Les modèles associés incluent également Alphacode
Le texte de recherche scientifique est également l'un des objectifs de la génération de texte par l'IA, mais il reste encore un long chemin à parcourir pour obtenir des résultats.
Galactica
Ce modèle a été développé conjointement par Meta AI et Papers with Code et peut être utilisé pour organiser automatiquement des modèles de textes scientifiques à grande échelle.
Le principal avantage de Galactica est que même après avoir entraîné plusieurs épisodes, le modèle ne sera toujours pas surajusté et les performances en amont et en aval s'amélioreront avec l'utilisation répétée de jetons.
Et la conception de l'ensemble de données est cruciale pour cette approche, car toutes les données sont traitées dans un format markdown commun, permettant le mélange de connaissances provenant de différentes sources.
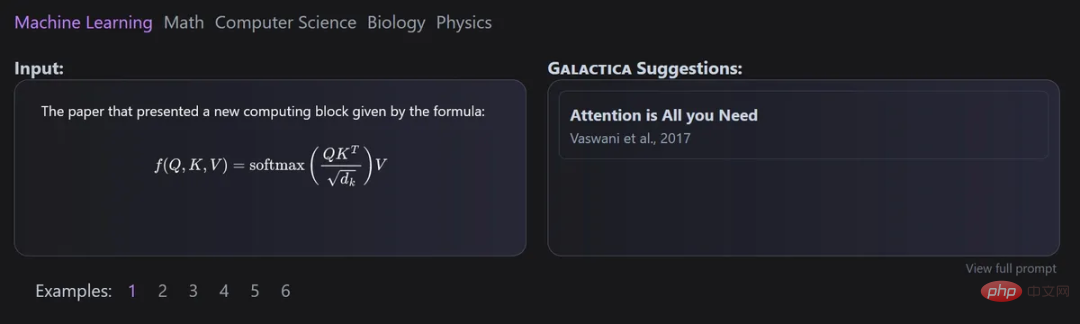
Les citations sont traitées via un jeton spécifique, permettant aux chercheurs de prédire une citation dans n'importe quel contexte de saisie. La capacité des modèles Galactica à prédire les citations augmente avec l'échelle.
De plus, le modèle utilise une architecture Transformer dans un environnement de décodeur uniquement avec activation GeLU pour toutes les tailles de modèle, permettant d'effectuer des tâches multimodales impliquant des formules chimiques et des séquences de protéines SMILES,
Minerva
L'objectif principal de Minerva est de résoudre des problèmes mathématiques et scientifiques. À cette fin, il a collecté une grande quantité de données de formation, résolu des problèmes de raisonnement quantitatif, des problèmes de développement de modèles à grande échelle et a également adopté une technologie de raisonnement de première classe.
L'architecture du modèle de langage d'échantillonnage Minerva résout le problème de l'entrée en utilisant un raisonnement étape par étape, c'est-à-dire que l'entrée doit contenir des calculs et des opérations symboliques sans introduire d'outils externes.
Il existe également certains modèles qui n'entrent pas dans les catégories mentionnées précédemment.
AlphaTensor
Développé par Deepmind, c'est un modèle complètement révolutionnaire dans l'industrie de par sa capacité à découvrir de nouveaux algorithmes.
Dans l'exemple publié, AlphaTensor a créé un algorithme de multiplication matricielle plus efficace. Cet algorithme est si important que tout, des réseaux de neurones aux programmes de calcul scientifique, peut bénéficier de ce calcul de multiplication efficace.
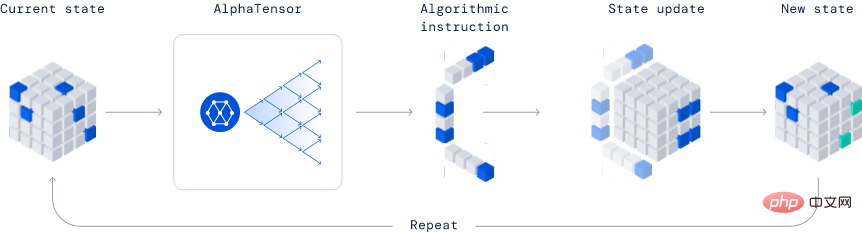
Cette méthode est basée sur la méthode d'apprentissage par renforcement profond, dans laquelle le processus de formation de l'agent AlphaTensor consiste à jouer à un jeu solo, et le but est de trouver une décomposition tensorielle dans un espace factoriel limité.
À chaque étape de TensorGame, les joueurs doivent choisir comment combiner différentes entrées de la matrice pour effectuer la multiplication et gagner des points bonus en fonction du nombre d'opérations requises pour obtenir le résultat de multiplication correct. AlphaTensor utilise une architecture de réseau neuronal spéciale pour exploiter la symétrie du jeu d'entraînement synthétique.
GATO
Ce modèle est un agent général développé par Deepmind Il peut être utilisé comme stratégie de généralisation multimodale, multi-tâches ou multi-incarnations.
Le même réseau avec le même poids peut héberger des fonctionnalités très différentes, comme jouer à des jeux Atari, décrire des images, discuter, empiler des blocs, etc.
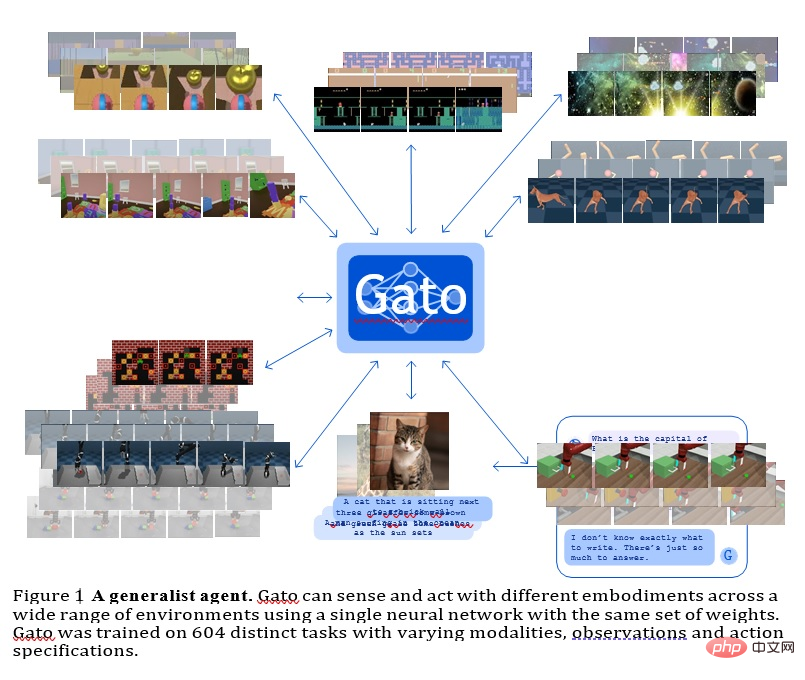
L'utilisation d'un modèle de séquence neuronale unique pour toutes les tâches présente de nombreux avantages, réduisant ainsi le besoin de créer manuellement des modèles stratégiques avec leurs propres biais inductifs et augmentant la quantité et la diversité des données d'entraînement.
Cet agent polyvalent réussit un grand nombre de tâches et peut être optimisé avec peu de données supplémentaires pour réussir encore plus de tâches.
Actuellement, GATO dispose d'environ 1,2 milliard de paramètres, qui peuvent contrôler l'échelle du modèle de robots du monde réel en temps réel.
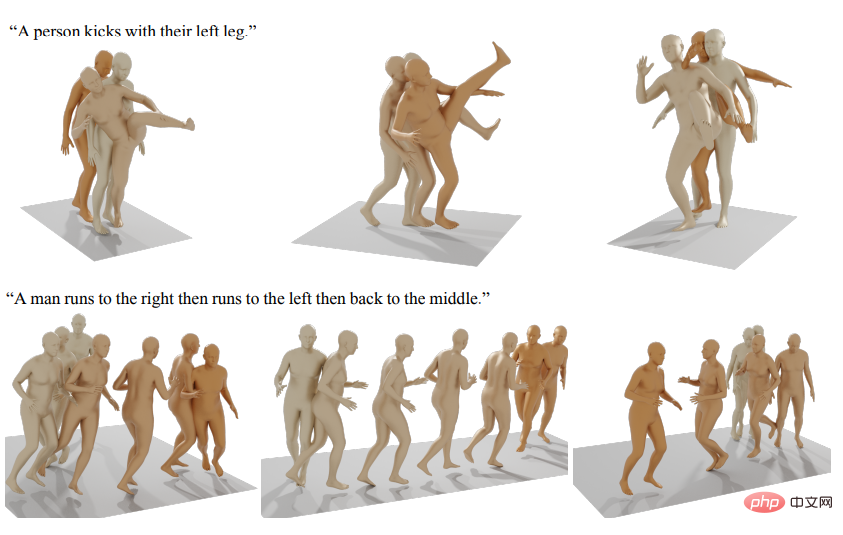
D'autres modèles d'intelligence artificielle générative publiés incluent la génération de mouvements humains, etc.
Référence : https://arxiv.org/abs/2301.04655
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 méthode js pour supprimer le nœud
méthode js pour supprimer le nœud
 Solution à l'échec de la connexion entre wsus et le serveur Microsoft
Solution à l'échec de la connexion entre wsus et le serveur Microsoft
 python fusionne deux listes
python fusionne deux listes
 qu'est-ce qu'Ed
qu'est-ce qu'Ed
 Avantages de pycharm
Avantages de pycharm
 Comment définir la police Dreamweaver
Comment définir la police Dreamweaver
 Que sont les frameworks d'intelligence artificielle Python ?
Que sont les frameworks d'intelligence artificielle Python ?
 Comment configurer la redirection de nom de domaine
Comment configurer la redirection de nom de domaine








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



