Auteur : 亚劼英梁成龙 attendez
Introduction
#🎜 🎜# Comme L'activité de livraison de nourriture de Meituan continue de se développer, l'équipe du moteur publicitaire de livraison de nourriture a mené des explorations et des pratiques techniques dans plusieurs domaines et a obtenu certains résultats. Nous le partagerons en série, et le contenu comprend principalement : ① La pratique de la plateforme commerciale ; ② La pratique de l'ingénierie de modèles d'apprentissage profond à grande échelle ; ③ L'exploration et la pratique de l'informatique de proximité ; services de construction d'index à grande échelle et de récupération en ligne ; ⑤ Pratique de la plate-forme d'ingénierie des mécanismes. Il n'y a pas si longtemps, nous avons publié la pratique de la plateforme commerciale (Pour plus de détails, veuillez vous référer à "Exploration et pratique de la plateforme publicitaire à emporter Meituan # 🎜🎜#》一文). Cet article est le deuxième d'une série d'articles.Nous nous concentrerons sur les défis posés par les modèles profonds à grande échelle au niveau des liens complets, en partant de deux aspects : la latence en ligne et l'efficacité hors ligne, et en expliquant l'ingénierie de la publicité à grande échelle. -Modèles profonds à l'échelle Pratique, j'espère que cela pourra apporter de l'aide ou de l'inspiration à tout le monde. 1 Contexte
fait partie des activités principales d'Internet telles que la recherche, la recommandation et la publicité (
est appelé promotion de recherche ). Dans ce scénario, l'exploration de données et la modélisation des intérêts pour fournir aux utilisateurs des services de haute qualité sont devenues des éléments clés pour améliorer l'expérience utilisateur. Ces dernières années, pour le secteur de la recherche et de la promotion, des modèles d'apprentissage profond ont été largement mis en œuvre dans l'industrie à l'aide des dividendes des données et de la technologie matérielle. Dans le même temps, dans les scénarios CTR, l'industrie est progressivement passée du simple DNN petit. des modèles à de grands modèles d'intégration avec des milliards de paramètres ou même des modèles très grands. Le secteur d'activité de la publicité à emporter a principalement connu le processus d'évolution du « modèle LR superficiel (tree model) » -> « modèle d'apprentissage profond » -> « modèle d'apprentissage profond à grande échelle ». L’ensemble de la tendance évolutive passe progressivement de modèles simples basés sur des caractéristiques artificielles à des modèles complexes d’apprentissage en profondeur centrés sur les données. L'utilisation de grands modèles a considérablement amélioré la capacité d'expression du modèle, fait correspondre plus précisément l'offre et la demande et a offert davantage de possibilités de développement commercial ultérieur. Mais à mesure que l'échelle du modèle et des données continue d'augmenter, nous constatons que l'efficacité a la relation suivante avec eux : Comme le montre la figure ci-dessus, lorsque l'échelle des données et l'échelle du modèle augmentent, , la « durée » correspondante deviendra de plus en plus longue. Cette « durée » correspond au niveau hors ligne, reflété dans l'efficacité ; correspond au niveau en ligne, reflété dans la Latence. Et notre travail s'articule autour de l'optimisation de cette « durée ». 
2 Analyse
Par rapport aux petits modèles ordinaires, le problème central des grands modèles est le suivant : comme le À mesure que le volume et l'échelle du modèle augmentent des dizaines, voire des centaines de fois, le stockage, la communication et le calcul sur l'ensemble du lien seront confrontés à de nouveaux défis, qui affecteront l'efficacité des itérations hors ligne de l'algorithme. Comment surmonter une série de problèmes tels que les contraintes de retard en ligne ? Analysons d'abord l'ensemble du lien, comme indiqué ci-dessous :
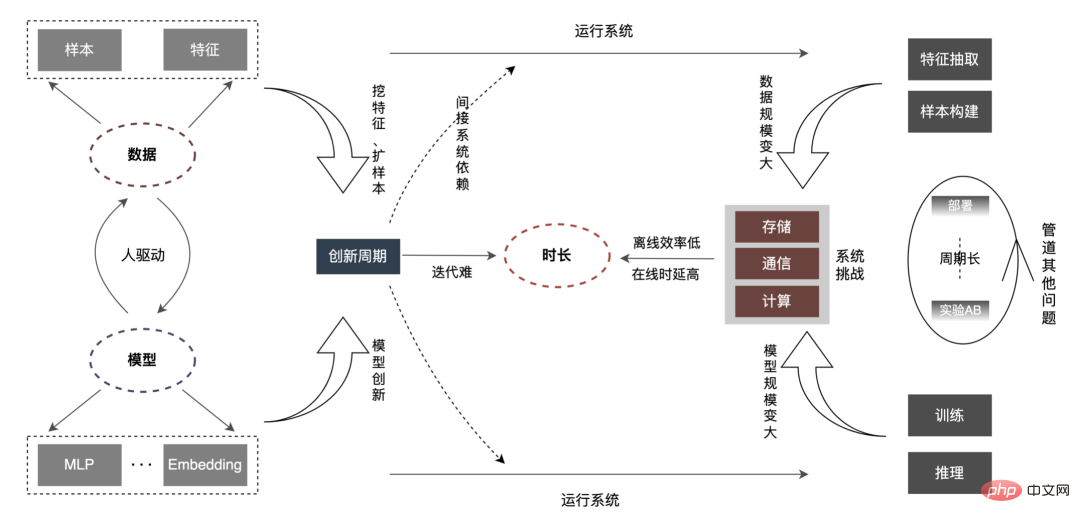
La « durée » s'allonge, ce qui reflète principalement In les aspects suivants :
-
Délai en ligne : Au niveau des fonctionnalités, lorsque la demande en ligne reste inchangée, l'augmentation du volume des fonctionnalités entraîne des problèmes telles que l'augmentation de la consommation de temps d'E/S et de calcul des fonctionnalités sont particulièrement importantes, ce qui nécessite une refonte dans des aspects tels que l'analyse et la compilation des opérateurs de fonctionnalités, la planification des tâches internes d'extraction de fonctionnalités et la transmission des E/S réseau. Au niveau du modèle, le modèle est passé de centaines de M/G à des centaines de G, ce qui a entraîné une augmentation de deux ordres de grandeur du stockage. De plus, le montant de calcul d'un seul modèle a également augmenté d'un ordre de grandeur (FLOPs de millions à maintenant des dizaines de millions#🎜🎜 #), S'appuyer simplement sur le processeur ne peut pas répondre à la demande d'une puissance de calcul énorme. Il est impératif de créer une architecture de raisonnement CPU + GPU + cache hiérarchique pour prendre en charge le raisonnement d'apprentissage en profondeur à grande échelle.
-
Efficacité hors ligne : Avec l'augmentation multiple des échantillons et des fonctionnalités, la construction d'échantillons et la formation des modèles. le délai sera considérablement prolongé et pourrait même devenir inacceptable. Comment résoudre la construction d’échantillons massifs et la formation de modèles avec des ressources limitées est le principal problème du système. Au niveau des données, l'industrie résout généralement le problème à deux niveaux. D'une part, elle optimise en permanence les contraintes du processus de traitement par lots. D'autre part, elle « transforme les lots en flux » de données, du centralisé au distribué. , ce qui améliore considérablement l'efficacité des données. Au niveau de la formation, l'accélération est obtenue grâce au GPU matériel combiné à une optimisation au niveau de l'architecture. Deuxièmement, l'innovation en matière d'algorithmes est souvent pilotée par les personnes. Comment les nouvelles données peuvent-elles rapidement correspondre au modèle ? Comment le nouveau modèle peut-il être rapidement appliqué par d'autres entreprises ? Si N personnes sont placées dans N secteurs d'activité pour effectuer indépendamment la même optimisation ? en un En optimisant un secteur d'activité et en diffusant vers N secteurs d'activité en même temps, N-1 main-d'œuvre sera libérée pour réaliser de nouvelles innovations, ce qui raccourcira considérablement le cycle d'innovation, en particulier lorsque l'ensemble de l'échelle du modèle changera à l'avenir. cela augmentera inévitablement le coût de l'itération manuelle, réalisera une transformation profonde de « les gens trouvent des fonctionnalités/modèles » à « les fonctionnalités/modèles trouvent des personnes », réduira « l'innovation répétée » et réalisera une correspondance intelligente des modèles et des données.
- PipelineAutres questions : Le pipeline d'apprentissage automatique ne se trouve pas seulement dans les liens de modèles d'apprentissage profond à grande échelle, mais dans les grands modèles Avec le déploiement , il y aura de nouveaux défis, tels que : ① Comment le processus système prend en charge le déploiement en ligne complet et incrémentiel ; ② Le temps de restauration du modèle, le temps pour faire les choses correctement et le temps de récupération après avoir mal fait les choses. En bref, de nouvelles exigences apparaîtront en matière de développement, de tests, de déploiement, de surveillance, de restauration, etc.
Cet article se concentre sur le retard en ligne (inférence de modèle, service de fonctionnalités), L'efficacité hors ligne (sample construction, préparation des données ) sera réalisée pour expliquer progressivement la pratique d'ingénierie de la publicité sur des modèles profonds à grande échelle. Nous partagerons comment optimiser la « durée » et d’autres problèmes connexes dans les chapitres suivants, alors restez à l’écoute.
3 Inférence de modèle
Au niveau de l'inférence de modèle, la publicité à emporter a connu trois versions. Depuis l'ère 1.0, elle prend en charge les niches. échelle DNN Comme le représente le modèle, à l'ère 2.0, les itérations multiservices à haute efficacité et à faible code étaient prises en charge, et dans l'ère 3.0 d'aujourd'hui, il a progressivement fait face aux besoins de puissance de calcul DNN d'apprentissage en profondeur et de stockage à grande échelle. Les principales tendances d'évolution sont présentées dans la figure ci-dessous : 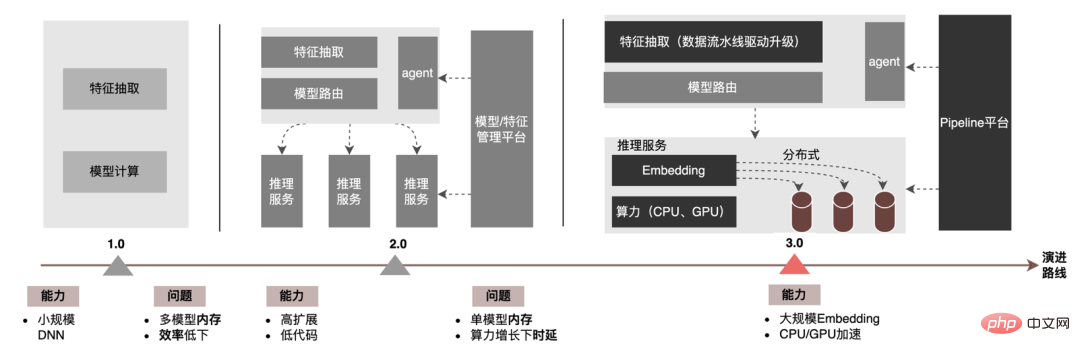
Pour les scénarios d'inférence de grands modèles, les deux problèmes centraux résolus par l'architecture 3.0 sont : "le stockage problème" et "problèmes de performances". Bien sûr, comment itérer sur N centaines de modèles G+, comment assurer la stabilité en ligne lorsque la charge de calcul augmente des dizaines de fois, comment renforcer le Pipeline, etc. sont également des défis auxquels le projet est confronté. Ci-dessous, nous nous concentrerons sur la manière dont l'architecture Model Inference 3.0 résout le problème du stockage de grands modèles via la « distribution » et sur la manière de résoudre les problèmes de performances et de débit grâce à l'accélération CPU/GPU.
3.1 Distribué
Les paramètres d'un grand modèle sont principalement divisés en deux parties : les paramètres clairsemés et les paramètres denses.
-
Paramètres clairsemés : L'ampleur du paramètre est très grande, généralement au niveau du milliard, voire au niveau du milliard/dizaine de milliards, ce qui conduira à une occupation importante de l'espace de stockage, généralement au niveau des centaines de G, ou même le niveau T. Ses caractéristiques : ① Difficulté de chargement autonome : en mode autonome, tous les paramètres Sparse doivent être chargés dans la mémoire de la machine, ce qui entraîne un grave manque de mémoire, affectant la stabilité et l'efficacité des itérations ; ② Lecture clairsemée : seulement une partie du Sparse ; les paramètres doivent être lus pour chaque calcul d'inférence. Paramètres, par exemple, le nombre total de paramètres utilisateur est au niveau de 200 millions, mais un seul paramètre utilisateur doit être lu pour chaque demande d'inférence.
- Paramètres denses : L'échelle des paramètres n'est pas grande, le modèle est généralement entièrement connecté en 2 à 3 couches et l'ampleur du paramètre est de l'ordre du million/dix millions. Caractéristiques : ① Une seule machine peut être chargée : les paramètres denses occupent environ des dizaines de mégaoctets et la mémoire d'une seule machine peut être chargée normalement. Par exemple : la couche d'entrée est 2000, la couche entièrement connectée est [1024, 512, 256] et. le total des paramètres est : 2000 * 1024 + 1024 * 512 + 512 * 256 + 256 = 2703616, un total de 2,7 millions de paramètres, et la mémoire occupée est inférieure à 100 Mo ② Lecture complète : pour chaque calcul d'inférence, les paramètres complets sont nécessaires ; à lire.
Par conséquent, la clé pour résoudre le problème de la croissance à grande échelle des paramètres de modèle est de transformer les paramètres clairsemés du stockage sur une seule machine en stockage distribué. La méthode de transformation comprend deux parties : ① Conversion de la structure du réseau du modèle ; ② Exportation des paramètres clairsemés ; .
3.1.1 Conversion de la structure du réseau de modèle
Les méthodes de l'industrie pour obtenir des paramètres distribués sont grossièrement divisées en deux types : les services externes obtiennent les paramètres à l'avance et les transmettent au service de prédiction qui transforme en interne TF (TensorFlow ; ) opérateur pour obtenir les paramètres du stockage distribué. Afin de réduire le coût de modification architecturale et de réduire l'intrusion dans la structure du modèle existant, nous avons choisi d'obtenir des paramètres distribués en modifiant l'opérateur TF.
Dans des circonstances normales, le modèle TF utilisera des opérateurs natifs pour lire les paramètres Sparse. L'opérateur principal est l'opérateur GatherV2. L'entrée de l'opérateur comporte principalement deux parties : ① Liste d'ID à interroger ; tableau des paramètres. La fonction de l'opérateur
est de lire les données d'intégration correspondant à l'index de la liste d'ID à partir de la table d'intégration et de les renvoyer. Il s'agit essentiellement d'un processus de requête de hachage. Parmi eux, les paramètres Sparse stockés dans la table Embedding sont tous stockés dans la mémoire mono-machine dans le modèle mono-machine.
La transformation de l'opérateur TF est essentiellement une transformation de la structure du réseau modèle. Les points centraux de la transformation comprennent principalement deux parties : ① Reconstruction du graphe de réseau ② Opérateurs distribués personnalisés.
1. Reconstruction du diagramme de réseau : Transformez la structure du réseau du modèle, remplacez l'opérateur TF natif par un opérateur distribué personnalisé et solidifiez la table d'intégration native.
-
Remplacement de l'opérateur distribué : parcourez le réseau modèle, remplacez l'opérateur GatherV2 qui doit être remplacé par l'opérateur distribué personnalisé MtGatherV2 et modifiez l'entrée/sortie des nœuds en amont et en aval en même temps .
- Solidification de la table d'intégration native : la table d'intégration native est solidifiée en tant qu'espaces réservés, ce qui peut non seulement conserver l'intégrité de la structure du réseau du modèle, mais également éviter l'occupation de la mémoire d'une seule machine par des paramètres clairsemés.
 2. Opérateur distribué personnalisé : modifiez le processus de requête d'intégration en fonction de la liste d'ID, interrogez à partir de la table d'intégration locale et modifiez-le pour interroger à partir du KV distribué.
2. Opérateur distribué personnalisé : modifiez le processus de requête d'intégration en fonction de la liste d'ID, interrogez à partir de la table d'intégration locale et modifiez-le pour interroger à partir du KV distribué.
-
Demande de requête : dédupliquez l'ID d'entrée pour réduire le volume de requête et interrogez simultanément le cache de deuxième niveau (Cache local + KV distant) via le partitionnement pour obtenir le vecteur d'intégration.
-
Gestion des modèles : Maintenir le processus d'enregistrement et de désinstallation du modèle Embedding Meta, ainsi que la création et la destruction des fonctions de cache.
- Déploiement de modèle : Déclenche le chargement des informations sur les ressources du modèle et le processus d'importation parallèle des données d'intégration dans KV.
3.1.2 Exportation de paramètres clairsemés
-
Exportation parallèle fragmentée : analysez le fichier Checkpoint du modèle, obtenez les informations de pièce correspondant à la table d'intégration, divisez-les en fonction de la pièce et passez chaque fichier pièce via plusieurs nœuds Worker est exporté vers HDFS en parallèle.
- Importer KV : pré-attribuez plusieurs buckets à l'avance. Les buckets stockeront des informations telles que les versions de modèles pour faciliter les requêtes de routage en ligne. Dans le même temps, les données d'intégration du modèle seront également stockées dans le Bucket et importées dans KV en parallèle par sharding.
Le processus global est illustré dans la figure ci-dessous. Nous garantissons les exigences normales d'itération du grand modèle 100G grâce à la conversion de la structure du modèle distribué hors ligne, à la garantie de cohérence des données de proximité et à la mise en cache des données de point d'accès en ligne.
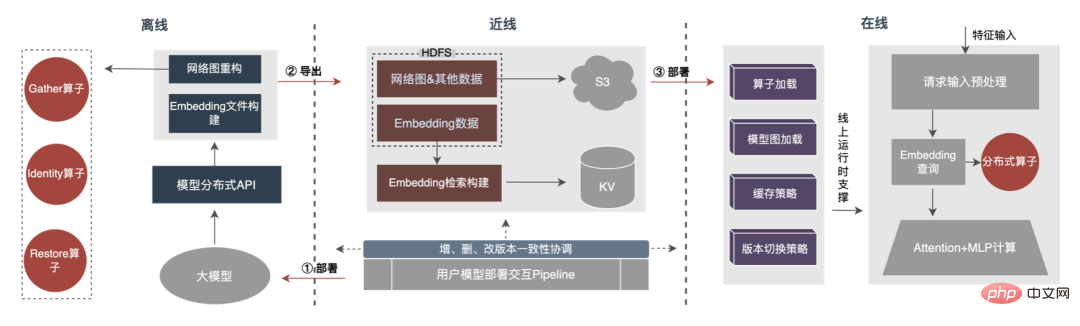
On peut voir que le stockage utilisé par le stockage distribué est une capacité KV externe, qui sera remplacée à l'avenir par le service d'intégration plus efficace, flexible et facile à gérer.
3.2 Accélération du processeur
En plus des méthodes d'optimisation du modèle lui-même, il existe deux principales méthodes d'accélération du processeur courantes : ① Optimisation du jeu d'instructions, comme l'utilisation du jeu d'instructions AVX2, AVX512 ; ② Utilisation des bibliothèques d'accélération (TVM ; , OpenVINO ).
-
Optimisation du jeu d'instructions : Si vous utilisez le modèle TensorFlow, lors de la compilation du code du framework TensorFlow, ajoutez simplement l'élément d'optimisation du jeu d'instructions directement aux options de compilation. La pratique a prouvé que l'introduction des jeux d'instructions AVX2 et AVX512 a des effets d'optimisation évidents et que le débit des services d'inférence en ligne a augmenté de plus de 30 %.
- Optimisation de la bibliothèque d'accélération : La bibliothèque d'accélération optimise et intègre la structure du modèle de réseau pour obtenir des effets d'accélération d'inférence. Les bibliothèques d'accélération couramment utilisées dans l'industrie incluent TVM, OpenVINO, etc. Parmi elles, TVM prend en charge plusieurs plates-formes et offre une bonne polyvalence. OpenVINO est optimisé spécifiquement pour le matériel du fabricant Intel. Il offre une polyvalence générale mais un bon effet d'accélération.
Ci-dessous, nous nous concentrerons sur une partie de notre expérience pratique dans l'utilisation d'OpenVINO pour l'accélération du processeur. OpenVINO est un ensemble de cadres d'optimisation de l'accélération informatique basés sur l'apprentissage profond lancé par Intel, qui prend en charge l'optimisation de la compression, le calcul accéléré et d'autres fonctions des modèles d'apprentissage automatique. Le principe d'accélération d'OpenVINO est simplement résumé en deux parties : la fusion d'opérateurs linéaires et l'étalonnage de la précision des données.
-
Fusion d'opérateurs linéaires : OpenVINO utilise l'optimiseur de modèle pour fusionner de manière uniforme et linéaire les opérateurs multicouches dans le réseau modèle afin de réduire les frais de planification des opérateurs et les frais d'accès aux données entre les opérateurs. Par exemple, les trois opérateurs Conv+. BN+Relu sont regroupés en un opérateur de structure CBR.
- Étalonnage de la précision des données : Une fois le modèle entraîné hors ligne, puisqu'il n'est pas nécessaire de rétropropagation pendant le processus d'inférence, la précision des données peut être réduite de manière appropriée, par exemple en passant à la précision FP16 ou INT8, rendant ainsi la mémoire empreinte plus petite, latence d'inférence plus faible.
L'accélération du processeur accélère généralement l'inférence pour les files d'attente de candidats par lots fixes, mais dans les scénarios de recherche et de promotion, les files d'attente de candidats sont souvent dynamiques. Cela signifie qu'avant l'inférence de modèle, une opération de correspondance par lots doit être ajoutée, c'est-à-dire que la file d'attente dynamique des candidats Batch demandée est mappée sur un modèle Batch le plus proche, mais cela nécessite la construction de N modèles de correspondance, ce qui entraîne N fois l'utilisation de la mémoire. . Le volume du modèle actuel a atteint des centaines de gigaoctets et la mémoire est très limitée. Par conséquent, la sélection d’une structure de réseau raisonnable pour l’accélération est une question clé à prendre en compte. L'image ci-dessous représente la structure opérationnelle globale : 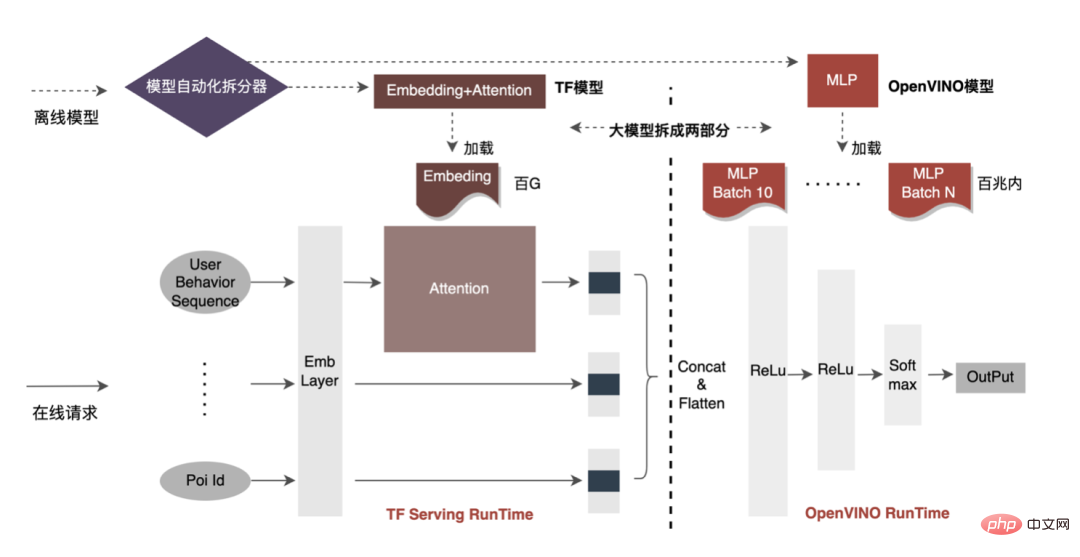
-
Distribution du réseau : La structure globale du réseau du modèle CTR est résumée en trois parties : la couche d'intégration, la couche d'attention et la couche MLP. La couche d'intégration est utilisée pour l'acquisition de données et la couche d'attention contient des opérations plus logiques. et les réseaux légers, la couche MLP est une informatique en réseau dense.
- Sélection du réseau d'accélération : OpenVINO a un meilleur effet d'accélération pour les calculs de réseau purs et peut être bien appliqué à la couche MLP. De plus, la plupart des données du modèle sont stockées dans la couche Embedding et la couche MLP n'occupe que quelques dizaines de mégaoctets de mémoire. Si plusieurs lots sont divisés pour le réseau de couches MLP, l'utilisation de la mémoire du modèle sera avant l'optimisation (Embedding+Attention+MLP) ≈ après l'optimisation (Embedding+Attention+MLP×Batch number), et l'impact sur l'utilisation de la mémoire sera petit. Par conséquent, nous avons finalement sélectionné le réseau de couche MLP comme réseau d’accélération du modèle.
À l'heure actuelle, la solution d'accélération CPU basée sur OpenVINO a obtenu de bons résultats dans l'environnement de production : lorsque le CPU est le même que la ligne de base, le débit du service est augmenté de 40 % et le délai moyen est réduit de 15%. Si vous souhaitez faire une certaine accélération au niveau du CPU, OpenVINO est un bon choix.
3.3 Accélération GPU
D'une part, avec le développement des entreprises, les formes commerciales deviennent de plus en plus abondantes, le trafic devient de plus en plus élevé, les modèles deviennent plus larges et plus profonds et la consommation de puissance de calcul augmente fortement ; d'autre part, des scénarios publicitaires utilisant principalement le modèle DNN, impliquant un grand nombre d'opérations d'intégration de fonctionnalités clairsemées et de réseaux neuronaux en virgule flottante. En tant que service en ligne d'accès à la mémoire et de calcul intensif, il doit répondre aux exigences de faible latence et de débit élevé tout en garantissant la disponibilité, ce qui constitue également un défi pour la puissance de calcul d'une seule machine. Si ces conflits entre les besoins en ressources informatiques et l'espace ne sont pas bien résolus, ils limiteront considérablement le développement commercial : avant que le modèle ne soit élargi et approfondi, les services d'inférence purement CPU peuvent fournir un débit considérable, mais une fois le modèle élargi et approfondi, les calculs deviennent complexe Afin de garantir une haute disponibilité, une grande quantité de ressources machine doit être consommée, ce qui rend les grands modèles impossibles à appliquer en ligne à grande échelle. À l'heure actuelle, une solution courante dans l'industrie consiste à utiliser le GPU pour résoudre ce problème. Le GPU lui-même est plus adapté aux tâches gourmandes en calcul. L'utilisation de GPU nécessite de résoudre les défis suivants : comment atteindre un débit aussi élevé que possible tout en garantissant une disponibilité et une faible latence, tout en prenant en compte la facilité d'utilisation et la polyvalence. À cette fin, nous avons également réalisé de nombreux travaux pratiques sur les GPU, tels que TensorFlow-GPU, TensorFlow-TensorRT, TensorRT, etc. Afin de prendre en compte la flexibilité de TF et l'effet d'accélération de TensorRT, nous adoptons une conception d'architecture indépendante en deux étapes de TensorFlow+TensorRT.
3.3.1 Analyse de l'accélération
-
Calcul hétérogène : Notre idée est cohérente avec l'accélération du processeur. Le modèle CTR d'apprentissage en profondeur 200G ne peut pas être directement intégré au GPU, et les opérateurs gourmands en accès mémoire conviennent ( Par exemple, les opérations liées à l'intégration) CPU, les opérateurs à forte intensité de calcul (tels que MLP) conviennent au GPU.
-
Plusieurs points auxquels il faut prêter attention lors de l'utilisation du GPU : ① Interaction fréquente entre la mémoire et la mémoire vidéo ; ② Latence et débit ; ③ Compromis pour l'évolutivité et l'optimisation des performances ;
-
Sélection de moteurs d'inférence : Les moteurs d'accélération d'inférence couramment utilisés dans l'industrie incluent TensorRT, TVM, XLA, ONNXRuntime, etc. Étant donné que TensorRT est plus approfondi dans l'optimisation des opérateurs que les autres moteurs, il peut également être implémenté via des plugins personnalisés. Tout opérateur a une forte évolutivité. De plus, TensorRT prend en charge les modèles des plateformes d'apprentissage courantes (Caffe, PyTorch, TensorFlow, etc. ), et ses périphériques deviennent de plus en plus complets (outil de conversion de modèles onnx-tensorrt, outil d'analyse des performances nsys , etc. ), Par conséquent, le moteur d'accélération côté GPU utilise TensorRT.
- Analyse du modèle : La structure globale du réseau du modèle CTR est résumée en trois parties : la couche d'intégration, la couche d'attention et la couche MLP. La couche d'intégration est utilisée pour l'acquisition de données et convient au processeur que contient la couche d'attention ; opérations plus logiques et légères Pour l'informatique en réseau, la couche MLP se concentre sur l'informatique en réseau, et ces calculs peuvent être effectués en parallèle et conviennent aux cœurs GPU (Cuda Core, Tensor Core) peuvent être pleinement utilisés pour améliorer le degré. du parallélisme.
3.3.2 Objectifs d'optimisation
La phase d'inférence de l'apprentissage profond a des exigences très élevées en termes de puissance de calcul et de latence. Si le réseau neuronal formé est directement déployé du côté de l'inférence, il est très probable qu'il sera insuffisant. puissance de calcul pour fonctionner. Ou des problèmes tels qu'un long temps de raisonnement. Par conséquent, nous devons effectuer certaines optimisations sur le réseau neuronal formé. L'idée générale d'optimiser les modèles de réseaux neuronaux dans l'industrie peut être optimisée sous différents aspects tels que la compression des modèles, la fusion de différentes couches de réseau, la fragmentation et l'utilisation de types de données de faible précision. Elle nécessite même une optimisation ciblée. sur les caractéristiques du matériel. Pour cela, nous optimisons principalement autour des deux objectifs suivants :
-
Débit sous contraintes de retard et de ressources : lorsque les ressources partagées telles que le registre et le cache n'ont pas besoin d'être en concurrence, l'augmentation de la concurrence peut améliorer efficacement l'utilisation des ressources (CPU, GPU, etc. utilisation), mais alors ceci peut augmenter la latence des requêtes. Étant donné que la limite de délai du système en ligne est très stricte, la limite supérieure de débit du système en ligne ne peut pas être simplement convertie via l'indicateur d'utilisation des ressources. Elle doit être évaluée de manière globale sous la contrainte de délai et combinée avec la limite supérieure des ressources. Lorsque la latence du système est faible et que l'utilisation des ressources (Mémoire/CPU/GPU, etc.) est le facteur limitant, l'utilisation des ressources peut être réduite grâce à l'optimisation du modèle. Lorsque l'utilisation des ressources du système est faible, la latence ; is Lorsque des contraintes surviennent, la latence peut être réduite grâce à l'optimisation de la fusion et à l'optimisation du moteur. En combinant les diverses méthodes d'optimisation ci-dessus, les capacités globales des services système peuvent être efficacement améliorées, atteignant ainsi l'objectif d'amélioration du débit du système.
- Densité de calcul sous contraintes de calcul : dans les systèmes hétérogènes CPU/GPU, les performances d'inférence du modèle sont principalement affectées par l'efficacité de la copie des données et l'efficacité du calcul, qui sont déterminées respectivement par les opérateurs gourmands en accès mémoire et les opérateurs gourmands en calcul. l'efficacité est affectée par l'efficacité de la transmission des données PCIe, la lecture et l'écriture de la mémoire CPU/GPU, etc., et l'efficacité informatique est affectée par l'efficacité informatique de diverses unités informatiques telles que CPU Core, CUDA Core et Tensor Core. Avec le développement rapide du matériel tel que les GPU, les capacités de traitement des opérateurs gourmands en calcul ont augmenté rapidement, ce qui a entraîné le phénomène selon lequel les opérateurs gourmands en accès mémoire entravent l'amélioration des capacités de service du système, réduisant ainsi les opérateurs gourmands en accès mémoire. et l'amélioration de la densité de calcul devient également de plus en plus importante pour les capacités des services système, c'est-à-dire réduire la copie des données et le lancement du noyau lorsque la quantité de calculs du modèle ne change pas beaucoup. Par exemple, l'optimisation du modèle et l'optimisation de la fusion sont utilisées pour réduire l'utilisation de transformations d'opérateurs (tels que Cast/Unsqueeze/Concat et d'autres opérateurs), et CUDA Graph est utilisé pour réduire le lancement du noyau, etc.
Ce qui suit se concentrera sur les deux objectifs ci-dessus et présentera en détail certains des travaux que nous avons effectués dans optimisation du modèle, optimisation de la fusion et optimisation du moteur.
3.3.3 Optimisation du modèle
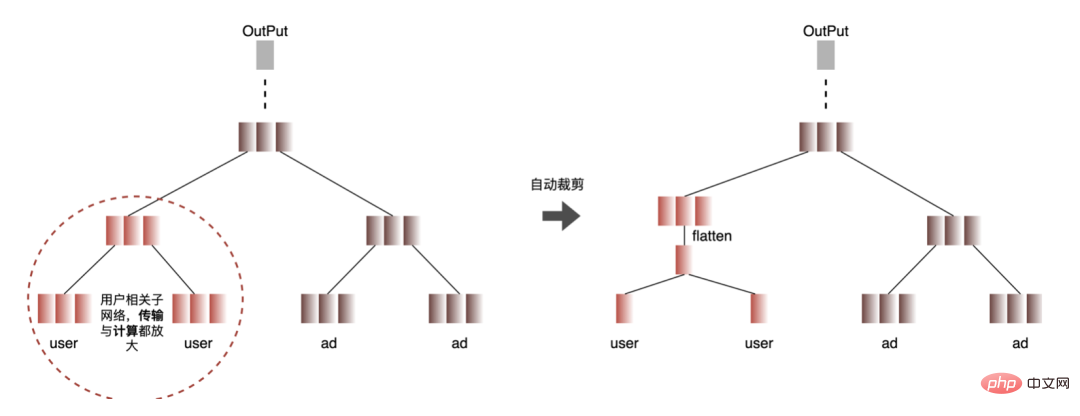
1. Calcul et déduplication de transmission : lors de l'inférence, le même lot ne contient qu'une seule information utilisateur, de sorte que les informations utilisateur peuvent être réduites de la taille du lot à 1 avant l'inférence, ce qui est vraiment nécessaire Développez à nouveau pendant l'inférence pour réduire la copie de transmission de données et la surcharge de calcul répétée. Comme le montre la figure ci-dessous, vous pouvez interroger les informations sur les fonctionnalités de la classe User une seule fois avant l'inférence, les couper uniquement dans les sous-réseaux liés à l'utilisateur, puis les développer lorsque vous devez calculer l'association.
-
Processus automatisé : recherchez le nœud avec des calculs répétés (nœud rouge), si tous les nœuds feuilles du nœud sont des nœuds de calcul répétés, alors le nœud calcule également les nœuds à plusieurs reprises. , en commençant par les nœuds feuilles et en recherchant vers le haut couche par couche tous les nœuds en double jusqu'à ce que les nœuds soient traversés et recherchés, que les lignes de connexion de tous les nœuds rouges et blancs soient trouvées, que le nœud d'expansion de la fonctionnalité utilisateur soit inséré et que la fonctionnalité utilisateur soit développée.
2. Optimisation de la précision des données : Étant donné que la formation du modèle nécessite une rétropropagation pour mettre à jour les gradients, la précision des données doit être plus élevée tandis que l'inférence du modèle ne nécessite que l'inférence directe. dans le but d'assurer l'effet, utilisez FP16 ou une précision mixte pour l'optimisation, économisez de l'espace mémoire, réduisez la surcharge de transmission et améliorez les performances et le débit d'inférence.
3. Calculation Pushdown : La structure du modèle CTR est principalement composée de trois couches : Embedding, Attention et MLP. La couche Embedding est orientée vers l'acquisition de données, et l'Attention est partiellement orientée vers la logique et partiellement biaisée. Vers le calcul, afin d'exploiter pleinement le potentiel du GPU, la majeure partie de la logique de calcul d'Attention et MLP dans la structure du modèle CTR est déplacée du CPU vers le GPU pour le calcul, et le débit global est grandement amélioré.
3.3.4 Optimisation de la fusion
Lors de l'inférence de modèle en ligne, le fonctionnement de chaque couche est complété par le GPU. En fait, le CPU termine le calcul en démarrant différents noyaux CUDA. Cependant, le noyau CUDA calcule les tenseurs très rapidement. beaucoup de temps est souvent perdu au démarrage du noyau CUDA et à la lecture et à l'écriture des tenseurs d'entrée/sortie de chaque couche, ce qui provoque un goulot d'étranglement de la bande passante mémoire et un gaspillage des ressources GPU. Ici, nous présenterons principalement la partie TensorRT optimisation automatique et optimisation manuelle. 1. Optimisation automatique : TensorRT est un optimiseur d'inférence d'apprentissage profond haute performance qui peut fournir un déploiement d'inférence à faible latence et à haut débit pour les applications d'apprentissage profond. TensorRT peut être utilisé pour accélérer l'inférence sur des modèles à très grande échelle, des plateformes embarquées ou des plateformes de conduite autonome. TensorRT peut désormais prendre en charge presque tous les frameworks d'apprentissage profond tels que TensorFlow, Caffe, MXNet et PyTorch. La combinaison de TensorRT avec les GPU NVIDIA peut permettre un déploiement et une inférence rapides et efficaces dans presque tous les frameworks. Et certaines optimisations ne nécessitent pas trop de participation de l'utilisateur, comme certaines Layer Fusion, Kernel Auto-Tuning, etc.
- Layer Fusion : TensorRT réduit considérablement le nombre de couches réseau en fusionnant horizontalement ou verticalement entre les couches. En termes simples, il réduit le nombre de temps de circulation des données et de la mémoire vidéo en fusionnant certaines opérations de calcul ou en supprimant certaines opérations redondantes. . Utilisation fréquente et surcharge de planification. Par exemple, les structures de réseau courantes incluent la fusion Convolution And ElementWise Operation, la fusion CBR, etc. La figure suivante est un diagramme structurel de certains sous-graphes de la structure entière du réseau avant et après la fusion FusedNewOP peut impliquer diverses tactiques pendant le processus de fusion, tels que CudnnMLPFC, CudnnMLPMM, CudaMLP, etc. Enfin, une tactique optimale sera sélectionnée comme structure fusionnée en fonction de la durée. Grâce à l'opération de fusion, le nombre de couches réseau est réduit et le canal de données est raccourci ; la même structure est fusionnée pour élargir le canal de données, atteignant ainsi l'objectif d'une utilisation plus efficace des ressources GPU.
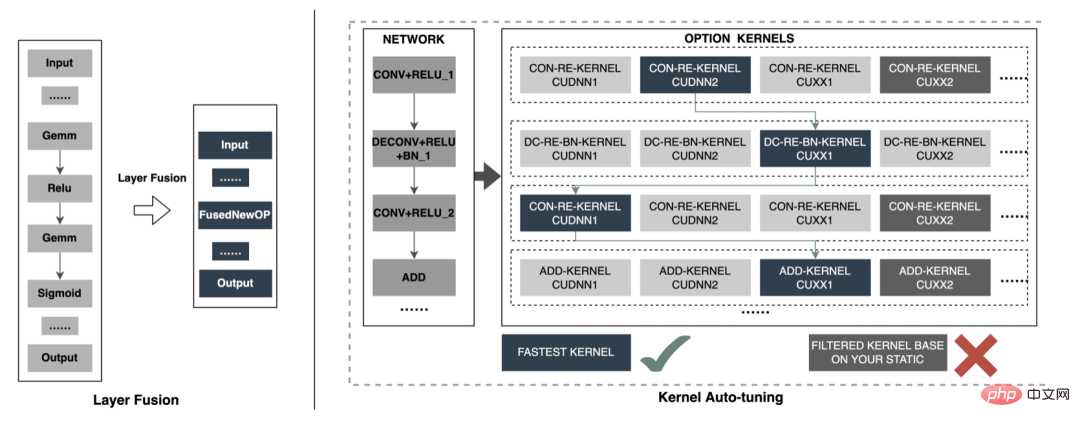
- Kernel Auto-Tuning : Lorsque le modèle de réseau est en inférence, il appelle le noyau CUDA du GPU pour le calcul. TensorRT peut ajuster le noyau CUDA pour différents modèles de réseau, structures de cartes graphiques, nombre de SM, fréquences de base, etc., sélectionner différentes stratégies d'optimisation et méthodes de calcul, et trouver la méthode de calcul optimale adaptée à la situation actuelle pour garantir que le modèle actuel obtient les meilleurs résultats sur une plateforme spécifique. Excellentes performances. L'image ci-dessus est l'idée principale de l'optimisation. Chaque opération aura plusieurs stratégies d'optimisation du noyau (cuDNN, cuBLAS, etc. Selon l'architecture actuelle, les noyaux inefficaces sont filtrés de toutes les stratégies d'optimisation et du noyau optimal). est sélectionné en même temps, formant finalement un nouveau réseau.
2. Optimisation manuelle : Comme nous le savons tous, le GPU convient aux opérateurs gourmands en calculs, mais pas aussi bien aux autres types d'opérateurs (opérateurs de calcul légers, opérateurs d'opérations logiques, etc. .) amical. Lors de l'utilisation des calculs GPU, chaque opération passe généralement par plusieurs processus : le CPU alloue de la mémoire vidéo sur le GPU -> Le CPU envoie des données au GPU -> Le CPU démarre le noyau CUDA -> Le CPU récupère les données -> Le CPU libère la mémoire vidéo du GPU. Afin de réduire les frais généraux tels que la planification, le lancement du noyau et l'accès à la mémoire, une intégration réseau est requise. En raison de la structure flexible et changeante du grand modèle CTR, il est difficile d'unifier les méthodes de fusion de réseaux et seuls des problèmes spécifiques peuvent être analysés en détail. Par exemple, dans le sens vertical, Cast, Unsqueeze et Less sont fusionnés, et TensorRT internal Conv, BN et Relu sont fusionnés ; dans le sens horizontal, les opérateurs d'entrée de même dimension sont fusionnés ; À cette fin, nous utilisons des outils d'analyse des performances liés à NVIDIA (NVIDIA Nsight Systems, NVIDIA Nsight Compute, etc.) pour analyser des problèmes spécifiques en fonction de scénarios commerciaux en ligne réels. Intégrez ces outils d'analyse des performances dans l'environnement d'inférence en ligne pour obtenir le fichier GPU Profing pendant le processus d'inférence. Grâce au fichier Profing, nous pouvons clairement voir le processus d'inférence.Nous avons constaté que le phénomène lié au lancement du noyau de certains opérateurs dans l'ensemble de l'inférence est grave, que les écarts entre certains opérateurs sont importants et qu'il y a place à l'optimisation, comme le montre l'exemple ci-dessous. le chiffre suivant :
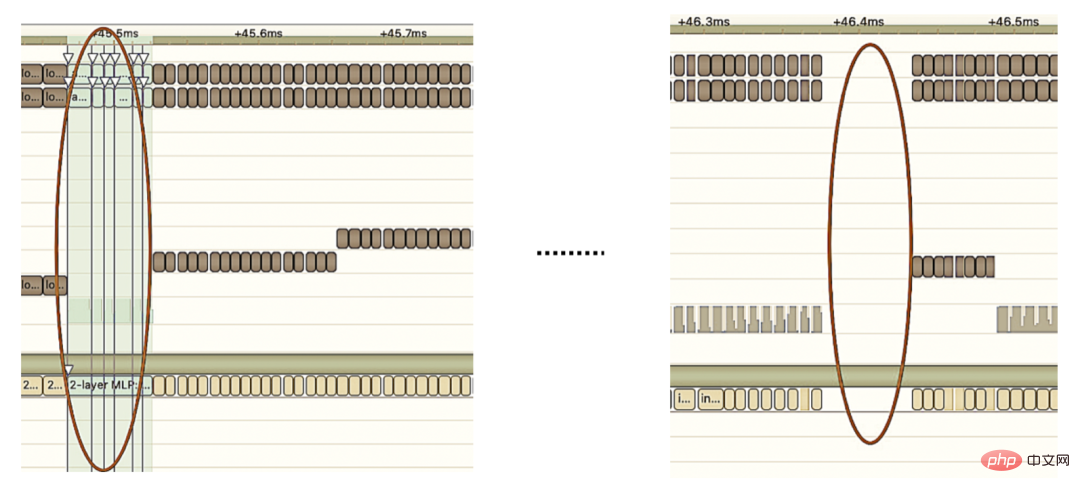
À cette fin, analysez l'ensemble du réseau à l'aide d'outils d'analyse des performances et de modèles convertis pour découvrir les parties optimisées par TensorRT, puis effectuez l'intégration du réseau sur d'autres sous-structures du réseau qui peuvent être optimisées, tout en garantissant également que ces sous-structures sont L'ensemble du réseau occupe une certaine proportion pour garantir que la densité de calcul puisse augmenter dans une certaine mesure après l'intégration. Quant au type de méthode d'intégration de réseau à utiliser, elle peut être utilisée de manière flexible selon le scénario spécifique. La figure suivante est une comparaison des diagrammes de sous-structure avant et après notre intégration :
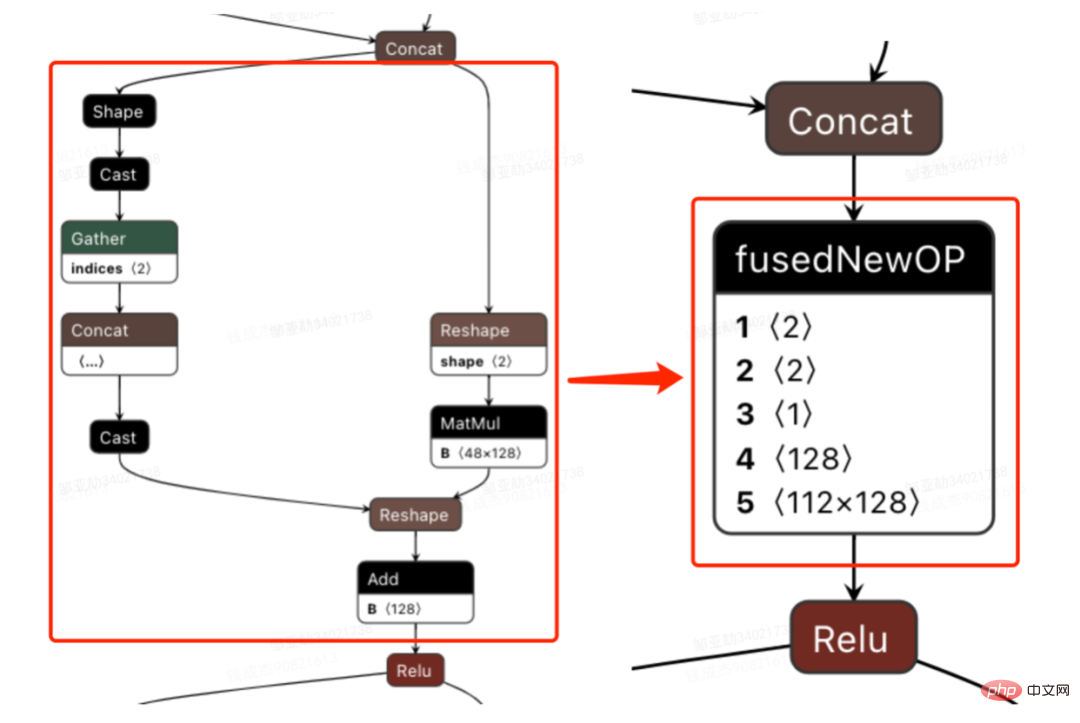
3.3.5 Optimisation du moteur
.
-
Multi-modèle : Étant donné que l'ampleur des demandes des utilisateurs dans les annonces à emporter est incertaine et que les annonces sont parfois plus nombreuses et parfois moins, plusieurs modèles sont chargés à cet effet. Chaque modèle correspond à un lot d'entrées différentes. . L'échelle d'entrée est divisée en compartiments et catégories, et le remplissage est divisé en plusieurs. Le lot est fixe et correspond au modèle d'inférence correspondant.
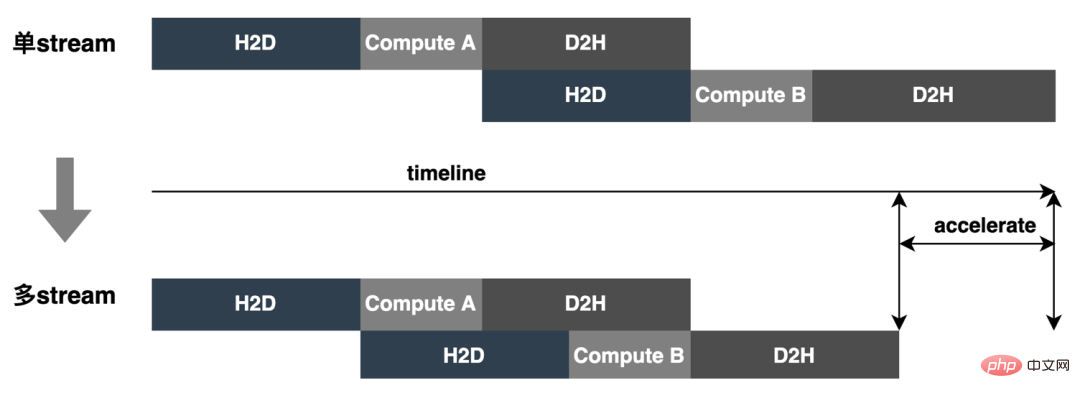
- Multi-contextes et Multi-flux : L'utilisation du multi-contexte et du multi-flux pour chaque modèle Batch peut non seulement éviter la surcharge du modèle en attente du même contexte, mais également utiliser pleinement la concurrence de multi-flux pour réaliser le flux Dans le même temps, afin de mieux résoudre le problème de la concurrence entre les ressources, CAS est introduit. Comme le montre la figure ci-dessous, un flux unique devient un flux multiple :
-
Dynamic Shape : Afin de gérer le remplissage de données inutile dans les scénarios où le lot d'entrée est incertain, et en même temps, réduisez le nombre de modèles et réduisez les ressources telles que la mémoire vidéo. Pour réduire le gaspillage, Dynamic Shape est introduit et le modèle est une inférence basée sur les données d'entrée réelles, réduisant ainsi le remplissage des données et le gaspillage inutile de ressources informatiques, et finalement atteindre les objectifs d’optimisation des performances et d’amélioration du débit.
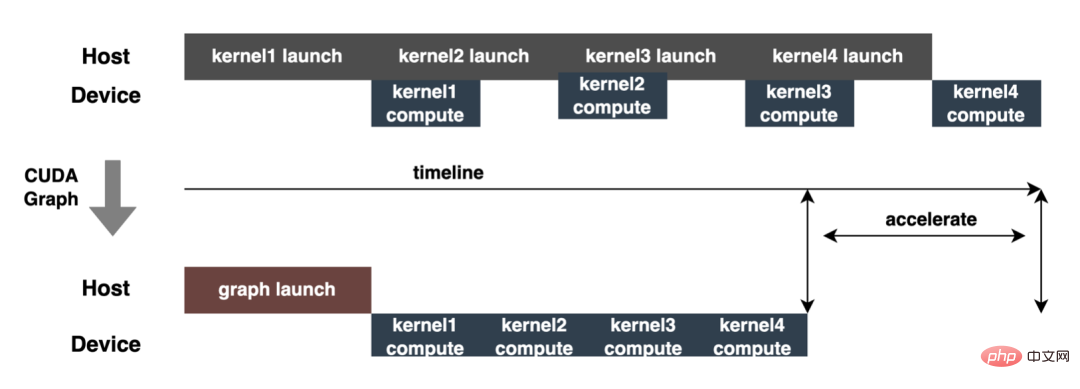
- CUDA Graph : Le temps passé par un GPU moderne pour chaque opération (exécution du noyau, etc.) est d'au moins un niveau de la microseconde, et la soumission de chaque opération au GPU générera également une certaine surcharge (niveau de la microseconde ). Dans l'inférence réelle, il est souvent nécessaire d'effectuer un grand nombre d'opérations sur le noyau. Chacune de ces opérations est soumise au GPU séparément et calculée indépendamment. Si la surcharge de tous les démarrages de soumission peut être résumée, cela devrait apporter une amélioration globale. en performances. CUDA Graph peut y parvenir en définissant l'ensemble du processus informatique comme un graphique plutôt qu'une liste d'opérations individuelles, puis en réduisant la surcharge de démarrage de la soumission du noyau en permettant à une seule opération CPU de lancer plusieurs opérations GPU sur le graphique. L'idée principale de CUDA Graph est de réduire le nombre de lancements de noyau en capturant le graphique avant et après l'inférence et en mettant à jour le graphique en fonction des besoins d'inférence, les inférences ultérieures ne nécessitent plus de lancements de noyau les uns après les autres, uniquement des lancements de graphiques. sont nécessaires, réduisant ainsi le nombre de lancements du noyau. Comme le montre la figure ci-dessous, une inférence effectue 4 opérations liées au noyau, et l'effet d'optimisation peut être clairement visible en utilisant CUDA Graph.
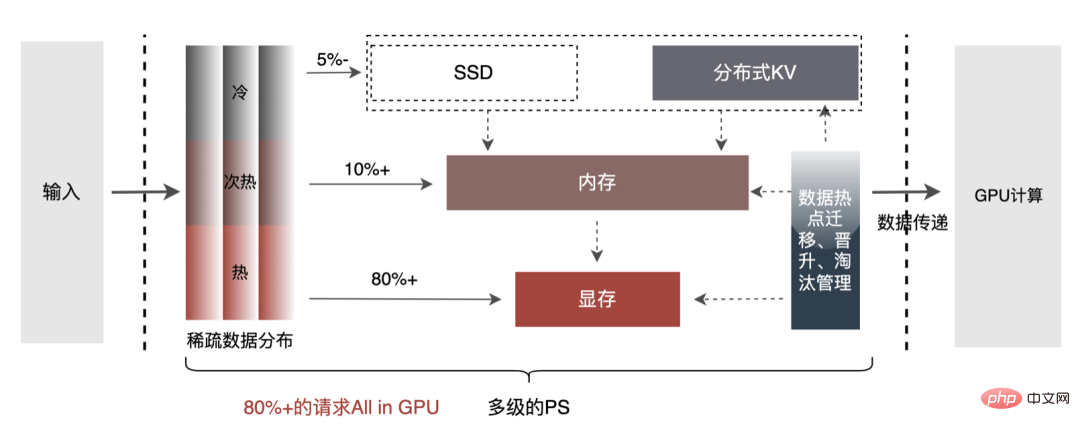
- PS multi-niveaux : Afin d'explorer davantage les performances du moteur d'accélération GPU, les opérations de requête sur l'intégration de données peuvent être effectuées via PS multi-niveaux : Mémoire GPU Cache-> Mémoire CPU Cache-> SSD local / KV distribué. Parmi eux, les données de points d'accès peuvent être mises en cache dans la mémoire du GPU, et les données mises en cache peuvent être mises à jour dynamiquement via des mécanismes tels que la migration, la promotion et l'élimination des points d'accès de données, en utilisant pleinement la puissance de calcul parallèle et les capacités d'accès à la mémoire du GPU pour des requêtes efficaces. . Après des tests hors ligne, les performances de requête du cache GPU sont 10 fois supérieures à celles du cache CPU ; pour les données manquantes du cache GPU, elles peuvent être interrogées en accédant au cache CPU pour satisfaire plus de 90 % des accès aux données ; requêtes à longue traîne, l'acquisition de données doit alors être effectuée en accédant au KV distribué. La structure spécifique est la suivante :
3.3.6 Pipeline
Le modèle va de la formation hors ligne au chargement final en ligne. L'ensemble du processus est fastidieux et sujet aux erreurs, et le modèle ne peut pas être utilisé universellement. différentes cartes GPU, différentes versions de TensorRT et CUDA. Cela apporte plus de possibilités d'erreurs dans la conversion de modèle. Par conséquent, afin d'améliorer l'efficacité globale de l'itération du modèle, nous avons construit des fonctionnalités pertinentes dans Pipeline, comme le montre la figure ci-dessous :
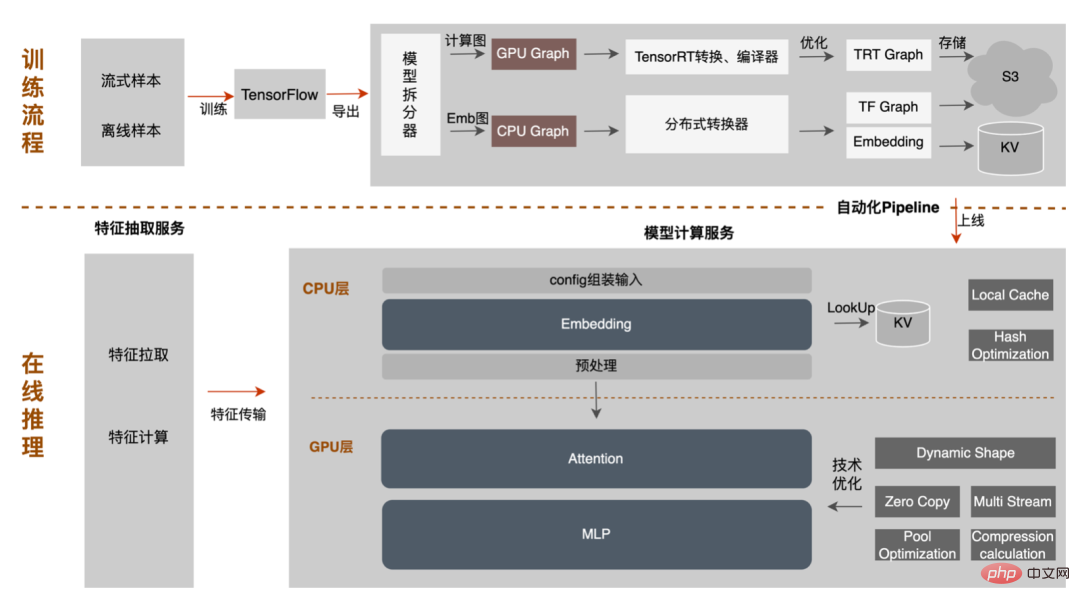
La construction du pipeline comprend deux parties : le processus de fractionnement et de conversion du modèle côté hors ligne et le processus de déploiement du modèle côté en ligne : #🎜🎜 ## 🎜🎜#
- Côté hors ligne : fournissez simplement le nœud de division du modèle et la plate-forme divisera automatiquement le modèle TF d'origine en sous-modèles d'intégration et sous-graphiques de calcul -modèles, où le sous-modèle d'intégration effectue le remplacement des opérateurs distribués et l'importation d'intégration via le convertisseur distribué ; le sous-modèle de graphique informatique exécute le modèle TensorRT en fonction de l'environnement matériel sélectionné (modèle GPU, version TensorRT, version CUDA ; ) un travail d'optimisation de conversion et de compilation, et enfin les résultats de conversion des deux sous-modèles sont stockés dans S3 pour un déploiement ultérieur du modèle et en ligne. L'ensemble du processus est automatiquement complété par la plateforme, sans que l'utilisateur ait connaissance des détails d'exécution.
- Test en ligne : Sélectionnez simplement l'environnement matériel de déploiement du modèle ( reste cohérent avec l'environnement de conversion du modèle#🎜🎜 # ), la plateforme effectuera un chargement push adaptatif du modèle en fonction de la configuration de l'environnement, et terminera le déploiement et le déploiement en ligne du modèle en un seul clic.
Pipeline a considérablement amélioré l'efficacité de l'itération du modèle grâce à la construction de fonctionnalités de configuration et en un clic, aidant les étudiants en algorithme et en ingénierie à se concentrer davantage sur leur travail. Bon travail. La figure suivante montre les avantages globaux obtenus dans la pratique du GPU par rapport à l'inférence pure du CPU :
L'extraction de fonctionnalités est la pré-étape du calcul du modèle. Qu'il s'agisse d'un modèle LR traditionnel ou d'un modèle d'apprentissage en profondeur de plus en plus populaire, les informations doivent être obtenues via l'extraction de fonctionnalités. Dans le blog précédent
La construction et la pratique de la plateforme de fonctionnalités Meituan Takeout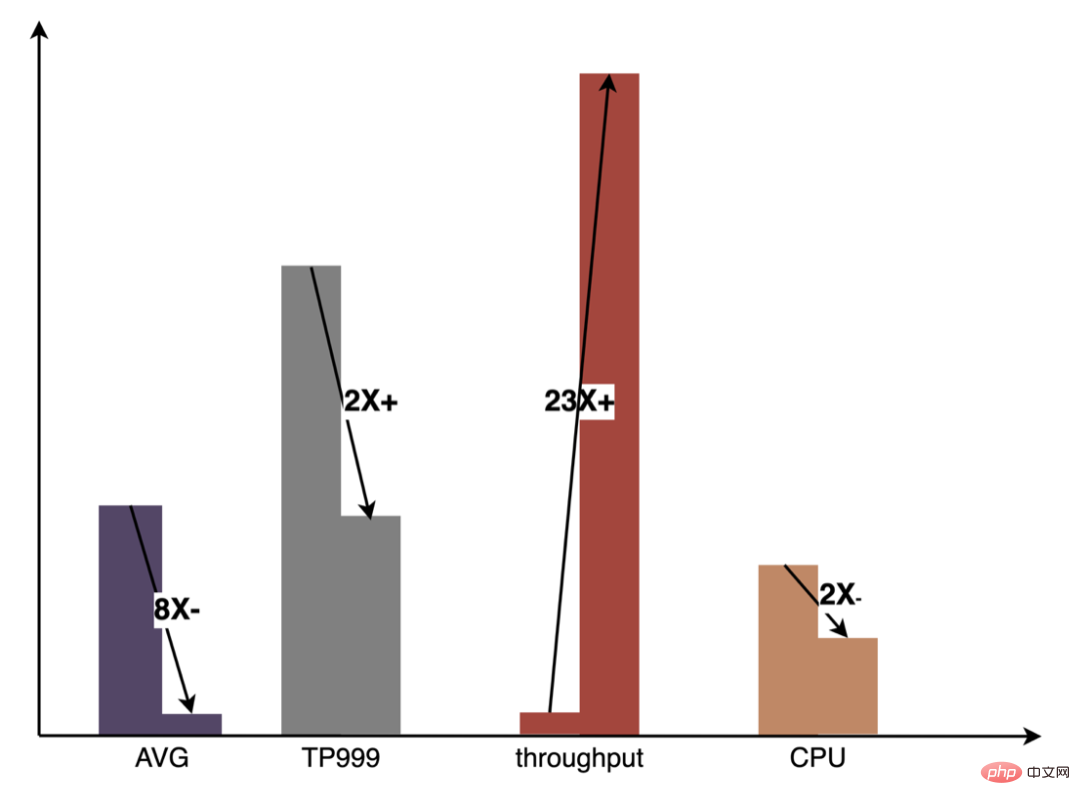
, nous avons décrit nos fonctionnalités automatiques basées sur un modèle. Décrivez MFDL, configurez le processus de calcul des caractéristiques et essayez de garantir la cohérence des échantillons lors de l'estimation en ligne et de la formation hors ligne. Avec l'itération rapide des activités, le nombre de fonctionnalités des modèles continue d'augmenter. Les modèles particulièrement volumineux introduisent un grand nombre de fonctionnalités discrètes, ce qui entraîne un doublement de la quantité de calcul. À cette fin, nous avons apporté quelques optimisations à la couche d’extraction de fonctionnalités et obtenu des gains significatifs en termes de débit et de consommation de temps.
4.1 Optimisation complète de CodeGen par processus DSL est une description de la logique de traitement des fonctionnalités. Dans les premières implémentations de calcul de fonctionnalités, le DSL configuré pour chaque modèle était interprété et exécuté. L'avantage de l'interprétation de l'exécution est qu'elle est simple à mettre en œuvre et qu'une bonne implémentation peut être obtenue grâce à une bonne conception, comme le modèle d'itérateur couramment utilisé ; être évité au niveau de la mise en œuvre par souci de polyvalence, etc. En fait, pour une version fixe de la configuration du modèle, toutes ses règles de conversion des fonctionnalités du modèle sont fixes et ne changeront pas avec les demandes. Dans les cas extrêmes, sur la base de ces informations connues, chaque fonctionnalité du modèle peut être codée en dur pour atteindre les performances ultimes. De toute évidence, les configurations des fonctionnalités des modèles changent constamment et il est impossible de coder manuellement chaque modèle. D'où l'idée de CodeGen, qui génère automatiquement un ensemble de codes propriétaires pour chaque configuration lors de la compilation. CodeGen n'est pas une technologie ou un framework spécifique, mais une idée qui complète le processus de conversion d'un langage de description abstrait vers un langage d'exécution spécifique. En fait, dans l'industrie, il est courant d'utiliser CodeGen pour accélérer les calculs dans des scénarios gourmands en calcul. Par exemple, Apache Spark utilise CodeGen pour optimiser les performances d'exécution de SparkSql. Depuis ExpressionCodeGen dans 1.x pour accélérer les opérations d'expression jusqu'à WholeStageCodeGen introduit dans 2.x pour une accélération complète, des gains de performances très évidents ont été obtenus. Dans le domaine de l'apprentissage automatique, certains cadres d'accélération de modèles TF, tels que TensorFlow XLA et TVM, sont également basés sur l'idée de CodeGen. Les nœuds Tensor sont compilés dans un IR de couche intermédiaire unifié, et l'optimisation de la planification est effectuée sur la base de l'IR combiné avec. l'environnement local pour obtenir une accélération du calcul du modèle d'exécution.
En nous appuyant sur WholeStageCodeGen de Spark, notre objectif est de compiler l'intégralité du calcul de caractéristiques DSL dans une méthode exécutable, réduisant ainsi la perte de performances lors de l'exécution du code. L'ensemble du processus de compilation peut être divisé en : front-end (FrontEnd), optimiseur (Optimizer) et back-end (BackEnd ). Le front-end est principalement responsable de l'analyse du DSL cible et de la conversion du code source en AST ou IR ; l'optimiseur optimise le code intermédiaire obtenu en fonction du front-end pour rendre le code plus efficace ; code en code natif pour la plate-forme respective. L'implémentation spécifique est la suivante :
- Front-end : Chaque modèle correspond à un graphe DAG de nœud, et chaque le calcul des caractéristiques est analysé un par un DSL, génère un AST et ajoute des nœuds AST au graphique.
- Optimizer : Optimisez les nœuds DAG, tels que l'extraction d'opérateurs publics, le repli constant, etc.
- Backend : Compilez le graphique optimisé en bytecode.
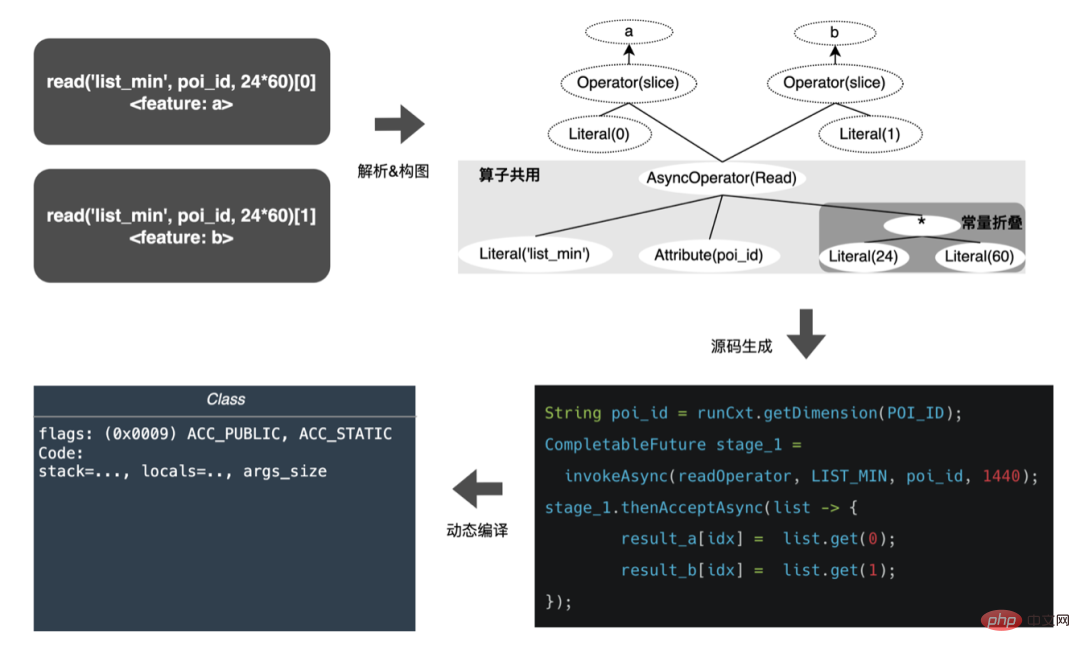
Après optimisation, la traduction du graphe DAG du nœud, c'est-à-dire le back-end l'implémentation du code, a été décidée pour des performances ultimes. L'une des difficultés réside également dans la raison pour laquelle les moteurs d'expression open source existants ne peuvent pas être utilisés directement : le calcul de caractéristiques DSL n'est pas une expression purement informatique. Il peut décrire le processus d'acquisition et de traitement des fonctionnalités grâce à une combinaison d'opérateurs de lecture et d'opérateurs de conversion : Le processus d'obtention de fonctionnalités du système de stockage est une tâche de type IO. Par exemple, interrogez le système KV distant.
- Opérateur de conversion : La conversion des fonctionnalités une fois les fonctionnalités obtenues localement est une tâche gourmande en calcul. Par exemple, hachez les valeurs des fonctionnalités.
- Donc, dans la mise en œuvre réelle, il est nécessaire de considérer la planification des différents types de tâches, d'améliorer autant que possible l'utilisation des ressources de la machine et d'optimiser le le processus global prend beaucoup de temps. Combinant recherche industrielle et pratique propre, les trois mises en œuvre suivantes ont été réalisées :
-
Diviser l'étape en fonction du type de tâche : Divisez l'ensemble du processus en deux étapes : l'acquisition et le calcul, et divisez le étape en interne Traitement parallèle, l'étape suivante est exécutée une fois l'étape précédente terminée. C'est la solution que nous avons utilisée au début. Elle est simple à mettre en œuvre et permet de choisir différentes tailles de partitions en fonction de différents types de tâches. Par exemple, les tâches de type IO peuvent utiliser des partitions plus grandes. Mais les inconvénients sont également évidents, ce qui entraînera la superposition de longues traînes de différentes étapes. La longue traîne de chaque étape affectera la durée de l'ensemble du processus.
-
Divide Stage based on pipeline : Afin de réduire la superposition de longue traîne des différentes étapes, vous pouvez d'abord diviser les données en Sharding, ajouter des rappels pour chaque fragment de lecture de fonctionnalité, rappeler la tâche de calcul une fois la tâche IO terminée, rendant l'ensemble du processus aussi fluide qu'une chaîne de montage. La planification des fragments peut permettre aux fragments qui sont prêts plus tôt dans l'étape précédente d'entrer dans l'étape suivante à l'avance, réduisant ainsi le temps d'attente et réduisant ainsi la longue traîne du temps global de demande. Mais l'inconvénient est que la taille unifiée des partitions ne peut pas améliorer pleinement l'utilisation de chaque étape. Des partitions plus petites entraîneront une plus grande consommation de réseau pour les tâches d'E/S, et des partitions plus grandes augmenteront la consommation de temps des tâches informatiques.
- Basée sur l'approche SEDA (Staged Event-Driven Architecture) : L'approche événementielle par étapes utilise des files d'attente pour isoler l'acquisition et le calcul des étapes étape, chaque étape se voit attribuer un pool de threads indépendant et une file d'attente de traitement par lots, consommant N (batching factor) éléments à chaque fois. Cela permet à chaque étape de sélectionner indépendamment la taille de la partition, et le modèle basé sur les événements peut également assurer la fluidité du processus. C’est ce que nous explorons actuellement.
CodeGen n'est pas parfait. Le code généré dynamiquement réduit la lisibilité du code et augmente les coûts de débogage. Cependant, avec CodeGen comme couche d'adaptation, il s'ouvre également. espace pour une optimisation plus approfondie. Basé sur CodeGen et l'implémentation asynchrone non bloquante, de bons avantages ont été obtenus en ligne. D'une part, cela réduit le calcul fastidieux des fonctionnalités, d'autre part, cela réduit également considérablement la charge du processeur et améliore le débit du système. À l'avenir, nous continuerons à tirer parti de CodeGen et à procéder à des optimisations ciblées dans le processus de compilation back-end, comme l'exploration de la combinaison d'instructions matérielles (telles que SIMD) ou du calcul hétérogène ( tels que GPU# 🎜🎜#) pour une optimisation plus approfondie.
4.2 Optimisation de la transmission
Le service de prédiction en ligne a une architecture à deux couches dans son ensemble. La couche d'extraction de fonctionnalités est responsable du routage du modèle. et calcul des caractéristiques Calcul du modèle La couche est responsable des calculs du modèle. Le processus du système d'origine consiste à regrouper les résultats du calcul des caractéristiques dans une matrice de M (Predicted Batch Size) × N (Sample width), puis à le sérialiser. transmis à la couche informatique. La raison en est, d'une part, des raisons historiques.Le format d'entrée de nombreux premiers modèles simples non-DNN est une matrice, d'autre part, une fois la couche de routage épissée, la couche informatique peut être utilisée directement sans conversion. , le format du tableau est relativement compact et permet de gagner du temps sur la transmission réseau.  Cependant, avec le développement itératif des modèles, les modèles DNN sont progressivement devenus courants, et les inconvénients de la transmission matricielle sont également très évidents :
Cependant, avec le développement itératif des modèles, les modèles DNN sont progressivement devenus courants, et les inconvénients de la transmission matricielle sont également très évidents :
-
Mauvaise évolutivité : Le format des données est unifié et n'est pas compatible avec les valeurs de caractéristiques de type non numérique.
- Perte de performances de transmission : en fonction du format matriciel, les fonctionnalités doivent être alignées. Par exemple, la dimension Requête/Utilisateur doit être copiée et alignée sur chaque élément, ce qui augmente la quantité de données de transmission réseau requise pour. la couche informatique.
Afin de résoudre les problèmes ci-dessus, le processus optimisé ajoute une couche de conversion au-dessus de la couche de transmission pour convertir les caractéristiques du modèle calculé dans le format requis en fonction de la configuration de MDFL, comme Tensor, matrice ou utilisation hors ligne. Format CSV, etc.  La plupart des modèles en ligne actuels sont des modèles TF Afin de réduire davantage la consommation de transmission, la plateforme a conçu le format Tensor Sequence pour stocker chaque matrice Tensor : parmi eux, r_flag est utilisé pour marquer s'il s'agit d'une fonctionnalité de type élément, et la longueur représente la caractéristique de l'élément. Longueur, la valeur est M (Nombre d'éléments) × NF (Longueur de la caractéristique), les données sont utilisées pour stocker les valeurs réelles des caractéristiques de l'élément, les valeurs des caractéristiques M sont stockées à plat. , et pour les fonctionnalités de type requête, elles sont renseignées directement. Basée sur le format compact Tensor Sequence, la structure des données est plus compacte et la quantité de données transmises sur le réseau est réduite. Le format de transmission optimisé a également obtenu de bons résultats en ligne. La taille des requêtes de la couche de routage appelant la couche informatique a été réduite de plus de 50 % et le temps de transmission du réseau a été considérablement réduit.
La plupart des modèles en ligne actuels sont des modèles TF Afin de réduire davantage la consommation de transmission, la plateforme a conçu le format Tensor Sequence pour stocker chaque matrice Tensor : parmi eux, r_flag est utilisé pour marquer s'il s'agit d'une fonctionnalité de type élément, et la longueur représente la caractéristique de l'élément. Longueur, la valeur est M (Nombre d'éléments) × NF (Longueur de la caractéristique), les données sont utilisées pour stocker les valeurs réelles des caractéristiques de l'élément, les valeurs des caractéristiques M sont stockées à plat. , et pour les fonctionnalités de type requête, elles sont renseignées directement. Basée sur le format compact Tensor Sequence, la structure des données est plus compacte et la quantité de données transmises sur le réseau est réduite. Le format de transmission optimisé a également obtenu de bons résultats en ligne. La taille des requêtes de la couche de routage appelant la couche informatique a été réduite de plus de 50 % et le temps de transmission du réseau a été considérablement réduit.
4.3 Codage de fonctionnalités d'identification de haute dimension
Les fonctionnalités discrètes et les fonctionnalités de séquence peuvent être unifiées en fonctionnalités clairsemées. Au cours de l'étape de traitement des fonctionnalités, les fonctionnalités d'origine seront hachées et transformées en fonctionnalités de type ID. Face à des fonctionnalités comportant des centaines de milliards de dimensions, le processus de concaténation et de hachage de chaînes ne peut pas répondre aux exigences en termes d'espace d'expression et de performances. Sur la base de recherches industrielles, nous avons conçu et appliqué un format d'encodage de fonctionnalités basé sur le codage Slot :
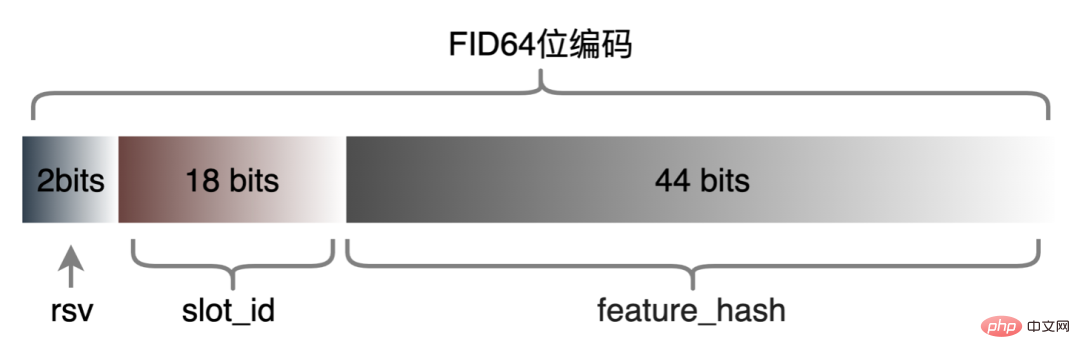
Parmi eux, feature_hash est la valeur de la valeur de fonctionnalité d'origine après hachage. Les entités entières peuvent être remplies directement. Les entités non entières ou les entités croisées sont d'abord hachées, puis remplies si le nombre dépasse 44 bits, il sera tronqué. Après le lancement du système de codage Slot, il a non seulement amélioré les performances du calcul des caractéristiques en ligne, mais a également considérablement amélioré l'effet du modèle.
5 Construction d'échantillons
5.1 Échantillon de streaming
Afin de résoudre le problème de cohérence en ligne et hors ligne, l'industrie met généralement en ligne les données de fonctionnalités utilisées pour la notation en temps réel, appelées instantanés de fonctionnalités ; d'utiliser de simples échantillons de construction d'étiquettes hors ligne via l'épissage et le remplissage de fonctionnalités, car cette méthode entraînera une plus grande incohérence des données. L'architecture originale est illustrée dans la figure ci-dessous :

À mesure que l'échelle des fonctionnalités devient plus grande et que les scénarios d'itération deviennent de plus en plus complexes, le problème majeur est que le service d'extraction de fonctionnalités en ligne est soumis à une forte pression, suivi de les coûts de collecte de l'ensemble du flux de données sont trop élevés. Ce schéma de collecte d'échantillons présente les problèmes suivants :
- Long délai de préparation : Dans le cadre des contraintes de ressources actuelles, il faut presque T+2 pour que les exemples de données soient prêts lors de l'exécution de données aussi volumineuses, ce qui affecte l'itération du modèle d'algorithme.
- Consommation élevée de ressources : la méthode de collecte d'échantillons existante consiste à calculer les caractéristiques de toutes les requêtes, puis à les combiner avec l'exposition et les clics. En raison du calcul des caractéristiques et de la liste déroulante des données des éléments non exposés, la quantité de données stockées. est grand, consommant beaucoup de ressources.
5.1.1 Solutions courantes
Afin de résoudre les problèmes ci-dessus, il existe deux solutions courantes dans l'industrie : ①Traitement du flux en temps réel Flink ; ②Traitement secondaire du cache KV. Le processus spécifique est illustré dans la figure ci-dessous :
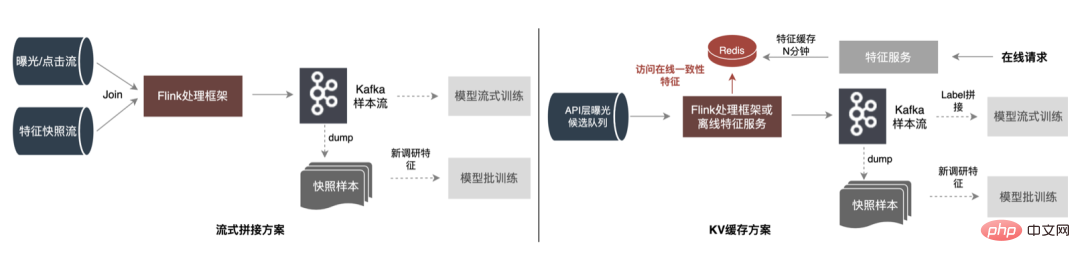
- Solution d'épissage de streaming : capacités de traitement de flux à faible latence à l'aide de frameworks de traitement de streaming (Flink, Storm, etc.#🎜 🎜#), lisez directement le flux d'exposition/clic en temps réel et associez-le aux données du flux d'instantané de fonctionnalité en mémoire (Join) pour le traitement, générez d'abord des échantillons de formation en streaming, puis transférez-les ; pour modéliser des échantillons de formation hors ligne. Les échantillons en streaming et les échantillons hors ligne sont stockés respectivement dans différents moteurs de stockage, prenant en charge différents types de méthodes de formation de modèles. Problèmes avec cette solution : la quantité de données dans le lien de flux de données est toujours très importante, occupant beaucoup de ressources de flux de messages (comme Kafka) la consommation de ressources Flink est trop importante, si les données le volume est de plusieurs centaines de G par seconde, l'exécution de la fenêtre Join nécessite 30 minutes × 60 × 100G de ressources mémoire.
- Solution de cache KV : Écrivez tous les instantanés de fonctionnalités de l'extraction de fonctionnalités dans le stockage KV (tel que Redis ) pendant N minutes, le système d'entreprise transmet les éléments de la file d'attente des candidats au système informatique en temps réel (Flink ou application grand public ) via le mécanisme de message. être plus grand que les éléments précédemment demandés. Le montant est beaucoup plus petit. De cette manière, ces fonctionnalités d'élément sont supprimées du cache d'instantanés de fonctionnalités et les données sont sorties via le flux de messages pour prendre en charge la formation en streaming. Cette méthode s'appuie sur le stockage externe Quelle que soit l'augmentation des fonctionnalités ou du trafic, les ressources Flink sont contrôlables et le fonctionnement est plus stable. Mais le problème en suspens nécessite toujours une mémoire plus grande pour mettre en cache de grandes quantités de données.
5.1.2 Amélioration et optimisation
Du point de vue de la réduction des calculs invalides, toutes les données demandées ne seront pas exposées. La stratégie entraîne une demande plus forte en données exposées, de sorte que le transfert du traitement au niveau journalier vers le traitement en flux peut considérablement améliorer le délai de préparation des données. Deuxièmement, à partir du contenu des données, les caractéristiques incluent les données modifiées au niveau de la demande et les données modifiées au niveau du jour. Le lien peut séparer de manière flexible le traitement des deux, ce qui peut considérablement améliorer l'utilisation des ressources. : #🎜 🎜#
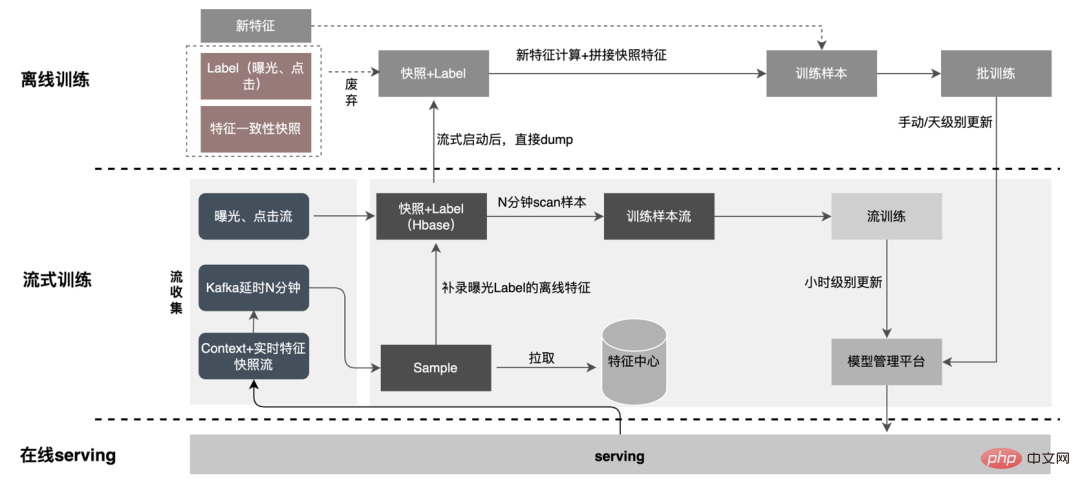
1. Répartition des données : Résoudre le problème du grand volume de transmission de données. (Feature Snapshot Streaming Gros problème ), les étiquettes prédites et les données en temps réel correspondent une par une, et les données hors ligne sont accessibles deux fois pendant la redistribution, ce qui peut réduire considérablement la taille du lien flux de données.
Il n'y a que des fonctionnalités de contexte + temps réel dans l'exemple de flux, ce qui augmente la stabilité du flux de données lu en même temps, puisque. seules les fonctionnalités en temps réel doivent être stockées, le stockage sur le disque dur de Kafka diminue de plus de 10 fois.
2. Consommation différée Méthode Join : Résolvez le problème de l'utilisation importante de la mémoire.
Le flux d'exposition est utilisé comme flux principal et écrit dans HBase en même temps, afin de permettre à d'autres flux d'être exposés sur la jointure. dans HBase plus tard, la RowKey est écrite sur Redis ; les flux suivants sont écrits dans HBase via RowKey, et l'épissage de l'exposition, des clics et des fonctionnalités est effectué à l'aide d'un stockage externe pour garantir que le système peut fonctionner de manière stable en fonction de la quantité de les données augmentent.
3. Échantillon d'entrée supplémentaire de fonctionnalité : Grâce à Label's Join, le nombre de demandes de fonctionnalité pour une entrée supplémentaire ici est pas à 20 % en ligne ; l'échantillon est retardé et fusionné avec l'exposition pour filtrer la demande de service de modèle d'exposition (Contexte+fonctionnalité en temps réel), puis toutes les fonctionnalités hors ligne sont enregistrées dans formez des exemples de données complets. Écrivez dans HBase. 5.2 Stockage structuré
Avec l'itération métier, le nombre de fonctionnalités dans l'instantané des fonctionnalités devient de plus en plus grand, ce qui rend l'instantané global des fonctionnalités dans un seul scénario d'entreprise, il atteint des dizaines de niveaux de To par jour ; du point de vue du stockage, les instantanés de fonctionnalités d'une seule entreprise sur plusieurs jours sont déjà au niveau du PB et sont sur le point d'atteindre le seuil de stockage de l'algorithme publicitaire. , Grande pression de stockage; d'un point de vue informatique Il semble que l'utilisation du processus de calcul d'origine, en raison des limitations de ressources du moteur de calcul (Spark) (#🎜🎜 # utilise la lecture aléatoire, les données de la phase d'écriture aléatoire seront déposées sur le disque si la mémoire allouée est insuffisante, des placements multiples et un tri externe se produiront ), ce qui nécessite une mémoire de la même taille que ses propres données et. plus de CU informatiques pour terminer efficacement le calcul, prend beaucoup de mémoire . Le processus de base du processus de construction de l'échantillon est illustré dans la figure ci-dessous : 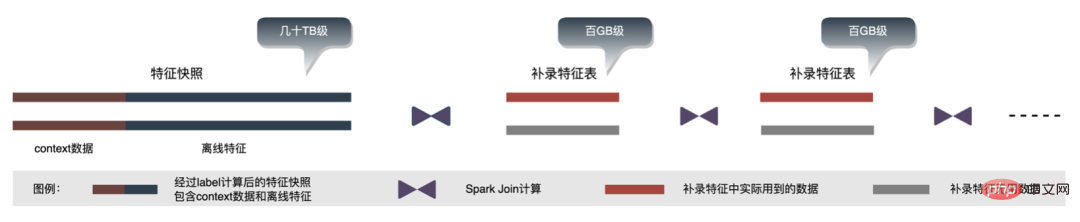
Lors du réenregistrement des fonctionnalités, les problèmes suivants surviennent :
-
Redondance des données : Le tableau hors ligne pour les fonctionnalités de réenregistrement contient généralement une quantité complète de données, avec le nombre d'éléments au niveau des milliards, utilisé pour la construction de l'échantillon. Le nombre d'entrées est approximativement égal au nombre de DAU ce jour-là, qui se chiffre en dizaines de millions, il y a donc des données redondantes dans les données de la table de caractéristiques enregistrées en plus lors de la participation au calcul.
- Ordre de jointure : Le processus de calcul des caractéristiques supplémentaires est l'achèvement des caractéristiques dimensionnelles. Il existe plusieurs calculs de jointure, donc la performance du calcul de jointure a beaucoup à voir avec l'ordre des tables de jointure, comme le montre la figure ci-dessus. , si la table de gauche est une grande table avec des dizaines de niveaux de To, donc le processus de calcul aléatoire ultérieur générera une grande quantité d'E/S réseau et d'E/S disque.
Afin de résoudre le problème de l'efficacité lente de la construction d'échantillons, nous commencerons par la gestion de la structure des données à court terme. Le processus détaillé est le suivant :
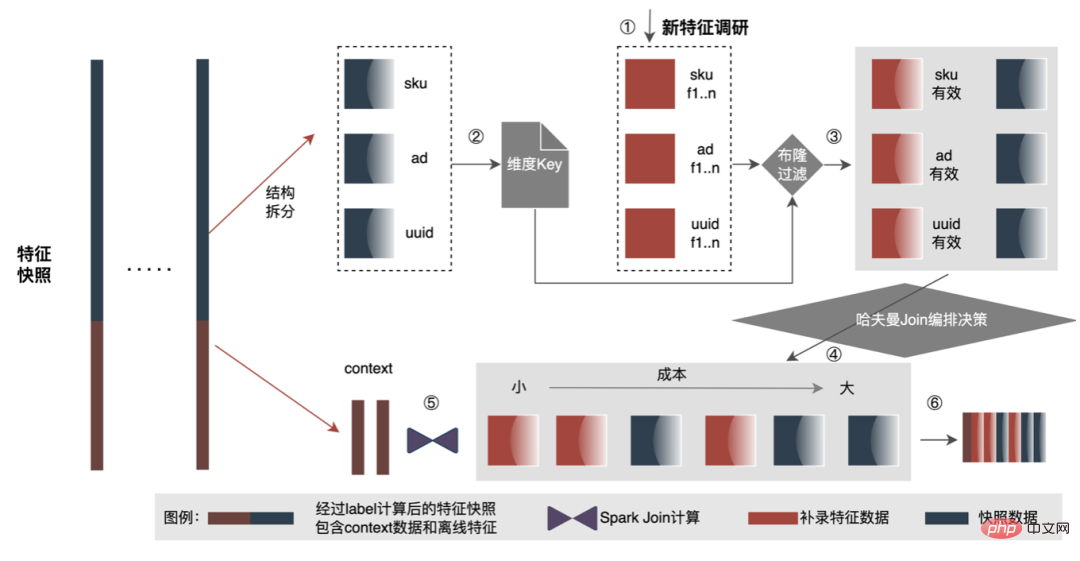
-
Structuré. scission. Les données sont divisées en données contextuelles et en stockage structuré de données dimensionnelles au lieu d'un stockage mixte. Il résout le problème du transport d'une grande quantité de données redondantes lors du processus d'épissage de nouvelles fonctionnalités des échantillons Label et, après un stockage structuré, une excellente compression du stockage est obtenue pour les fonctionnalités hors ligne ;
-
Pré-filtre de filtration haute efficacité. Le filtrage des données est avancé avant la jointure, réduisant ainsi la quantité de données impliquées dans le calcul des caractéristiques, ce qui peut réduire efficacement les E/S du réseau. Pendant le processus d'épissage, la table Hive pour l'enregistrement supplémentaire des caractéristiques est généralement une table complète, et le nombre d'éléments de données correspond généralement à l'activité mensuelle. Cependant, le nombre d'éléments de données utilisés dans le processus d'épissage réel correspond approximativement à l'activité quotidienne. il y a donc une grande quantité de redondance de données, les données invalides apporteront des E/S et des calculs supplémentaires. La méthode d'optimisation consiste à précalculer la clé de dimension et à générer le filtre Bloom correspondant. Utilisez le filtre Bloom pour filtrer lors de la lecture des données, ce qui peut réduire considérablement la transmission de données redondante et les calculs redondants pendant le processus d'enregistrement supplémentaire.
- Join haute performance. Utilisez des stratégies efficaces pour organiser la séquence de jointure afin d'améliorer l'efficacité et l'utilisation des ressources du processus de réenregistrement des fonctionnalités. Au cours du processus d'épissage des fonctionnalités, des opérations de jointure seront effectuées sur plusieurs tables, et l'ordre des jointures affectera également grandement les performances d'épissage. Comme le montre la figure ci-dessus, si la quantité de données dans la table de gauche épissée est importante, les performances globales seront médiocres. Vous pouvez utiliser l'idée de l'algorithme de Huffman pour considérer chaque table comme un nœud et la quantité de données correspondante comme son poids. La quantité de calcul de jointure entre les tables peut être simplement analogue à l'addition des poids de deux. nœuds. Par conséquent, ce problème peut être résumé dans la construction d’un arbre de Huffman, et le processus de construction de l’arbre de Huffman est l’ordre de jointure optimal.
Les ressources de stockage des données hors ligne sont économisées de plus de 80 % et l'efficacité de la construction des échantillons est augmentée de plus de 200 %. Actuellement, l'ensemble des données d'échantillon est également mis en œuvre sur la base du lac de données pour améliorer encore l'efficacité des données.
6 Préparation des données
La plateforme a accumulé une grande quantité de contenu précieux tel que des fonctionnalités, des échantillons et des modèles. On espère qu'en réutilisant ces actifs de données, elle pourra aider les stratèges à mieux mener des itérations commerciales et à obtenir de meilleurs revenus commerciaux. . L'optimisation des fonctionnalités représente 40 % de toutes les méthodes utilisées par le personnel chargé des algorithmes pour améliorer les effets du modèle. Cependant, la méthode traditionnelle d'exploration de fonctionnalités présente des problèmes tels qu'une longue consommation de temps, une faible efficacité d'exploration et une extraction de fonctionnalités répétée. la dimension des fonctionnalités. S'il existe un processus expérimental automatisé pour vérifier l'effet de n'importe quelle fonctionnalité et recommander les indicateurs d'effet final aux utilisateurs, cela aidera sans aucun doute les stratèges à gagner beaucoup de temps. Une fois la construction complète du lien terminée, il vous suffit de saisir différents ensembles de fonctionnalités candidates pour générer les indicateurs d'effet correspondants. À cette fin, la plateforme a construit un mécanisme intelligent pour « l'addition », la « soustraction », la « multiplication » et la « division » de caractéristiques et d'échantillons.
6.1 Faire un "ajout"
La recommandation de fonctionnalités est basée sur la méthode de test de modèle, réutiliser les fonctionnalités dans des modèles existants d'autres secteurs d'activité, construire de nouveaux échantillons et modèles ; comparer les effets hors ligne du nouveau modèle et du modèle de base, obtenir Les avantages des nouvelles fonctionnalités sont automatiquement transmis aux dirigeants d'entreprise concernés. Le processus de recommandation de fonctionnalités spécifiques est illustré dans la figure ci-dessous :
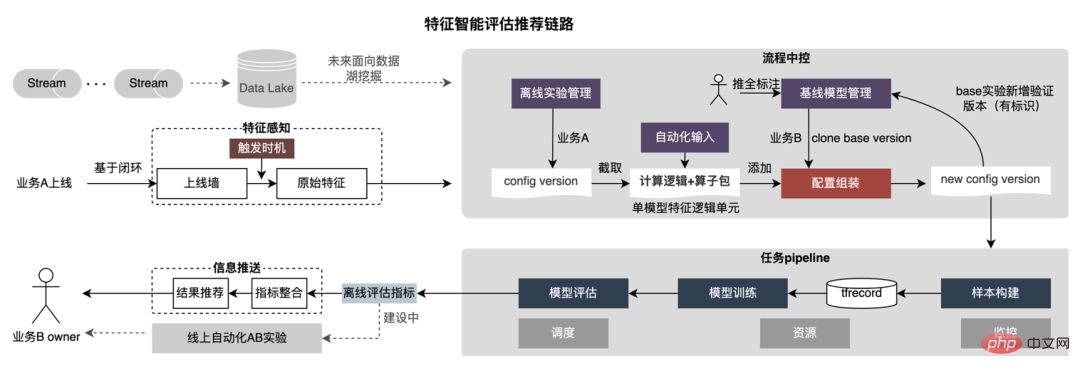
-
Conscience des fonctionnalités : la recommandation de fonctionnalités est déclenchée via le mur en ligne ou la méthode d'inventaire inter-entreprises. Ces fonctionnalités ont été vérifiées dans une certaine mesure, ce qui peut garantir le taux de réussite de la recommandation de fonctionnalités.
-
Production d'échantillons : les fonctionnalités sont extraites du fichier de configuration pendant la production d'échantillons, et le processus ajoute automatiquement de nouvelles fonctionnalités au fichier de configuration, puis produit de nouveaux exemples de données. Après avoir obtenu de nouvelles fonctionnalités, analysez les fonctionnalités d'origine, les dimensions et les opérateurs UDF dont dépendent ces fonctionnalités, et intégrez la nouvelle configuration de fonctionnalités et les données d'origine dépendantes dans le fichier de configuration d'origine du modèle de base pour construire un nouveau fichier de configuration de fonctionnalités. Créez automatiquement de nouveaux échantillons. Pendant la construction de l'échantillon, les fonctionnalités pertinentes sont extraites de l'entrepôt de fonctionnalités via les noms de fonctionnalités, et l'UDF configuré est appelé pour le calcul des fonctionnalités. La période de construction de l'échantillon est configurable.
-
Formation du modèle : transformez automatiquement la structure du modèle et la configuration du format d'échantillon, puis effectuez la formation du modèle, utilisez TensorFlow comme cadre de formation du modèle, utilisez le format tfrecord comme exemple d'entrée et classez les nouvelles fonctionnalités en fonction des classes numériques. et classes ID. Placez-les en deux groupes, A et B respectivement. Les fonctionnalités de type ID sont recherchées dans le tableau, puis ajoutées aux fonctionnalités existantes. De nouveaux échantillons peuvent être reçus pour la formation du modèle sans modifier la structure du modèle.
-
Configurez automatiquement les nouveaux paramètres de formation du modèle : y compris la date de formation, le chemin de l'échantillon, les super paramètres du modèle, etc., divisez l'ensemble de formation et l'ensemble de test, et entraînez automatiquement le nouveau modèle.
- Évaluation du modèle : appelez l'interface d'évaluation pour obtenir des indicateurs hors ligne, comparez les résultats d'évaluation des nouveaux et des anciens modèles et réservez les résultats d'évaluation d'une seule fonctionnalité. Après avoir divisé certaines fonctionnalités, la contribution d'une seule fonctionnalité est donnée. Les résultats de l'évaluation sont uniformément envoyés aux utilisateurs.
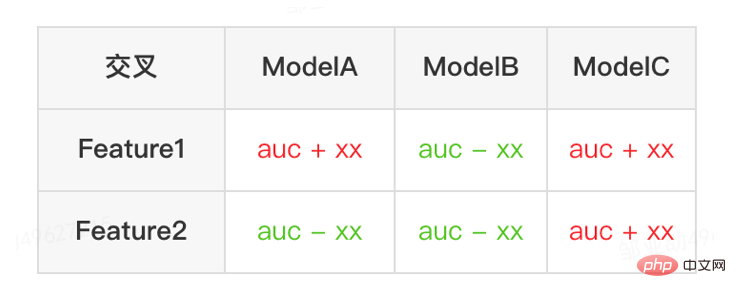
6.2 Faire une "soustraction"
Après que la recommandation de fonctionnalités ait été implémentée dans la publicité et obtenu certains avantages, nous avons effectué une nouvelle exploration au niveau de l'autonomisation des fonctionnalités. Avec l'optimisation continue du modèle, la vitesse d'expansion des fonctionnalités est très rapide et la consommation de ressources des services de modèle augmente fortement. Il est impératif d'éliminer les fonctionnalités redondantes et de « mincir » le modèle. Par conséquent, la plate-forme a créé un ensemble d’outils de sélection de fonctionnalités de bout en bout.

-
Score des fonctionnalités : Tous les scores des fonctionnalités du modèle sont donnés via divers algorithmes d'évaluation tels que WOE (Weight Of Evidence, Weight of Evidence) pour noter la qualité de fonctionnalités supérieures Plus élevée, la précision de l'évaluation est élevée.
-
Vérification des effets : Après avoir entraîné le modèle, triez par score et éliminez les fonctionnalités par lots. Plus précisément, en utilisant la méthode de fragmentation des caractéristiques, les résultats de l'évaluation du modèle original et du modèle fragmenté sont comparés lorsque la différence est supérieure au seuil, l'évaluation se termine et les caractéristiques qui peuvent être éliminées sont indiquées.
- Solution de bout en bout : Une fois que l'utilisateur a configuré les paramètres expérimentaux et les seuils d'indicateur, les fonctionnalités supprimables et les résultats d'évaluation hors ligne du modèle après la suppression des fonctionnalités peuvent être fournis sans intervention humaine.
Au final, après 40% des fonctionnalités du modèle interne hors ligne, la baisse des indicateurs d'activité est toujours maîtrisée dans un seuil raisonnable.
6.3 Faire de la "multiplication"
Afin d'obtenir de meilleurs effets de modèle, de nouvelles explorations ont été lancées dans le domaine de la publicité, notamment les grands modèles, le temps réel, les bibliothèques de fonctionnalités, etc. Il y a un objectif clé derrière ces explorations : le besoin de données plus nombreuses et de meilleure qualité pour rendre les modèles plus intelligents et plus efficaces. À partir de la situation actuelle de la publicité, la construction d'un exemple de base de données (Data Bank) est proposée pour intégrer davantage de types et une plus grande échelle de données externes et l'appliquer aux entreprises existantes. Comme le montre la figure ci-dessous :
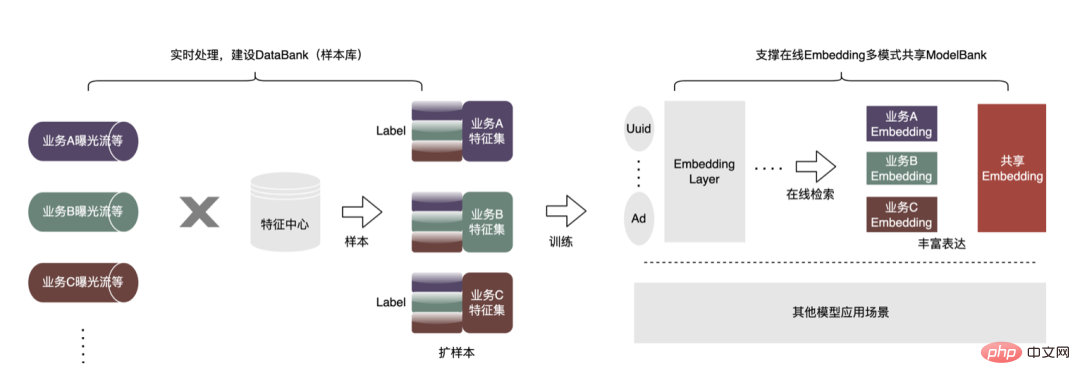
Nous avons mis en place une plateforme universelle de partage d'échantillons, sur laquelle d'autres secteurs d'activité peuvent être empruntés pour générer des échantillons incrémentiels. Il construit également une architecture de partage d'intégration commune pour réaliser l'intégration commerciale à grande et à petite échelle. Voici un exemple de réutilisation d'échantillons non publicitaires dans le secteur publicitaire. La méthode spécifique est la suivante :
.
-
Extension d'échantillons : basée sur le cadre de traitement de streaming Flink, une bibliothèque d'échantillons hautement évolutive DataBank est créée. L'entreprise A peut facilement réutiliser l'exposition, les clics et d'autres données d'étiquette de l'entreprise B et de l'entreprise C pour des expériences. En particulier pour les petites entreprises, une grande quantité de données de valeur a été élargie. Par rapport à l'enregistrement supplémentaire hors ligne, cette approche aura une plus grande cohérence. La plate-forme de fonctionnalités offre des garanties de cohérence en ligne et hors ligne.
- Partager : Une fois l'échantillon prêt, un scénario d'application très typique est l'apprentissage par transfert. De plus, un chemin de données pour le partage d'intégration est également construit ( ne s'appuie pas fortement sur le processus « d'expansion des échantillons » ). Tous les secteurs d'activité peuvent être formés sur la base de grandes intégrations. Chaque partie commerciale peut également mettre à jour cette intégration et établir une intégration. Intégration du mécanisme de version en ligne pour fournir Utilisé par plusieurs secteurs d'activité.
Par exemple, en réutilisant des échantillons non publicitaires dans une entreprise de publicité, le nombre d'échantillons a été augmenté plusieurs fois. En combinaison avec l'algorithme d'apprentissage par transfert, l'AUC hors ligne a augmenté de quatre millièmes et le CPM a augmenté. augmenté de 1% après sa mise en ligne. En outre, nous construisons également une bibliothèque d'exemples de thèmes publicitaires pour gérer uniformément les exemples de données générés par chaque entreprise (métadonnées unifiées), exposer la classification unifiée des exemples de thèmes aux utilisateurs, s'inscrire, rechercher et réutiliser rapidement, ainsi qu'un stockage unifié pour le couche inférieure, économisez les ressources de stockage et de calcul, réduisez la jointure des données et améliorez la rapidité.
6.4 Faire une "division"
La "soustraction" de fonctionnalités peut éliminer certaines fonctionnalités qui n'ont aucun effet positif, mais grâce à l'observation, on constate qu'il existe encore de nombreuses fonctionnalités de peu de valeur dans le modèle. Par conséquent, nous pouvons aller plus loin en considérant globalement à la fois la valeur et le coût. Sous les contraintes de coût de l’ensemble du lien, nous pouvons éliminer les fonctionnalités avec des entrées et des sorties relativement faibles et réduire la consommation de ressources. Ce processus de résolution sous contraintes de coût est défini comme « division ». Le processus global est illustré dans la figure ci-dessous.
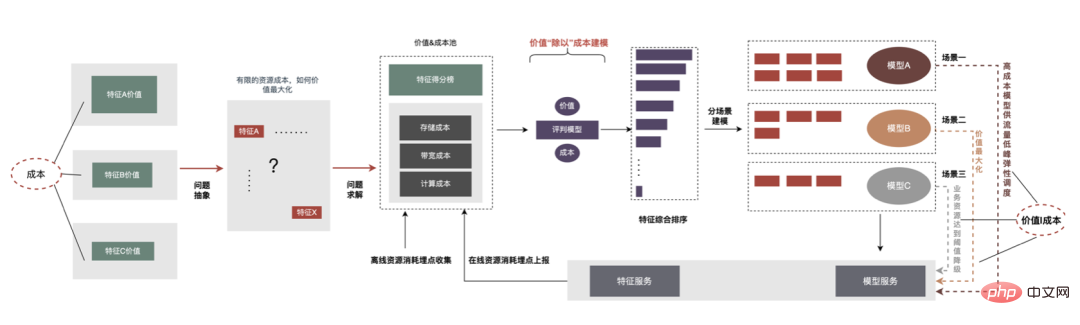
Dans la dimension hors ligne, nous avons établi un système d'évaluation de la valeur des fonctionnalités pour donner le coût et la valeur des fonctionnalités. Lors du raisonnement en ligne, nous pouvons utiliser les informations sur la valeur des fonctionnalités pour effectuer des opérations telles que la dégradation du trafic et l'élasticité des fonctionnalités. calculs et effectuer une "division" "Les étapes clés sont les suivantes :
-
Abstraction du problème : Si nous pouvons obtenir le score de valeur de chaque fonctionnalité, nous pouvons également obtenir le coût de la fonctionnalité ( stockage, communication, calcul et traitement), Ensuite, le problème se transforme en comment maximiser la valeur des fonctionnalités dans le cadre de la structure de modèle connue et des coûts de ressources fixes.
-
Évaluation de la valeur sous contraintes de coûts : sur la base de l'ensemble des fonctionnalités du modèle, la plateforme effectue d'abord un résumé statistique des coûts et des valeurs, le coût comprend les coûts hors ligne et les coûts en ligne, et sur la base de l'évaluation entraînée ; modèle, les fonctionnalités sont obtenues classement complet.
- Modélisation de scénarios : vous pouvez sélectionner différents ensembles de fonctionnalités pour la modélisation en fonction de différentes conditions de ressources. Avec des ressources limitées, choisissez le modèle ayant la plus grande valeur pour travailler en ligne. En outre, il peut être modélisé pour un ensemble de fonctionnalités relativement important et activé lors de faibles pics de trafic afin d'améliorer l'utilisation des ressources et d'apporter de plus grands avantages à l'entreprise. Un autre scénario d'application est la dégradation du trafic. Le service d'inférence surveille la consommation des ressources en ligne. Une fois que le calcul des ressources atteint le goulot d'étranglement, il passe au modèle de dégradation.
7 Résumé et perspectives
Ce qui précède est notre pratique anti-«augmentation» dans les projets d'apprentissage en profondeur à grande échelle pour aider à réduire les coûts des entreprises et à améliorer l'efficacité. À l'avenir, nous continuerons à explorer et à pratiquer dans les aspects suivants :
-
GPUisation full-link : au niveau de l'inférence, grâce à la commutation GPU, tout en prenant en charge des itérations commerciales plus complexes, le coût global est également considérablement réduit. Plus tard, la construction d'échantillons et les services de fonctionnalités seront basés sur le GPU. , et promouvoir en collaboration la mise à niveau des niveaux de formation hors ligne.
-
Sample Data Lake : créez un entrepôt d'échantillons plus grand grâce à l'évolution de schéma, à la mise à jour des correctifs et à d'autres fonctionnalités du lac de données pour exposer des données à faible coût et de grande valeur au côté commercial.
-
Pipeline : Dans le processus d'itération du cycle de vie complet de l'algorithme, de nombreux aspects du débogage et des informations de lien ne sont pas suffisamment « connectés », et les perspectives des indicateurs hors ligne, en ligne et d'effet sont relativement fragmentées. Basé sur le lien complet La normalisation et l'observabilité constituent la tendance générale et constituent la base d'un déploiement intelligent et élastique des liens ultérieurs. Les MLOps et le cloud natif, qui sont désormais populaires dans l'industrie, ont de nombreuses idées de référence.
- Correspondance intelligente des données et des modèles : comme mentionné ci-dessus, en partant du principe que la structure du modèle est fixe, des fonctionnalités sont automatiquement ajoutées et soustraites au modèle. De même, au niveau du modèle, certaines nouvelles fonctionnalités sont automatiquement intégrées. dans le but de corriger certaines entrées de fonctionnalités de la structure du modèle. Et à l'avenir, nous compléterons également automatiquement la mise en correspondance des données et des modèles en fonction du domaine d'activité et via les fonctionnalités et le système de modèles de la plateforme.
8
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



 Comment définir la zone de texte en lecture seule
Comment définir la zone de texte en lecture seule
 Comment ouvrir les autorisations de portée
Comment ouvrir les autorisations de portée
 Comment prendre des captures d'écran sur les téléphones mobiles Huawei
Comment prendre des captures d'écran sur les téléphones mobiles Huawei
 Quel est le système Honor ?
Quel est le système Honor ?
 Comment implémenter une liste chaînée en go
Comment implémenter une liste chaînée en go
 Comment accéder au site Web 404
Comment accéder au site Web 404
 Comment changer de ville sur Douyin
Comment changer de ville sur Douyin
 Comment supprimer vos propres œuvres sur TikTok
Comment supprimer vos propres œuvres sur TikTok








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



