


Les programmes d'attention autorégressifs avec Transformer comme noyau ont toujours été difficiles à surmonter la difficulté d'échelle. À cette fin, DeepMind/Google a récemment lancé un nouveau projet visant à proposer un bon moyen d'aider efficacement ces programmes à mincir.
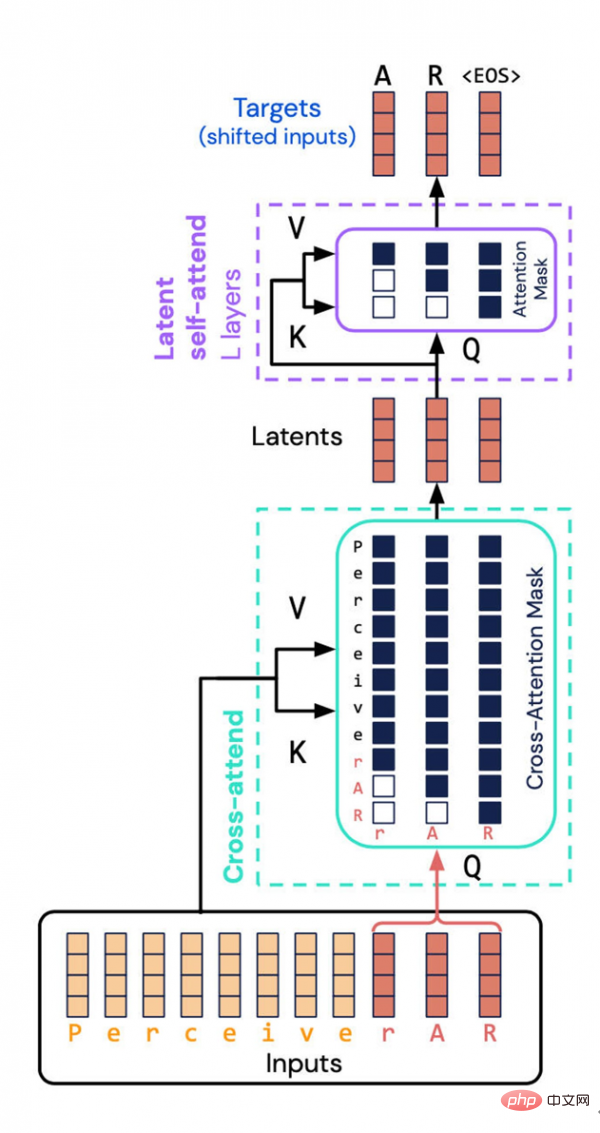
L'architecture Perceiver AR créée par DeepMind et Google Brain évite une tâche gourmande en ressources : calculer les propriétés combinées des entrées et des sorties dans l'espace potentiel. Au lieu de cela, ils ont introduit un « masquage causal » dans l’espace latent, obtenant ainsi l’ordre autorégressif d’un Transformer typique.
L'une des tendances de développement les plus impressionnantes dans le domaine de l'intelligence artificielle/deep learning est que la taille des modèles devient de plus en plus grande. Les experts dans le domaine affirment que, puisque l’échelle est souvent directement liée à la performance, cette vague d’expansion des volumes est susceptible de se poursuivre.
Cependant, l'échelle des projets devient de plus en plus grande et les ressources consommées augmentent naturellement, ce qui a amené le deep learning à soulever de nouvelles problématiques au niveau social et éthique. Ce dilemme a attiré l’attention de revues scientifiques grand public telles que Nature.
Pour cette raison, nous devrons peut-être revenir au vieux mot « efficacité » : les programmes d'IA peuvent-ils encore améliorer leur efficacité ?
Des scientifiques des départements DeepMind et Google Brain ont récemment modifié le réseau neuronal Perceiver qu'ils ont lancé l'année dernière, dans l'espoir d'améliorer son efficacité dans l'utilisation des ressources informatiques.
Le nouveau programme s'appelle Perceiver AR. L'AR ici provient de « autorégressif », qui est également une autre direction de développement de plus en plus de programmes d'apprentissage profond aujourd'hui. L'autorégression est une technique qui permet à la machine d'utiliser la sortie comme nouvelle entrée du programme. Il s'agit d'une opération récursive, formant ainsi une carte d'attention dans laquelle plusieurs éléments sont liés les uns aux autres.
Le populaire réseau neuronal Transformer lancé par Google en 2017 possède également cette caractéristique autorégressive. En fait, le dernier GPT-3 et la première version de Perceiver ont poursuivi la voie technique autorégressive.
Avant Perceiver AR, Perceiver IO, lancé en mars de cette année, était la deuxième version de Perceiver. En remontant plus loin, c'était la première version de Perceiver sortie à la même époque l'année dernière.
L'innovation originale de Perceiver est d'utiliser Transformer et d'effectuer des ajustements afin qu'il puisse absorber de manière flexible diverses entrées, y compris le texte, le son et les images, rompant ainsi la dépendance à l'égard de types spécifiques d'entrée. Cela permet aux chercheurs de développer des réseaux de neurones utilisant plusieurs types d’entrées.
En tant que membre de la tendance du moment, Perceiver, comme d'autres projets modèles, a également commencé à utiliser le mécanisme d'attention autorégressive pour mélanger différents modes de saisie et différents domaines de tâches. Ces cas d’utilisation incluent également Pathways de Google, Gato de DeepMind et data2vec de Meta.
En mars de cette année, Andrew Jaegle, le créateur de la première version de Perceiver, et son équipe de collègues ont sorti la version "IO". La nouvelle version améliore les types de sortie pris en charge par Perceiver, permettant un grand nombre de sorties contenant une variété de structures, notamment le langage textuel, les champs de flux optiques, les séquences audiovisuelles et même les ensembles de symboles non ordonnés, etc. Perceiver IO peut même générer des instructions d'utilisation dans le jeu "StarCraft 2".
Dans ce dernier article, Perceiver AR a pu implémenter une modélisation autorégressive générale pour des contextes longs. Mais au cours de leurs recherches, Jaegle et son équipe ont également été confrontés à de nouveaux défis : comment faire évoluer le modèle face à diverses tâches d'entrée et de sortie multimodales.
Le problème est que la qualité autorégressive de Transformer, et de tout programme qui crée de la même manière des cartes d'attention entrée-sortie, nécessite des tailles de distribution massives pouvant atteindre des centaines de milliers d'éléments.
C'est la faiblesse fatale du mécanisme d'attention. Plus précisément, tout doit être pris en compte afin de construire une distribution de probabilité de la carte d'attention.
Comme Jaegle et son équipe l'ont mentionné dans l'article, à mesure que le nombre de choses qui doivent être comparées les unes aux autres augmente dans l'entrée, la consommation de ressources informatiques du modèle deviendra de plus en plus exagérée : #🎜🎜 ##🎜 🎜#Cette longue structure de contexte entre en conflit avec les caractéristiques informatiques de Transformer. Les transformateurs effectuent à plusieurs reprises des opérations d'auto-attention sur l'entrée, ce qui entraîne une croissance des exigences de calcul à la fois quadratique avec la longueur d'entrée et linéaire avec la profondeur du modèle. Plus il y a de données d'entrée, plus il y a de balises d'entrée correspondant au contenu des données observées, les modèles dans les données d'entrée deviennent plus subtils et complexes, et des couches plus profondes doivent être utilisées pour modéliser les modèles générés. En raison de la puissance de calcul limitée, les utilisateurs de Transformer sont obligés soit de tronquer l'entrée du modèle (empêchant l'observation de modèles plus éloignés), soit de limiter la profondeur du modèle (le privant ainsi de la capacité expressive de modéliser des modèles complexes).
En fait, la première version de Perceiver a également essayé d'améliorer l'efficacité des Transformers : non pas en effectuant une attention directement, mais en effectuant une attention sur la représentation potentielle de l'entrée. De cette manière, les besoins en puissance de calcul liés au traitement de grands réseaux d'entrée peuvent être « (découplés) des besoins en puissance de calcul correspondant aux grands réseaux profonds ».
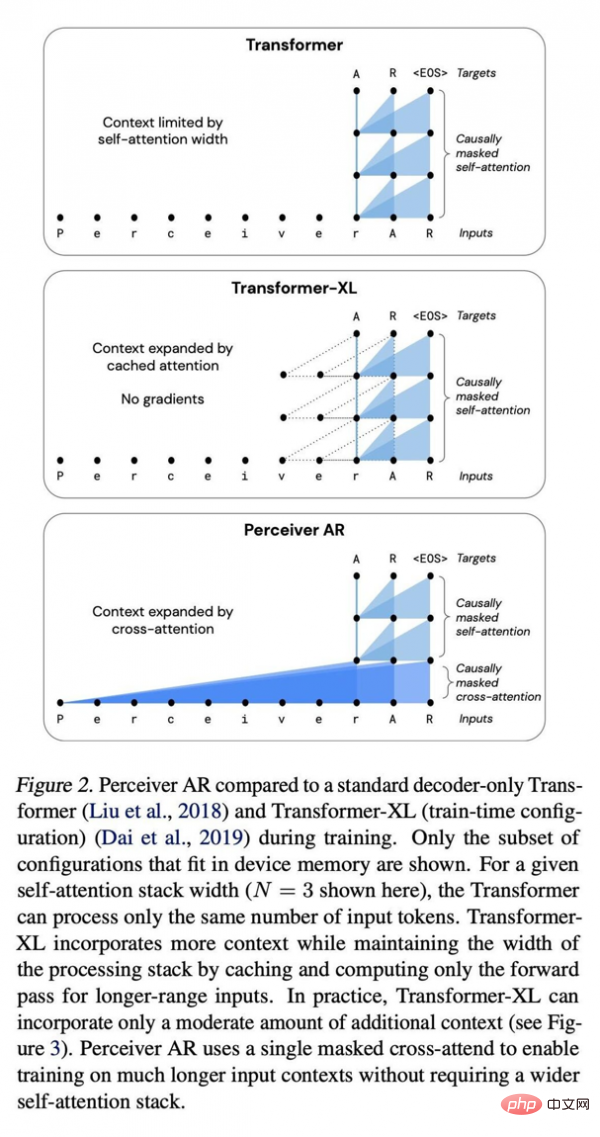
Perceiver AR avec réseau profond Transformer standard et comparaison Transformer XL améliorée.
Dans la partie latente, la représentation d'entrée est compressée, devenant ainsi un moteur d'attention plus efficace. De cette façon, « avec les réseaux profonds, la plupart des calculs se font réellement sur la pile d’auto-attention », plutôt que de devoir opérer sur d’innombrables entrées.
Mais le défi existe toujours, car la représentation sous-jacente n'a pas le concept d'ordre, donc Perceiver ne peut pas générer de sortie comme Transformer. Et l'ordre est crucial dans l'autorégression, chaque sortie doit être le produit de l'entrée qui la précède, et non le produit qui la suit.
Mais puisque chaque modèle latent prête attention à toutes les entrées quel que soit leur emplacement, l'exigence selon laquelle chaque sortie de modèle doit reposer uniquement sur la génération autorégressive de ses entrées précédentes est dite, Perceiver ne sera pas directement applicable.
Quant à Perceiver AR, l'équipe de recherche est allée plus loin et a inséré la séquence dans Perceiver pour permettre une régression automatique.
La clé ici est d'effectuer ce que l'on appelle un "masquage causal" sur l'entrée et la représentation latente. Du côté de l'entrée, le masquage causal effectue une « attention croisée », tandis que du côté de la représentation sous-jacente, il oblige le programme à ne prêter attention qu'à ce qui précède un symbole donné. Cette méthode restaure la directivité du transformateur et peut encore réduire considérablement le montant total du calcul.
Le résultat est que Perceiver AR peut obtenir des résultats de modélisation comparables à Transformer sur la base de plus d'entrées, mais les performances sont grandement améliorées.
Ils écrivent : « Perceiver AR peut parfaitement identifier et apprendre de longs modèles de contexte espacés d'au moins 100 000 jetons dans la tâche de copie synthétique. En comparaison, Transformer a une limite stricte de 2048 jetons, d'autant plus. » balises, plus le contexte est long et plus le résultat du programme sera complexe.
Comparé aux architectures Transformer et Transformer-XL qui utilisent largement des décodeurs purs, Perceiver AR est plus efficace et peut modifier de manière flexible les ressources informatiques réelles utilisées lors des tests en fonction du budget cible.
Le document écrit que dans les mêmes conditions d'attention, le temps d'horloge murale pour calculer le Perceiver AR est nettement plus court et peut absorber plus de contexte (c'est-à-dire plus de symboles d'entrée) avec le même budget de puissance de calcul : # 🎜🎜#
La longueur du contexte de Transformer est limitée à 2048 jetons, ce qui équivaut à ne prendre en charge que 6 couches - car les modèles plus grands et les contextes plus longs nécessitent une énorme quantité de mémoire. En utilisant la même configuration à 6 couches, nous pouvons étendre la longueur totale du contexte de la mémoire Transformer-XL à 8 192 jetons. Perceiver AR peut étendre la longueur du contexte jusqu'à 65 000 marqueurs, et avec une optimisation plus poussée, elle devrait même dépasser 100 000. Tout cela rend l'informatique plus flexible : « Nous sommes en mesure de mieux contrôler la quantité de calculs qu'un modèle donné génère lors des tests, et nous permettons d'atteindre un équilibre stable entre vitesse et performances. ." Jaegle et ses collègues écrivent également que cette approche fonctionne pour tout type d'entrée et ne se limite pas aux symboles verbaux. Par exemple, les pixels dans les images peuvent être pris en charge : Le même processus fonctionne pour toute entrée pouvant être triée, à condition que des techniques de masquage causal soient appliquées. Par exemple, les canaux RVB d'une image peuvent être triés dans l'ordre de balayage raster en décodant les canaux de couleur R, V et B de chaque pixel de la séquence, dans l'ordre ou dans le désordre. Les auteurs ont trouvé un grand potentiel dans Perceiver et ont écrit dans l'article : "Perceiver AR est un candidat idéal pour les modèles autorégressifs à usage général à contexte long Mais en quête." d’une plus grande efficacité de calcul, un autre facteur d’instabilité supplémentaire doit être pris en compte. Les auteurs soulignent que la communauté des chercheurs a également récemment tenté de réduire les exigences informatiques de l'attention autorégressive grâce à la « parcimonie » (c'est-à-dire le processus de limitation de l'importance accordée à certains éléments d'entrée).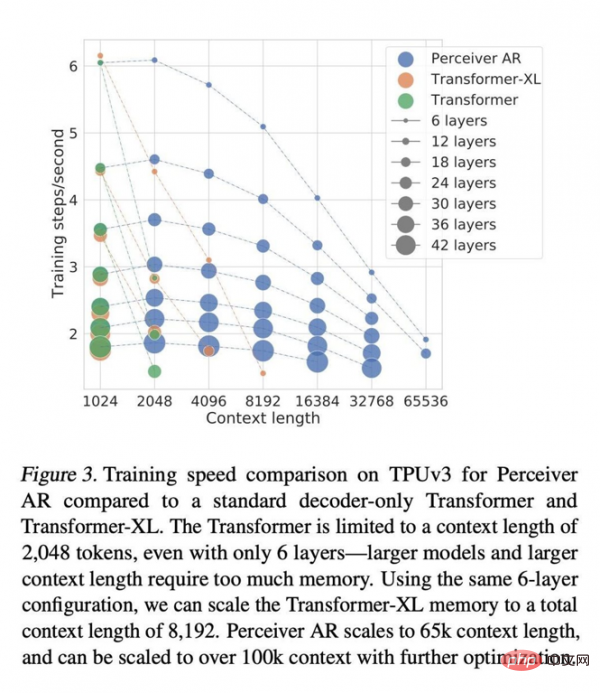
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



