


Ce programme utilise une bibliothèque d'automatisation Python ----pywinauto Parce que la version officielle n'a pas été mise à jour depuis longtemps, la version la plus élevée de Python ne peut être qu'autour de Python 3.7. .J'utilise Celui-ci est Python 3.7.1. Je l'ai utilisé pour simuler la saisie de mots, copier les exemples de phrases, effacer le presse-papiers, puis répéter cette opération. par souci de simplicité, je suis passé manuellement à la page d'exemple de phrases, vous n'avez donc pas besoin d'utiliser un programme pour passer à la page d'exemple de phrase
requirements.txt
pyperclip==1.8.2 pywin32==304 pywinauto==0.6.8
code
import os
import random
import time
import re
from typing import Dict, List
from pywinauto.application import Application
from pywinauto import mouse
from pywinauto import keyboard
import pyperclip
import json
# 程序处理中的各种路径
dir_path = r"C:/Users/Dick/Desktop/work/DragonEnglish/tools"
input_path = os.path.join(dir_path, r"input.txt")
output_path = os.path.join(dir_path, r"output.json")
error_path = os.path.join(dir_path, r"error.txt")
# 顺序错误的单词
error_words = []
# 有道词典的进程id
processId = 13840
def line_process(content: str) -> str:
"""
去除所有空行, 再去除前面四行无关内容
"""
lines = content.split("\r\n")
# 因为例句开头是 数字. 开头的, 所以先以这个为特点来进行过滤掉多复制的开头
count = 0
for i in range(len(lines)):
if re.match(r"\d+\.", lines[i]):
count = i
break
lines = lines[count:]
filter_lines = []
for line in lines:
if line.strip() != "": # 过滤空行
if not line.startswith("youdao") and not \
(line.startswith("《") and line.endswith("》")): # 过滤来源
filter_lines.append(line)
if len(filter_lines) % 3 != 0:
raise Exception("抓取数据错误")
content = "\n".join(filter_lines) + "\n" # 补上一个 \n, 不然正则会漏掉一个结果
return content
def to_list(line: str) -> List[Dict[str, str]]:
"""
直接生成列表字典对象
[{
"no": 1,
"original": "",
"translate"
}]
"""
sentences = []
# 正则表达式
REGEXP = r'(?P<no>\d+?)\.\n(?P<original>.+?)\n(?P<translate>.+?)\n'
# 编译
pattern = re.compile(REGEXP)
# 匹配
rs = pattern.finditer(line)
# 组装结果
for r in rs:
print(r.groupdict())
sentences.append(r.groupdict())
return sentences
if __name__ == "__main__":
# 连接网易有道词典
app = Application(backend="uia").connect(process=processId)
# 获取需要的窗口
win = app.window(class_name="RICHEDIT50W")
# 输入词汇列表
input_words = []
# 输出词汇对象列表
output_words = []
# 打开输入文件,初始化输入词汇列表
with open(input_path, "r", encoding="utf-8") as input_file:
input_words = input_file.read().split("\n")
for word in input_words:
print("正在抓取单词: %s" % word)
# 清空剪切板,这步很重要,防止重复复制
pyperclip.copy("")
# 将输入数据复制到剪切板
pyperclip.copy(word)
# 定位到输入框(采用坐标定位,定位到大致位置即可)
mouse.click(coords=(2400, 80))
# 模拟按键操作:全选 删除 粘贴 回车(触发查询)
keyboard.send_keys("^a{DELETE}^v{ENTER}")
# 清空剪切板,这步很重要,防止重复复制
pyperclip.copy("")
# 鼠标左键点击,这个操作只是为了把鼠标移动到这里
mouse.click(button="left", coords=(2200, 330))
# 模拟键盘 CTRL+A CTRL+C,直接全选所有的例句(这里会多选一部分内容,待会再处理)
keyboard.send_keys("^a^c")
# 暂停一会儿,不做操作的太快
time.sleep(random.random() * 2 + 1)
# pywinauto 复制的内容是在系统的剪切板里面的,所以需要其它库读取
content = pyperclip.paste()
# 对内容进行简单的预处理后,加入output_words
try:
lines = line_process(content)
except BaseException as exp:
print(exp)
# 如果抓取出现问题,说明被网易抓了现行,直接退出即可。
break
sentences = to_list(lines)
if not sentences:
print("获取例句为空, 可能是数据格式错误.")
break
output_words.append({
"word": word,
"example": sentences,
})
# 模拟暂停一个较长的随机时间,没有必要追求速度,平稳运行即可。
time.sleep(random.random() * 3 + 3)
# 清空剪切板,这步很重要,防止重复复制
pyperclip.copy("")
# 抓取完毕一个文件的内容后,然后一次性写入即可。
# 之前的写法是一个单词写入一次,会造成太多的IO次数,浪费性能!
with open(output_path, "a+", encoding="utf-8") as output_file:
output_file.write(json.dumps(
output_words, ensure_ascii=False, indent=4))
# 错误单词记录
with open(error_path, "w", encoding="utf-8") as err_file:
err_file.writelines("\n".join(error_words))Démonstration Si vous souhaitez démarrer ce code, c'est assez compliqué. Je suis là. Il suffit de lister les étapes requises, en espérant aider les étudiants intéressés.
input.txt, voici le fichier que j'ai testé
centralisation sophistiquéephénomène
J'ai obtenu le processus pid via le gestionnaire de tâches, vous. peut également y accéder par d'autres méthodes. Ou le plus simple est d'utiliser Inspect et Spy++, je suis paresseux ici et directement Voici comment éviter les ennuis
internationalisation
radioactif
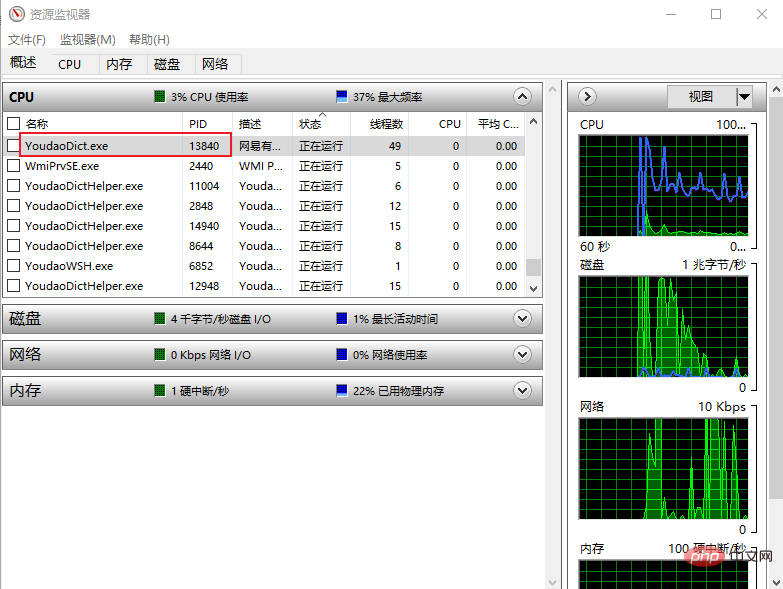 Les coordonnées de la zone de saisie du mot, les coordonnées de la copie et. coller l'emplacement. La première coordonnée consiste à positionner la zone de saisie, puis le programme y copiera le mot et appuiera sur la touche Entrée, puis le contenu est interrogé. Ensuite, déplacez la souris vers la deuxième coordonnée, ici c'est juste. déplacé vers l'espace vide ci-dessous, puis une opération de sélection de tout CTRL+A sera effectuée de cette façon, tout le contenu d'un mot est obtenu.
Les coordonnées de la zone de saisie du mot, les coordonnées de la copie et. coller l'emplacement. La première coordonnée consiste à positionner la zone de saisie, puis le programme y copiera le mot et appuiera sur la touche Entrée, puis le contenu est interrogé. Ensuite, déplacez la souris vers la deuxième coordonnée, ici c'est juste. déplacé vers l'espace vide ci-dessous, puis une opération de sélection de tout CTRL+A sera effectuée de cette façon, tout le contenu d'un mot est obtenu.
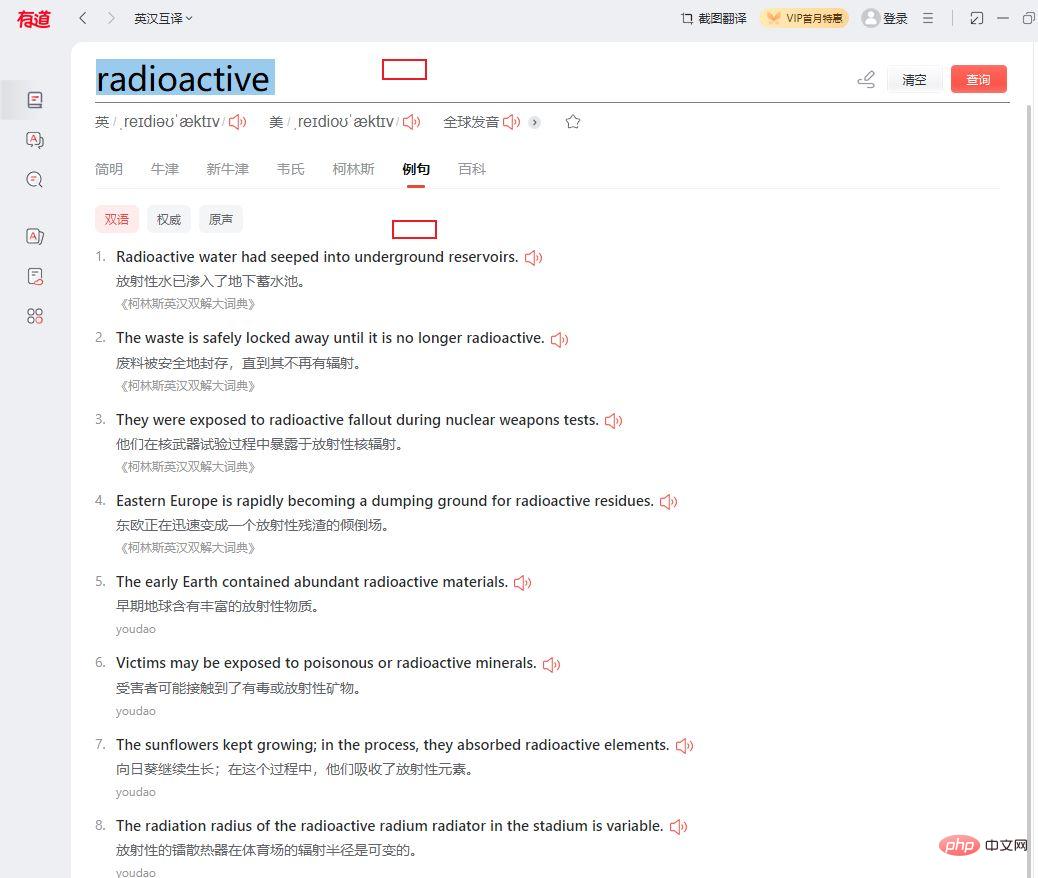 Ajustez Youdao à cette position, interrogez d'abord un mot, sélectionnez. un exemple de phrase, puis gardez cette interface inchangée.
Ajustez Youdao à cette position, interrogez d'abord un mot, sélectionnez. un exemple de phrase, puis gardez cette interface inchangée.
 La dernière étape est l'exécution du programme, et le GIF enregistré a été accéléré. En fait, lors de l'exécution, un délai est délibérément ajouté pour éviter une découverte prématurée.
La dernière étape est l'exécution du programme, et le GIF enregistré a été accéléré. En fait, lors de l'exécution, un délai est délibérément ajouté pour éviter une découverte prématurée.
 Sortie de la console
Sortie de la console
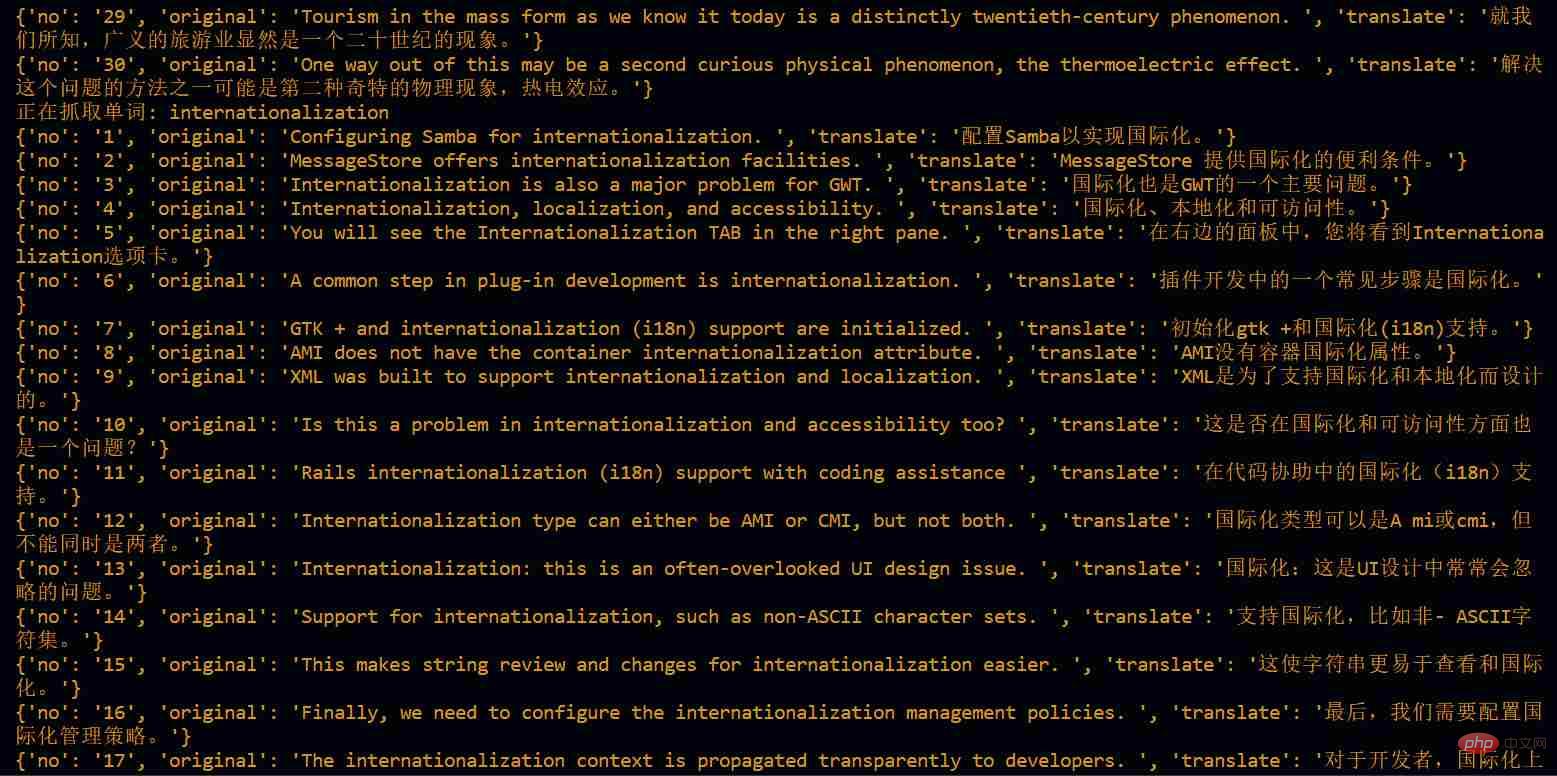 fichier output.json
fichier output.json
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



