Optimiser les performances d'épissage du plan de transport de transfert de Ctrip
WBOY
Libérer: 2023-04-25 18:31:09
avant
1336 Les gens l'ont consulté
À propos de l'auteur
En bref, responsable du développement back-end de Ctrip, axé sur l'architecture technique, l'optimisation des performances, la planification des transports et d'autres domaines.
1. Introduction générale
En raison des limites de la planification des transports et des ressources de transport, il se peut qu'il n'y ait pas de transport direct entre les deux lieux demandés par l'utilisateur, ou pendant les grandes vacances, le transport directa été épuisé. Cependant, les utilisateurs peuvent toujours atteindre leur destination via des transferts bidirectionnels ou multidirectionnels tels que des trains, des avions, des voitures, des navires, etc. De plus, le transport par transfert est parfois plus avantageux en termes de prix et de consommation de temps. Par exemple, de Shanghai à Yuncheng, la correspondance en train peut être plus rapide et moins chère qu'un train direct.
Figure 1 Liste de transport de transfert en train Ctrip
Lors de la fourniture de solutions de transport de transfert, un lien très important est de fusionner deux ou plusieurs voyages de trains, avions, voitures, navires, etc. en un transfert réalisable plan. La première difficulté du raccordement du trafic de transit est que l'espace de raccordement est énorme. En considérant simplement Shanghai comme une ville de transit, près de 100 millions de combinaisons peuvent être générées. Une autre difficulté réside dans l'exigence de performances en temps réel, car les données de la chaîne de production changent en même temps. à tout moment et doit être constamment mis à jour. Interrogez les données sur les trains, les avions, les voitures et les navires. L'épissage du trafic de transit nécessite beaucoup de ressources informatiques et de surcharge d'E/S, il est donc particulièrement important d'optimiser ses performances.
Cet article utilisera des exemples pour présenter les principes, les méthodes d'analyse et d'optimisation suivies dans le processus d'optimisation des performances d'épissage du trafic de transfert, dans le but de fournir aux lecteurs une référence et une inspiration précieuses.
2. Principes d'optimisation
L'optimisation des performances nécessite d'équilibrer et de faire des compromis entre diverses ressources et contraintes dans le but de répondre aux besoins de l'entreprise. Plus précisément, les trois principes suivants sont principalement suivis lors du processus d'optimisation de l'épissage du trafic de transfert :
2.1 L'optimisation des performances est un moyen plutôt qu'une fin
Bien que cet article porte sur l'optimisation des performances, il doit encore être souligné au début : Ne le faites pas pour l'optimisation Et optimiser. Il existe de nombreuses façons de répondre aux besoins de l'entreprise, et l'optimisation des performances n'est que l'une d'entre elles. Parfois, le problème est très complexe et il existe de nombreuses restrictions. Sans affecter de manière significative l’expérience utilisateur, réduire l’impact sur les utilisateurs en assouplissant les restrictions ou en adoptant d’autres processus est également un bon moyen de résoudre les problèmes de performances. Dans le développement de logiciels, il existe de nombreux exemples de réductions de coûts significatives obtenues en sacrifiant une petite quantité de performances. Par exemple, l'algorithme HyperLogLog utilisé pour les statistiques de cardinalité (suppression des duplications) dans Redis ne nécessite que 12 Ko d'espace pour compter 264 données avec une erreur standard de 0,81 %.
Retour au problème lui-même, en raison de la nécessité d'interroger fréquemment les données de la chaîne de production et d'effectuer des opérations d'épissage massives, si chaque utilisateur doit renvoyer immédiatement le plan de transfert le plus récent lors de l'interrogation, le coût sera très élevé. Pour réduire les coûts, il faut trouver un équilibre entre temps de réponse et fraîcheur des données. Après un examen attentif, nous choisissons d'accepter les incohérences de données au niveau minute. Pour certains itinéraires et dates impopulaires, il se peut qu'il n'y ait pas de bon plan de transfert lors de la première requête. Dans ce cas, il suffit de guider l'utilisateur pour actualiser la page.
2.2 Une optimisation incorrecte est la racine de tous les maux
Donald Knuth mentionné dans "Programmation structurée avec instructions Go To" : "Les programmeurs perdent beaucoup de temps à réfléchir et à s'inquiéter des performances des chemins non critiques, et essaient L'optimisation de cette partie des performances aura un impact négatif très sérieux sur le débogage et la maintenance du code global, donc dans 97% des cas, il faudra oublier les petits points d'optimisation." En bref, avant que le véritable problème de performances ne soit découvert, une optimisation excessive et ostentatoire au niveau du code non seulement n’améliorera pas les performances, mais pourrait également conduire à davantage d’erreurs. Cependant, l'auteur a également souligné : « Pour les 3 % critiques restants, nous ne devons pas manquer l'occasion d'optimiser ». Par conséquent, vous devez toujours prêter attention aux problèmes de performances, ne pas prendre de décisions qui affecteront les performances et effectuer les optimisations correctes si nécessaire.
2.3 Analyser quantitativement les performances et clarifier la direction de l'optimisation
Comme mentionné dans la section précédente, avant d'optimiser, nous devons d'abord quantifier les performances et identifier les goulots d'étranglement, afin que l'optimisation peut être mieux Être ciblé. L'analyse quantitative des performances peut utiliser une surveillance chronophage, des outils d'analyse des performances Profiler, des outils de test de référence, etc., en se concentrant sur les domaines qui prennent particulièrement beaucoup de temps ou ont une fréquence d'exécution particulièrement élevée. Comme le dit la loi d'Amdahl : « Le degré d'amélioration des performances du système qui peut être obtenu en utilisant une méthode d'exécution plus rapide pour un certain composant du système dépend de la fréquence à laquelle cette méthode d'exécution est utilisée, ou de la proportion du temps d'exécution total. "
De plus, il est également important de noter que l'optimisation des performances est une bataille de longue haleine. À mesure que l'entreprise continue de se développer, l'architecture et le code évoluent constamment. Il est donc encore plus nécessaire de quantifier en permanence les performances, d'analyser en permanence les goulots d'étranglement et d'évaluer les effets d'optimisation.
3. La route vers l'analyse des performances
3.1 Trier le processus métier
Avant l'analyse des performances, nous doit d'abord trier le processus commercial. L'épissage des solutions de transport par transfert comprend principalement les quatre étapes suivantes :
a Le chargement de la feuille d'itinéraire, comme Pékin à Shanghai via le transfert de Nanjing, ne prend en compte que les informations de. l'itinéraire lui-même et les vols spécifiques ne sont pas pertinents ;
b. Vérifiez les données de la chaîne de production des trains, des avions, des voitures et des navires, y compris l'heure de départ et l'heure d'arrivée. , gare de départ, gare d'arrivée, prix et informations sur les billets restants, etc.
c. être trop court pour éviter de ne pas pouvoir terminer le transfert en même temps ; il ne doit pas être trop long pour éviter d'attendre trop longtemps ; Après avoir assemblé une solution réalisable, vous devez encore améliorer les champs commerciaux, tels que le prix total, la consommation de temps totale et les informations de transfert
d ; règles, parmi toutes les solutions de transfert réalisables, certaines solutions susceptibles d'intéresser les utilisateurs sont sélectionnées.
3.2 Performances de l'analyse quantitative
(1) Augmenter la surveillance chronophage# 🎜 🎜#
Le suivi chronophage est le moyen le plus intuitif d'observer la situation chronophage de chaque étape d'un point de vue macro. Il peut non seulement visualiser la valeur et la proportion de temps consommé à chaque étape du processus métier, mais également observer la tendance aux changements chronophages sur une longue période de temps.
Une surveillance chronophage peut utiliser le système de surveillance et d'alarme des indicateurs internes de l'entreprise pour ajouter une gestion fastidieuse au processus principal de connexion des solutions de transport en commun. Ces processus incluent le chargement des cartes d'itinéraire, l'interrogation des données d'équipe et leur épissage, le filtrage et l'enregistrement des plans d'épissage, etc. La situation chronophage de chaque étape est illustrée dans la figure 2. On peut voir que l'épissage (y compris les données de la chaîne de production) prend la plus grande proportion de temps, il est donc devenu un objectif d'optimisation clé à l'avenir.
Figure 2 Surveillance fastidieuse de l'épissage du trafic de transit
# 🎜 🎜#
(2) Analyse des performances du Profiler
Une gestion chronophage peut envahir le code métier et avoir un impact sur les performances, ce n'est donc pas trop approprié, plus adapté à la surveillance des processus principaux. L'outil d'analyse des performances du Profiler correspondant (tel qu'Async-profiler) peut générer une arborescence d'appels plus spécifique et le taux d'utilisation du processeur de chaque fonction, aidant ainsi à analyser et à localiser les chemins critiques et les goulots d'étranglement des performances.
Figure 3 Arbre d'appels d'épissage et ratio CPU
# 🎜 🎜#Comme le montre la figure 3, la solution d'épissage (combineTransferLines) représente 53,80 % et les données de la ligne de production de requêtes (querySegmentCacheable, cache utilisé) représentent 21,45 %. Dans le schéma d'épissage, le calcul du score du schéma (computeTripScore, représentant 48,22 %), la création de l'entité du schéma (buildTripBO, représentant 4,61 %) et la vérification de la faisabilité de l'épissage (checkCombineMatchCondition, représentant 0,91 %) sont les trois liens les plus importants.
Figure 4 Arbre d'appels de notation de solution et ratio CPU
En poursuivant l'analyse du score du plan de calcul (computeTripScore) avec la proportion la plus élevée, nous avons constaté qu'il est principalement lié à la fonction de formatage de chaîne personnalisée (StringUtils.format), y compris les appels directs (utilisés pour afficher les détails du score du plan), et appels indirects via getTripId Call (l'ID utilisé pour générer le schéma). La proportion la plus élevée de StringUtils.format personnalisé est java/lang/String.replace. Le remplacement de chaîne natif de Java 8 est implémenté via des expressions régulières, ce qui est relativement inefficace (ce problème a été amélioré après Java 9).
Avec l'aide de l'outil de référence Benchmark, vous pouvez mesurer le temps d'exécution de votre code avec plus de précision. Dans le tableau 1, nous utilisons JMH (Java Microbenchmark Harness) pour effectuer des tests fastidieux sur trois méthodes de formatage de chaînes et une méthode d'épissage de chaînes. Les résultats des tests montrent que le formatage de chaîne à l'aide de la méthode de remplacement de Java8 offre les pires performances, tandis que l'utilisation de la fonction d'épissage de chaîne d'Apache offre les meilleures performances.
Tableau 1 Comparaison des performances du formatage et de l'épissage des chaînes
implémentation
temps moyen (nous) pour 1000 exécutions
StringUtils .format implémenté à l'aide du remplacement
1988.982
StringUtils de Java8.format implémenté à l'aide du remplacement Apache
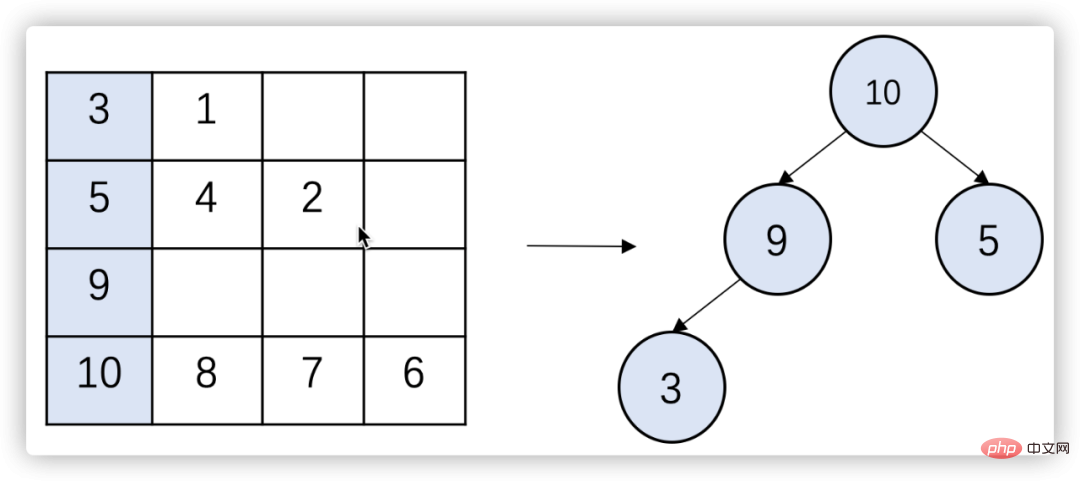
b. Prenez le plus grand élément du haut du grand tas racine et placez-le dans l'ensemble de résultats
c S'il reste des éléments dans la file d'attente où se trouve l'élément, ajoutez l'élément suivant à l'élément suivant. tas ;
d. Répétez les étapes 2 et 3 jusqu'à ce que l'ensemble de résultats contienne K éléments ou que toutes les files d'attente soient vides.
Figure 7 Algorithme Top-K de fusion multidirectionnelle
4.2 Création d'un cache multi-niveaux
Le cache est une stratégie espace-temps typique qui peut mettre en cache les données et les résultats des calculs. Améliorez l’efficacité de l’accès et les résultats du cache pour éviter les calculs répétés. Si la mise en cache apporte des améliorations de performances, elle introduit également de nouveaux problèmes :
La capacité du cache est limitée et les stratégies de chargement, de mise à jour, d'invalidation et de remplacement des données doivent être soigneusement étudiées ;
La conception de l'architecture du cache ; : On dit généralement que les caches mémoire (tels que HashMap, Caffeine, etc.) ont les performances les plus élevées, suivis des caches distribués tels que Redis qui sont relativement lents et que la limite supérieure de capacité est exactement le contraire. être soigneusement sélectionné et utilisé ensemble ;
Comment résoudre le problème de l'incohérence du cache , combien de temps pouvez-vous accepter l'incohérence.
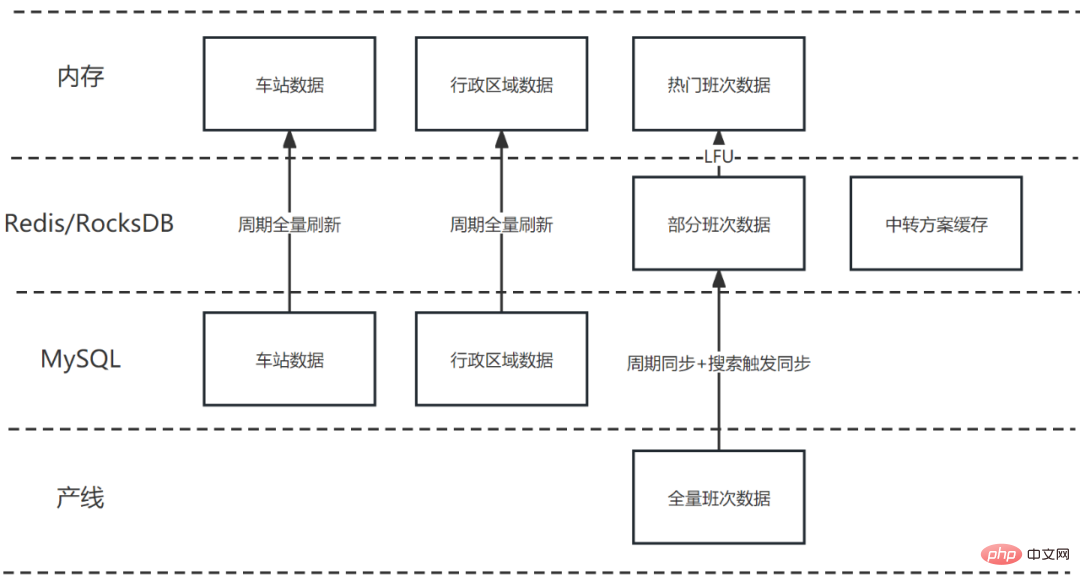
Dans le processus d'épissage des solutions de transport de transfert, une grande quantité de données de base (telles que les gares, les zones administratives, etc.) et des données dynamiques massives (telles que les données d'équipe) doivent être utilisées. Sur la base des facteurs ci-dessus et combinée aux caractéristiques commerciales de l'épissage du trafic de transit, l'architecture du cache est conçue comme suit :
Données de base (telles que les gares, les zones administratives, etc.), car le volume de données est faible et la fréquence des modifications est faible, le montant total est enregistré dans HashMap, mise à jour complète périodique
Certaines données d'horaires de trains, d'avions, de voitures et de navires sont mises en cache dans Redis pour améliorer l'efficacité et la stabilité de l'accès ; Les stratégies de mise en cache adoptées par les différentes lignes de production sont légèrement différentes, mais en général, il s'agit d'une combinaison de mises à jour planifiées et de mises à jour déclenchées par la recherche.
Des centaines de données de la ligne de production peuvent être interrogées au cours d'un processus d'épissage, et Redis dispose d'une milliseconde ; -level delay Cela représente un montant très important. Par conséquent, on espère créer une autre couche de cache mémoire au-dessus de Redis pour améliorer les performances. Grâce à l'analyse, il a été constaté qu'il existe des données très évidentes dans le processus d'épissage. La proportion de requêtes sur les dates et les itinéraires populaires est très élevée et leur nombre est relativement limité. Par conséquent, cette partie des données de point d'accès peut être enregistrée dans le cache mémoire et remplacée par LFU (Least Frequency Used). Le taux de réussite du cache mémoire des données de la ligne de production finale atteint plus de 45 %, ce qui équivaut à réduire près de la moitié de la surcharge d'E/S. .
Étant donné que des incohérences de données infimes peuvent être acceptées, les résultats d'épissage sont mis en cache pendant la période de validité, si l'utilisateur suivant interroge le même itinéraire à la même date de départ, les données mises en cache peuvent être utilisées directement. Étant donné que les données du schéma de transfert épissé sont relativement volumineuses, les résultats d'épissage sont enregistrés dans RocksDB. Bien que les performances ne soient pas aussi bonnes que celles de Redis, l'impact sur une seule requête est acceptable.
Figure 8 Structure de cache multi-niveaux
4.3 Prétraitement
Bien qu'en théorie n'importe quelle ville puisse être sélectionnée comme point de transit entre les deux endroits, en fait la plupart des villes de transit ne peuvent pas fusionner de haute qualité plan. Par conséquent, certains points de transfert de haute qualité sont d'abord filtrés via un prétraitement hors ligne, réduisant ainsi l'espace de solution de plusieurs milliers à plusieurs dizaines. Par rapport aux équipes à évolution dynamique, les données de ligne sont relativement fixes et peuvent être calculées une fois par jour. De plus, le prétraitement hors ligne peut utiliser la technologie Big Data pour traiter des données massives et est relativement insensible à la consommation de temps.
4.4 Traitement multithread
Dans un processus d'épissage, des dizaines de lignes avec différents points de transfert doivent être traitées. L'épissage de chaque ligne est indépendant les uns des autres, ce qui permet d'utiliser le multithreading, ce qui minimise le temps de traitement. Cependant, en raison de l'influence du nombre de décalages de ligne et du taux de réussite du cache, le temps d'épissage des différentes lignes est difficile à être cohérent. Souvent, lorsque deux threads se voient attribuer le même nombre de tâches, même si l'un des threads termine son exécution rapidement, il devra attendre que l'autre thread ait terminé son exécution avant de passer à l'étape suivante. Pour éviter cette situation, le mécanisme de vol de travail de ForkJoinPool est utilisé. Ce mécanisme peut garantir qu'une fois que chaque thread a terminé sa propre tâche, il partagera également le travail inachevé des autres threads, améliorera l'efficacité de la concurrence et réduira les temps d'inactivité.
Mais le multi-threading n'est pas omnipotent. Lorsque vous l'utilisez, vous devez faire attention à :
L'exécution des sous-tâches doit être indépendante les unes des autres et ne pas s'influencer mutuellement. S'il y a des dépendances, vous devez attendre que la tâche précédente soit exécutée avant de démarrer la tâche suivante, ce qui rendra le multithread inutile.
Le nombre de cœurs de processeur détermine la limite supérieure de concurrence. provoquer des changements de contexte fréquents. Pour réduire les performances, une attention particulière doit être accordée aux indicateurs tels que le nombre de threads, l’utilisation du processeur et le temps de limitation du processeur.
4.5 Calcul différé
En reportant les calculs au moment nécessaire, il est possible d'éviter beaucoup de surcharge redondante. Par exemple, après avoir épissé le plan de transfert, vous devez créer l'entité du plan et améliorer les champs métier. Cette partie consomme également des ressources. Et toutes les solutions épissées ne seront pas exclues, ce qui signifie que ces solutions non filtrées doivent quand même consommer des ressources informatiques. Par conséquent, la construction de l'objet entité de solution complète est retardée. Des dizaines de milliers de solutions dans le processus d'épissage sont d'abord enregistrées en tant qu'objets intermédiaires légers, et l'entité de solution complète n'est construite que pour les centaines d'objets intermédiaires après le filtrage.
4.6 Optimisation JVM
Le projet d'épissage du trafic de transit est basé sur Java 8 et utilise le garbage collector G1 (Garbage-First) et est déployé sur des machines 8C8G. G1 atteint un débit élevé tout en respectant autant que possible les exigences de temps de pause. Les paramètres par défaut définis par le service d'architecture système sont déjà adaptés à la plupart des scénarios et ne nécessitent généralement pas d'optimisation particulière.
Cependant, il existe trop de schémas de transfert de ligne, ce qui entraîne des paquets trop volumineux, dépassant la moitié de la taille de la région (8G, la taille par défaut de la région est de 2M), ce qui entraîne de nombreux objets volumineux qui devraient entrer dans la jeune génération. entrer directement dans l'ancienne génération. Afin d'éviter cela, dans ce cas, modifiez la taille de la région à 16 M.
V. Résumé
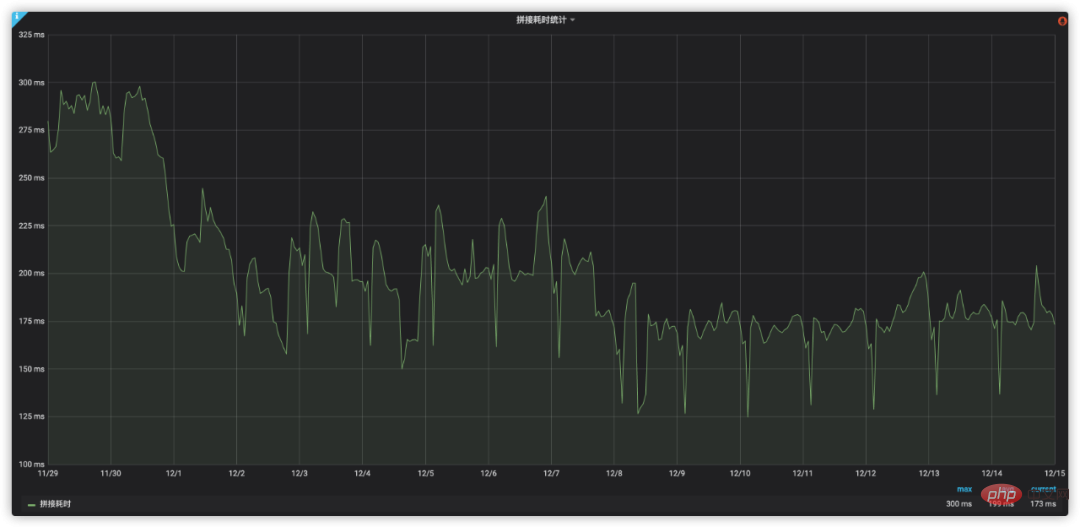
Grâce à l'analyse et à l'optimisation ci-dessus, le changement dans la consommation de temps d'épissage est illustré dans la figure 9 :
Figure 9 Effet d'optimisation des performances d'épissage du schéma de transport de transfert
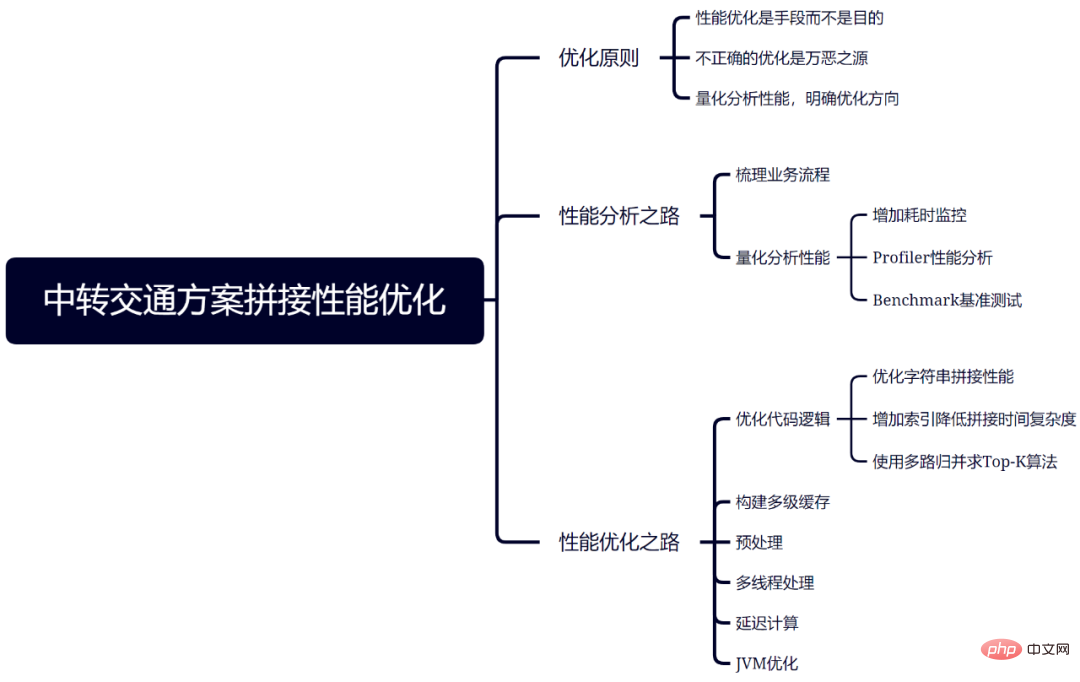
Bien que chaque métier, chaque scénario ait ses propres caractéristiques, et l'optimisation des performances nécessite également une analyse spécifique. Cependant, les principes sont les mêmes, et vous pouvez toujours vous référer aux méthodes d’analyse et d’optimisation décrites dans cet article. Un résumé de toutes les méthodes d'analyse et d'optimisation de cet article est présenté dans la figure 10.
Figure 10 Résumé de l'optimisation de l'épissage du plan de transport de transfert
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn



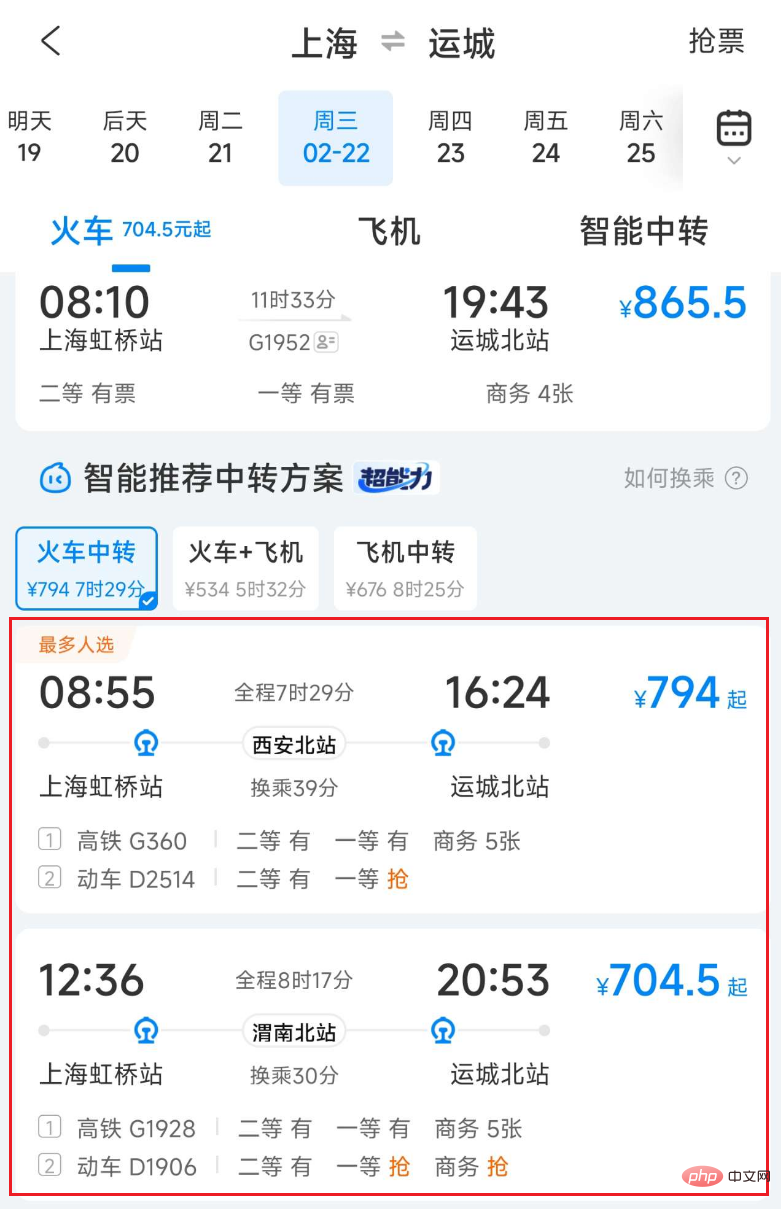
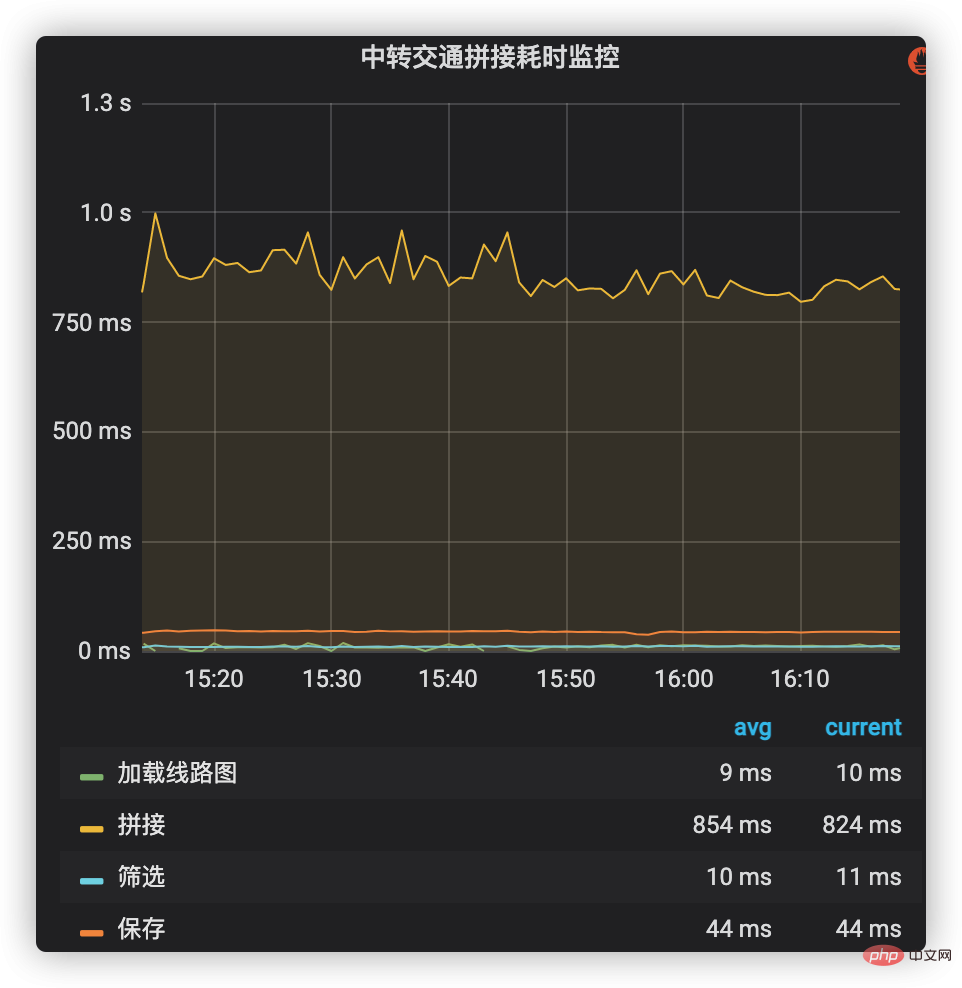

 Figure 4 Arbre d'appels de notation de solution et ratio CPU
Figure 4 Arbre d'appels de notation de solution et ratio CPU

















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



