


En raison du développement rapide de modèles génératifs visuels tels que Stable Diffusion, des images de visage haute fidélité peuvent être automatiquement falsifiées, créant un problème de DeepFake de plus en plus grave.
Avec l'émergence de grands modèles de langage tels que ChatGPT, un grand nombre de faux articles peuvent également être facilement générés et diffuser de fausses informations de manière malveillante.
À cette fin, une série de modèles de détection monomodaux ont été conçus pour traiter la contrefaçon de la technologie AIGC ci-dessus dans les modalités d'image et de texte. Cependant, ces méthodes ne permettent pas de lutter efficacement contre la falsification multimodale de fausses nouvelles dans de nouveaux scénarios de contrefaçon.
Plus précisément, dans la falsification médiatique multimodale, les visages de personnalités importantes sur les images de divers reportages (le visage du président français dans la figure 1) sont remplacés, et des phrases ou mots clés dans le texte sont falsifiés ( Comme le montre la figure 1, la phrase positive « est le bienvenu » a été falsifiée par la phrase négative « est contraint de démissionner »).
Cela changera ou dissimulera l'identité des personnalités clés de l'actualité, ainsi que modifiera ou induira en erreur le sens du texte d'actualité, créant ainsi de fausses nouvelles multimodales diffusées à grande échelle sur Internet.
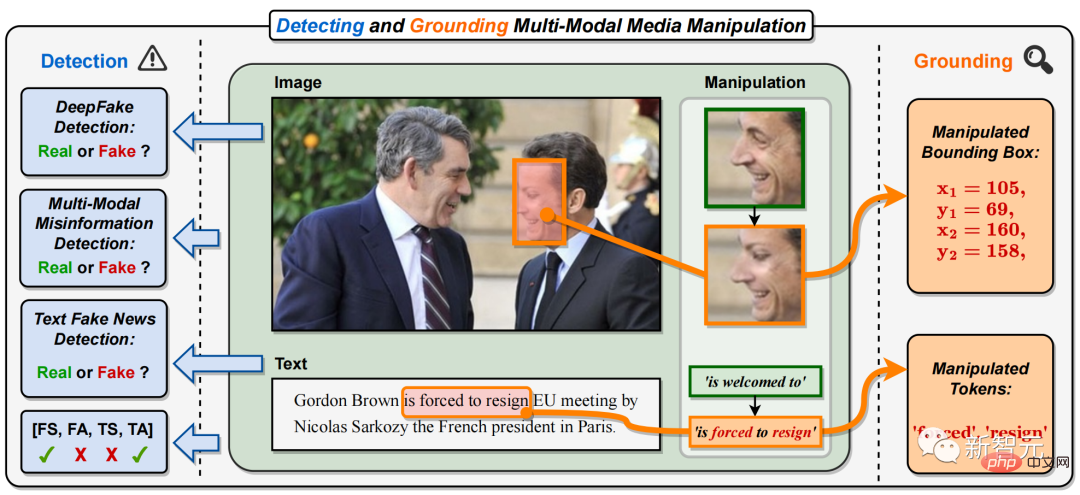
Figure 1. Cet article propose la tâche de détection et de localisation de la falsification de médias multimodaux (DGM4). Différent des tâches de détection DeepFake monomodales existantes, DGM4 prédit non seulement la classification vraie et fausse des paires image-texte d'entrée, mais tente également de détecter des types de falsification plus fins et de localiser les zones d'image falsifiées et les mots falsifiés de texte. En plus de la classification binaire vrai et faux, cette tâche fournit une explication plus complète et une compréhension plus approfondie de la détection de falsification.

Tableau 1 : Comparaison du DGM proposé 4 avec les tâches existantes liées à la détection de falsification d'images et de textes
pour comprendre Pour ce nouveau défi, des chercheurs de l'Institut de technologie de Harbin (Shenzhen) et de l'Institut de technologie de Nanyang ont proposé la tâche de détection et de localisation de la falsification de médias multimodaux (DGM4), ont construit et open source l'ensemble de données DGM4, et ont également proposé un modèle d'inférence de falsification hiérarchique multimodal. Actuellement, ce travail a été inclus dans le CVPR 2023.

Sur Adresse de l'article : https://arxiv.org/abs/2304.02556
GitHub : https://github.com/rshaojimmy/Multi Modal- DeepFaux
Page d'accueil du projet : https://rshaojimmy.github.io/Projects/MultiModal-DeepFake
Comme le montrent la figure 1 et le tableau 1, Détection et localisation des tâches de falsification de médias multimodaux (détection et Grounding Multi-Modal Media Manipulation (DGM4))La différence avec la détection de falsification monomodale existante est la suivante :
1) Différent des méthodes existantes de détection d'images DeepFake et de détection de faux textes ne peuvent détecter que pour les méthodes monomodales fausses informations, DGM4 nécessite une détection simultanée de falsification multimodale dans les paires image-texte ; mots. Cela nécessite que le modèle de détection effectue un raisonnement plus complet et plus approfondi pour la falsification entre les modalités image-texte.
Détecter et localiser l'ensemble de données de falsification de médias multimodauxAfin de soutenir la recherche sur le DGM4
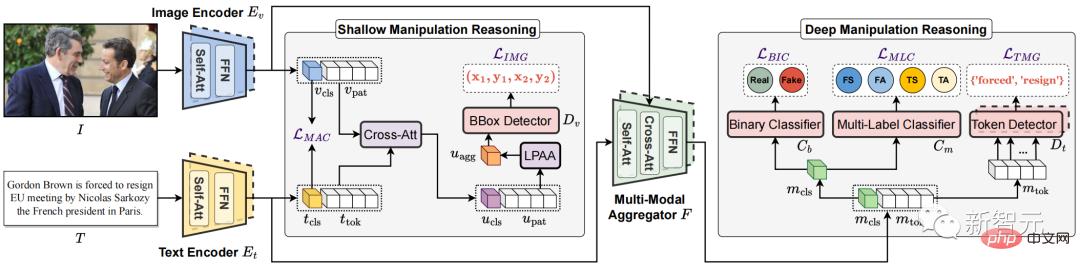
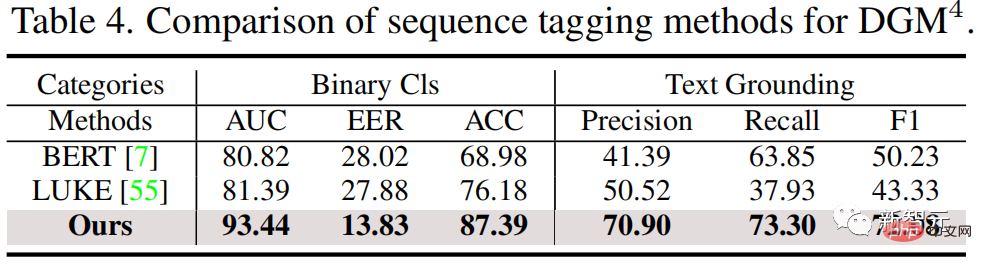
, comme le montre la figure 2, ce travail contribue à la première) Ensemble de données. Figure 2. L'ensemble de données DGM4 L'ensemble de données DGM4 étudie 4 types de falsification, la falsification par remplacement de visage (FS), la falsification d'attributs de visage (FA), la falsification par substitution de texte (TS) , falsification d'attributs de texte (TA). La figure 2 montre les informations statistiques globales du DGM4, y compris (a) la répartition du nombre de types de falsification ; (b) les zones falsifiées de la plupart des images sont de petite taille, en particulier pour la falsification des attributs du visage ; (c) ) La falsification des attributs de texte comporte moins de mots falsifiés que la falsification par remplacement de texte ; (d) Distribution des scores de sentiment du texte ; (e) Nombre d'échantillons pour chaque type de falsification ; Ces données ont généré un total de 230 000 échantillons de paires image-texte, dont 77 426 paires image-texte originales et 152 574 paires d'échantillons falsifiées. Les paires d'échantillons falsifiés comprennent 66 722 falsifications de remplacement de visage, 56 411 falsifications d'attributs de visage, 43 546 falsifications de remplacement de texte et 18 588 falsifications d'attributs de texte. Cet article estime que la falsification multimodale provoquera de subtiles incohérences sémantiques entre les modalités. Par conséquent, détecter l'incohérence sémantique intermodale des échantillons falsifiés en fusionnant et en déduisant des caractéristiques sémantiques entre les modalités est l'idée principale de cet article pour traiter du DGM4. Figure 3. Le modèle d'inférence de falsification hiérarchique multimodal proposé HierArchical Multi-modal Manipulation reasoning tRasformer (HAMMER) Sur la base de cette idée, comme le montre la figure 3, cet article propose Modèle d'inférence de falsification hiérarchique multimodale HierArchical Multi-modal Manipulation raisoning tRasformer (HAMMER). Ce modèle est construit sur l'architecture de modèle de fusion sémantique multimodale et de raisonnement basé sur la structure à deux tours, et implémente la détection et la localisation de la falsification multimodale grâce à un raisonnement de falsification superficiel et profond à un niveau fin. niveau. Plus précisément, comme le montre la figure 3, le modèle HAMMER présente les deux caractéristiques suivantes : 1) Dans le raisonnement de falsification superficiel, grâce à un apprentissage contrastif sensible à la falsification (Manipulation-Aware Contrastive Learning) Pour aligner les caractéristiques sémantiques monomodales des images et du texte extraites par l'encodeur d'image et l'encodeur de texte. Dans le même temps, les fonctionnalités intégrées monomodales utilisent le mécanisme d'attention croisée pour l'interaction des informations, et la Local Patch Attentional Aggregation est conçue pour localiser la zone de falsification de l'image 2) Dans un raisonnement en profondeur sur la falsification, la modalité ; -un mécanisme d'attention croisée conscient dans l'agrégateur multimodal est utilisé pour fusionner davantage les caractéristiques sémantiques multimodales. Sur cette base, un marquage de séquence multimodal spécial et une classification multimodale multi-étiquettes sont effectués pour localiser les mots de falsification de texte et détecter un type de falsification plus fin. Résultats expérimentaux
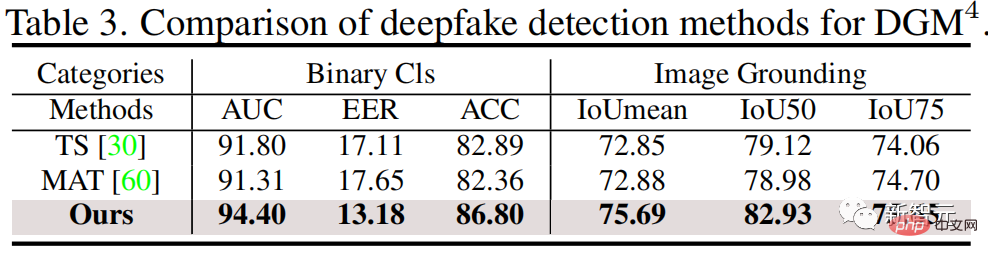
Figure 4. Visualisation des résultats de détection et de localisation de falsification multimodale Figure 5. Visualisation de l'attention de la détection de falsification sur un texte falsifié La figure 4 fournit des éléments visuels multimodaux Les résultats de la détection et de la localisation des manipulations montrent que HAMMER peut effectuer simultanément et avec précision des tâches de détection et de localisation des manipulations. La figure 5 fournit les résultats de visualisation de l'attention du modèle sur les mots falsifiés, démontrant en outre que HAMMER effectue une détection et une localisation de falsification multimodale en se concentrant sur les zones d'image qui sont sémantiquement incompatibles avec le texte falsifié. Le code et le lien de l'ensemble de données de ce travail ont été partagés sur le GitHub de ce projet. Tout le monde est invité à lancer ce dépôt GitHub et à utiliser l'ensemble de données DGM4 et HAMMER pour étudier les problèmes de DGM4. Le domaine de DeepFake ne concerne pas seulement la détection d’images à modalité unique, mais également un problème plus large de détection de falsification multimodale qui doit être résolu de toute urgence ! 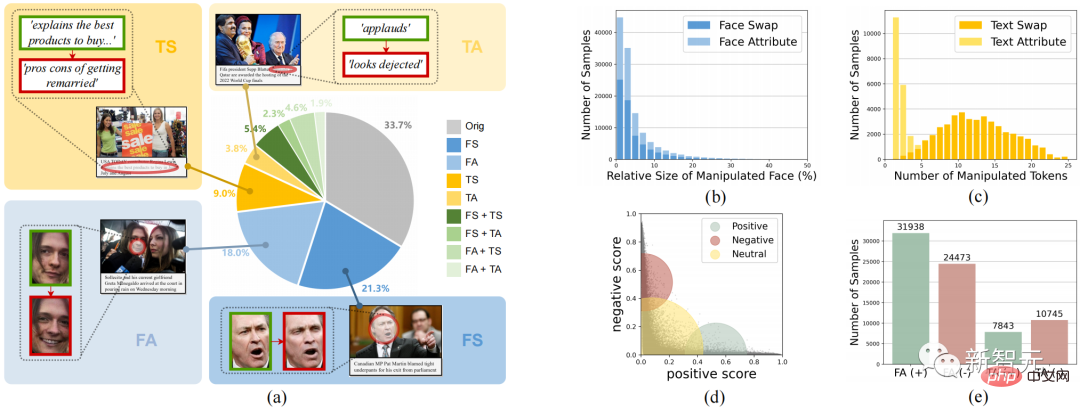
Modèle d'inférence de falsification hiérarchique multimodale


Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Convertir le texte en valeur numérique
Convertir le texte en valeur numérique
 Échange de Bitcoins
Échange de Bitcoins
 Tutoriel de configuration du mot de passe de démarrage de Windows 10
Tutoriel de configuration du mot de passe de démarrage de Windows 10
 Comment résoudre le problème de l'impossibilité de créer un nouveau dossier dans Win7
Comment résoudre le problème de l'impossibilité de créer un nouveau dossier dans Win7
 qu'est-ce que h5
qu'est-ce que h5
 Comment vérifier les liens morts sur votre site Web
Comment vérifier les liens morts sur votre site Web
 Comment récupérer des fichiers vidés de la corbeille
Comment récupérer des fichiers vidés de la corbeille
 Introduction aux plug-ins requis pour que vscode exécute Java
Introduction aux plug-ins requis pour que vscode exécute Java








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



