



Les chatbots ou assistants du service client sont des outils d'IA qui espèrent générer une valeur commerciale grâce à la livraison aux utilisateurs par texte ou voix sur Internet. Le développement des chatbots a progressé rapidement ces dernières années, depuis les premiers robots basés sur une logique simple jusqu'à l'intelligence artificielle actuelle basée sur la compréhension du langage naturel (NLU). Pour ces derniers, les frameworks ou bibliothèques les plus couramment utilisés lors de la création de tels chatbots incluent RASA, Dialogflow, Amazon Lex, etc. étrangers, ainsi que les grandes entreprises nationales Baidu, iFlytek, etc. Ces frameworks peuvent intégrer le traitement du langage naturel (NLP) et NLU pour traiter le texte saisi, classer l'intention et déclencher les bonnes actions pour générer des réponses.
Avec l'émergence des grands modèles de langage (LLM), nous pouvons directement utiliser ces modèles pour créer des chatbots entièrement fonctionnels. L'un des exemples célèbres de LLM est Generative Pre-trained Transformer 3 d'OpenAI (GPT-3 : chatgpt est basé sur le réglage fin de gpt et l'ajout d'un modèle de feedback humain), qui peut affiner le modèle en utilisant des données de dialogue ou de session, générer un texte qui ressemble à une conversation naturelle. Cette capacité en fait le meilleur choix pour créer des chatbots personnalisés.
Aujourd'hui, nous allons parler de la façon de créer notre propre chatbot conversationnel simple en affinant le modèle GPT-3.
Souvent, nous souhaitons affiner le modèle sur un ensemble de données de nos propres exemples de conversations professionnelles, tels que les enregistrements de conversations du service client, les journaux de discussion ou les sous-titres d'un film. Le processus de réglage fin ajuste les paramètres du modèle pour mieux s'adapter à ces données conversationnelles, permettant ainsi au chatbot de mieux comprendre et de mieux répondre aux entrées de l'utilisateur.
Pour affiner GPT-3, nous pouvons utiliser la bibliothèque Transformers de Hugging Face, qui fournit des modèles pré-entraînés et des outils de réglage fin. La bibliothèque propose plusieurs modèles GPT-3 de différentes tailles et capacités. Plus le modèle est grand, plus il peut traiter de données et plus sa précision est susceptible d'être élevée. Cependant, par souci de simplicité, nous utilisons cette fois l'interface OpenAI, qui peut implémenter des réglages fins en écrivant une petite quantité de code.
La prochaine étape est que nous utilisons OpenAI GPT-3 pour implémenter le réglage fin. L'ensemble de données peut être obtenu à partir d'ici. Désolé, j'ai encore utilisé un ensemble de données étranger. Il existe vraiment peu d'ensembles de données traités en Chine.
Créer un compte est très simple, vous pouvez simplement ouvrir ce lien. Nous pouvons accéder au modèle sur OpenAI via la clé openai. Les étapes pour créer une clé API sont les suivantes :
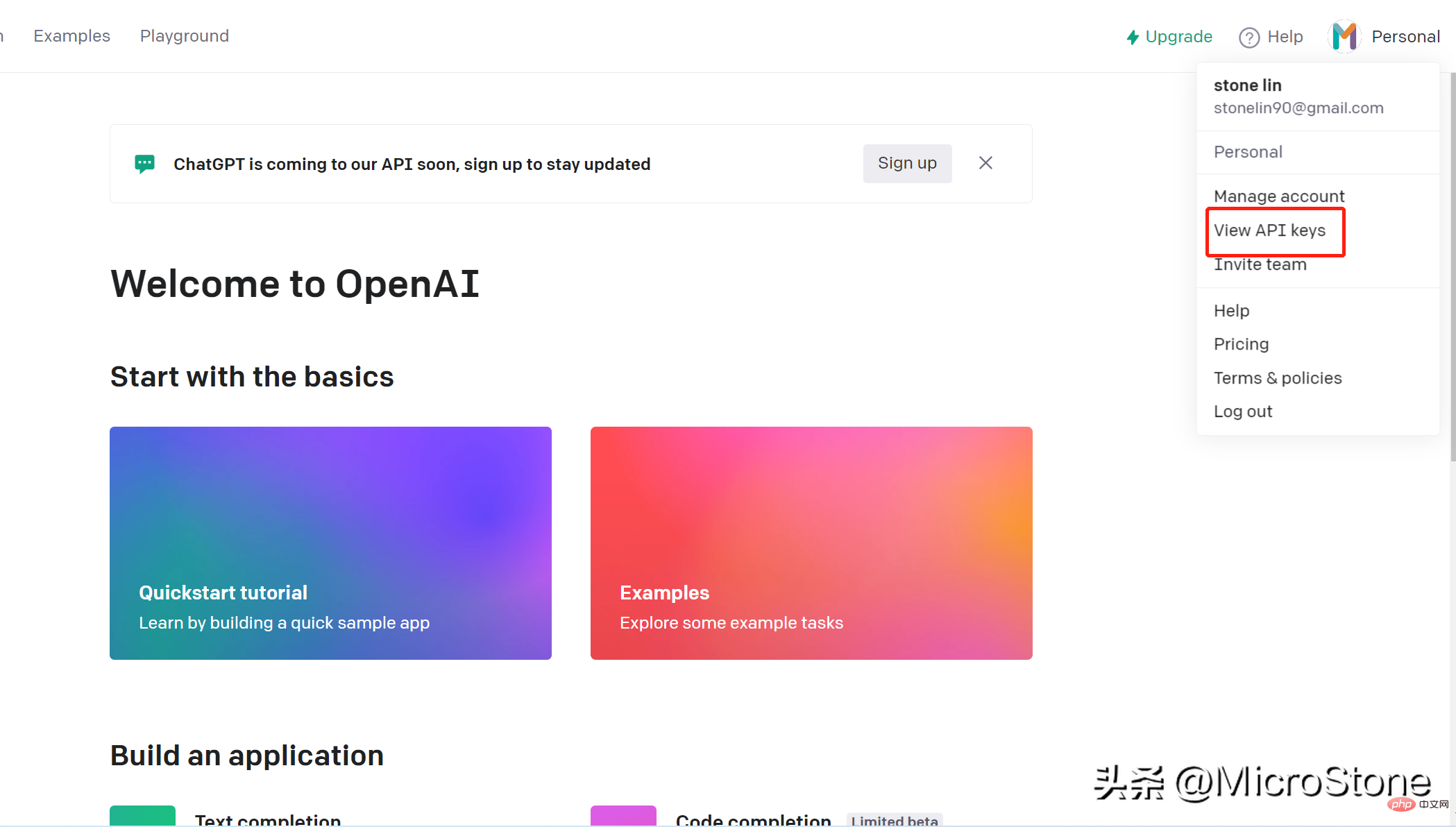
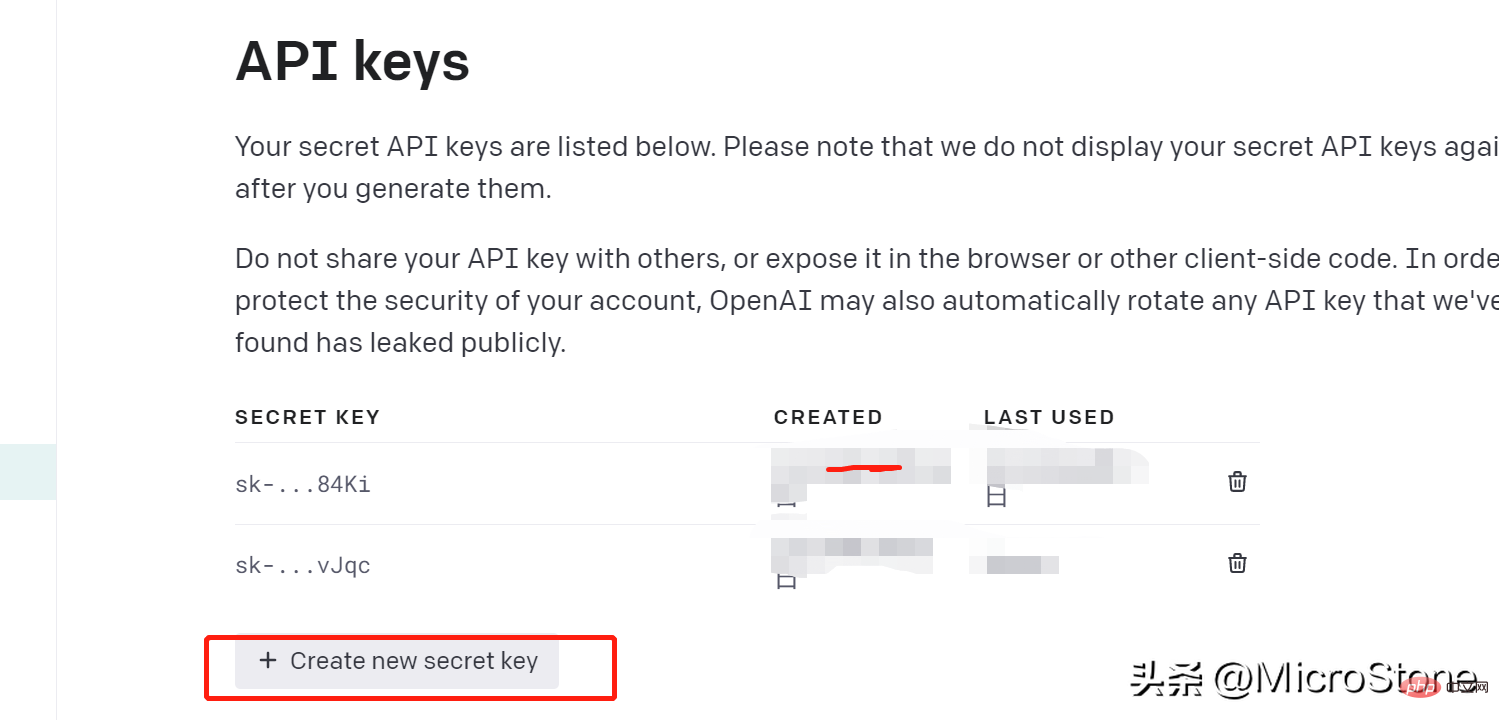
Nous avons créé la clé API, nous pouvons ensuite commencer à préparer les données pour le modèle de réglage fin, et vous pouvez voir l'ensemble de données ici.

Installez la bibliothèque OpenAI pip install openai
Après l'installation, nous pouvons charger les données :
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))Nous chargeons les questions dans la colonne Interview AI et les réponses correspondantes dans la colonne Humain. Nous devons également créer un fichier .env de variable d'environnement pour enregistrer OPENAI_API_KEY
Ensuite, nous convertissons les données au standard GPT-3. Selon la documentation, assurez-vous que les données sont au format JSONL avec deux clés, c'est important : invitez par exemple l'achèvement
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }Restructurez l'ensemble de données pour l'adapter à ce qui précède, parcourez chaque ligne du dataframe et attribuez le texte à Human , attribuez au texte Interview AI la valeur Terminé.
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')Utilisez la commande prepare_data. Certaines questions seront posées lorsque vous y êtes invité. Nous pouvons fournir des réponses O ou N.
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")Enfin, un fichier nommé data_prepared.jsonl est vidé dans le répertoire.
Pour régler le modèle de manière amusante, il suffit d'exécuter une seule ligne de commandes :
os .system( "openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci " )
这基本上使用准备好的数据从 OpenAI 训练davinci模型,fine-tuning后的模型将存储在用户配置文件下,可以在模型下的右侧面板中找到。
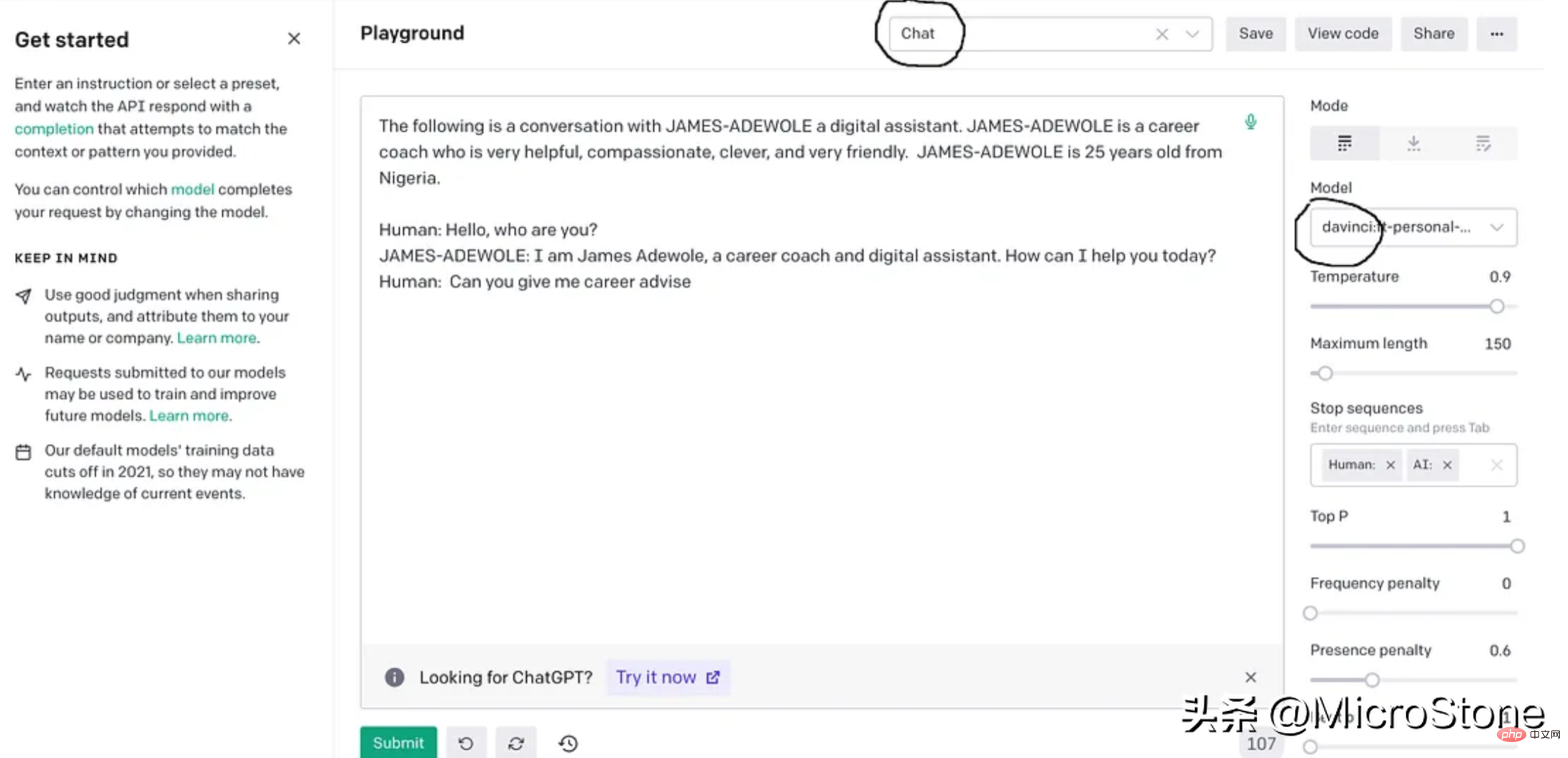
我们可以使用多种方法来验证我们的模型。可以直接从 Python 脚本、OpenAI Playground 来测试,或者使用 Flask 或 FastAPI 等框构建 Web 服务来测试。
我们先构建一个简单的函数来与此实验的模型进行交互。
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()
output = generate_response(input_text)
print(output)把它们放在一起。
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")
os.system("openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci ")
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()示例响应:
input_text = "what is breadth first search algorithm" output = generate_response(input_text)
The breadth-first search (BFS) is an algorithm for discovering all the reachable nodes from a starting point in a computer network graph or tree data structure
GPT-3 是一种强大的大型语言生成模型,最近火到无边无际的chatgpt就是基于GPT-3上fine-tuning的,我们也可以对GPT-3进行fine-tuning,以构建适合我们自己业务的聊天机器人。fun-tuning过程调整模型的参数可以更好地适应业务对话数据,让机器人更善于理解和响应业务的需求。经过fine-tuning的模型可以集成到聊天机器人平台中以处理用户交互,还可以为聊天机器人生成客服回复习惯与用户交互。整个实现可以在这里找到,数据集可以从这里下载。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 ajouter l'utilisation
ajouter l'utilisation
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment représenter des nombres négatifs en binaire
Comment représenter des nombres négatifs en binaire
 Le dernier classement des processeurs Snapdragon
Le dernier classement des processeurs Snapdragon
 Raisons pour lesquelles le chargement du CSS a échoué
Raisons pour lesquelles le chargement du CSS a échoué
 Comment utiliser le contrôle du panneau
Comment utiliser le contrôle du panneau
 Comment désactiver le centre de sécurité Windows
Comment désactiver le centre de sécurité Windows
 tutoriel vbnet
tutoriel vbnet








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



