


Depuis la sortie de la version 5 de Midjourney, des améliorations significatives ont été apportées au réalisme des personnages et des détails des doigts dans les images générées, et des progrès ont également été réalisés en termes de précision de la compréhension rapide, de diversité esthétique et de compréhension du langage.
En revanche, bien que Stable Diffusion soit gratuit et open source, il doit écrire une longue liste d'invites à chaque fois, et générer des images de haute qualité dépend du tirage de cartes à plusieurs reprises.

Récemment, Stability AI a officiellement annoncé que le Stable Diffusion XL en cours de développement a commencé à être testé pour le public et est actuellement disponible en essai gratuit sur la plateforme Clipdrop.

Lien d'essai : https://clipdrop.co/stable-diffusion
Emad Mostaque, fondateur et PDG de Stability AI, a déclaré que le modèle est encore en phase de formation, ce sera open source une fois que les paramètres sont stables ; SD-XL fonctionnera mieux dans les détails de l'image tels que la "poignée de main" et est presque entièrement contrôlable.
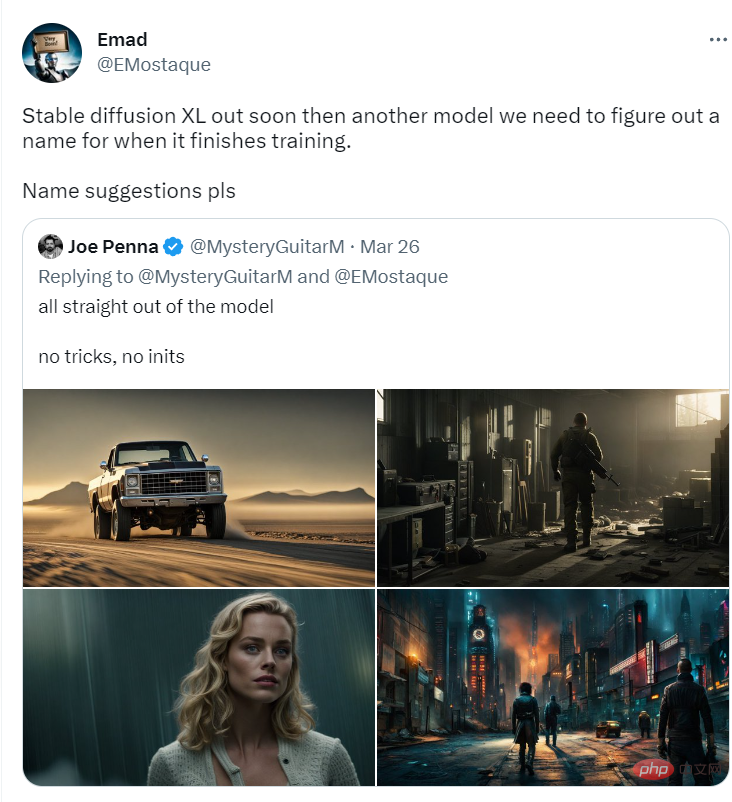
Stable Diffusion XL n'est pas le nom de la version finale, et ce n'est pas la v3, car l'architecture du SD-XL est très similaire à l'architecture du modèle de la série SD-v2.

Gym à domicile minimaliste avec revêtement de sol en caoutchouc, téléviseur mural, banc de musculation, ballon médicinal, haltères, tapis de yoga, équipement de haute technologie, très détaillé, organisé et efficace.
Simple Salle de gym à domicile, revêtement de sol en caoutchouc, téléviseur mural, banc de musculation, médecine-ball, haltères, tapis de yoga, équipement de haute technologie, détails élevés, organisation et efficacité
Les quelques exemples d'images suivants officiellement publiés par SD-XL peuvent be On peut voir que la qualité de l’image est très impressionnante.



Mais parfois, moins ne veut pas dire plus. L'espace de personnalisation devient de plus en plus petit et ne répond pas aux préférences de la plupart des gens. Stable Diffusion, actuellement v1.5, reste le modèle de base le plus populaire de la communauté.

Les internautes ont exprimé l'espoir que la nouvelle version de SD puisse rester compatible avec les modèles d'intégration, d'hyperréseau et de Lora de la version SD 2.1. Il serait trop inconfortable de se recycler à partir de zéro.

Certains internautes pensent que les performances du SD-XL sont similaires au modèle partagé par les internautes sur le site civit, et l'effet du nouveau modèle n'est pas particulièrement étonnant, ce qui est moyen.

SD-v2.1 comprend 900 millions de paramètres, SD-XL compte environ 2,3 milliards de paramètres et Emad a déclaré que la version officielle pourrait en outre publier une version distillée plus petite.
SD-XL présente les améliorations suivantes par rapport à la version précédente :
Utilisez une invite descriptive plus courte pour générer des images de haute qualité
Texte clair et lisible
Bien que les informations textuelles générées par SD-XL ne soient pas toujours exactes, elles apportent une énorme amélioration.

Une jeune femme tenant une pancarte indiquant "Stable Diffusion", des reflets dans les cheveux, assise à l'extérieur du restaurant, les yeux marrons, portant une robe, une lumière latérale
Liang, assise à l'extérieur du restaurant, yeux marrons, porter une jupe, lumières latérales

Stable La diffusion a toujours eu de nombreux problèmes pour générer l'anatomie humaine, plus de jambes, moins de bras sont un problème très courant, c'est généralement nécessaire. pour utiliser la fonction inpaint pour corriger davantage les détails de l'image ; ou utiliser la fonction Open Pose de ControlNet pour copier la posture du corps humain à partir de l'image de référence.
Par exemple, lorsque SD-v1.5 génère des images de yoga, des corps humains déformés apparaissent souvent.
Photo d'une femme en tenue de yoga, pose en triangle, plage en soirée, éclairage de jante
Bien que les images générées par SD-XL ne soient pas parfaites, elles ont fait des progrès significatifs dans la posture humaine.

Par exemple, avec le même thème d'une maison, SD-XL peut générer des photos plus symétriques et avoir de meilleurs effets visuels.

SD-XL présente également des améliorations significatives dans les photos de portrait.
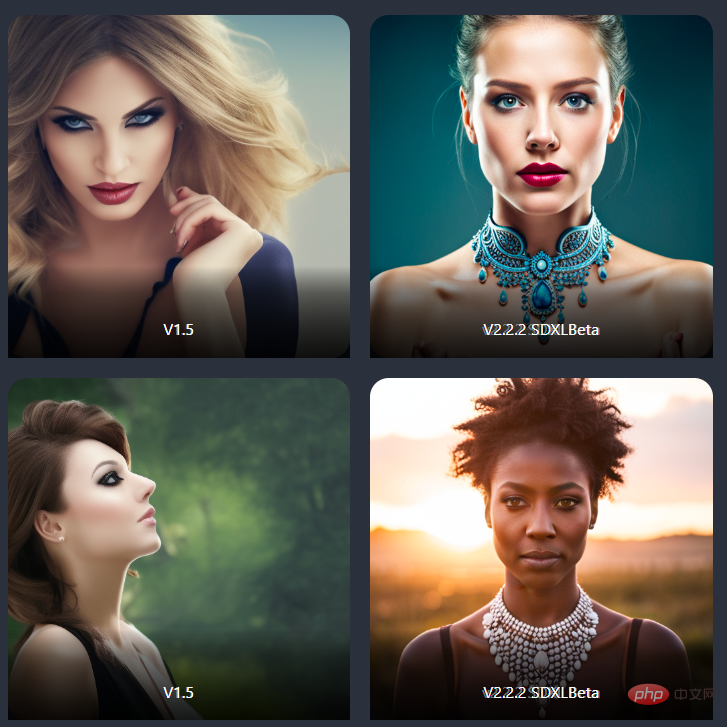
prise de vue d'une femme
Une image qui correspond mieux à l'invite
Par exemple, en prenant comme exemple le bicolore (bicolore), SD-v1.5 ne générera que des images en noir et blanc, tandis que SD-XL peut générer des images bicolores avec plusieurs couleurs.
La capacité à comprendre les invites s'est améliorée par rapport au modèle v1.
Portrait bicolore d'une femme
Portrait bicolore d'une femme
Parce que SD-XL appartient au même modèle de la série v2, la taille du modèle de texte est plus grande et peut être par rapport au modèle v1. Mieux comprendre les mots d'invite.
Par exemple, dans l'exemple ci-dessous, le modèle v1.5 ne peut jamais comprendre les deux sujets de l'image (robot et humain), mais le modèle SD-XL peut générer des images normales (bien que le robot soit toujours pas assez grand).

grand ami robot assis à côté d'un humain, fantôme dans le style coquille, fond d'écran anime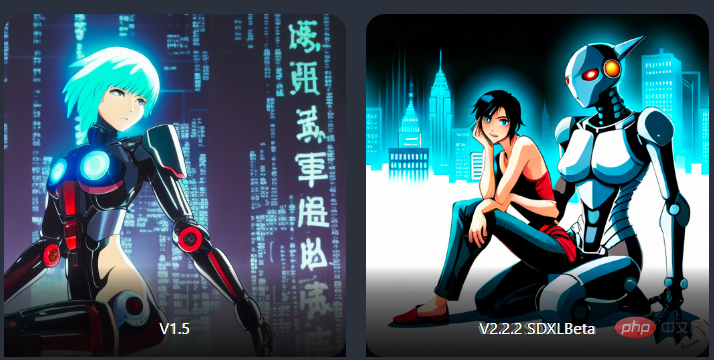
Grand ami robot assis à côté d'un humain, fantôme dans le style coquille, fond d'écran anime
un jeune homme, mèches de cheveux, yeux marrons, en chemise blanche et jean bleu sur une plage avec un volcan en arrière-plan
Un jeune homme, mèches de cheveux, yeux marrons, en chemise blanche et jean bleu sur une plage avec un volcan en arrière-plan Chemise blanche et jean bleu, debout sur la plage, avec un volcan en arrière-plan
Style artistique
Par exemple, deux modèles génèrent des images de style Edward Hopper sous des angles différents.

New York par Edward Hopper
Edward Hopper dessine New York
Le style de Leonid Afmov, SD-v1.5 est plus précis, SD-XL manque de couleurs différentes. coups de pinceau de planches colorées).

New York City par Leonid Afremov
new York dessiné par Leonid Afemov
william-Adolphe Bouguereau Style, V1.5 et SDXL peuvent générer un contenu similaire, parmi les deux eux, SD-XL est plus proche de la peinture académique classique créée par Bouguereau et présente plus de détails sur le visage.

moins Ajouter quelques clés non pertinentes Après l'écriture, le style du modèle peut soudainement changer.
Par exemple, générez d'abord une image de style photo.
Un jeune homme, méchés dans les cheveux, yeux marrons, en chemise blanche et jean bleu sur une plage avec un volcan en arrière-plan Yeux, vêtu d'une chemise blanche et d'un jean bleu, debout sur la plage avec un volcan en arrière-plan
Après avoir ajouté une écharpe jaune, le style de l'image devient dessin animé style. 
un jeune homme, des reflets dans les cheveux, les yeux marrons,
portant un foulard jaune,en chemise blanche et un jean bleu sur une plage avec un volcan en fond
un jeune homme, Cheveux teints de couleurs vives, yeux marron, portant un foulard jaune, portant une chemise blanche et un jean bleu, debout sur une plage avec un volcan en arrière-plan

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment fonctionne le capteur de température
Comment fonctionne le capteur de température
 La différence entre vscode et vs
La différence entre vscode et vs
 tutoriel d'exécution de code c++
tutoriel d'exécution de code c++
 Annuler la campagne WeChat
Annuler la campagne WeChat
 Comment gérer les téléchargements de fichiers bloqués dans Windows 10
Comment gérer les téléchargements de fichiers bloqués dans Windows 10
 utilisation des balises de jeu de champs
utilisation des balises de jeu de champs
 Comment afficher le HTML au centre
Comment afficher le HTML au centre
 Comment sauter avec des paramètres dans vue.js
Comment sauter avec des paramètres dans vue.js








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



