


La popularité de ChatGPT et Midjourney a fait du modèle de diffusion technologique qui les sous-tend le fondement de la révolution de « l'IA générative ».
Même, il est très recherché par les chercheurs de l'industrie, et sa popularité dépasse de loin celle du GAN, qui attaquait autrefois le monde.
Juste au moment où les modèles de diffusion étaient à leur apogée, certains internautes ont soudainement annoncé de manière très médiatisée :
L'ère des modèles de diffusion est révolue ! Les modèles de cohérence sont sacrés rois !

Que diable se passe-t-il ? ? ?
Il s'avère qu'OpenAI a publié un article à succès et précieux "Consistency Models" en mars, et a publié les poids des modèles sur GitHub aujourd'hui.

Adresse papier : https://arxiv.org/abs/2303.01469
Adresse du projet : https://github.com/openai/consistency_models
Le Le « modèle de cohérence » renverse le modèle de diffusion en termes de vitesse d'entraînement. Il peut « générer en une seule étape » et effectuer des tâches simples un ordre de grandeur plus rapidement que le modèle de diffusion, et nécessite 10 à 2 000 fois moins de calculs.

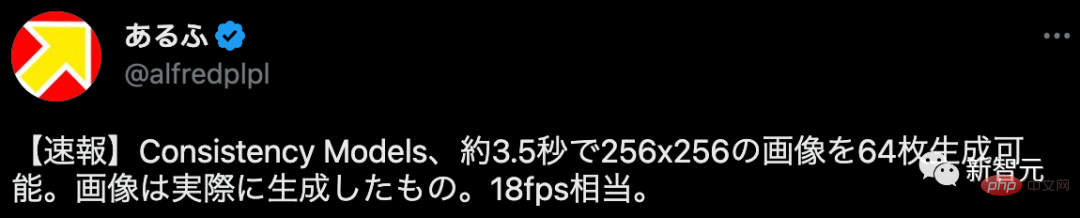
Certains internautes ont déclaré que cela équivaut à générer 64 images avec une résolution de 256x256 en 3,5 secondes environ, soit
18 images par seconde !

a été rédigée par Ilya Sutskever, l'un des étudiants Hinton des Trois Grands de Turing et le principal promoteur d'AlexNet, ainsi que par les universitaires chinois Mark Chen et Prafulla Dhariwal qui ont développé DALL-E. 2, Vous pouvez imaginer à quel point le contenu de la recherche est complexe.
Certains internautes ont même dit que le « modèle de cohérence » est l'orientation future de la recherche. Je pense que nous allons certainement rire du modèle de diffusion à l'avenir.

Plus rapide, plus fort, pas besoin de confrontation
Actuellement, cet article est encore une version non finalisée et les recherches sont toujours en cours.

En 2021, Sam Altman, PDG d'OpenAI, a écrit un blog expliquant comment la loi de Moore devrait être appliquée à tous les domaines.

Altman a déclaré publiquement sur Twitter il y a quelque temps que l'intelligence artificielle était en train de réaliser un "saut de grenouille". Il a déclaré : « Une nouvelle version de la loi de Moore pourrait bientôt apparaître, avec le nombre d'intelligences dans l'univers doublant tous les 18 mois. » Pour d'autres, l'optimisme d'Altman peut sembler infondé.
Mais les dernières recherches menées par l’équipe dirigée par Ilya Sutskever, scientifique en chef d’OpenAI, apportent un soutien solide à l’affirmation d’Altman. 
On dit que 2022 est la première année de l'AIGC, car de nombreux modèles sont basés sur le modèle de diffusion.
La popularité du modèle de diffusion a progressivement remplacé le GAN et est devenu le modèle de génération d'images le plus efficace de l'industrie actuelle. Par exemple, DALL.E 2 et Google Imagen sont tous deux des modèles de diffusion. 
Cependant, le « modèle de cohérence » nouvellement proposé s'est avéré capable de produire le même contenu de qualité que le modèle de diffusion dans un délai plus court.
En effet, ce « modèle de cohérence » utilise un processus de génération en une seule étape similaire au GAN.
En revanche, le modèle de diffusion utilise un processus d'échantillonnage répété pour éliminer progressivement le bruit dans l'image.
Cette méthode, bien qu'impressionnante, repose sur l'exécution de centaines, voire de milliers d'étapes pour obtenir de bons résultats, ce qui est non seulement coûteux à mettre en œuvre, mais aussi lent.
Le processus de génération itérative continue du modèle de diffusion consomme 10 à 2000 fois plus de calculs que le « modèle de cohérence », et ralentit même la vitesse d'inférence pendant le processus de formation.
La puissance du « modèle de cohérence » réside dans sa capacité à faire un compromis entre la qualité des échantillons et les ressources informatiques lorsque cela est nécessaire. 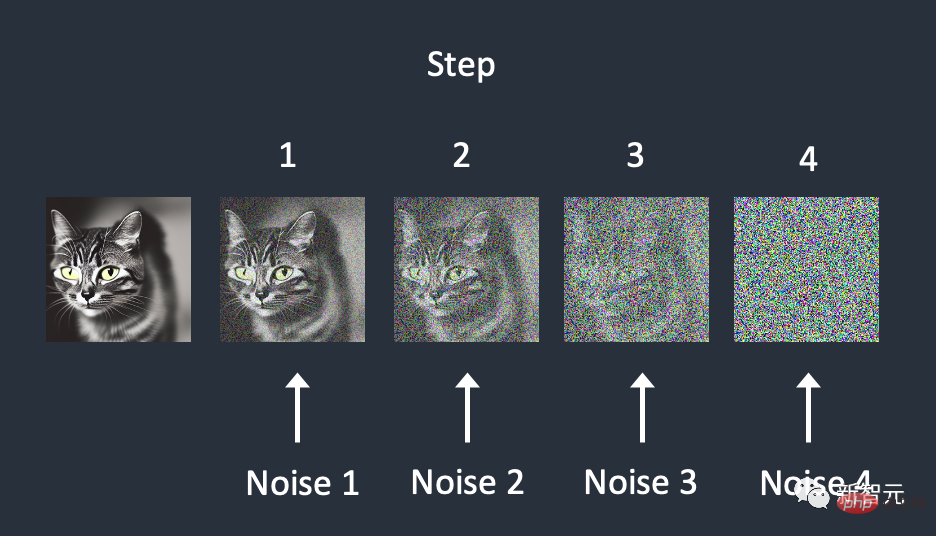
De plus, ce modèle est également capable d'effectuer des tâches d'édition de données sans prise de vue telles que l'application de correctifs d'images, la colorisation ou l'édition d'images guidées par traits.
Édition d'image Zero-shot à l'aide du modèle de cohérence formé par distillation sur LSUN Bedroom 256^256

Ce type d'équation est appelé « Équation différentielle ordinaire du flux de probabilité » (Probability Flow ODE).
Cette étude a nommé ce type de modèle « cohérence » car ils maintiennent cette auto-cohérence entre les données d'entrée et les données de sortie.
Ces modèles peuvent être entraînés soit en mode distillation, soit en mode isolation.
En mode distillation, le modèle est capable d'extraire les données d'un modèle de diffusion pré-entraîné, permettant de l'exécuter en une seule étape.
En mode séparé, le modèle est totalement indépendant du modèle de diffusion, ce qui en fait un modèle totalement indépendant.

Il est à noter que ces deux méthodes de formation en suppriment la « formation contradictoire ».
Je dois admettre que l'entraînement contradictoire produira effectivement un réseau neuronal plus puissant, mais le processus est plus détourné. Autrement dit, il introduit un ensemble d’échantillons contradictoires mal classés, puis recycle le réseau neuronal cible avec les étiquettes correctes.
Par conséquent, l'entraînement contradictoire entraînera également une légère diminution de la précision des prédictions des modèles d'apprentissage profond, et pourrait même entraîner des effets secondaires inattendus dans les applications robotiques.
Les résultats expérimentaux montrent que la technique de distillation utilisée pour entraîner le « modèle de cohérence » est meilleure que celle utilisée pour le modèle de diffusion.
Le « Modèle cohérent » a obtenu les derniers scores FID de pointe de 3,55 et 6,20 sur l'ensemble d'images CIFAR10 et l'ensemble de données ImageNet 64x64, respectivement.
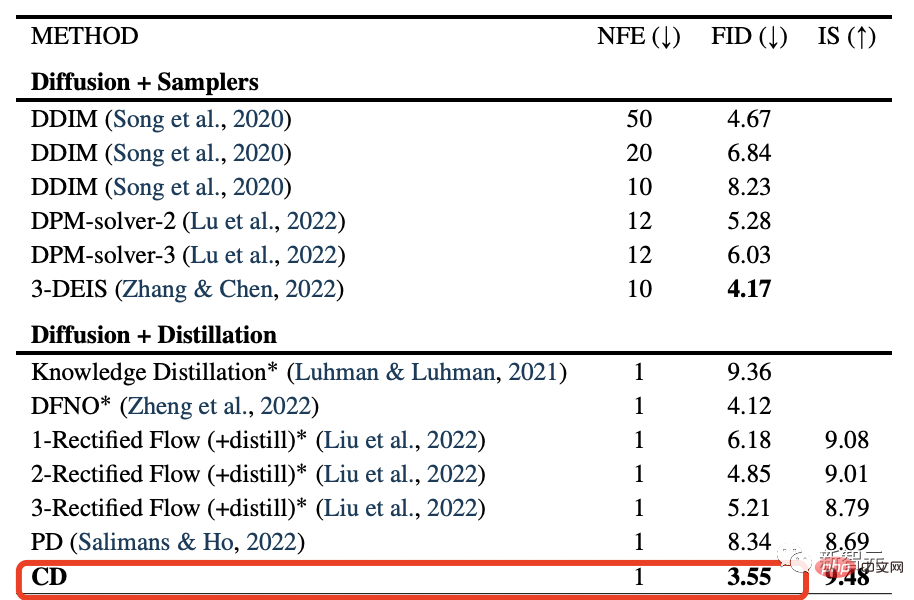
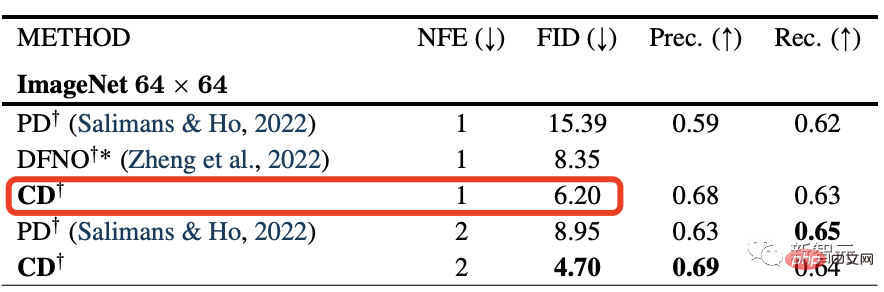
C'est tout simplement réalisé, la qualité du modèle de diffusion + la vitesse du GAN, double perfection.
En février, Sutskever a publié un tweet suggérant :
De nombreuses personnes pensent que les grands progrès de l'IA doivent inclure une nouvelle « idée ». Mais ce n’est pas le cas : bon nombre des plus grandes avancées de l’IA se sont présentées sous la forme de cette humble idée familière qui, si elle est bien réalisée, devient incroyable.

Les dernières recherches le prouvent, les ajustements basés sur d'anciens concepts peuvent tout changer.
En tant que co-fondateur et scientifique en chef d'OpenAI, Ilya SutskeverPas besoin d'entrer dans les détails, il suffit de regarder cette photo de groupe des "top leaders".

(à l'extrême droite de la photo)

Song 飏, le premier auteur du journal, un chercheur scientifique à OpenAI.
Auparavant, il a obtenu une licence en mathématiques et en physique de l'Université Tsinghua, ainsi qu'une maîtrise et un doctorat en informatique de l'Université de Stanford. De plus, il a effectué des stages chez Google Brain, Uber ATG et Microsoft Research.
En tant que chercheur en apprentissage automatique, il se concentre sur le développement de méthodes évolutives pour modéliser, analyser et générer des données complexes de grande dimension. Ses intérêts couvrent plusieurs domaines, notamment la modélisation générative, l'apprentissage des représentations, le raisonnement probabiliste, la sécurité de l'intelligence artificielle et l'IA pour la science.

Mark Chen est le chef du département de recherche multimodale et de pointe d'OpenAI et l'entraîneur de l'équipe américaine de l'Olympiade informatique.
Auparavant, il a obtenu un baccalauréat en mathématiques et en informatique du MIT et a travaillé comme trader quantitatif dans plusieurs sociétés de trading pour compte propre, dont Jane Street Capital.
Après avoir rejoint OpenAI, il a dirigé l'équipe pour développer DALL-E 2 et introduit la vision dans GPT-4. De plus, il a dirigé le développement du Codex, participé au projet GPT-3 et créé Image GPT.

Prafulla Dhariwal est chercheuse scientifique à OpenAI, travaillant sur les modèles génératifs et l'apprentissage non supervisé. Avant cela, il était étudiant au MIT, où il étudiait l'informatique, les mathématiques et la physique.
Fait intéressant, le modèle de diffusion peut battre le GAN dans le domaine de la génération d'images, c'est ce qu'il a proposé dans l'article NeurIPS 2021.

OpenAI a ouvert le code source du modèle de cohérence aujourd'hui.
Enfin de retour à Open AI.

Face à tant d'avancées et d'annonces folles chaque jour. Les internautes ont demandé : devrions-nous faire une pause ou accélérer ?

Par rapport aux modèles de diffusion, cela permettra aux chercheurs d'économiser considérablement sur le coût de la formation des modèles.
Certains internautes ont également donné de futurs cas d'utilisation du « modèle de cohérence » : édition en temps réel, rendu NeRF et rendu de jeu en temps réel.
Il n'y a actuellement aucune démo, mais il convient de confirmer qu'elle peut augmenter considérablement la vitesse de génération d'images et qu'elle est toujours gagnante.
Nous sommes passés directement de l'accès commuté au haut débit.

Interface cerveau-ordinateur, ainsi que des images ultra-réalistes générées en temps quasi réel.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 écran de téléphone portable tft
écran de téléphone portable tft
 Comment installer le filtre PS
Comment installer le filtre PS
 Comment désactiver la complétion automatique sublime
Comment désactiver la complétion automatique sublime
 Comment aligner les zones de texte en HTML
Comment aligner les zones de texte en HTML
 ps supprimer la zone sélectionnée
ps supprimer la zone sélectionnée
 Comment acheter et vendre du Bitcoin sur Binance
Comment acheter et vendre du Bitcoin sur Binance
 Étapes WeChat
Étapes WeChat
 Classement des dix principaux échanges de devises numériques
Classement des dix principaux échanges de devises numériques








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



