



Première forme normale : atomicité du champ, deuxième forme normale : les lignes sont uniques et ont des colonnes de clé primaire, troisième forme normale : chaque colonne est liée à la colonne de clé primaire.
Dans les applications réelles, un petit nombre de champs redondants seront utilisés pour réduire le nombre de tables associées et améliorer l'efficacité des requêtes.
La base de données MySQL elle-même est bloquée, par exemple : ressources système ou réseau insuffisantes
Les instructions SQL sont bloquées, telles que : verrous de table, verrous de ligne, etc., empêchant le moteur de stockage d'exécuter le correspondant Déclarations SQL
Cela est en effet dû à une mauvaise utilisation de l'index et à l'absence d'indexation
Les caractéristiques des données dans la table L'indexation est utilisée, mais le nombre de retours de table est énorme
Pour les fonctions de comptage sous la forme de count(*), count(constant), count(primary key), le optimiseur Vous pouvez sélectionner l'index avec le coût d'analyse le plus faible pour exécuter la requête afin d'améliorer l'efficacité. Leurs processus d'exécution sont les mêmes. count(*)、count(常数)、count(主键)形式的count函数来说,优化器可以选择扫描成本最小的索引执行查询,从而提升效率,它们的执行过程是一样的。
而对于count(非索引列)来说,优化器选择全表扫描,说明只能在聚集索引的叶子结点顺序扫描。
count(二级索引列)
count (colonne non-index), l'optimiseur choisit une analyse complète de la table, ce qui signifie qu'il ne peut analyser que les nœuds feuilles de l'index cluster de manière séquentielle. 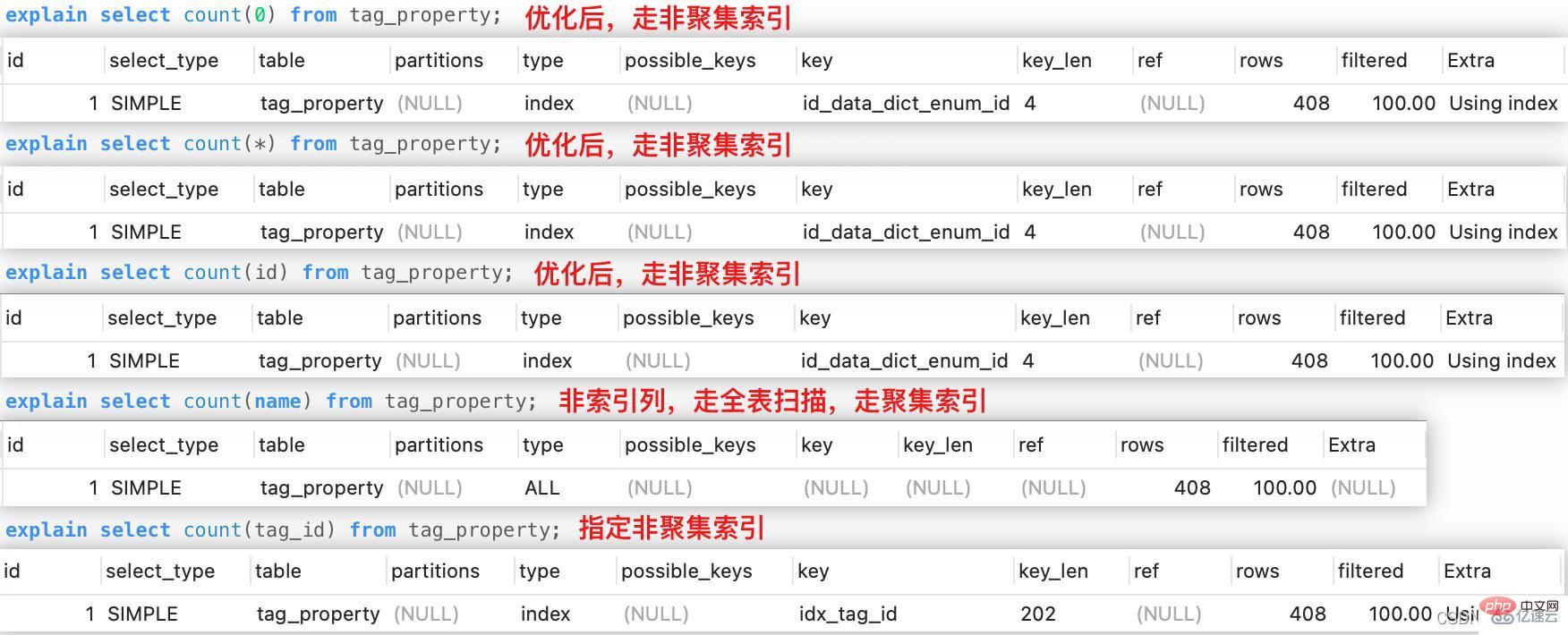
count (colonne d'index secondaire) ne peut sélectionner que l'index contenant les colonnes que nous spécifions pour exécuter la requête, ce qui peut faire en sorte que le coût d'exécution de l'index sélectionné par l'optimiseur ne soit pas le plus petit.
Optimiser avec l'index de couverture : lorsqu'une requête MySQL atteint complètement l'index, on parle d'index de couverture, ce qui est très rapide car la requête n'a besoin que de rechercher sur l'index et peut être renvoyée directement sans revenir à la table pour obtenir les données.Par conséquent, nous pouvons d'abord trouver l'ID de l'index, puis obtenir les données en fonction de l'ID.
Limiter le nombre de pages si les affaires le permettent
Ajoutez des index appropriés : créez un index pour les champs utilisés comme conditions de requête et triez-les, considérez plusieurs champs de requête pour établir un index combiné, faites attention à l'ordre des champs d'index combinés et placez les colonnes les plus courantes. utilisés comme conditions restrictives dans A l'extrême gauche, par ordre décroissant, les indices ne doivent pas être trop nombreux, généralement inférieurs à 5.
Optimiser la structure de la table : les champs numériques sont meilleurs que les types de chaîne, les types de données plus petits sont généralement meilleurs, essayez d'utiliser NOT NULL
Optimiser les instructions de requête : analyser le plan d'exécution SQL, s'il atteint l'index, etc., si le SQL est très complexe, optimisez la structure SQL. Si la quantité de données de la table est trop importante, envisagez de diviser la table
À la suite de l'exécution de show processlist, j'ai vu des milliers de connexions, ce qui fait référence à des connexions simultanées.
L'instruction "en cours d'exécution" est une requête simultanée.
Un grand nombre de connexions simultanées affecte la mémoire.
Les requêtes concurrentes trop élevées sont mauvaises pour le CPU. Une machine dispose d'un nombre limité de cœurs de processeur et si tous les threads s'y précipitent, le coût du changement de contexte sera trop élevé.
Il convient de noter qu'après qu'un thread entre dans l'attente de verrouillage, le nombre de threads simultanés est réduit de un, de sorte que les threads en attente de verrous de ligne ou de verrous d'espacement ne sont pas inclus dans la plage de nombre. C'est-à-dire que le thread en attente du verrouillage ne consomme pas de CPU, évitant ainsi le blocage de l'ensemble du système.
Les mêmes données ne seront pas mises à jour.
Cependant, différents formats de binlog ont des méthodes de traitement des journaux différentes :
1) Lorsqu'elle est basée sur le mode ligne, la couche serveur correspond à l'enregistrement à mettre à jour et constate que la nouvelle valeur est cohérente avec l'ancienne valeur, donc aucune action n'est prise. S'il est mis à jour, il sera renvoyé directement sans enregistrer le journal binaire.
2) Lorsqu'il est basé sur une instruction ou un format mixte, MySQL exécute l'instruction de mise à jour et enregistre l'instruction de mise à jour dans binlog.
la plage de dates de datetime est de 1001 à 9999 ; la plage de temps de l'horodatage est de 1970 à 2038
la durée de stockage de datetime n'a rien à voir avec le fuseau horaire, la durée de stockage de l'horodatage est liée au fuseau horaire, et la valeur affichée dépend également ; on L'espace de stockage du fuseau horaire
datetime est de 8 octets ; l'espace de stockage de l'horodatage est de 4 octets
La valeur par défaut de datetime est nulle, la valeur par défaut du champ d'horodatage n'est pas vide (non nulle), et la valeur par défaut est l'heure actuelle (current_timestamp)
« Lecture non validée » est le niveau le plus bas et ne peut en aucun cas être garanti. occurrence de lectures sales et de lectures non répétables
"Sérialisable" peut éviter l'apparition de lectures sales, de lectures non répétables et de lectures fantômes
Le niveau d'isolement des transactions par défaut de Mysql est "Lecture répétable"
Chapitre d'index
Le contenu des nœuds feuilles dans les index de clé non primaire est la valeur de la clé primaire. Dans InnoDB, les index de clé non primaire sont également appelés index secondaires.
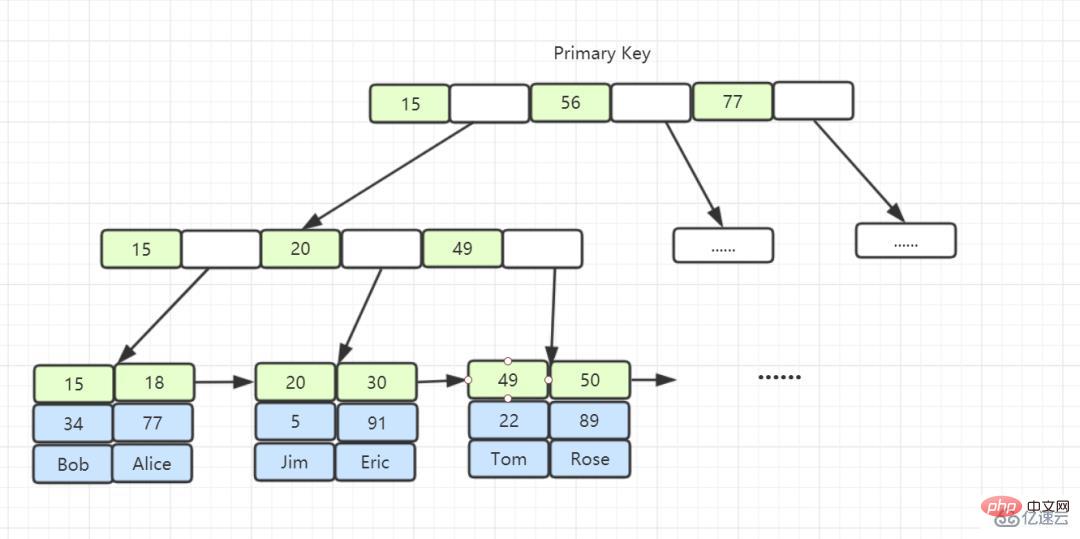
Index clusterisé : Un index clusterisé est un index créé avec la clé primaire. L'index clusterisé stocke les données dans la table dans les nœuds feuilles.
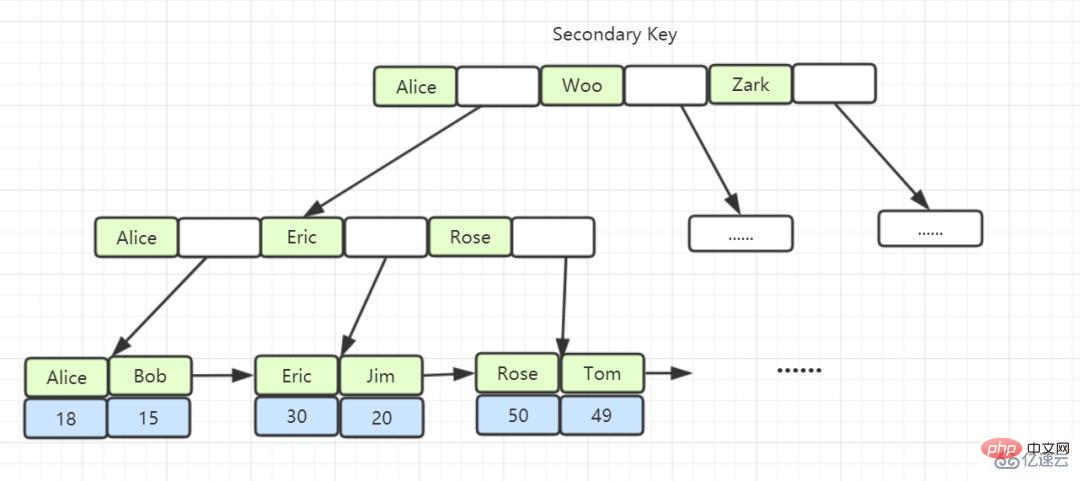
Index non clusterisé : Un index créé par une clé non primaire stocke la clé primaire et la colonne d'index dans le nœud feuille. Lorsque vous utilisez l'index non clusterisé pour interroger les données, vous devez. récupérez la clé primaire sur la feuille, puis recherchez les données à trouver. (Le processus d'obtention de la clé primaire puis de recherche est appelé retour de table).
Indice de couverture : En supposant que les colonnes interrogées se trouvent être les colonnes correspondant à l'index et qu'il n'est pas nécessaire de revenir à la table pour rechercher, alors cette colonne d'index est appelée un indice de couverture.
L'index de hachage peut gérer l'ajout, la suppression, la modification et l'interrogation d'une seule ligne de données à une vitesse O(1), mais lorsqu'il est confronté à des requêtes par plage ou à un tri, il conduira aux résultats d'une analyse complète de la table.
B-tree peut stocker des données dans des nœuds non-feuilles. Étant donné que tous les nœuds peuvent contenir des données cibles, nous devons toujours parcourir le sous-arbre vers le bas à partir du nœud racine pour trouver les lignes de données qui remplissent les conditions. Un certain nombre d'E/S aléatoires entraînent une dégradation des performances.
Toutes les lignes de données de l'arborescence B+ sont stockées dans des nœuds feuilles, et ces nœuds feuilles peuvent être connectés dans l'ordre via des « pointeurs ». Lorsque nous parcourons les données dans l'arborescence B+ comme indiqué ci-dessous, nous pouvons directement parcourir parmi plusieurs. nœuds enfants Passer d'un fichier à l'autre peut économiser beaucoup de temps d'E/S disque.
Arbre binaire : la hauteur de l'arbre est inégale et ne peut pas s'auto-équilibrer. L'efficacité de la recherche est liée aux données (la hauteur de l'arbre) et le coût d'E/S est élevé.
Arbre rouge-noir : la hauteur de l'arbre augmente à mesure que la quantité de données augmente, et le coût d'E/S est élevé.
Dans InnoDB, le nœud feuille de l'index B+ Tree stocke la ligne entière de données est l'index de clé primaire, également appelé index clusterisé, qui rassemble le stockage des données et l'index. Si vous trouvez l'index, vous trouverez les données.
Le nœud feuille de l'index B+Tree stocke la valeur de la clé primaire, qui est un index de clé non primaire, également appelé index non clusterisé ou index secondaire.
Le premier index est généralement une IO séquentielle, et l'opération de retour à la table est une IO aléatoire. Plus nous devons revenir à la table, c'est-à-dire plus nous avons besoin d'E/S aléatoires, plus nous avons tendance à utiliser des analyses de table complètes.
Pas nécessairement, cela implique que tous les champs requis par l'instruction de requête atteignent l'index. Si tous les champs atteignent l'index, il n'est pas nécessaire d'effectuer une requête vers la table. Un index contient (couvre) les valeurs de tous les champs qui doivent être interrogés et est appelé « index de couverture ».
Le principe du préfixe le plus à gauche est la priorité la plus à gauche. Lors de la création d'un index multi-colonnes, selon les besoins de l'entreprise, la colonne la plus fréquemment utilisée dans la clause Where est placée à l'extrême gauche.
MySQL continuera à correspondre vers la droite jusqu'à ce qu'il rencontre une requête de plage (>, <, between, like), puis cessera de correspondre, comme a = 1 et b = 2 et c > = 4. Si (Index dans l'ordre de a, b, c, d), d n'est pas utilisé pour l'indexation. Si vous créez un index de (a, b, d, c), il peut être utilisé dans l'ordre de. a, b, d peuvent être ajustés arbitrairement.
= et in peuvent être dans le désordre, comme a = 1 et b = 2 et c = 3. Vous pouvez créer des index (a, b, c) dans n'importe quel ordre. L'optimiseur de requêtes de MySQL vous aidera à l'optimiser. dans un index qui peut être reconnu.
Lorsque le principe du préfixe le plus à gauche est respecté, le préfixe le plus à gauche peut être utilisé pour localiser les enregistrements dans l'index.
Avant MySQL 5.6, vous ne pouviez renvoyer les tables qu'une par une en commençant par l'ID. Recherchez la ligne de données sur l'index de clé primaire, puis comparez les valeurs de champ.
L'optimisation du pushdown des conditions d'index (index condition pushdown) introduite dans MySQL 5.6 peut d'abord juger les champs inclus dans l'index pendant le processus de traversée de l'index, filtrer directement les enregistrements qui ne remplissent pas les conditions et réduire le nombre de tables. revient.
Si la table utilise une clé primaire à incrémentation automatique, chaque fois qu'un nouvel enregistrement est inséré, les enregistrements seront ajoutés séquentiellement à la position suivante du nœud d'index actuel. Lorsqu'une page est pleine, une nouvelle page. sera automatiquement ouvert. Si vous utilisez une clé primaire non auto-croissante (telle qu'un numéro d'identification ou un numéro d'étudiant, etc.), puisque la valeur de la clé primaire insérée à chaque fois est approximativement aléatoire, chaque nouvel enregistrement doit être inséré quelque part au milieu de la clé primaire. page d'index existante, les opérations de déplacement et de pagination provoquaient une grande fragmentation et aboutissaient à une structure d'index qui n'était pas assez compacte. Par la suite, OPTIMIZE TABLE (optimiser la table) a dû être utilisée pour reconstruire la table et optimiser les pages remplies.
"Atomicité": Il est implémenté à l'aide du journal d'annulation. Si une erreur se produit lors de l'exécution de la transaction ou si l'utilisateur exécute une restauration, le système renvoie l'état du démarrage de la transaction via le journal d'annulation.
"Persistance" : utilisez le journal redo pour y parvenir. Tant que le journal redo est persistant, lorsque le système tombe en panne, les données peuvent être récupérées via le journal redo.
"Isolement" : les transactions sont isolées les unes des autres grâce à des verrous et MVCC.
« Cohérence » : obtenez la cohérence grâce à la restauration, à la récupération et à l'isolement dans des situations simultanées.
Moteur de stockage InnoDB : Les nœuds feuilles de l'index de l'arborescence B+ enregistrent les données elles-mêmes
Moteur de stockage MyISAM : Les nœuds feuilles de l'index de l'arborescence B+ enregistrent l'adresse physique des données ; InnoDB, son fichier de données lui-même est constitué de fichiers d'index, par rapport à MyISAM, les fichiers d'index et les fichiers de données sont séparés. Le fichier de données de la table lui-même est une structure d'index organisée par B+Tree. Le champ de données de nœud de l'arborescence enregistre des enregistrements de données complets. La clé de cet index est data.La clé primaire de la table, donc le fichier de données de la table InnoDB lui-même est l'index primaire, appelé "index clusterisé" ou index clusterisé, et le reste des index sert d'index secondaire. Le champ de données de l'index secondaire stocke la valeur de la clé primaire de l'enregistrement correspondant au lieu de l'adresse, ceci est également différent de MyISAM.
Le nœud feuille de l'index de clé primaire stocke la ligne entière de données. Dans InnoDB, l'index de clé primaire est également appelé index clusterisé.
Le contenu des nœuds feuilles dans les index de clé non primaire est la valeur de la clé primaire. Dans InnoDB, les index de clé non primaire sont également appelés index secondaires.
Utilisez la correspondance floue gauche ou gauche sur l'index : c'est-à-dire comme %xx ou comme %xx%. Les deux méthodes entraîneront un échec de l'index. La raison en est que les résultats de la requête peuvent être "Chen Lin, Zhang Lin, Zhou Lin" et ainsi de suite, nous ne savons donc pas avec quelle valeur d'index commencer à comparer, nous ne pouvons donc interroger que via une analyse complète de la table.
Utiliser des fonctions pour les index/calculer des expressions pour les index : étant donné que l'index enregistre la valeur d'origine du champ d'index, et non la valeur calculée par la fonction, il n'y a naturellement aucun moyen d'utiliser l'index.
Conversion de type implicite pour l'index : équivalent à l'utilisation d'une nouvelle fonction
La signification de OR dans la clause WHERE est qu'une seule des deux conditions est satisfaite, il est donc inutile qu'une seule colonne conditionnelle soit une colonne d'index Oui, tant que la colonne conditionnelle n'est pas une colonne d'index, une analyse complète de la table sera effectuée.
Arrêter l'expansion (non recommandé)
Plan de migration à double écriture : concevez le plan de structure de table étendue, puis implémentez la double écriture pour la base de données unique et la sous-base de données. Après avoir observé pendant une semaine cela. Il n'y a aucun problème, fermez la base de données unique. Observez le trafic de lecture pendant un moment. Une fois qu'il reste stable, fermez le trafic d'écriture de la base de données unique et passez en douceur à la sous-base de données et à la sous-table.
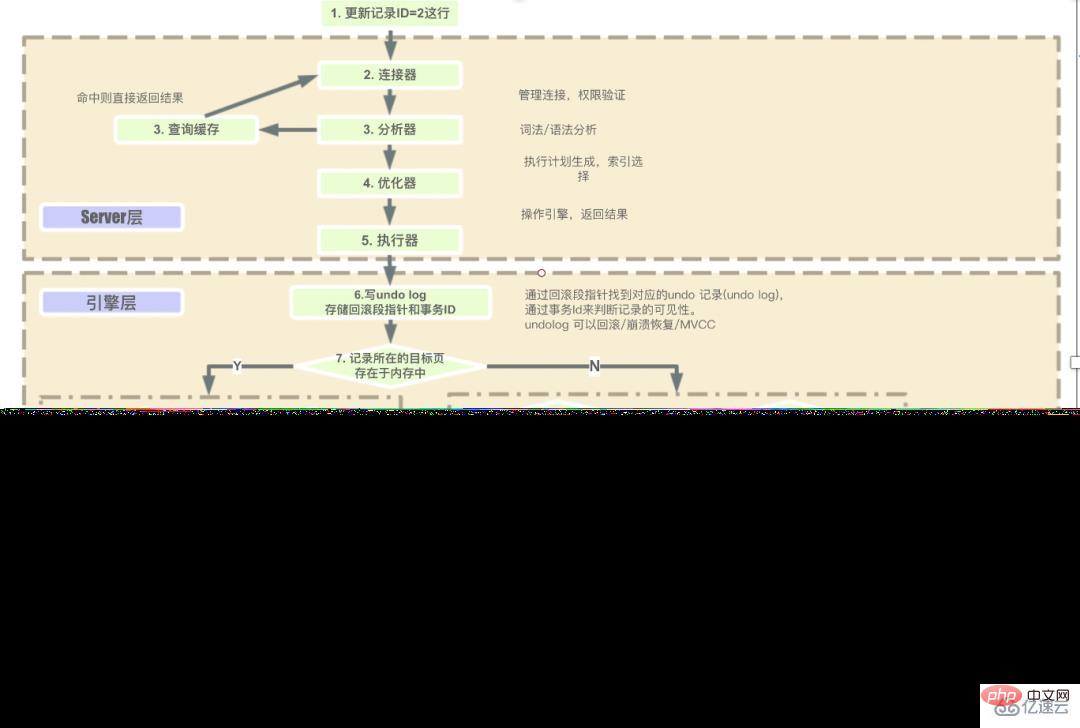
Les étapes permettant à la couche serveur d'exécuter SQL en séquence sont :
Demande du client -> Connecteur (vérifier l'identité de l'utilisateur, accorder des autorisations) -> , S'il n'existe pas, les opérations suivantes seront effectuées) -> Analyseur (opérations d'analyse lexicale et d'analyse syntaxique sur SQL) -> Optimiseur (sélectionne principalement la méthode de plan d'exécution optimale pour exécuter l'optimisation SQL) -> Il vérifiera d'abord si l'utilisateur dispose de l'autorisation d'exécution avant d'utiliser l'interface fournie par ce moteur) -> Accédez à la couche moteur pour obtenir le retour des données (si le cache des requêtes est activé, les résultats de la requête seront mis en cache).
MySQL allouera une mémoire (sort_buffer) pour chaque thread pour le tri. La taille de la mémoire est sort_buffer_size.
Si la quantité de données à trier est inférieure à sort_buffer_size, le tri sera effectué en mémoire.
Si la quantité de données triées est importante et que la mémoire ne peut pas stocker autant de données, des fichiers temporaires sur le disque seront utilisés pour faciliter le tri, également appelé tri externe.
Lors de l'utilisation du tri externe, MySQL le divisera en plusieurs fichiers temporaires distincts pour stocker les données triées, puis fusionnera ces fichiers en un seul gros fichier.
MVCC (Multiversion Concurrency Control) est un moyen de conserver plusieurs versions des mêmes données, réalisant ainsi un contrôle de concurrence. Lors de l'interrogation, recherchez les données de la version correspondante via la vue de lecture et la chaîne de versions.
Fonction : Améliorer les performances de concurrence. Pour les scénarios à forte concurrence, MVCC est moins coûteux que les verrous au niveau des lignes.
L'implémentation de MVCC repose sur la chaîne de versions, qui est implémentée via trois champs cachés de la table.
1) DB_TRX_ID : identifiant de transaction actuel, la séquence temporelle de la transaction est jugée par la taille de l'identifiant de transaction.
2) DB_ROLL_PRT : Le pointeur de restauration pointe vers la version précédente de l'enregistrement de ligne actuel. Grâce à ce pointeur, plusieurs versions des données sont connectées ensemble pour former une chaîne de versions de journal d'annulation.
3) DB_ROLL_ID : Clé primaire Si la table de données n'a pas de clé primaire, InnoDB générera automatiquement une clé primaire.
Tant que redolog et binlog garantissent les disques persistants, le mécanisme d'écriture de binlog peut assurer la récupération des données après un redémarrage anormal de MySQL.
redolog garantit que les données perdues peuvent être refaites après une exception système, et binlog archive les données pour garantir que les données perdues peuvent être récupérées.
Écrivez redolog avant l'exécution de la transaction. Pendant l'exécution de la transaction, le journal est d'abord écrit dans le cache binlog Lorsque la transaction est soumise, le cache binlog est écrit dans le fichier binlog.
Une fois l'élément de données supprimé, InnoDB marque la page A comme réutilisable
Qu'en est-il de la commande delete pour supprimer les données de la table entière ? En conséquence, toutes les pages de données seront marquées comme réutilisables. Mais sur le disque, le fichier ne diminue pas.
Les tables ayant subi un grand nombre d'ajouts, de suppressions et de modifications peuvent présenter des trous. Ces trous prennent également de la place, donc si ces trous peuvent être supprimés, l'objectif de réduire l'espace de la table peut être atteint.
Reconstruire la table peut atteindre cet objectif. Vous pouvez utiliser la commande alter table A engine=InnoDB pour reconstruire la table.
Le journal binlog au format de ligne enregistre l'identifiant de clé primaire de la ligne d'opération et la valeur réelle de chaque champ, il n'y aura donc aucune incohérence dans les données d'opération primaires et de sauvegarde. .
instruction : l'instruction SQL source enregistrée
mixte : les deux premiers sont mélangés, pourquoi avez-vous besoin d'un fichier au format mixte Car certains binlogs au format instruction peuvent provoquer une incohérence entre primaire et secondaire, donc format de ligne ? est utilisé. Mais l’inconvénient du format ligne est qu’il prend beaucoup de place. MySQL a pris un compromis. MySQL déterminera lui-même si cette instruction SQL peut provoquer une incohérence entre les serveurs principal et secondaire. Si possible, il utilisera le format de ligne, sinon il utilisera le format d'instruction.
Principe 1 : L'unité de base du verrouillage est le verrouillage par clé suivante, et le verrouillage par clé suivante est l'intervalle d'ouverture avant et de fermeture arrière.
Principe 2 : Seuls les objets accédés pendant le processus de recherche seront verrouillés
Optimisation 1 : Pour des requêtes équivalentes sur l'index, lors du verrouillage d'un index unique, le verrouillage de la touche suivante dégénère en verrouillage de ligne.
Optimisation 2 : Pour les requêtes équivalentes sur l'index, lors d'un parcours vers la droite et que la dernière valeur ne remplit pas la condition d'équivalence, le verrou de la touche suivante dégénère en un verrou à espacement
Un bug : sur le La plage d'index unique interroge l'accès jusqu'à la première valeur qui ne remplit pas la condition.
« Lecture sale » : la lecture sale fait référence à la lecture de données non validées provenant d'autres transactions. La désengagement signifie que les données peuvent être annulées, ce qui signifie qu'elles ne peuvent finalement pas être enregistrées dans la base de données, c'est-à-dire qu'elles peuvent être annulées. n’existe pas de données. La lecture de données qui pourraient ne pas exister à terme est appelée lecture sale.
« Lecture non répétable » : La lecture non répétable fait référence à la situation dans laquelle, au sein d'une transaction, les données lues au début sont incohérentes avec le même lot de données lu à tout moment avant la fin de la transaction.
« Lecture fantôme » : la lecture fantôme ne signifie pas que les ensembles de résultats obtenus par deux lectures sont différents. L'objectif de la lecture fantôme est que l'état des données du résultat obtenu par une certaine opération de sélection ne peut pas prendre en charge les opérations commerciales ultérieures. Pour être plus précis : sélectionnez si un certain enregistrement existe. S'il n'existe pas, préparez-vous à insérer l'enregistrement. Cependant, lors de l'exécution de l'insertion, il s'avère que l'enregistrement existe déjà et ne peut pas être inséré à ce moment. se produit.
En termes de types de verrous, il existe des verrous partagés et des verrous exclusifs.
1) Verrou partagé : également appelé verrou de lecture Lorsque l'utilisateur souhaite lire des données, un verrou partagé est ajouté aux données. Plusieurs verrous partagés peuvent être ajoutés en même temps.
2) Verrou exclusif : également appelé verrou en écriture Lorsque l'utilisateur souhaite écrire des données, un verrou exclusif est ajouté aux données. Un seul verrou exclusif peut être ajouté, et il est exclusif avec d'autres verrous exclusifs et verrous partagés. .
La granularité des verrous dépend du moteur de stockage spécifique. InnoDB implémente des verrous au niveau de la ligne, des verrous au niveau de la page et des verrous au niveau de la table.
Leurs frais généraux de verrouillage vont de grands à petits, et leurs capacités de concurrence vont également de grandes à petites.
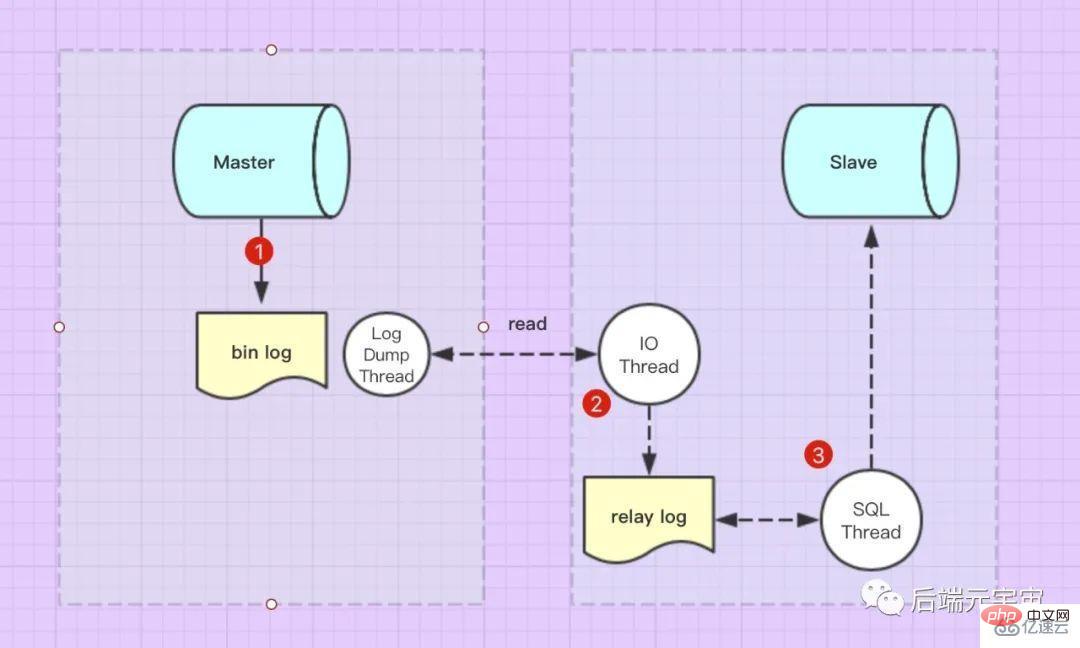
Les événements de mise à jour du Master (mise à jour, insertion, suppression) seront écrits dans bin-log dans l'ordre. Lorsque l'esclave est connecté au maître, la machine maître ouvrira le thread binlog dump pour l'esclave, et ce thread lira le journal bin-log. bin-log中。当Slave连接到Master的后,Master机器会为Slave开启binlog dump线程,该线程会去读取bin-log日志。
Slave连接到Master后,Slave库有一个I/O线程 通过请求binlog dump thread读取bin-log日志,然后写入从库的relay log日志中。
Slave还有一个 SQL线程
thread d'E/S qui lit le journal bin-log en demandant le thread de dump binlog, puis l'écrit sur l'esclave. le code du journal de relais de la bibliothèque dans le journal. thread SQL, qui surveille le contenu du journal de relais en temps réel pour les mises à jour, analyse les instructions SQL dans le fichier et les exécute dans la base de données Slave. 2. Quelles sont les méthodes de synchronisation de réplication maître-esclave Mysql ?
Réplication asynchrone :
La synchronisation maître-esclave MySQL est répliquée de manière asynchrone par défaut. Autrement dit, parmi les trois étapes ci-dessus, seule la première étape est synchrone (c'est-à-dire que Mater écrit le journal du journal bin), c'est-à-dire que la bibliothèque principale peut revenir avec succès au client après avoir écrit le journal binlog, sans attendre le journal binlog. log à transférer vers la bibliothèque esclave.Réplication synchrone :
Pour la réplication synchrone, une fois que l'hôte maître envoie l'événement à l'hôte esclave, il déclenchera une attente jusqu'à ce que tous les nœuds esclaves (s'il y a plusieurs esclaves) renvoient les informations de réussite de la réplication des données au maître.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



