


La découpe d'image fait référence à l'extraction du premier plan précis de l'image. Les méthodes automatiques actuelles ont tendance à extraire sans discernement tous les objets saillants d’une image. Dans cet article, l'auteur propose une nouvelle tâche appelée Reference Image Matting (RIM), qui fait référence à l'extraction d'un cache alpha détaillé d'un objet spécifique, qui peut le mieux correspondre à une description en langage naturel donnée. Cependant, les méthodes visuelles populaires sont limitées au niveau de segmentation, probablement en raison du manque d’ensembles de données RIM de haute qualité. Pour combler cette lacune, les auteurs ont créé RefMatte, le premier ensemble de données ambitieux à grande échelle, en concevant un moteur complet de synthèse d'images et de génération d'expressions pour générer des images synthétiques basées sur les perspectives publiques actuelles de matage de haute qualité, avec une logique de flexibilité et des propriétés diversifiées réétiquetées. .
RefMatte se compose de 230 catégories d'objets, 47 500 images, 118 749 entités de zone d'expression et 474 996 expressions, et peut être facilement étendu à l'avenir. En outre, les auteurs ont également construit un ensemble de tests réels composé de 100 images naturelles utilisant des annotations de phrases générées artificiellement pour évaluer davantage la capacité de généralisation du modèle RIM. Tout d'abord, des tâches RIM dans deux contextes, basées sur des invites et basées sur des expressions, ont été définies, puis plusieurs méthodes typiques de maillage d'images et conceptions de modèles spécifiques ont été testées. Ces résultats fournissent un aperçu empirique des limites des méthodes existantes ainsi que des solutions possibles. On pense que la nouvelle tâche RIM et le nouvel ensemble de données RefMatte ouvriront de nouvelles directions de recherche dans ce domaine et favoriseront les recherches futures.

Titre de l'article : Referring Image Matting
Adresse de l'article : https://arxiv.org/abs/2206.0514 9
Adresse du code : https://github.com/JizhiziLi/RI M
Le tapis d'image fait référence à l'extraction d'un tapis ahpha doux du premier plan dans des images naturelles, ce qui est bénéfique pour diverses applications en aval telles que la vidéoconférence, la production publicitaire et la promotion du commerce électronique. Les méthodes de maillage typiques peuvent être divisées en deux groupes : 1) les méthodes auxiliaires basées sur des entrées, telles que trimap, et 2) les méthodes de maillage automatiques qui extraient le premier plan sans aucune intervention humaine. Cependant, le premier n'est pas adapté aux scénarios d'application automatiques et le second est généralement limité à des catégories d'objets spécifiques, telles que des personnes, des animaux ou tous les objets significatifs. Comment effectuer un maillage d'image contrôlable d'objets arbitraires, c'est-à-dire extraire le maillage alpha d'un objet spécifique qui correspond le mieux à une description donnée en langage naturel, reste un problème à explorer.
Les tâches basées sur le langage telles que la segmentation d'expressions référentes (RES), la segmentation d'images référentes (RIS), la réponse visuelle aux questions (VQA) et la compréhension d'expressions référentes (REC) ont été largement explorées. De grands progrès ont été réalisés dans ces domaines sur la base de nombreux ensembles de données tels que ReferIt, Google RefExp, RefCOCO, VGPhraseCut et Cops-Ref. Par exemple, les méthodes RES visent à segmenter des objets arbitraires indiqués par des descriptions en langage naturel. Cependant, les masques obtenus sont limités à des niveaux de segmentation sans détails fins en raison des images à faible résolution et des annotations grossières des masques dans l'ensemble de données. Par conséquent, il est peu probable qu’ils soient utilisés dans des scènes nécessitant un maillage alpha détaillé des objets au premier plan.

Pour combler cette lacune, l'auteur propose une nouvelle tâche appelée "Referring Image Matting (RIM)" dans cet article. RIM fait référence à l'extraction d'objets spécifiques au premier plan dans une image qui correspondent le mieux à une description en langage naturel donnée, ainsi qu'à un maillage alpha détaillé et de haute qualité. Différent des tâches résolues par les deux méthodes de maillage ci-dessus, RIM vise un maillage d'image contrôlable d'objets arbitraires dans l'image indiquée par la description linguistique. Il revêt une importance pratique dans le domaine des applications industrielles et ouvre de nouvelles directions de recherche pour le monde universitaire.
Pour promouvoir la recherche RIM, l'auteur a établi le premier ensemble de données nommé RefMatte, qui comprend 230 catégories d'objets, 47 500 images et 118 749 entités de zone d'expression ainsi que le cache alpha de haute qualité correspondant et 474 996 compositions d'expression.
Plus précisément, afin de créer cet ensemble de données, l'auteur a d'abord revisité de nombreux ensembles de données de tapis publics populaires, tels que AM-2k, P3M-10k, AIM-500, SIM, et a étiqueté manuellement chaque objet pour l'examiner attentivement. Les auteurs utilisent également plusieurs modèles pré-entraînés basés sur l’apprentissage profond pour générer divers attributs pour chaque entité, tels que le sexe humain, l’âge et le type de vêtements. Les auteurs conçoivent ensuite un moteur complet de génération de compositions et d’expressions pour générer des images composites avec des positions absolues et relatives raisonnables, en tenant compte d’autres objets de premier plan. Enfin, l'auteur propose plusieurs formes logiques d'expression qui exploitent de riches attributs visuels pour générer différentes descriptions linguistiques. En outre, les auteurs proposent un ensemble de tests réels RefMatte-RW100, qui contient 100 images contenant différents objets et expressions annotées humaines, pour évaluer la capacité de généralisation de la méthode RIM. L'image ci-dessus montre quelques exemples.
Pour fournir une évaluation juste et complète des méthodes de pointe dans des tâches connexes, les auteurs les comparent sur RefMatte dans deux paramètres différents, à savoir un paramètre basé sur des indices et un paramètre basé sur des expressions, sous la forme de descriptions linguistiques. Étant donné que les méthodes représentatives sont spécifiquement conçues pour les tâches de segmentation, il existe encore une lacune lors de leur application directe aux tâches RIM.
Pour résoudre ce problème, l'auteur a proposé deux stratégies pour les personnaliser pour RIM, à savoir 1) soigneusement conçu un en-tête de tapis léger nommé CLIPmat au-dessus de CLIPSeg pour générer des résultats de tapis alpha de haute qualité, tout en conservant son aspect de bout en bout. pipeline pouvant être entraîné ; 2) Plusieurs méthodes de matage grossières distinctes basées sur des images sont fournies en tant que post-raffineurs pour améliorer encore les résultats de segmentation/matage. Des résultats expérimentaux approfondis 1) démontrent la valeur de l'ensemble de données RefMatte proposé pour la recherche sur les tâches RIM, 2) identifient le rôle important de la forme de description du langage 3) valident l'efficacité de la stratégie de personnalisation proposée ;
Les principaux apports de cette étude sont triples. 1) Définir une nouvelle tâche appelée RIM, qui vise à identifier et extraire des caches alpha d'objets spécifiques de premier plan qui correspondent le mieux à une description en langage naturel donnée. 2) Établir le premier ensemble de données à grande échelle RefMatte, composé de 47 500 images et de 118 749 régions d'expression ; entités, avec un matage alpha de haute qualité et une expression riche ; 3) Des méthodes représentatives de pointe ont été comparées dans deux contextes différents à l'aide de deux stratégies adaptées à RIM pour RefMatte Tested et ont permis d'obtenir des informations utiles.

Dans cette section, le pipeline pour construire RefMatte (Section 3.1 et Section 3.2) ainsi que les paramètres de la tâche (Section 3.3) et les statistiques de l'ensemble de données (Section 3.5) seront présentés. . L'image ci-dessus montre quelques exemples de RefMatte. De plus, les auteurs construisent un ensemble de tests réels composé de 100 images naturelles annotées avec des descriptions en langage riche étiquetées manuellement (Section 3.4).
Afin de préparer suffisamment d'entités de matage de haute qualité pour aider à construire l'ensemble de données RefMatte, l'auteur revisite les ensembles de données de matage actuellement disponibles pour filtrer les prospects qui répondent aux exigences. Toutes les entités candidates sont ensuite étiquetées manuellement avec leurs catégories et leurs attributs sont annotés à l'aide de plusieurs modèles pré-entraînés basés sur l'apprentissage profond.
Prétraitement et filtrage
En raison de la nature de la tâche de maillage d'image, toutes les entités candidates doivent être en haute résolution et avoir des détails clairs et fins dans le maillage alpha. De plus, les données doivent être accessibles au public via des licences ouvertes et sans problèmes de confidentialité pour faciliter les recherches futures. Pour ces besoins, les auteurs ont utilisé toutes les images de premier plan d'AM-2k, P3M-10k et AIM-500. Plus précisément, pour P3M-10k, les auteurs filtrent les images comportant plus de deux instances de premier plan collantes pour garantir que chaque entité est associée à une seule instance de premier plan. Pour d'autres ensembles de données disponibles, tels que SIM, DIM et HATT, les auteurs filtrent les images de premier plan comportant des visages identifiables parmi les instances humaines. Les auteurs filtrent également les images de premier plan qui sont de faible résolution ou dont le revêtement alpha est de mauvaise qualité. Le nombre total final d'entités était de 13 187. Pour les images d'arrière-plan utilisées dans les étapes de synthèse ultérieures, les auteurs ont sélectionné toutes les images dans BG-20k.
Annoter les noms de catégorie des entités
Étant donné que les méthodes de découpe automatique précédentes avaient tendance à extraire tous les objets saillants du premier plan de l'image, elles ne fournissaient pas de noms (de catégorie) spécifiques pour chaque entité. Cependant, pour les tâches RIM, le nom de l'entité est requis pour la décrire. Les auteurs ont attribué à chaque entité un nom de catégorie d'entrée de gamme, qui représente le nom le plus couramment utilisé pour une entité spécifique. Ici, une stratégie semi-automatique est adoptée. Plus précisément, les auteurs utilisent un détecteur Mask RCNN avec un squelette ResNet-50-FPN pour détecter et étiqueter automatiquement le nom de classe de chaque instance de premier plan, puis les inspecter et les corriger manuellement. RefMatte compte un total de 230 catégories. De plus, les auteurs utilisent WordNet pour générer des synonymes pour chaque nom de catégorie afin d'améliorer la diversité. Les auteurs ont vérifié manuellement les synonymes et remplacé certains d’entre eux par des synonymes plus raisonnables.
Annoter les attributs des entités
Afin de garantir que toutes les entités possèdent de riches attributs visuels pour soutenir la formation d'expressions riches, l'auteur a annoté toutes les entités avec divers attributs tels que la couleur, le sexe, l'âge et le type de vêtement humain. entités. Les auteurs emploient également une stratégie semi-automatique pour générer de telles propriétés. Pour générer des couleurs, les auteurs regroupent toutes les valeurs de pixels de l'image de premier plan, recherchent les valeurs les plus courantes et les associent à des couleurs spécifiques dans webcolors. Pour le sexe et l’âge, les auteurs utilisent des modèles pré-entraînés. Faites preuve de bon sens pour définir des groupes d’âge en fonction de l’âge prévu. Pour les types de vêtements, l'auteur utilise un modèle pré-entraîné. De plus, inspirés par la classification de premier plan, les auteurs ajoutent des attributs saillants ou insignifiants et transparents ou opaques à toutes les entités, car ces attributs sont également importants dans les tâches de matage d'image. En fin de compte, chaque entité possède au moins 3 attributs, et les entités humaines ont au moins 6 attributs.
Sur la base des entités de découpe collectées dans la section précédente, l'auteur a proposé un moteur de synthèse d'image et un moteur de génération d'expression pour construire l'ensemble de données RefMatte. Comment organiser différentes entités pour former des images synthétiques raisonnables, et en même temps générer des expressions sémantiquement claires, grammaticalement correctes, riches et fantaisistes pour décrire les entités dans ces images synthétiques est la clé de la construction de RefMatte, et c'est également un défi. À cette fin, les auteurs définissent six relations de position pour organiser différentes entités dans des images synthétiques et utilisent différentes formes logiques pour produire des expressions appropriées.
Moteur de composition d'images
Afin de maintenir la haute résolution des entités tout en les disposant dans une relation de position raisonnable, l'auteur adopte deux ou trois entités pour chaque image composite. L'auteur définit six relations de position : gauche, droite, haut, bas, avant et arrière. Pour chaque relation, les images de premier plan ont d'abord été générées et composées via un mélange alpha avec l'image d'arrière-plan du BG-20k. Plus précisément, pour les relations gauche, droite, haut et bas, les auteurs veillent à ce qu'il n'y ait pas d'occlusions dans les instances de premier plan afin de préserver leurs détails. Pour les relations avant-après, l'occlusion entre les instances de premier plan est simulée en ajustant leurs positions relatives. Les auteurs préparent un sac de mots candidats pour représenter chaque relation.
Moteur de génération d'expression
Afin de fournir des méthodes d'expression riches pour les entités dans des images synthétiques, l'auteur définit trois méthodes d'expression pour chaque entité du point de vue des différentes formes logiques définies, où 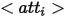 représente les attributs et
représente les attributs et 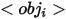 représente les catégories Le nom ,
représente les catégories Le nom , 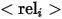 représente la relation entre l'entité de référence et l'entité associée. Des exemples des trois expressions spécifiques sont présentés dans (a), (b) et (c) ci-dessus.
représente la relation entre l'entité de référence et l'entité associée. Des exemples des trois expressions spécifiques sont présentés dans (a), (b) et (c) ci-dessus.
Répartition de l'ensemble de données
L'ensemble de données contient un total de 13 187 entités cartographiques, dont 11 799 sont utilisées pour créer l'ensemble d'entraînement et 1 388 sont utilisées pour l'ensemble de test. Cependant, les catégories des ensembles de formation et de test ne sont pas équilibrées car la plupart des entités appartiennent à la catégorie humaine ou animale. Plus précisément, parmi les 11 799 entités de l’ensemble de formation, il y a 9 186 humains, 1 800 animaux et 813 objets. Dans l’ensemble de tests de 1 388 entités, il y a 977 humains, 200 animaux et 211 objets. Pour équilibrer les catégories, les auteurs ont répliqué des entités pour obtenir un rapport humain:animal:objet de 5:1:1. Par conséquent, il y a 10 550 humains, 2 110 animaux et 2 110 objets dans l’ensemble d’apprentissage, et 1 055 humains, 211 animaux et 211 objets dans l’ensemble de test.
Pour générer des images pour RefMatte, les auteurs sélectionnent un ensemble de 5 humains, 1 animal et 1 objet à partir d'une formation ou d'un test et les introduisent dans le moteur de synthèse d'images. Pour chaque groupe de la formation ou du test, les auteurs ont généré 20 images pour former l’ensemble de formation et 10 images pour former l’ensemble de test. Le rapport de la relation gauche/droite:haut/bas:avant/arrière est fixé à 7:2:1. Le nombre d'entités dans chaque image est défini sur 2 ou 3. Pour le contexte, les auteurs choisissent toujours 2 entités afin de maintenir une haute résolution pour chaque entité. Après ce processus, il existe 42 200 images d’entraînement et 2 110 images de test. Pour améliorer encore la diversité des combinaisons d'entités, nous sélectionnons au hasard les entités et les relations parmi tous les candidats pour former 2 800 images de formation supplémentaires et 390 images de test. Enfin, il y a 45 000 images synthétiques dans l'ensemble d'entraînement et 2 500 images dans l'ensemble de test.
Paramètre de tâche
Pour comparer l'approche RIM étant donné différentes formes de description du langage, l'auteur a défini deux paramètres dans RefMatte :
Paramètre basé sur une invite : la description textuelle dans ce paramètre est une invite, qui est l'entrée -nom de catégorie de niveau de l'entité. Par exemple, les invites dans l'image ci-dessus sont fleur, humain et alpaga
Paramètre basé sur l'expression : dans ce paramètre, la description textuelle est l'expression générée dans la section précédente, sélectionnée parmi celles de base ; expressions, expressions de position absolue et expressions de position relative. Quelques exemples peuvent également être vus dans l’image ci-dessus.

Étant donné que RefMatte est construit sur des images synthétiques, il peut y avoir des écarts de domaine entre elles et les images du monde réel. Afin d'étudier la capacité de généralisation du modèle RIM formé sur celui-ci aux images du monde réel, l'auteur a en outre établi un ensemble de tests du monde réel nommé RefMatte-RW100, composé de 100 images haute résolution du monde réel, chaque image. il y a 2 à 3 entités dans . Les auteurs annotent ensuite leurs expressions en suivant les trois mêmes paramètres de la section 3.2. De plus, l'auteur a ajouté une expression libre dans l'annotation. Pour les balises de découpe alpha de haute qualité, l'auteur les génère à l'aide d'un logiciel de retouche d'image tel qu'Adobe Photoshop et GIMP. Quelques exemples de RefMatte-RW100 sont présentés ci-dessus.
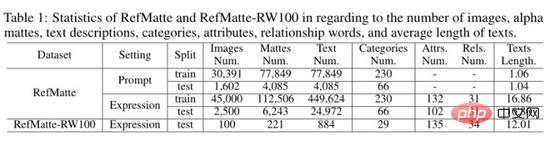
L'auteur a calculé les statistiques de l'ensemble de données RefMatte et de l'ensemble de test RefMatte-RW100 comme indiqué dans le tableau ci-dessus. Pour le paramètre basé sur des invites, étant donné que les descriptions textuelles sont des noms de catégories d'entrée de gamme, les auteurs suppriment les images comportant plusieurs entités appartenant à la même catégorie pour éviter les inférences ambiguës. Par conséquent, dans ce contexte, il y a 30 391 images dans l’ensemble d’apprentissage et 1 602 images dans l’ensemble de test. Le nombre, la description textuelle, les catégories, les attributs et les relations des découpes alpha sont indiqués respectivement dans le tableau ci-dessus. Dans le paramètre basé sur des invites, la longueur moyenne du texte est d'environ 1, car il n'y a généralement qu'un seul mot par catégorie, tandis que dans le paramètre basé sur les expressions, elle est beaucoup plus grande, c'est-à-dire environ 16,8 dans RefMatte et environ 16,8 dans RefMatte-RW100. 12.

L'auteur a également généré un nuage de mots d'invites, d'attributs et de relations dans RefMatte dans l'image ci-dessus. Comme on peut le constater, l'ensemble de données comprend une grande partie d'humains et d'animaux, car ils sont très courants dans les tâches de matage d'images. Les attributs les plus courants dans RefMatte sont masculins, gris, transparents et saillants, tandis que les mots relationnels sont plus équilibrés.
En raison des différences de tâches entre RIM et RIS/RES, les résultats de l'application directe de la méthode RIS/RES à RIM ne sont pas optimistes. Pour résoudre ce problème, l'auteur propose deux stratégies pour les personnaliser pour RIM :
1) Ajout de têtes de tapis : concevoir des têtes de tapis légères au-dessus des modèles existants pour générer un tapis alpha de haute qualité tout en conservant la portabilité. Pipeline entraînable de bout en bout. . Plus précisément, l'auteur a conçu un décodeur de matage léger au-dessus de CLIPSeg, appelé CLIPMat ;
2) Utilisation du raffineur de matage : l'auteur utilise une méthode de matage distincte basée sur des images grossières comme post-raffineur pour améliorer davantage les résultats de segmentation/mattage. des méthodes ci-dessus. Plus précisément, les auteurs entraînent GFM et P3M, en saisissant des images et des images grossières comme affineurs de découpe.
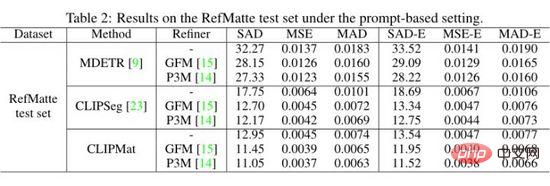
Les auteurs évaluent MDETR, CLIPSeg et CLIPMat sur un paramètre basé sur des indices sur l'ensemble de test RefMatte et montrent les résultats quantitatifs dans le tableau ci-dessus. On peut constater que par rapport à MDETR et CLIPSeg, CLIPMat fonctionne mieux, que l'affineur de découpe soit utilisé ou non. Vérifiez l'efficacité de l'ajout d'un en-tête de découpe pour personnaliser CLIPSeg pour les tâches RIM. De plus, l’utilisation de l’un ou l’autre des deux raffineurs de découpe peut encore améliorer les performances des trois méthodes.
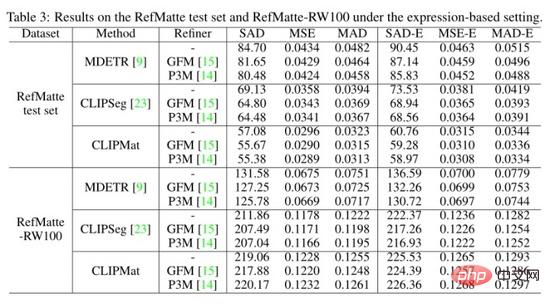
Les auteurs ont également évalué les trois méthodes sur l'ensemble de tests RefMatte et le réglage basé sur l'expression de RefMatte-RW100 et montrent les résultats quantitatifs dans le tableau ci-dessus. CLIPMat montre à nouveau une bonne capacité à conserver plus de détails sur l'ensemble de test RefMatte. Lorsqu'elles sont testées sur RefMatte-RW100, les méthodes en une étape telles que CLIPSeg et CLIPMat sont en retard par rapport à la méthode en deux étapes, à savoir MDETR, probablement en raison de la meilleure capacité des détecteurs de MDETR à comprendre la sémantique intermodale.
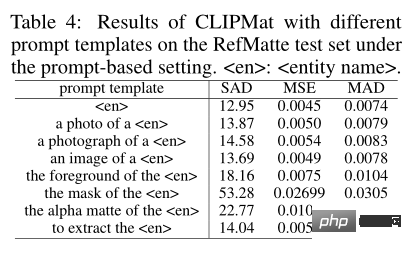
Pour étudier l'impact du formulaire de saisie rapide, les auteurs ont évalué les performances de différents modèles d'invite. En plus des modèles traditionnels utilisés, l'auteur a également ajouté d'autres modèles spécifiquement conçus pour les tâches de cache d'image, tels que le cache de premier plan/masque/alpha de
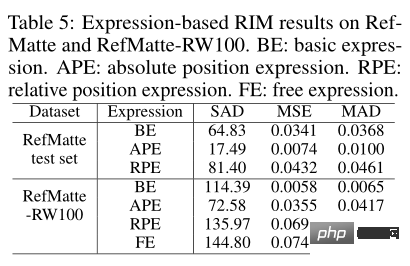
Étant donné que cet article présente différents types d'expressions dans la tâche, vous pouvez voir l'impact de chaque type sur les performances de découpe. Comme le montre le tableau ci-dessus, le modèle CLIPMat le plus performant a été testé sur l'ensemble de test RefMatte et le modèle MDETR a été testé sur RefMatte-RW100.
Dans cet article, nous proposons une nouvelle tâche appelée Reference Image Matting (RIM) et construisons un ensemble de données à grande échelle RefMatte. Les auteurs adaptent les méthodes représentatives existantes aux tâches pertinentes de RIM et mesurent leurs performances grâce à des expériences approfondies sur RefMatte. Les résultats expérimentaux de cet article fournissent des informations utiles sur la conception du modèle, l'impact des descriptions textuelles et l'écart de domaine entre les images synthétiques et réelles. La recherche RIM peut bénéficier à de nombreuses applications pratiques telles que l’édition d’images interactives et l’interaction homme-machine. RefMatte peut faciliter la recherche dans ce domaine. Cependant, l’écart entre les domaines synthétique et réel peut entraîner une généralisation limitée aux images du monde réel.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles sont les fonctions couramment utilisées d'informix ?
Quelles sont les fonctions couramment utilisées d'informix ?
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 Plateforme de trading quantitatif de devises numériques
Plateforme de trading quantitatif de devises numériques
 Fichier au format DAT
Fichier au format DAT
 Comment implémenter la fonction de pagination jsp
Comment implémenter la fonction de pagination jsp
 Yiouoky est-il un logiciel légal ?
Yiouoky est-il un logiciel légal ?
 Le dernier prix de la monnaie fil
Le dernier prix de la monnaie fil
 qu'est-ce qu'Internet.exe
qu'est-ce qu'Internet.exe








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



