


De nos jours, les modèles graphiques basés sur du texte produits par de grandes entreprises telles que Google et OpenAI sont le pain et le beurre des journalistes intéressants et le nectar d'une longue sécheresse pour les amateurs de mèmes. En saisissant des mots, vous pouvez générer diverses images belles ou amusantes, qui peuvent attirer l'attention des gens sans être fatiguantes ni gênantes. Par conséquent, la série DALL·E et Imagens ont les attributs essentiels de la nourriture et des vêtements et d'une sécheresse à long terme : le degré de disponibilité est limité et ce ne sont pas des avantages qui peuvent être distribués de manière illimitée à tout moment. À la mi-juin 2022, Hugging Face Company a dévoilé gratuitement la version simple et facile à utiliser de l'interface DALL·E : DALL·E Mini à tous les utilisateurs de l'ensemble du réseau. Sans surprise, cela a provoqué une autre grande vague sur divers. Sites de médias sociaux. Tendance de création.

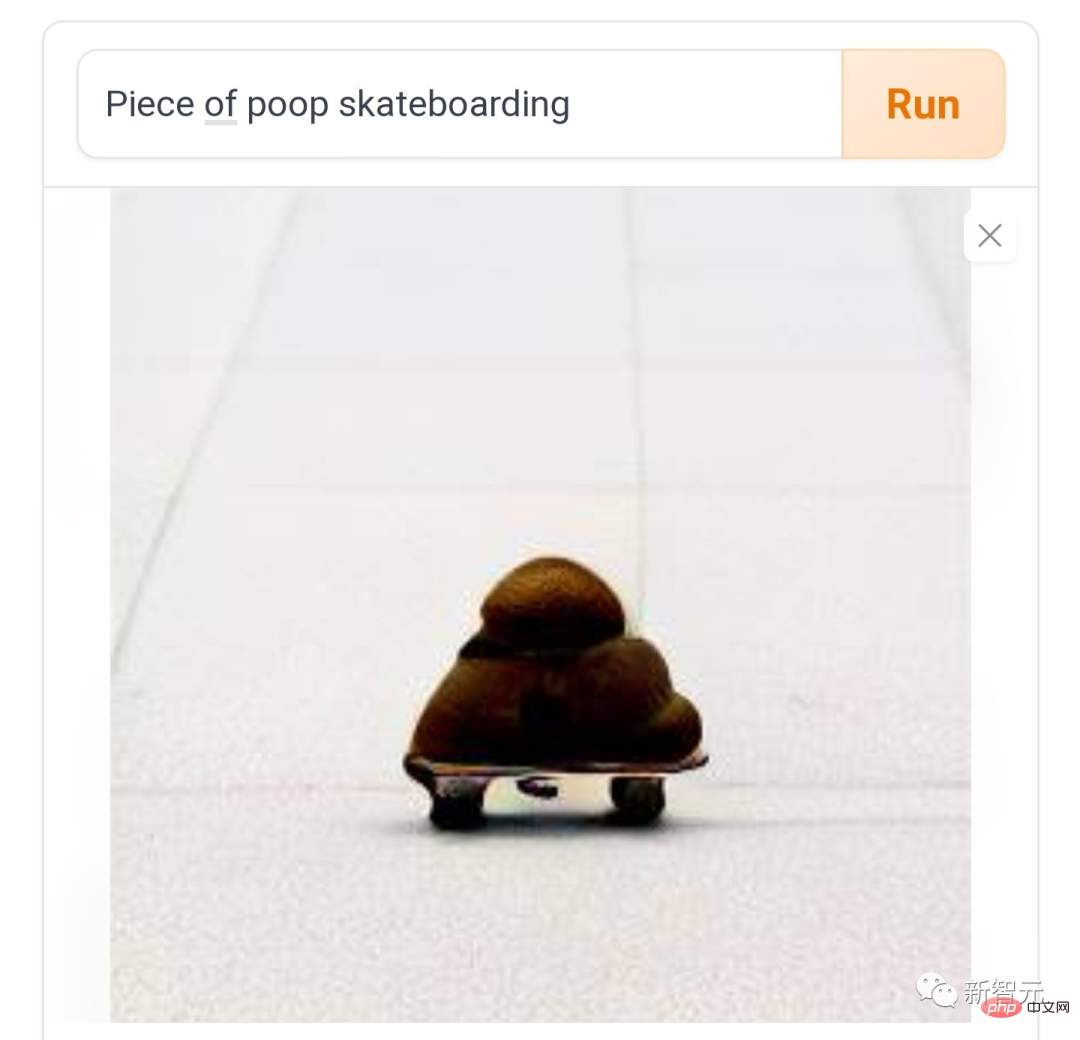
Maintenant, les gens sur divers réseaux sociaux ont déclaré : Jouer à DALL·E Mini est amusant pendant un moment, et c'est amusant de continuer à jouer, et vous pouvez' Je ne m'arrête pas du tout. Comme "caca sur un skateboard", friction et friction, comme le rythme du diable.
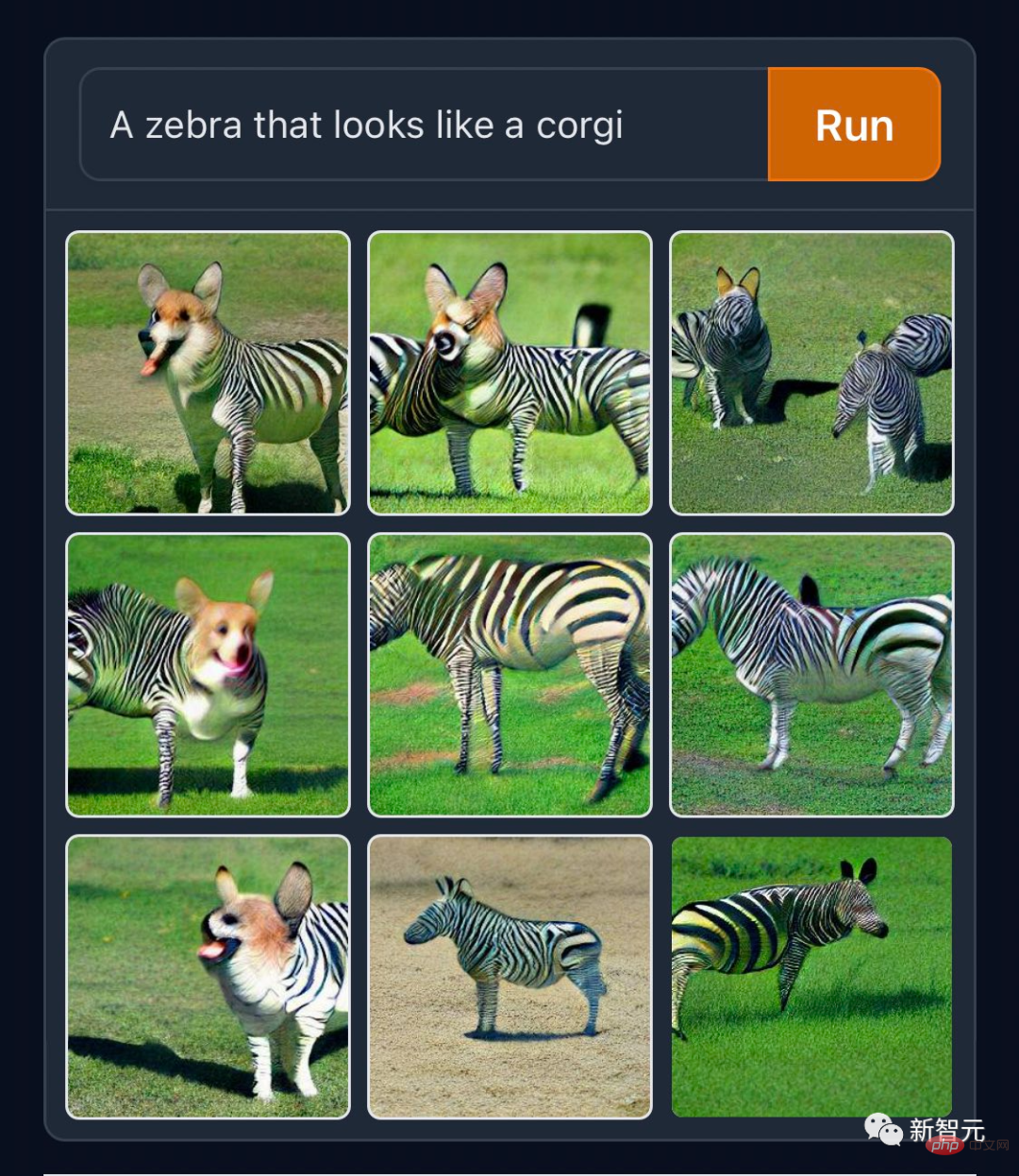
Certaines personnes aiment réaliser des « créations normales », comme le « Corgi Zebra » qui brise les frontières des espèces.
Si les anciens fonctionnaires disposaient de ces matériaux, ils n'auraient pas à travailler si dur pour inventer la girafe africaine dans la bête mythique Kirin. Les codeurs de GitHub sont fidèles à leur métier et ont publié un travail généré de "Squirrel Programming with Computers" sur le Twitter officiel.

"Godzilla's Court Sketches", je dois dire, ressemble vraiment au style de croquis des rapports de procès qui ne sont pas ouverts au public dans les journaux des pays anglophones.

"Les Care Bears braquent un dépanneur". Pourquoi l'idole du dessin animé est-elle tombée ainsi ? Est-ce la distorsion de la nature de l'ours ou la perte de moralité...
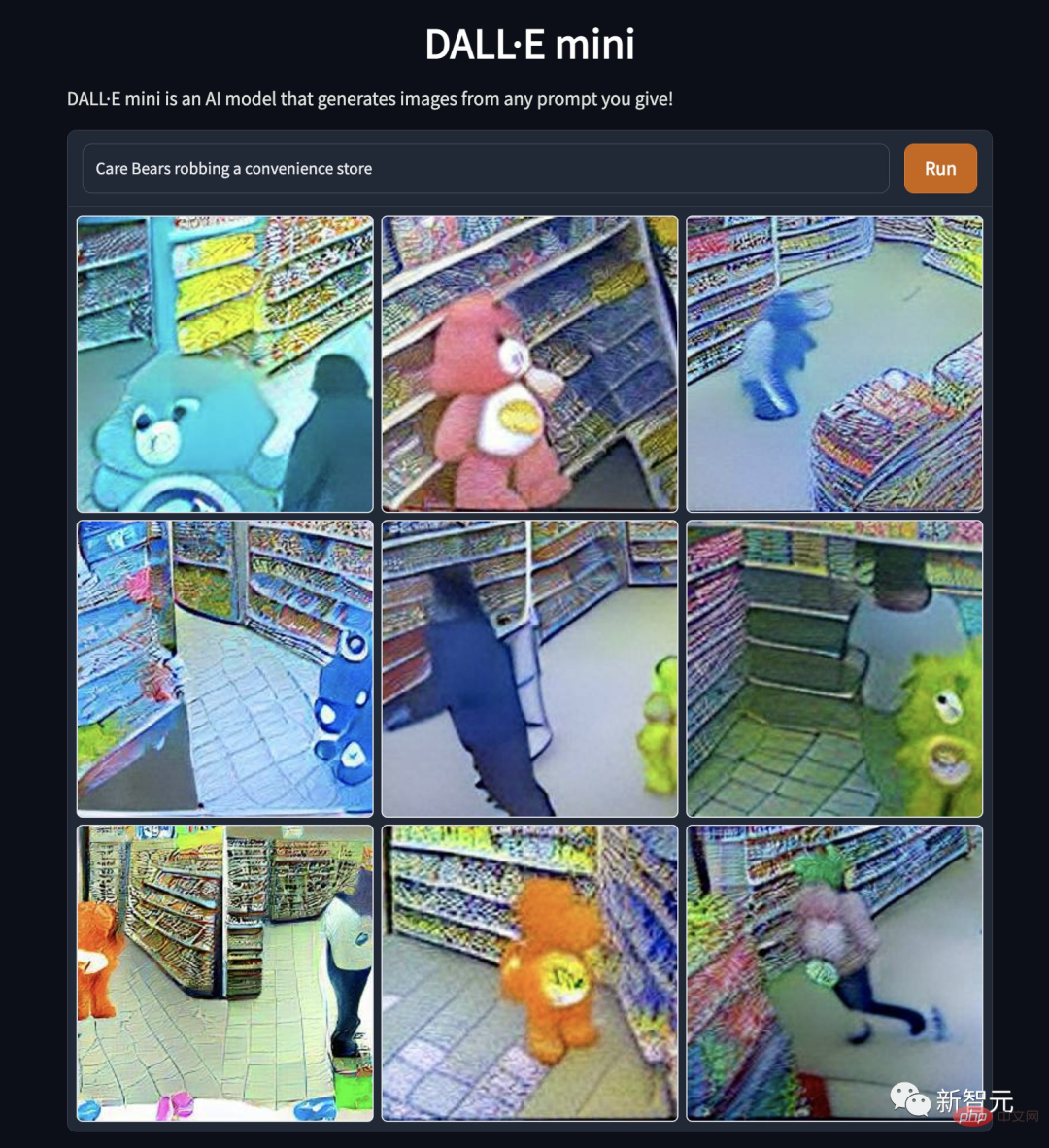
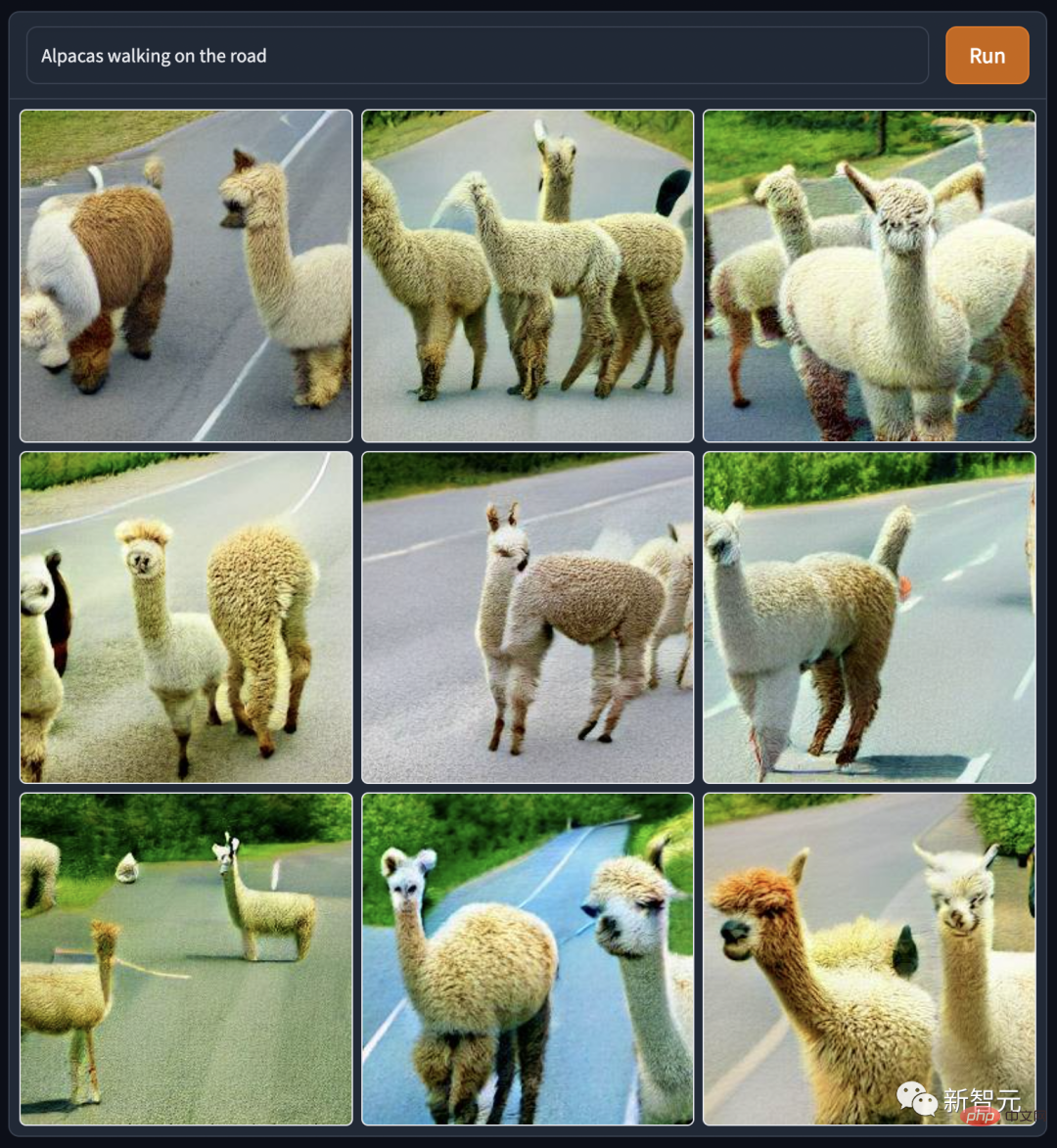
De plus, DALL·E Mini a généré "La bête mythique a été capturée marchant sur un sentier sauvage "L'image a aussi des réalisations exceptionnelles. Il s'agit "d'un petit dinosaure marchant sur un sentier sauvage, capturé par une caméra".

Il s'agit de "la marque Duolingo Parrot marchant sur le sentier sauvage, capturé par la caméra".
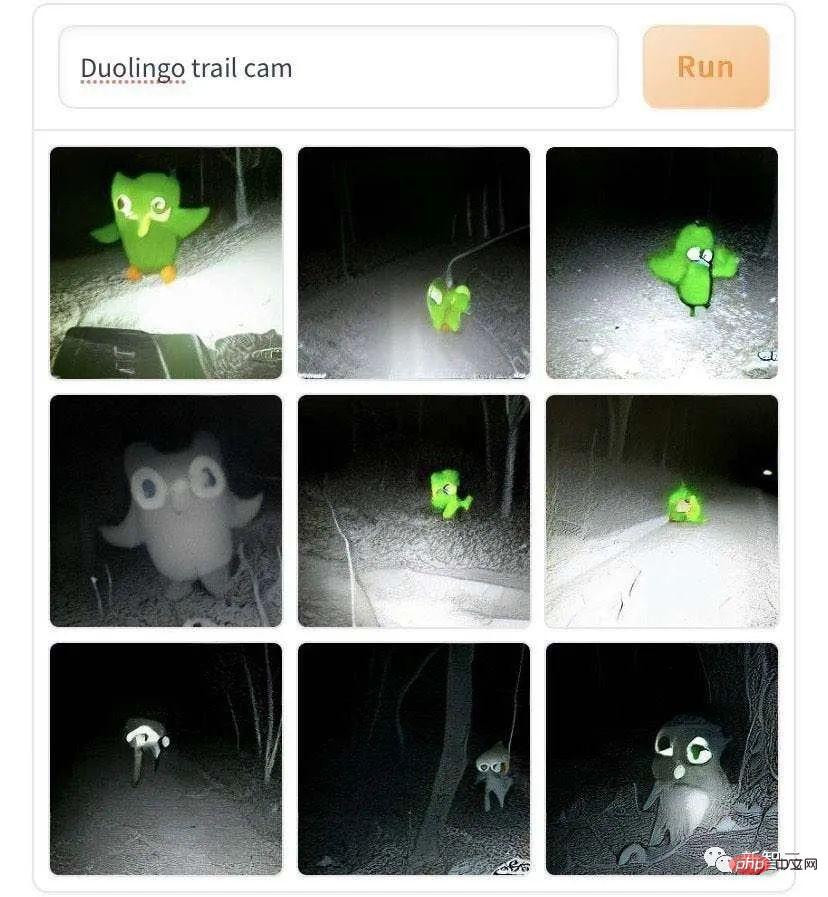
DALL·E Mini a généré ces images ambulantes de bêtes mythiques, les personnages de dos sont si solitaires et désolés. Mais il s’agit peut-être de l’effet photographique en basse lumière simulé par l’IA. Tout le monde à la rédaction l'a également imité : « Marcher sur la route sur des chevaux d'herbe et de boue », et le ton est devenu de plus en plus clair.
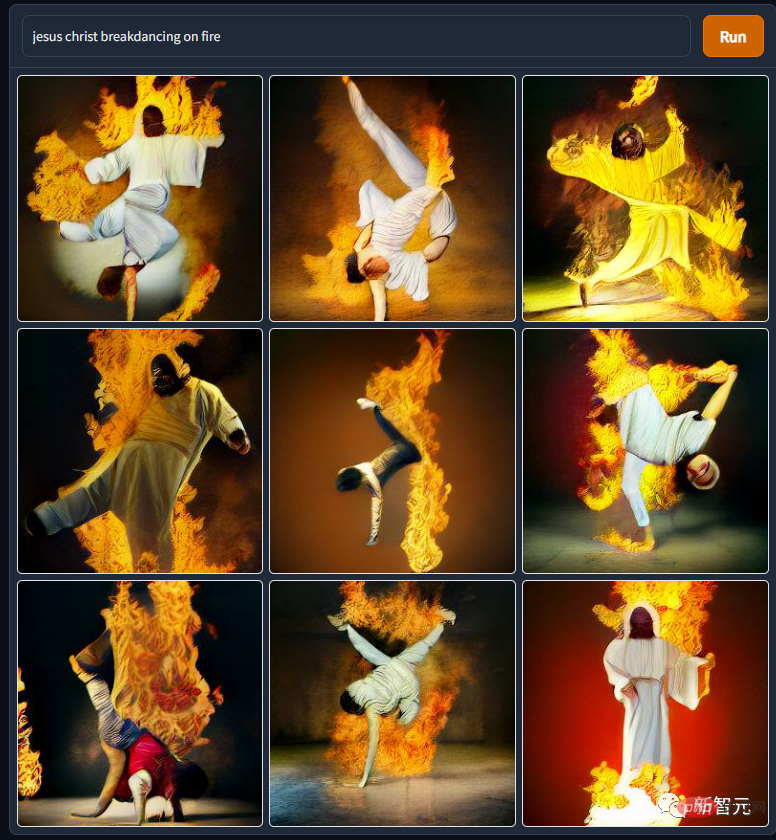
Les images de dieux et d'humains générées par DALL·E Mini ne sont pas pires que celles des bêtes mythiques. Par exemple, sur cette photo de « Jesus' Fiery Break Dance », je ne savais vraiment pas que son corps était si flexible. Il semble que les publicités « S'étirer avec le Seigneur » sur divers sites de fitness soient pour une raison.
Et ce "Rappeur Gou Ye sur le vitrail", a-t-il vraiment le style d'un vitrail d'icône d'église et d'un tableau impressionniste ?

Utiliser DALL·E Mini pour usurper des personnages de l'industrie du cinéma et de la télévision est désormais devenu une tendance. Ce qui suit est "Le baptême de R2D2" de l'univers Star Wars. Peut-être que les lois de la physique et de la chimie de l'univers Star Wars sont différentes de celles du monde réel. Les robots ne perdront pas d'électricité ni ne rouilleront après avoir été exposés à l'eau.

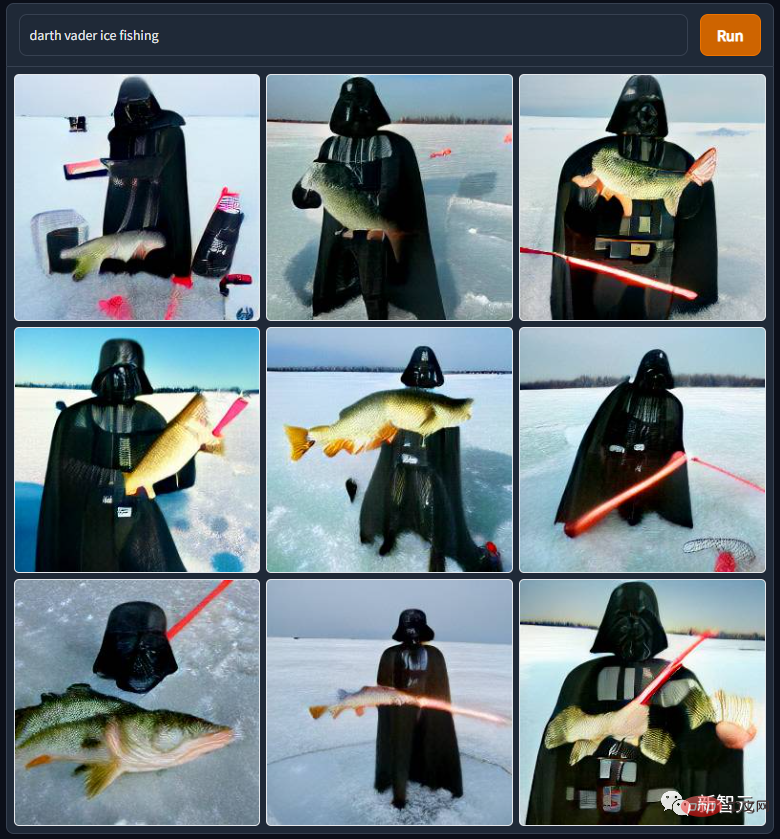
"Darth Vader Ice Fishing" est aussi issu de l'univers Star Wars. M. Dark Vador est vraiment misérable. Il a été piraté par son maître et contraint de prendre un bain dans la lave d'un volcan. Après être devenu handicapé, il a été pourchassé par son propre fils. Après avoir utilisé un ventilateur pour maîtriser la Force, le handicapé a été réduit à terre. pour rivaliser avec les Esquimaux pour les affaires...
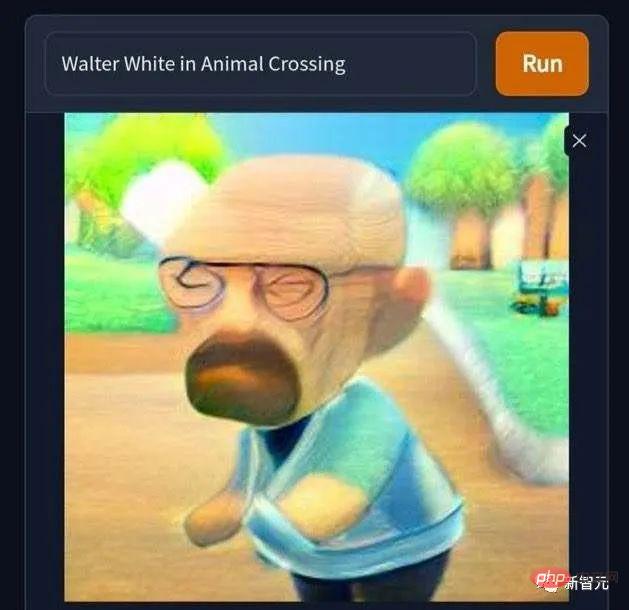
Il y a aussi cette photo de "Walter White entre accidentellement dans le monde d'Animal Crossing". Le baron de la drogue chauve, solitaire et désespéré devient soudain mignon. . C'est dommage que Nintendo n'ait pas vraiment lancé Animal Crossing dans les années 2000, sinon j'aurais trouvé que gagner de l'argent grâce aux transactions virtuelles dans Animal Crossing était beaucoup plus simple et sans problème que de travailler dur pour créer un physique en forme de glace bleue. des biens pour subvenir aux besoins de ma famille. Chantons "Rejeter la pornographie~rejeter les drogues~rejeter la pornographie, les jeux de hasard et les drogues~".
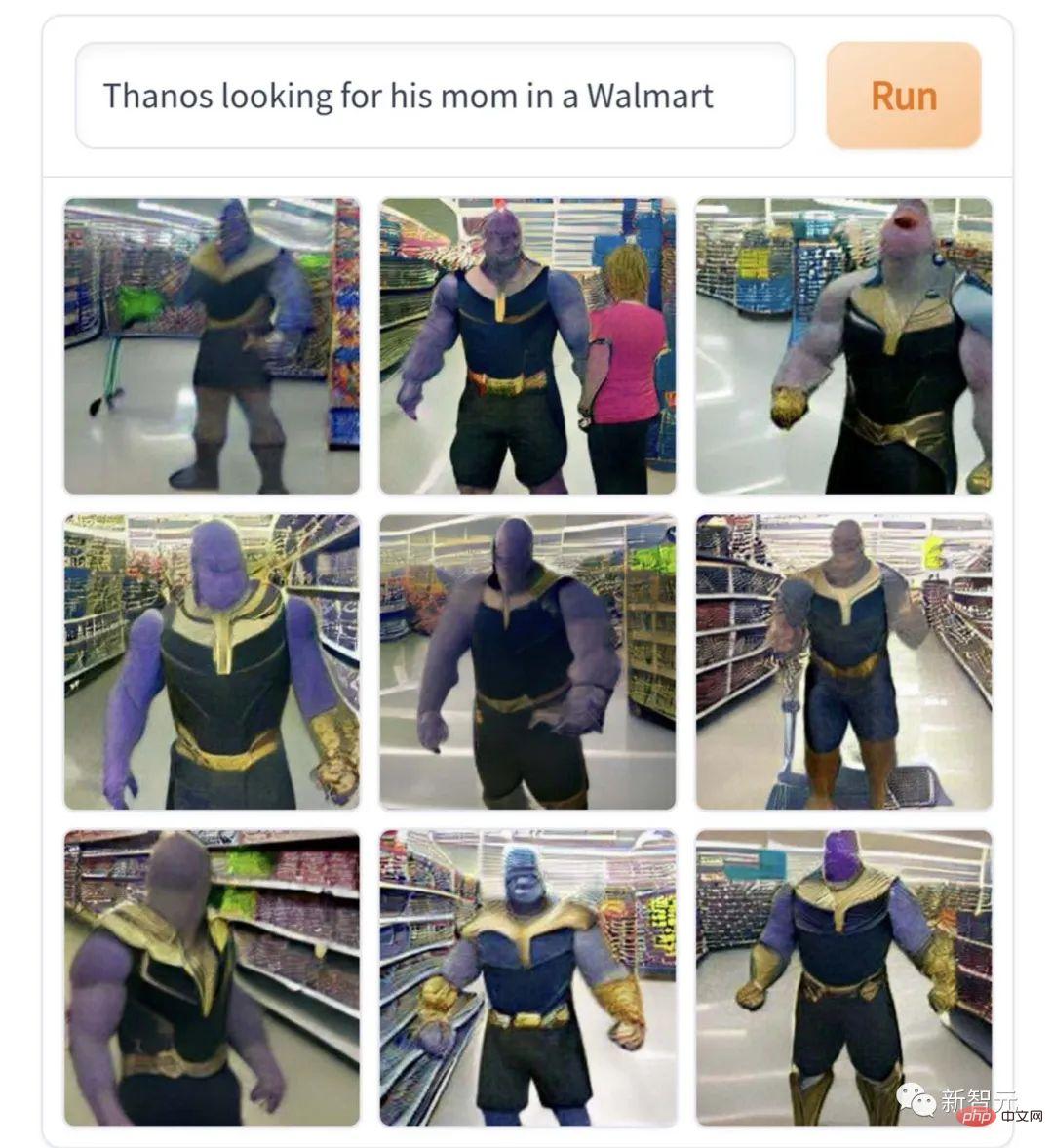
Cette image de "Thanos cherchant sa mère au supermarché" correspond vraiment au cœur du personnage et est une interprétation très professionnelle du drame. Si vous êtes malheureux, vous vous lancerez dans un génocide, et si vous n'êtes pas d'accord, vous détruirez l'univers. C'est le personnage d'un bébé géant qui pleurera amèrement lorsqu'il ne retrouvera pas sa mère.
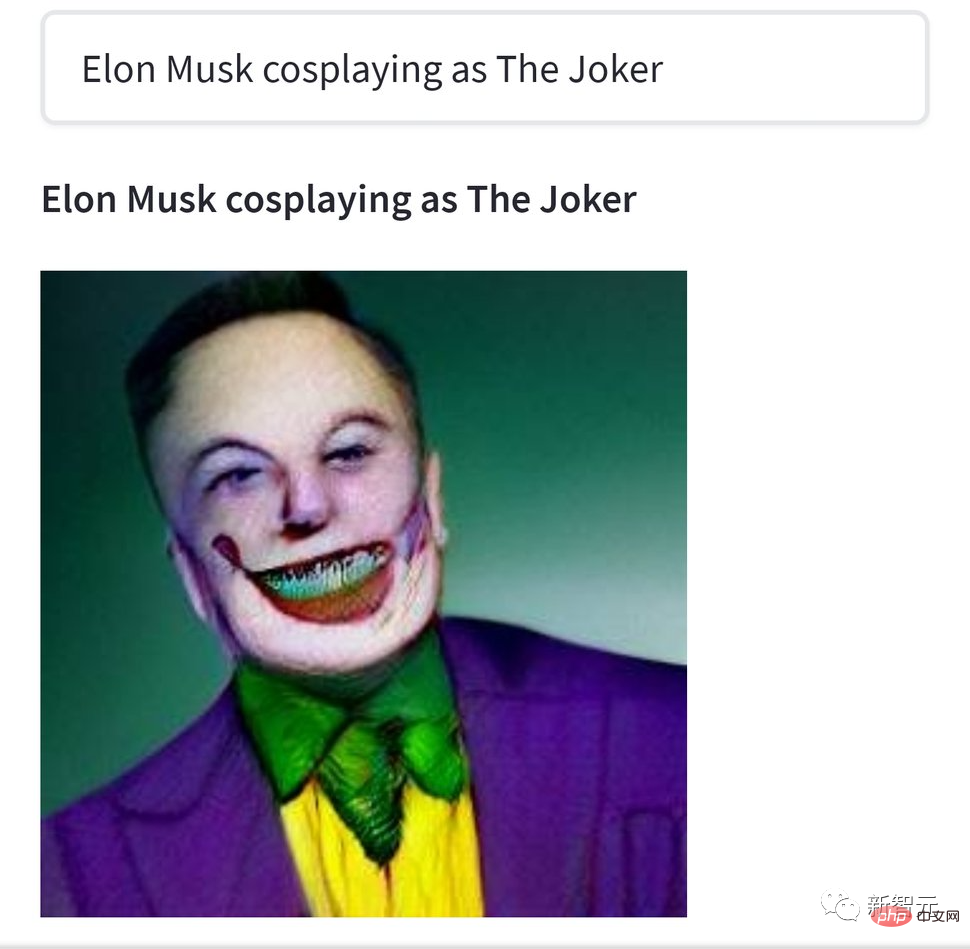
Cependant, ces créations ont toutes un goût léger Par rapport aux œuvres des passionnés de Cthulhu au goût prononcé, elles sont tout simplement aqueuses. Par exemple, cette image « Elon Musk joue le clown craquelé » fait un peu peur.
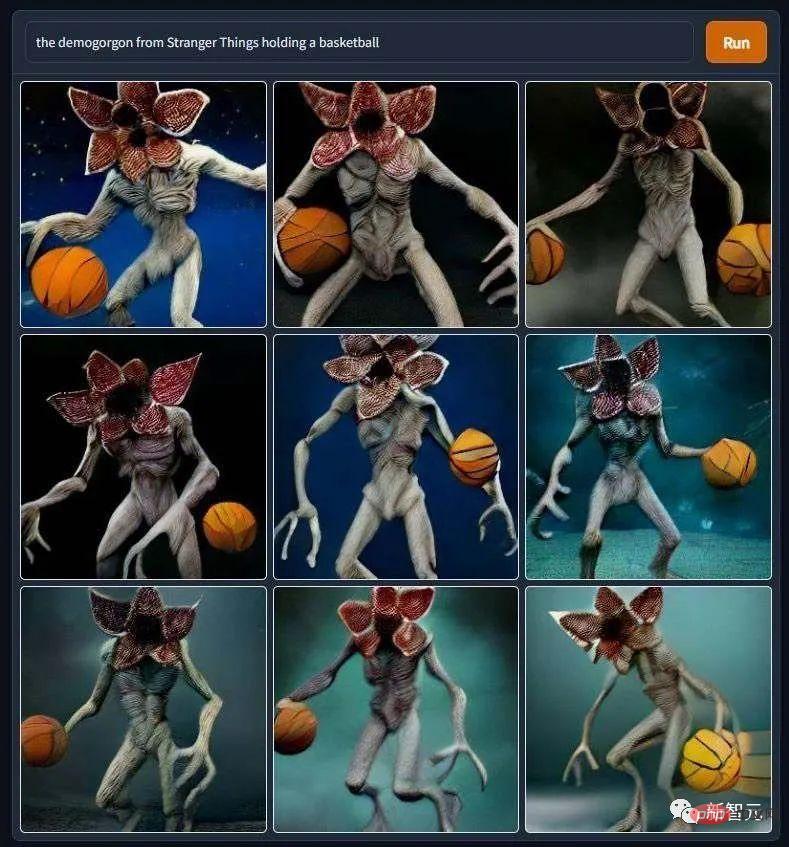
"Le Diable joue au basket". Après avoir vu cette photo, la rédaction n'a vraiment pas osé continuer à suivre l'émission "Stranger Things".
Les protagonistes de diverses séries de films d'horreur apparaissent également dans les œuvres, comme celle-ci "Masked Jason Devil mange burrito"

et celui-ci "A Nightmare on Elm Street Killer Eats Pasta"... le motif est si effrayant qu'il rappelle à l'éditeur les jours verts où il regardait ces films d'horreur à l'ère du DVD et était effrayé au point de paniquer.

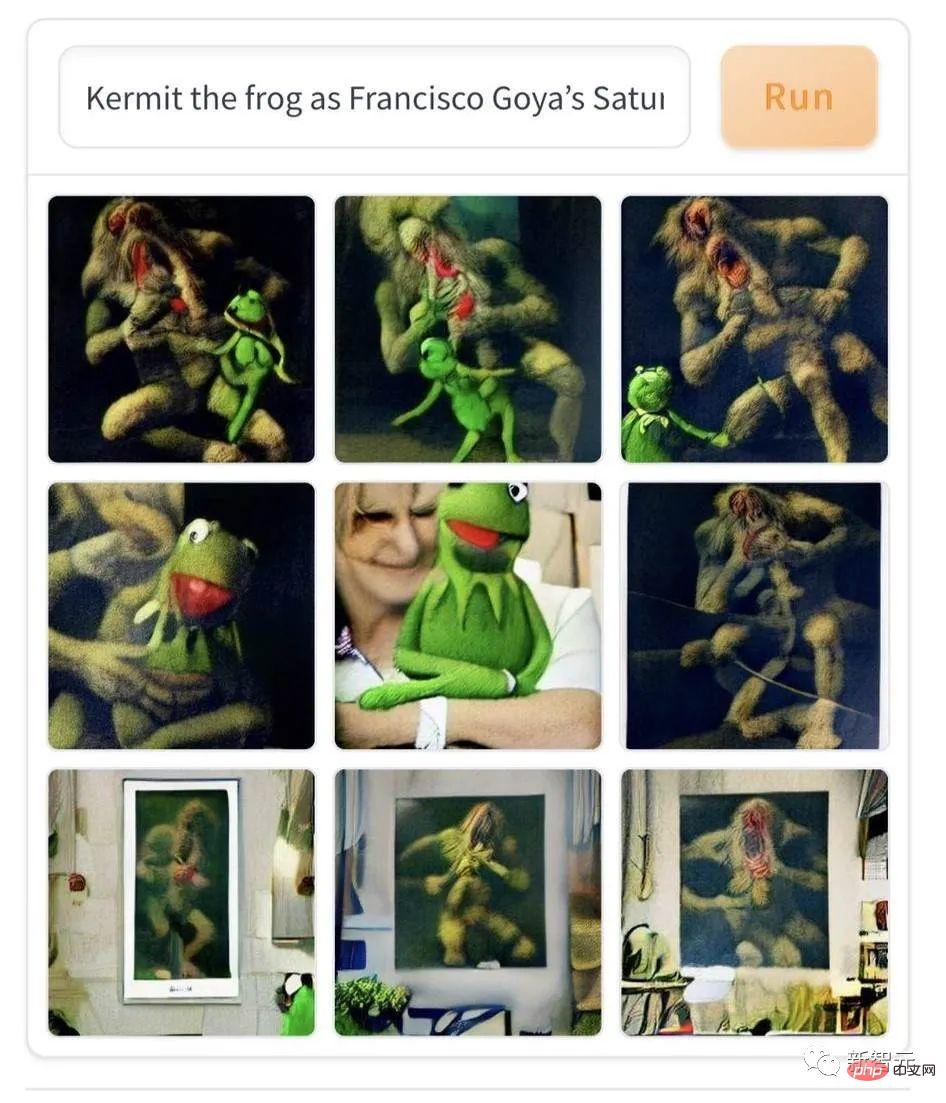
Cependant, la littérature et l'art populaires contemporains sont légèrement inférieurs à l'art classique en termes d'effarouchement, comme ce morceau de "Grenouille Komi photogénique dans la peinture à l'huile "Torma" de Goya." L'IA combine des dessins animés contemporains avec des peintures à l'huile expressionnistes du XIXe siècle, ce qui peut effrayer quiconque le voit pour la première fois avec des sueurs froides coulant dans le dos.
Il y a aussi cette photo "La mort clique sur les Arches d'Or". Après avoir lu ceci, oserez-vous être en retard au travail et à l'école à l'avenir ?

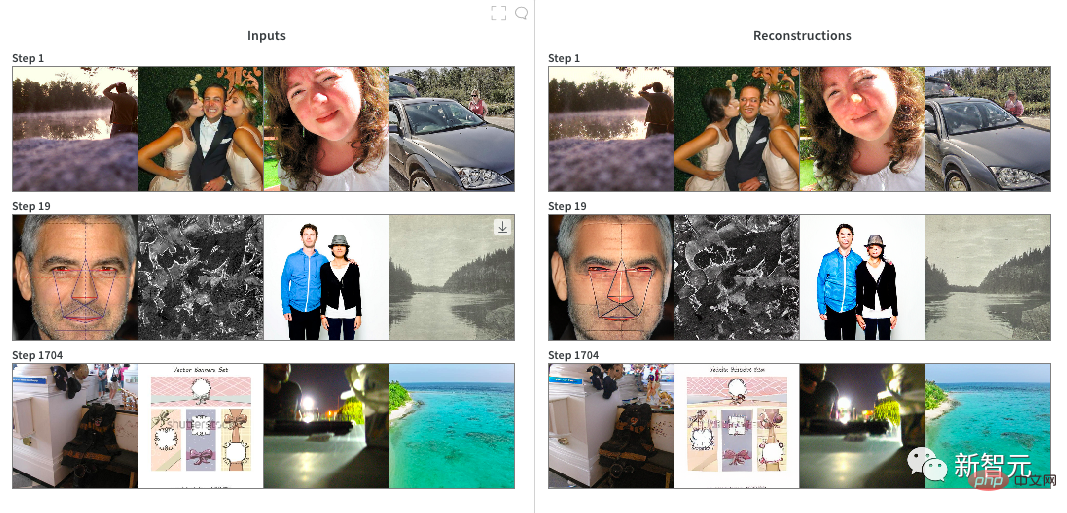
Bien sûr, les lecteurs attentifs et qui suivent la dynamique de la série DALL·E constateront qu'il existe des différences évidentes entre les images générées par DALL·E Mini et les grands modèles DALL·E précédents : Dans les portraits générés par DALL ·E Mini, Les visages sont plus flous que ceux générés initialement par DALL·E. Boris Dayma, le principal développeur du projet DALL·E Mini, a expliqué dans les notes de développement : Il s'agit d'une version conviviale avec des spécifications réduites. La démo ne contient que 60 lignes de code et il est normal que les fonctions soient faibles. .
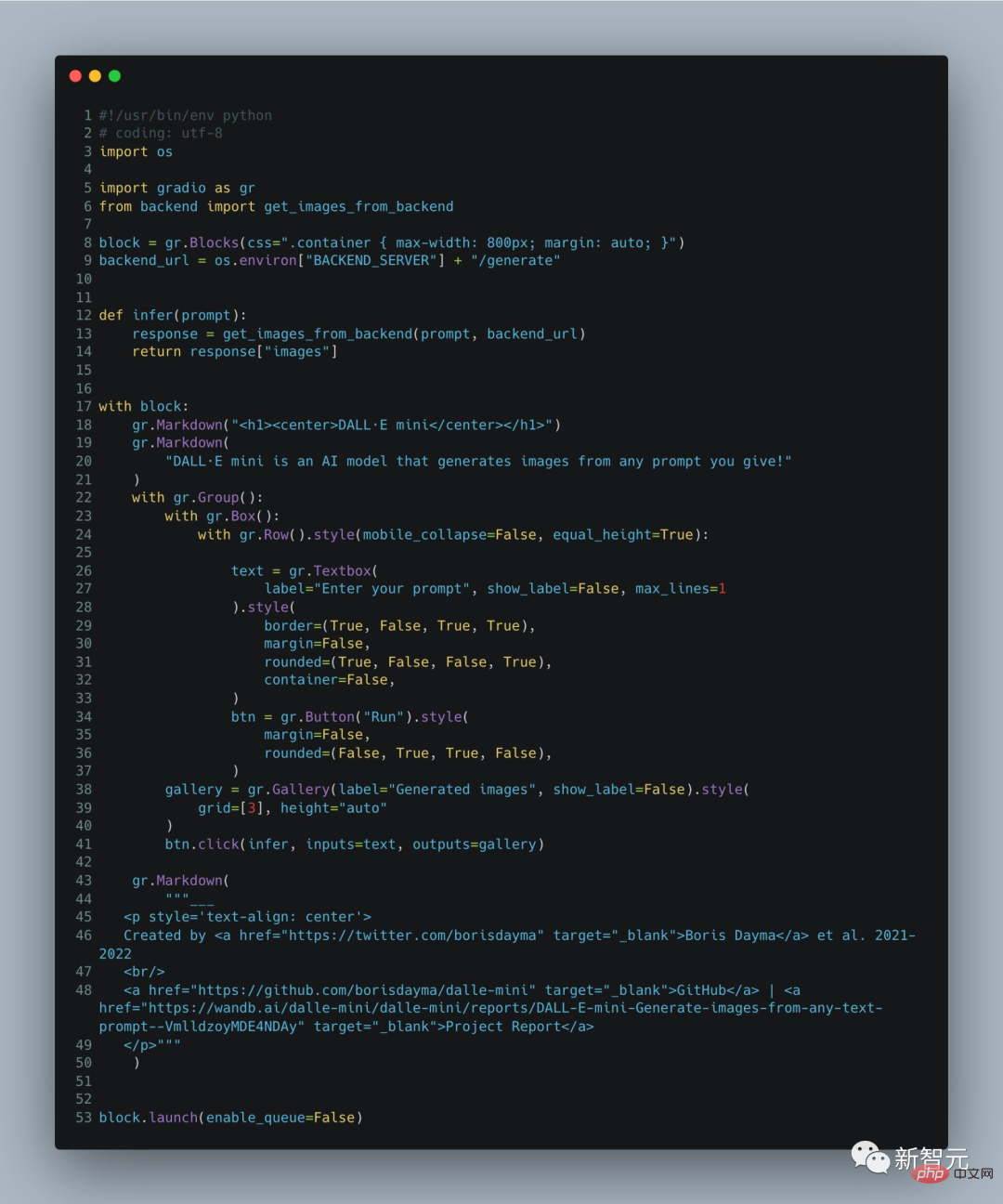
Ce qui suit est l'explication du projet par Boris Dayma dans ses notes. Jetons d'abord un coup d'œil à la mise en œuvre spécifique du projet. Il générera des images correspondantes basées sur le texte :
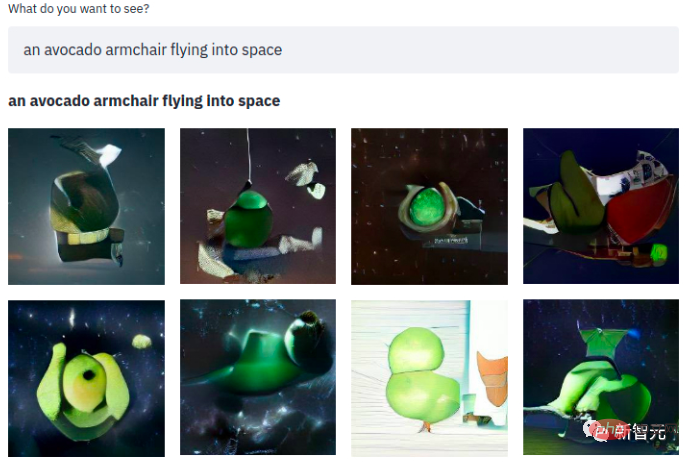
Une phrase simple, et ce qui suit est un fauteuil avocat clignotant dans l'espace~ Le modèle utilise trois ensembles de données :
1. "Ensemble de données de légendes conceptuelles" contenant 3 millions d'images et de paires de légendes
2. Le sous-ensemble Open AI de " ; YFCC100M" contient environ 15 millions d'images. Cependant, pour des raisons d'espace de stockage, l'auteur a sous-échantillonné 2 millions d'images. Utilisez simultanément les titres et les descriptions de texte comme balises et supprimez les balises html, les sauts de ligne et les espaces supplémentaires correspondants
3 "Conceptuel 12M" contenant 12 millions de paires d'images et de titres.
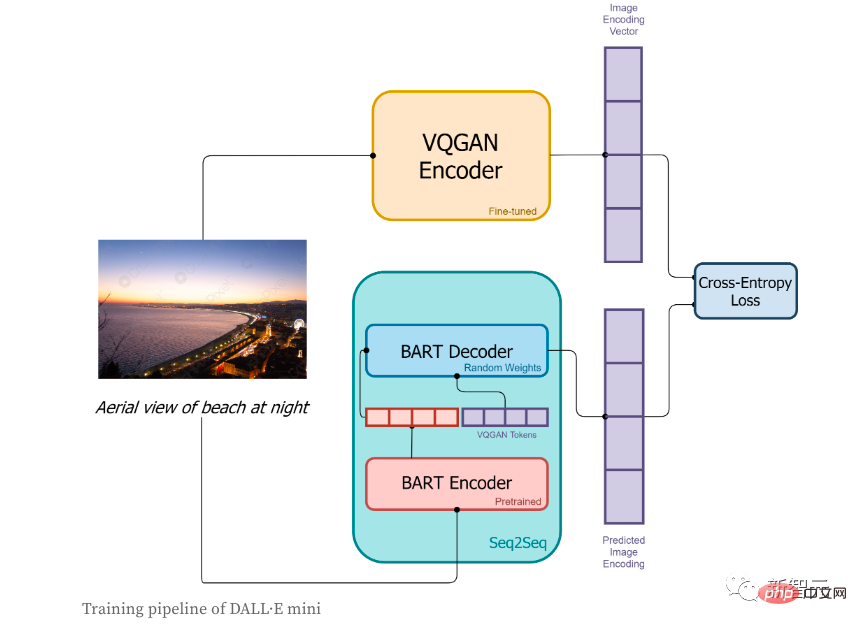
Dans la phase de formation :
1. Tout d'abord, l'image sera codée par l'encodeur VQGAN, dans le but de convertir l'image en une séquence de jetons
2. l'encodeur BART
3 , la sortie de l'encodeur BART et le jeton de séquence codé par l'encodeur VQGAN seront envoyés ensemble au décodeur BART. Le décodeur est un modèle autorégressif, et son but est de prédire la prochaine séquence de jetons ;
4. La fonction de perte est la perte d'entropie croisée, utilisée pour calculer la valeur de perte entre le résultat du codage d'image prédit par le modèle et le codage d'image réel VQGAN.
Dans la phase d'inférence, l'auteur n'a utilisé que des étiquettes courtes et a essayé de générer les images correspondantes. Le processus spécifique est le suivant :
1. Les étiquettes seront encodées via l'encodeur BART ; Démarrer un Le drapeau de séquence spéciale, le drapeau de départ, sera envoyé au décodeur BART
3 Sur la base de la distribution prédite par le décodeur BART dans le jeton suivant, les jetons d'image seront échantillonnés dans l'ordre
Voyons ensuite comment fonctionnent l'encodeur et le décodeur d'images VQGAN. Le modèle Transformer doit être familier à tout le monde. Depuis sa naissance, il domine non seulement le domaine de la PNL, mais aussi le réseau convolutif CNN dans le domaine du CV. Le but de l'auteur en utilisant VQGAN est d'encoder l'image dans une séquence de jetons discrets, qui peut être utilisée directement dans le modèle Transformer. En raison de l'utilisation de séquences de valeurs de pixels, l'espace d'intégration des valeurs discrètes sera trop grand, ce qui rendra finalement extrêmement difficile l'entraînement du modèle et la satisfaction des besoins en mémoire de la couche d'auto-attention. 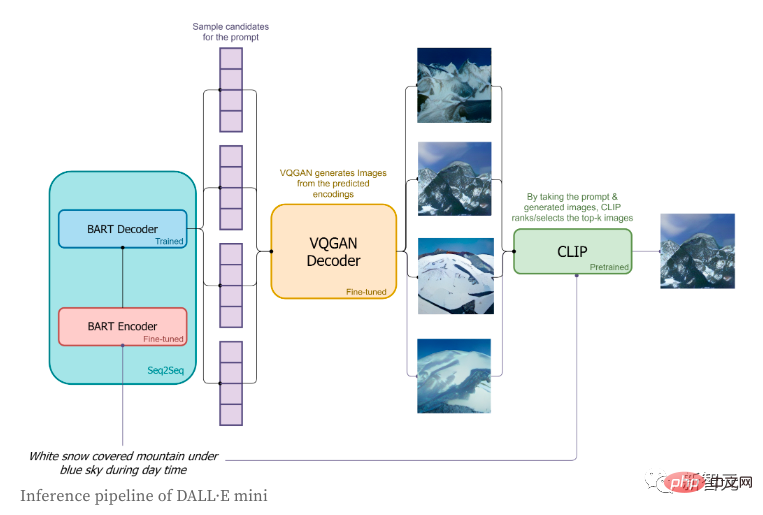
Le modèle Seq2Seq convertit une séquence de jetons en une autre séquence de jetons et est généralement utilisé en PNL pour des tâches telles que la traduction, le résumé ou la modélisation de dialogues. La même idée peut également être transférée au champ CV si les images sont codées en jetons discrets. Ce modèle utilise BART, et l'auteur vient d'affiner l'architecture originale : 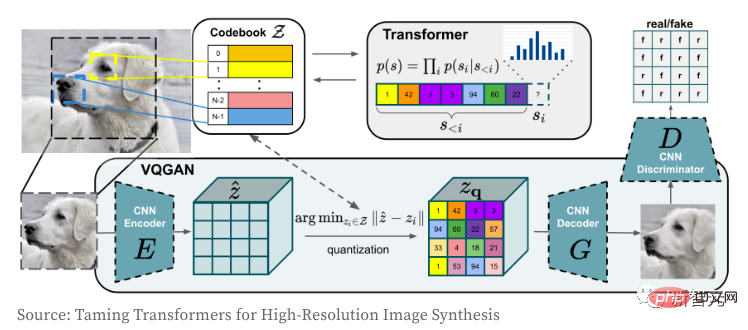
.
2. Ajustez la forme de l'entrée et de la sortie du décodeur pour la rendre cohérente avec la taille de VQGAN (cette étape ne nécessite pas de couche d'intégration intermédiaire) 3. La séquence de génération forcée comporte 256 jetons (non inclus ici); et
) qui marquent le début et la fin de la séquence.CLIP est utilisé pour établir la relation entre les images et le texte, et utilise l'apprentissage contrastif pour la formation, notamment en maximisant le produit (similitude cosinus, c'est-à-dire les échantillons positifs) entre les incorporations de paires d'images et de textes et en minimisant les échantillons non positifs. . Le produit entre des paires corrélées (c'est-à-dire des échantillons négatifs). Lors de la génération d'images, l'auteur échantillonne de manière aléatoire les étiquettes d'image en fonction de la distribution logits du modèle, ce qui entraîne des échantillons différents et une qualité incohérente des images générées. CLIP permet de noter les images générées en fonction des descriptions d'entrée, sélectionnant ainsi les meilleurs échantillons générés. Dans la phase d'inférence, la version pré-entraînée d'OpenAI est utilisée directement. 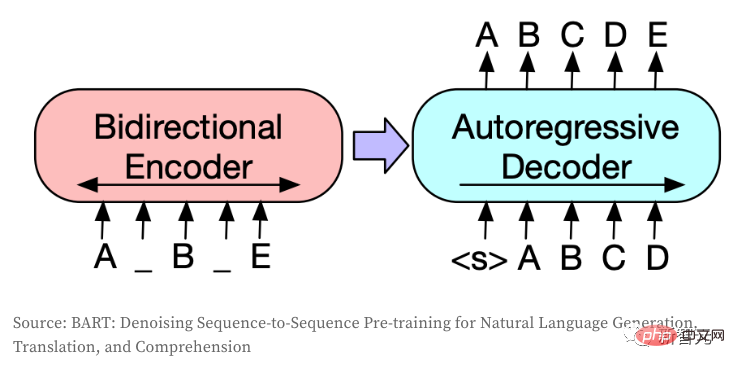
Alors, comment CLIP se compare-t-il à OpenAI DALL·E Tous les détails sur DAL ne sont pas connus du public, mais voici les principales différences selon l'auteur : 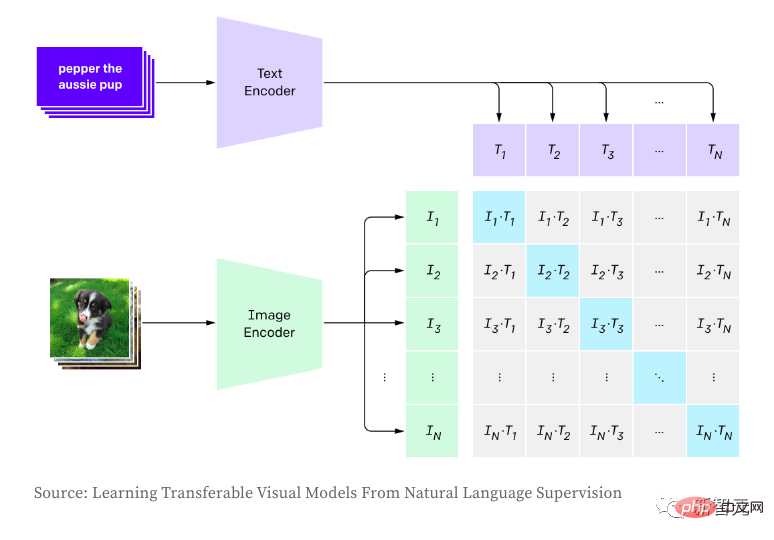
1. DALL·E utilise la version à 12 milliards de paramètres de GPT-3. En comparaison, le modèle de l’auteur est 27 fois plus grand et comporte environ 400 millions de paramètres.
2. L'auteur utilise largement des modèles pré-entraînés (VQGAN, encodeur BART et CLIP), tandis qu'OpenAI doit entraîner tous les modèles à partir de zéro. L'architecture du modèle prend en compte les modèles pré-entraînés disponibles et leur efficacité.
3. DALL·E encode les images en utilisant un plus grand nombre de jetons (1 024 VS 256) à partir d'un vocabulaire plus petit (8 192 VS 16 384).
4. DALL·E utilise VQVAE, tandis que l'auteur utilise VQGAN. DALL·E lit le texte et les images comme un seul flux de données lorsque les auteurs se partagent entre l'encodeur et le décodeur Seq2Seq. Cela leur permet également d'utiliser un vocabulaire distinct pour le texte et les images.
5. DALL·E lit le texte via un modèle autorégressif, tandis que l'auteur utilise un encodeur bidirectionnel.
6. DALL·E a formé 250 millions de paires d'images et de textes, alors que l'auteur n'en a utilisé que 15 millions. de.
7. DALL·E utilise moins de jetons (jusqu'à 256 VS 1024) et un vocabulaire plus petit (16384 VS 50264) pour encoder le texte. Lors de la formation de VQGAN, l'auteur est d'abord parti du point de contrôle pré-entraîné sur ImageNet, avec un facteur de compression de f=16 et une taille de vocabulaire de 16 384. Bien que très efficace pour encoder une large gamme d'images, le point de contrôle pré-entraîné n'est pas efficace pour encoder des personnes et des visages (car les deux ne sont pas courants dans ImageNet), l'auteur a donc décidé de le tester sur une instance cloud 2 x RTX A6000. 20 heures de mise au point. Il est évident que la qualité des images générées sur le visage humain ne s'est pas beaucoup améliorée, et il pourrait s'agir d'un « effondrement du modèle ». Une fois le modèle entraîné, nous convertissons le modèle Pytorch en JAX pour une utilisation à l'étape suivante.
Formation DALL·E Mini : Ce modèle utilise la programmation JAX et exploite pleinement les avantages du TPU. L'auteur pré-encode toutes les images avec un encodeur d'image pour un chargement plus rapide des données. Au cours de la formation, l'auteur a rapidement déterminé plusieurs paramètres presque réalisables :
1 À chaque étape, la taille de lot de chaque TPU est de 56, ce qui correspond à la mémoire maximale disponible pour chaque TPU
2. soit 56 × 8 puces TPU × 8 étapes = 3 584 images par mise à jour
3. L'efficacité de la mémoire de l'optimiseur Adafactor nous permet d'utiliser une taille de lot plus élevée
4. se désintègre de façon linéaire. L'auteur a passé près d'une demi-journée à trouver un bon taux d'apprentissage pour le modèle en lançant une recherche d'hyperparamètres. Derrière chaque modèle NB, il y a probablement un processus minutieux de recherche d'hyperparamètres ! Après l'exploration initiale de l'auteur, plusieurs taux d'apprentissage différents ont été essayés sur une période prolongée jusqu'à ce qu'ils soient finalement fixés à 0,005.
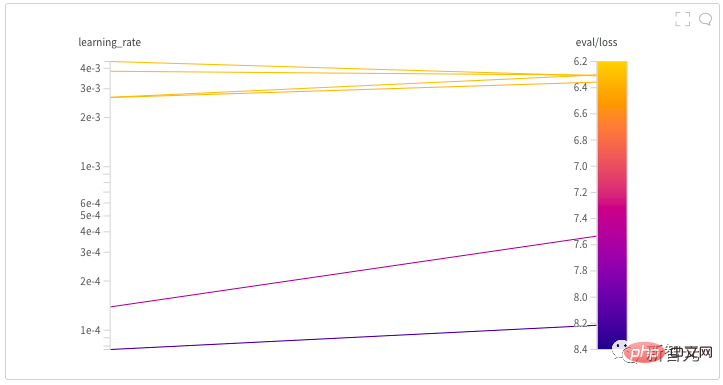
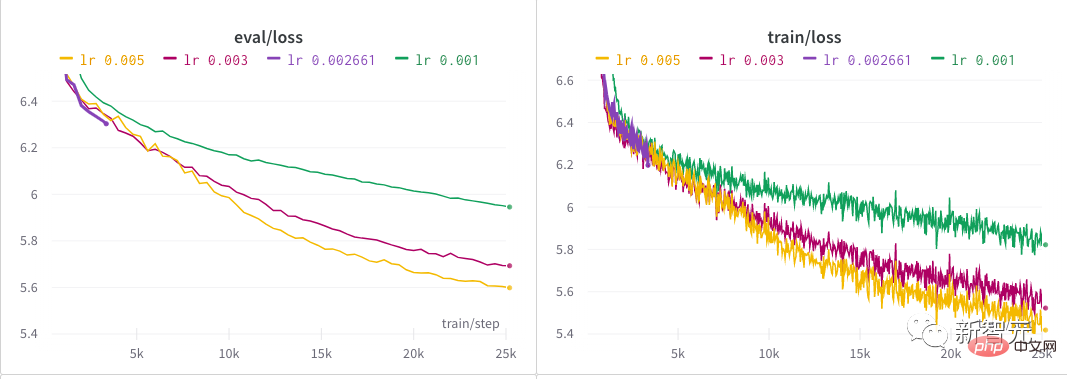
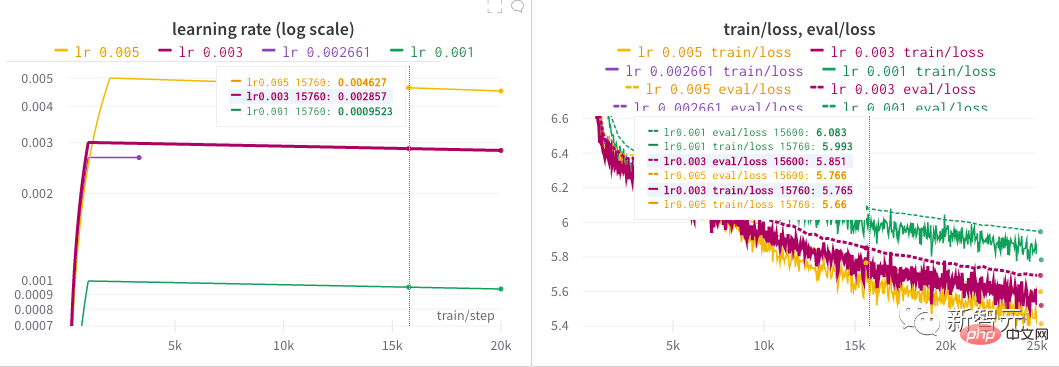
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Caractéristiques du réseau
Caractéristiques du réseau
 Le câble réseau est débranché
Le câble réseau est débranché
 Que se passe-t-il lorsque je n'arrive pas à me connecter au réseau ?
Que se passe-t-il lorsque je n'arrive pas à me connecter au réseau ?
 Comment définir une image d'arrière-plan ppt
Comment définir une image d'arrière-plan ppt
 Quelles sont les performances de thinkphp ?
Quelles sont les performances de thinkphp ?
 Introduction aux paramètres de l'indice de performances du processeur
Introduction aux paramètres de l'indice de performances du processeur
 Que signifie le jeton ?
Que signifie le jeton ?
 Logiciel d'enregistrement du temps
Logiciel d'enregistrement du temps








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



