


Les performances étonnantes de ChatGPT dans des scénarios avec peu de tirs et zéro tir ont rendu les chercheurs plus convaincus que la « pré-formation » est la bonne voie.
Les modèles de base pré-entraînés (PFM) sont considérés comme la base de diverses tâches en aval sous différents modes de données, c'est-à-dire basés sur des données à grande échelle, pour BERT, GPT-3, MAE, DALLE-E et ChatGPT, etc. Le modèle de base pré-entraîné est formé pour fournir une initialisation raisonnable des paramètres pour les applications en aval.
L'idée de pré-entraînement derrière PFM joue un rôle important dans l'application de grands modèles. Différente des méthodes précédentes d'extraction de fonctionnalités utilisant des modules de convolution et récursifs, la méthode de pré-entraînement génératif (GPT). utilise Transformer En tant qu'extracteur de fonctionnalités, effectuez un entraînement autorégressif sur de grands ensembles de données.
Comme la PFM a connu un grand succès dans divers domaines, un grand nombre de méthodes, d'ensembles de données et d'indicateurs d'évaluation ont été proposés dans des articles publiés ces dernières années. L'industrie a besoin d'un examen complet qui suit le processus de développement de BERT à ChatGPT. .
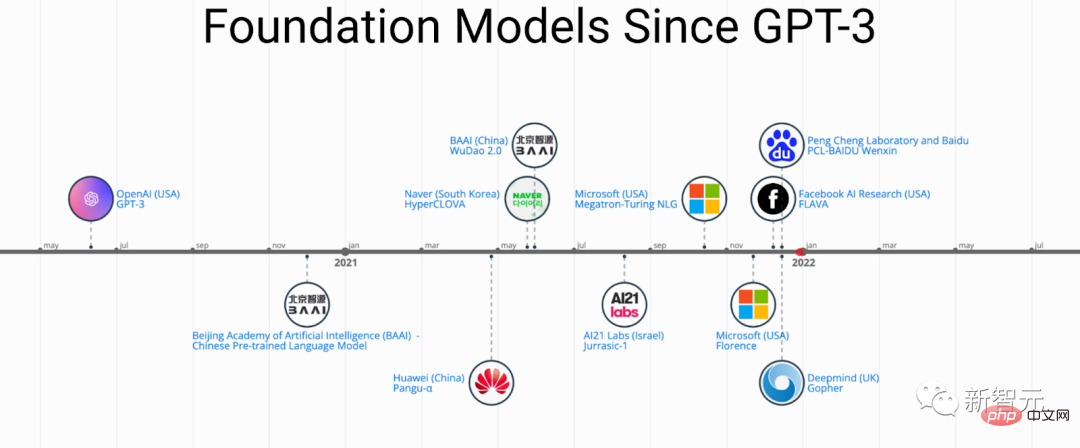
Récemment, des chercheurs de l'Université Beihang, de l'Université d'État du Michigan, de l'Université Lehigh, de l'Institut de technologie de Nanyang, de Duke et d'autres universités et entreprises nationales et étrangères bien connues ont rédigé conjointement une revue sur les modèles de base de pré-formation, fournissant les progrès récents de la recherche. dans les domaines du texte, des images et des graphiques, ainsi que des défis et opportunités actuels et futurs.

Lien papier : https://arxiv.org/pdf/2302.09419.pdf
Les chercheurs ont d'abord examiné les composants de base et le prétraitement existant du traitement du langage naturel, de la vision par ordinateur et de l'apprentissage graphique. la formation discute ensuite d'autres modes de données d'autres PFM avancées et unifiées en tenant compte de la qualité et de la quantité des données ; ainsi que des recherches connexes sur les principes de base de la PFM, y compris l'efficacité et la compression des modèles, la sécurité et la confidentialité. Enfin, l'article énumère plusieurs conclusions clés, notamment les futures ; orientations de recherche, défis et questions ouvertes.
Les modèles de base de pré-formation (PFM) sont un élément important de la construction de systèmes d'intelligence artificielle à l'ère du big data. Ils sont largement utilisés dans le traitement du langage naturel (NLP) et la vision par ordinateur. (CV) et apprentissage des graphes (GL) Les trois principaux domaines de l'intelligence artificielle ont fait l'objet de nombreuses recherches et applications.
Les PFM sont des modèles généraux efficaces dans divers domaines ou tâches inter-domaines, montrant un grand potentiel dans l'apprentissage des représentations de caractéristiques dans diverses tâches d'apprentissage, telles que la classification de texte, la génération de texte, la classification d'images, la détection d'objets et la classification d'images, etc. .
Les PFM montrent d'excellentes performances dans la formation de tâches multiples avec des corpus à grande échelle et dans le réglage fin de tâches similaires à petite échelle, permettant de lancer un traitement rapide des données.
Les PFM sont basés sur une technologie de pré-formation, qui vise à utiliser une grande quantité de données et de tâches pour former un modèle général qui peut être facilement ajusté dans différentes applications en aval.
L'idée de la pré-formation est née de l'apprentissage par transfert dans les tâches CV. Après avoir réalisé l'efficacité de la pré-formation dans le domaine du CV, les gens ont commencé à utiliser des techniques de pré-formation pour améliorer les performances des modèles dans d'autres domaines. Lorsque les techniques de pré-formation sont appliquées au domaine du PNL, des modèles linguistiques (LM) bien entraînés peuvent capturer des connaissances riches qui sont bénéfiques pour les tâches en aval, telles que les dépendances à long terme, les relations hiérarchiques, etc.
De plus, l'avantage significatif de la pré-formation dans le domaine de la PNL est que les données de formation peuvent provenir de n'importe quel corpus de texte non étiqueté, c'est-à-dire qu'il existe une quantité illimitée de données de formation dans le processus de pré-formation.
Au début, la pré-formation était une méthode statique, comme NNLM et Word2vec, difficile à adapter à différents environnements sémantiques. Plus tard, certains chercheurs ont proposé des technologies de pré-formation dynamique, comme BERT, XLNet, etc.

Histoire et évolution des PFM dans les domaines PNL, CV et GL
Les PFM basés sur des techniques de pré-formation utilisent de grands corpus pour apprendre les représentations sémantiques communes Avec l'introduction de ces travaux pionniers, divers PFM ont été développés. ont émergé et ont été appliqués aux tâches et applications en aval.
Un cas d'application PFM notable est le ChatGPT récemment populaire.
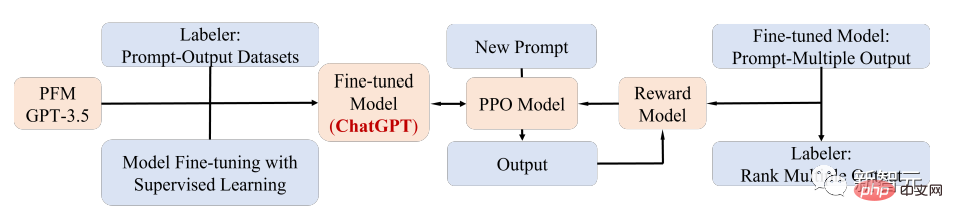
ChatGPT est affiné à partir du transformateur de pré-formation génératif, GPT-3.5, après une formation sur un corpus mixte de texte et de code, et ChatGPT utilise la technologie d'apprentissage par renforcement à partir de la rétroaction humaine (RLHF) ; est actuellement l’une des méthodes les plus prometteuses pour faire correspondre les grands LM aux intentions humaines.
Les performances supérieures de ChatGPT peuvent conduire à un point critique dans la transformation du paradigme de formation de chaque type de PFM, c'est-à-dire l'application de la technologie d'alignement des instructions, y compris l'apprentissage par renforcement (RL), le réglage rapide et la chaîne de- pensée), et à terme s’orienter vers l’intelligence artificielle générale.
Dans cet article, les chercheurs examinent principalement la PFM liée au texte, aux images et aux graphiques, qui est également une méthode de classification de recherche relativement mature.
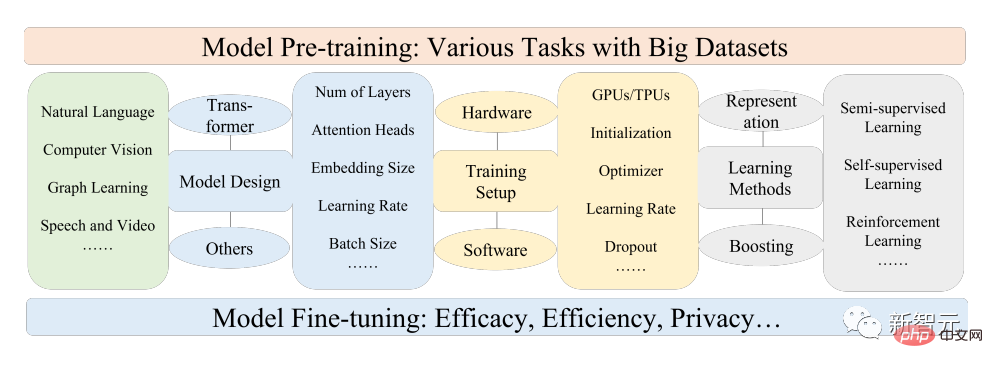
Pour le texte, les modèles linguistiques peuvent réaliser diverses tâches en prédisant le mot ou le caractère suivant. Par exemple, les PFM peuvent être utilisés pour la traduction automatique, les systèmes de questions-réponses, la modélisation de sujets, l'analyse des sentiments, etc. .
Pour les images, similaires aux PFM dans le texte, utilisez des ensembles de données à grande échelle pour former un grand modèle adapté à plusieurs tâches de CV.
Pour les graphiques, des idées de pré-formation similaires sont également utilisées pour obtenir des PFM, qui peuvent être utilisés pour de nombreuses tâches en aval.
En plus des PFM pour des domaines de données spécifiques, l'article passe également en revue et explique certains autres PFM avancés, tels que les PFM pour la voix, la vidéo et les données inter-domaines, et les PFM multimodaux.
En outre, une grande tendance à la fusion de PFM capables de gérer la multimodalité est en train d'émerger, ce que l'on appelle les PFM unifiés ; les chercheurs ont d'abord défini le concept de PFM unifiés, puis ont examiné l'état des lieux ; art dans les recherches récentes sur les PFM unifiés, notamment OFA, UNIFIED-IO, FLAVA, BEiT-3, etc.
Sur la base des caractéristiques des PFM existants dans ces trois domaines, les chercheurs ont conclu que les PFM présentent les deux avantages majeurs suivants :
1 Seul un ajustement minimal est nécessaire pour améliorer le modèle sur la performance des tâches en aval ;
2. Les PFM ont passé le test en termes de qualité.
Plutôt que de créer un modèle à partir de zéro pour résoudre un problème similaire, une meilleure option consiste à appliquer des PFM à un ensemble de données pertinent pour une tâche.
Les énormes perspectives des PFM ont inspiré de nombreux travaux connexes axés sur des questions telles que l'efficacité, la sécurité et la compression des modèles.
Les caractéristiques de cette revue sont :
Référence : https://arxiv.org/abs/2302.09419
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Inscription ChatGPT
Inscription ChatGPT
 Encyclopédie ChatGPT nationale gratuite
Encyclopédie ChatGPT nationale gratuite
 Comment installer chatgpt sur un téléphone mobile
Comment installer chatgpt sur un téléphone mobile
 Chatgpt peut-il être utilisé en Chine ?
Chatgpt peut-il être utilisé en Chine ?
 Qu'est-ce que CONNECTION_REFUSED ?
Qu'est-ce que CONNECTION_REFUSED ?
 Quelles sont les plateformes formelles de trading de devises numériques ?
Quelles sont les plateformes formelles de trading de devises numériques ?
 Comment utiliser l'éditeur d'atomes
Comment utiliser l'éditeur d'atomes
 logiciel erp gratuit
logiciel erp gratuit








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



