


La précision mixte est devenue une nécessité pour former de grands modèles d'apprentissage profond, mais elle pose également de nombreux défis. La conversion des paramètres et des gradients du modèle en types de données de moindre précision (tels que FP16) peut accélérer la formation, mais introduit également des problèmes de stabilité numérique. Le gradient utilisé pour la formation FP16 est plus susceptible de déborder ou d'être insuffisant, ce qui entraîne des calculs inexacts de la part de l'optimiseur et des problèmes tels que l'accumulateur dépassant la plage de types de données.

Dans cet article, nous aborderons la question de la stabilité numérique de l'entraînement de précision hybride. Les gros travaux de formation sont souvent suspendus pendant des jours pour faire face à des instabilités numériques, ce qui entraîne des retards dans les projets. Nous pouvons donc introduire Tensor Collection Hook pour surveiller les conditions de gradient pendant la formation, afin que nous puissions mieux comprendre l'état interne du modèle et identifier plus rapidement l'instabilité numérique.
C'est un très bon moyen de comprendre l'état interne du modèle au début de la formation pour déterminer si le modèle est sujet à l'instabilité lors d'une formation ultérieure. Si une instabilité de gradient peut être identifiée dans les premières heures de formation, elle peut le faire. aidez-nous à améliorer considérablement l’efficacité. Cet article fournit donc une série de mises en garde auxquelles il convient de prêter attention, ainsi que des remèdes aux instabilités numériques.
Alors que l'apprentissage profond continue d'évoluer vers des modèles de base plus larges. Les grands modèles de langage comme GPT et T5 dominent désormais la PNL, et des modèles contrastés tels que CLIP se généralisent mieux que les modèles supervisés traditionnels en CV. En particulier, la capacité de CLIP à apprendre l'incorporation de texte signifie qu'il peut effectuer des inférences à zéro et à quelques tirs qui dépassent les capacités des modèles CV précédents, qui représentaient tous deux un défi à former.
Ces grands modèles impliquent généralement des réseaux profonds de transformateurs, à la fois visuels et textuels, et contiennent des milliards de paramètres. GPT3 possède 175 milliards de paramètres et CLIP est formé sur des centaines de téraoctets d'images. La taille du modèle et des données signifie que les modèles nécessitent des semaines, voire des mois, pour s'entraîner sur de grands clusters GPU. Pour accélérer la formation et réduire le nombre de GPU requis, les modèles sont souvent formés avec une précision mixte.
L'entraînement de précision hybride place certaines opérations d'entraînement en FP16 au lieu du FP32. Les opérations effectuées dans FP16 nécessitent moins de mémoire et peuvent être traitées jusqu'à 8 fois plus rapidement que FP32 sur les GPU modernes. Bien que la plupart des modèles formés dans FP16 aient une précision inférieure, ils ne présentent aucune dégradation des performances due à un paramétrage excessif.
Avec l'introduction des Tensor Cores par NVIDIA dans l'architecture Volta, la formation accélérée en virgule flottante de faible précision est plus rapide. Étant donné que les modèles d’apprentissage profond comportent de nombreux paramètres, la valeur exacte d’un paramètre n’est généralement pas importante. En représentant les nombres avec 16 bits au lieu de 32 bits, davantage de paramètres peuvent être insérés simultanément dans les registres Tensor Core, augmentant ainsi le parallélisme pour chaque opération.

Mais l'entraînement pour le FP16 est un défi. Parce que FP16 ne peut pas représenter des nombres dont la valeur absolue est supérieure à 65 504 ou inférieure à 5,96e-8. Les frameworks d'apprentissage profond tels que PyTorch sont livrés avec des outils intégrés pour gérer les limitations du FP16 (mise à l'échelle des dégradés et précision mixte automatique). Mais même avec ces contrôles de sécurité en place, il n'est pas rare que de grandes tâches de formation échouent parce que les paramètres ou les gradients se situent en dehors de la plage disponible. Certains composants de l'apprentissage profond fonctionnent bien dans le FP32, mais le BN, par exemple, nécessite souvent un réglage très fin qui peut conduire à une instabilité numérique dans les limites du FP16, ou ne pas fournir suffisamment de précision pour que le modèle converge correctement. Cela signifie que les modèles ne peuvent pas être convertis aveuglément en FP16.
Ainsi, le cadre d'apprentissage en profondeur utilise Automatic Mixed Precision (AMP), qui est formé via une liste prédéfinie d'opérations sûres FP16. AMP ne convertit que les parties du modèle considérées comme sûres, tout en conservant les opérations nécessitant une plus grande précision dans FP32. De plus, dans le modèle d'entraînement de précision mixte, un gradient plus grand est obtenu en multipliant certaines pertes proches du gradient nul (en dessous de la plage minimale du FP16) par une certaine valeur, puis lorsque l'optimiseur est appliqué pour mettre à jour les poids du modèle, il sera proportionnellement vers le bas. L'ajustement pour résoudre le problème des gradients trop petits est appelé mise à l'échelle du gradient.
Ce qui suit est un exemple d'une boucle de formation AMP typique dans PyTorch.

Le scaler de gradient multiplie la perte par un montant variable. Si nan est observé dans le gradient, le multiplicateur est réduit de moitié jusqu'à ce que le nan disparaisse, puis augmente progressivement le multiplicateur tous les 2000 pas par défaut si aucun nan ne se produit. Cela maintiendra le gradient dans la plage FP16 tout en empêchant également le gradient d'atteindre zéro.
Malgré les meilleurs efforts des deux frameworks, les outils intégrés à PyTorch et TensorFlow ne peuvent empêcher l'instabilité numérique qui se produit dans FP16.
Dans l'implémentation T5 de HuggingFace, les variantes de modèle ont produit des valeurs INF même après l'entraînement. Dans les modèles T5 très profonds, les valeurs d'attention s'accumulent à travers les couches et finissent par dépasser la plage FP16, ce qui donne lieu à des valeurs infinies, telles que nan dans les couches BN. Ils ont résolu ce problème en modifiant la valeur INF à la valeur maximale au FP16 et ont constaté que cela avait un impact négligeable sur l'inférence.
Un autre problème courant concerne les limitations de l'optimiseur ADAM. En guise de petite mise à jour, ADAM utilise une moyenne mobile des premier et deuxième moments du gradient pour adapter le taux d'apprentissage de chaque paramètre du modèle.
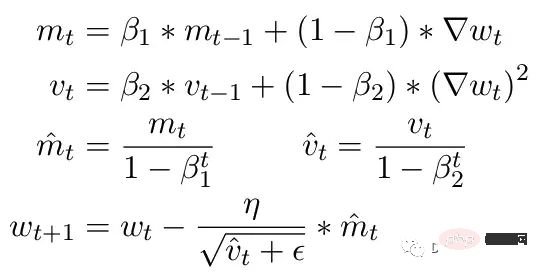
Ici, Beta1 et Beta2 sont les paramètres de moyenne mobile à chaque instant, généralement fixés à 0,9 et 0,999 respectivement. Diviser le paramètre bêta par la puissance du nombre d'étapes supprime le biais initial dans les mises à jour. Lors de l'étape de mise à jour, un petit epsilon est ajouté au deuxième paramètre de moment pour éviter une division par zéro erreur. La valeur par défaut typique pour epsilon est 1e-8. Mais le minimum pour le FP16 est de 5,96e-8. Cela signifie que si le deuxième instant est trop petit, la mise à jour sera divisée par zéro. Ainsi, dans PyTorch, afin que la formation ne diverge pas, les mises à jour ignoreront les modifications de cette étape. Mais le problème existe toujours. Surtout dans le cas de Beta2=.999, tout gradient inférieur à 5,96e-8 peut arrêter la mise à jour du poids des paramètres pendant une longue période et l'optimiseur entrera dans un état instable.
L'avantage d'ADAM est qu'en utilisant ces deux instants, le taux d'apprentissage de chaque paramètre peut être ajusté. Pour des paramètres d'apprentissage plus lents, la vitesse d'apprentissage peut être accélérée, et pour des paramètres d'apprentissage rapides, la vitesse d'apprentissage peut être ralentie. Mais si le gradient est calculé comme étant nul pour plusieurs étapes, même une petite valeur positive entraînera une divergence du modèle avant que le taux d'apprentissage n'ait le temps de s'ajuster à la baisse.
De plus, PyTorch a actuellement un problème où il change automatiquement epsilon en 1e-7 lors de l'utilisation d'une précision mixte, ce qui peut aider à empêcher les dégradés de diverger lors du retour à des valeurs positives. Mais cela pose un nouveau problème lorsque nous savons que le gradient est dans la même plage, augmenter ε réduit la capacité de l'optimiseur à s'adapter au taux d'apprentissage. Par conséquent, augmenter aveuglément l'epsilon ne peut pas résoudre le problème de la stagnation de l'entraînement due au gradient nul.
Pour démontrer davantage les instabilités qui peuvent survenir lors de la formation, nous avons construit une série d'expériences sur le modèle d'image CLIP. CLIP est un modèle basé sur l'apprentissage contrastif qui apprend simultanément des images via un transformateur visuel et des intégrations de texte décrivant ces images. Le composant de comparaison tente de faire correspondre les images à la description originale dans chaque lot de données. Étant donné que la perte est calculée par lots, il a été démontré que l’entraînement sur des lots plus importants donne de meilleurs résultats.
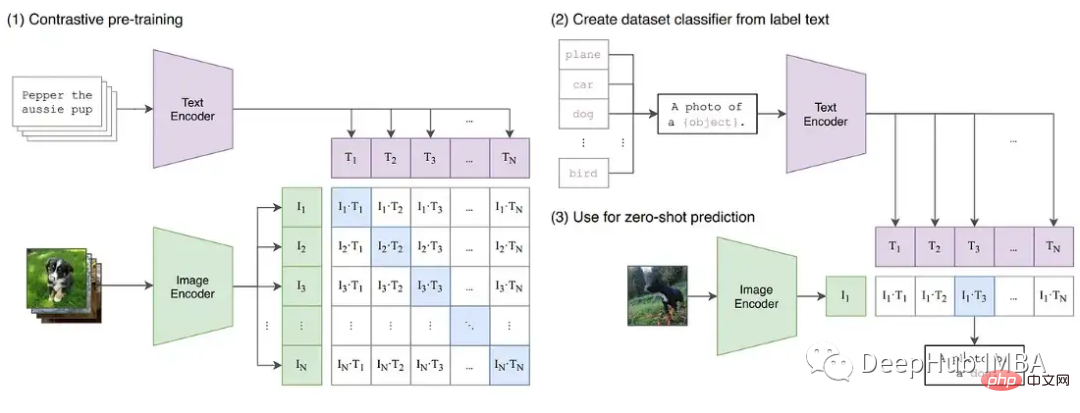
CLIP entraîne simultanément deux modèles de transformateurs, un modèle de langage de type GPT et un modèle d'image ViT. La profondeur des deux modèles crée des opportunités pour que la croissance graduelle dépasse la limite du FP16. L'implémentation d'OpenClip (arxiv 2212.07143) décrit l'instabilité de la formation lors de l'utilisation de FP16.
Pour mieux comprendre l'état interne du modèle pendant l'entraînement, nous avons développé un Tensor Collection Hook (TCH). TCH peut envelopper un modèle et collecter périodiquement des informations récapitulatives sur les poids, les gradients, les pertes, les entrées, les sorties et l'état de l'optimiseur.
Par exemple, dans cette expérience, nous voulons trouver et enregistrer les conditions de gradient pendant l'entraînement. Par exemple, vous souhaiterez peut-être collecter la norme de gradient, le minimum, le maximum, la valeur absolue, la moyenne et l'écart type de chaque couche toutes les 10 étapes et visualiser les résultats dans TensorBoard.

TensorBoard peut ensuite être démarré avec out_dir comme entrée --logdir.

Pour reproduire les instabilités d'entraînement dans CLIP, un sous-ensemble de l'ensemble de données d'images de 5 milliards de Laion a été utilisé pour entraîner OpenCLIP. Nous enveloppons le modèle avec TCH et enregistrons régulièrement les gradients, les poids et les états de moment de l'optimiseur du modèle, afin que nous puissions observer ce qui se passe à l'intérieur du modèle lorsqu'une instabilité se produit.
À partir de la variante vvi-h-14, les auteurs d'OpenCLIP décrivent un problème de stabilité lors de l'entraînement. À partir du point de contrôle pré-formation, augmentez le taux d'apprentissage à 1-e4, similaire au taux d'apprentissage de la seconde moitié de la formation CLIP. Lorsque l'entraînement atteint 300 étapes, 10 lots d'entraînement plus difficiles sont intentionnellement introduits successivement.
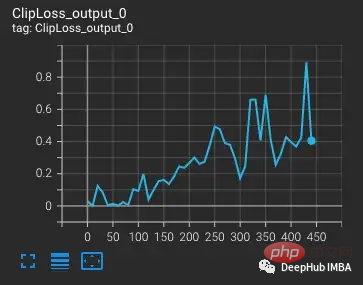
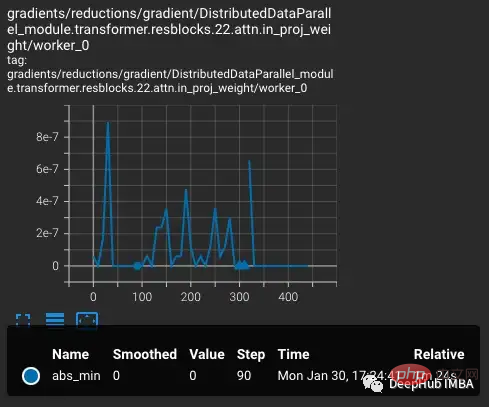
La perte augmente à mesure que le taux d'apprentissage augmente, ce qui est attendu. Lorsqu'une situation plus difficile est introduite à l'étape 300, il se produit une augmentation légère, mais pas importante, de la perte. Le modèle trouve les cas difficiles mais ne met pas à jour la plupart des poids au cours de ces étapes car nan apparaît dans le gradient (représenté sous forme de triangle dans le deuxième graphique). Après avoir réussi cet ensemble de cas difficiles, le gradient tombe à zéro.
Que se passe-t-il ici ? Pourquoi le gradient est-il nul ? Le problème réside dans la mise à l'échelle du gradient de PyTorch. La mise à l'échelle du gradient est un outil important dans l'entraînement de précision mixte. Parce que dans les modèles comportant des millions ou des milliards de paramètres, le gradient d’un paramètre est faible et souvent inférieur à la plage minimale du FP16.
Lorsque l'entraînement de précision hybride a été proposé pour la première fois, les scientifiques du deep learning ont constaté que leurs modèles s'entraînaient souvent comme prévu au début de l'entraînement, mais finissaient par diverger. Au fur et à mesure que l'entraînement progresse, la pente a tendance à devenir plus petite et un certain sous-débit FP16 passe à zéro, rendant l'entraînement instable.

Pour résoudre le sous-versement du gradient, les premières techniques multipliaient simplement la perte par un montant fixe, calculaient le gradient le plus important, puis ajustaient les mises à jour de poids au même montant fixe (pendant l'entraînement de précision hybride, les poids sont toujours stockés dans le PC32). Mais parfois, ce montant fixe n’est toujours pas suffisant. Alors que les techniques plus récentes, comme la mise à l'échelle du gradient de PyTorch, commencent avec un multiplicateur plus grand, généralement 65 536. Mais comme cela peut être si élevé que des gradients importants dépasseront la valeur FP16, le scaler de gradient surveille les gradients qui déborderont. Si nan est observé, ignorez la mise à jour du poids à cette étape pour réduire de moitié le multiplicateur et passez à l'étape suivante. Cela continue jusqu'à ce qu'aucun nan ne soit observé dans le gradient. Si le scaler de gradient ne détecte pas de nan à l'étape 2000, il tentera de doubler le multiplicateur.
Dans l'exemple ci-dessus, le scaler de dégradé fonctionne exactement comme prévu. Nous lui transmettons un ensemble de cas où la perte est plus importante que prévu, ce qui crée des gradients plus importants conduisant à un débordement. Mais le problème est que le multiplicateur est maintenant faible, les gradients les plus petits tombent à zéro et le scaler de gradient ne surveille pas uniquement les gradients nuls.
L'exemple ci-dessus peut sembler au départ quelque peu intentionnel, car nous avons intentionnellement regroupé les exemples difficiles. Mais après plusieurs jours de formation, dans le cas de lots importants, la probabilité de générer des anomalies nan va certainement augmenter. La probabilité de rencontrer suffisamment de nan pour pousser le gradient à zéro est donc très élevée. En fait, même si des échantillons difficiles ne sont pas introduits, on constate souvent que le gradient est toujours nul après des milliers d’étapes d’apprentissage.
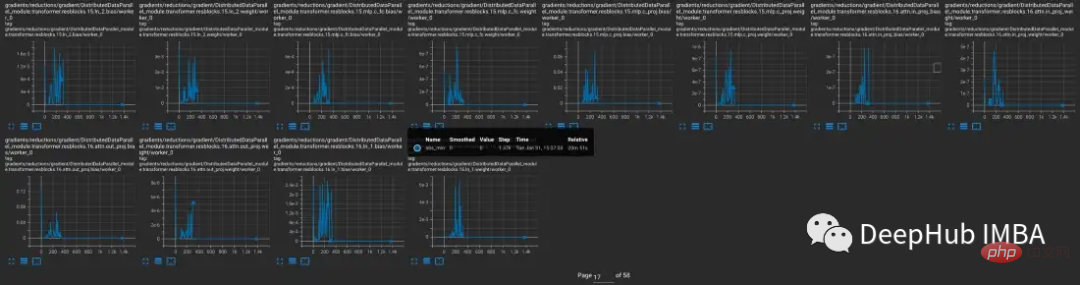
Pour explorer plus en détail quand le problème se produit et quand il ne se produit pas, CLIP a été comparé à YOLOV5, un modèle CV plus petit généralement entraîné avec une précision mixte. La fréquence des gradients nuls dans chaque couche a été suivie pendant l'entraînement dans les deux cas.

Au cours des 9 000 premières étapes de l'entraînement, 5 à 20 % des calques de CLIP présentent un sous-débit dégradé, tandis que les calques de Yolo ne présentent qu'un sous-débit occasionnel. Le taux de sous-débit dans CLIP augmente également avec le temps, rendant l'entraînement moins stable.
L'utilisation de la mise à l'échelle du gradient ne résout pas ce problème car l'amplitude du gradient dans la plage CLIP est beaucoup plus grande que l'amplitude du gradient dans la plage YOLO. Dans le cas de CLIP, alors que le scaler de gradient rapproche les gradients les plus importants du maximum dans le FP16, les gradients les plus petits restent en dessous du minimum.
Dans certains cas, l'ajustement des paramètres du scaler de gradient peut aider à éviter le débordement. Dans le cas de CLIP, on pourrait essayer des modifications pour commencer avec un multiplicateur plus grand et raccourcir l'intervalle d'augmentation.

Mais nous avons constaté que le multiplicateur chute immédiatement pour éviter tout débordement et forcer le petit gradient à revenir à zéro.

Une solution pour améliorer la mise à l'échelle est de la rendre plus adaptable à la plage de paramètres. Par exemple, l'article Adaptive Loss Scaling for Mixed Precision Training recommande d'effectuer une mise à l'échelle des pertes par couche plutôt que par l'ensemble du modèle, ce qui peut empêcher le sous-débordement. Et nos expériences démontrent la nécessité d’une approche plus adaptative. Étant donné que les gradients au sein de la couche CLIP couvrent toujours toute la plage FP16, la mise à l'échelle doit être adaptée à chaque paramètre individuel pour garantir la stabilité de l'entraînement. Mais une mise à l’échelle aussi détaillée nécessite beaucoup de mémoire, ce qui réduit la taille du lot de formation.
Un matériel plus récent offre des solutions plus efficaces. Par exemple, BFloat16 (BF16) est un autre type de données 16 bits qui échange la précision contre une plus grande portée. FP16 gère 5,96e-8 à 65 504, tandis que BF16 peut gérer 1,17e-38 à 3,39e38, la même plage que FP32. Cependant, la précision de BF16 est inférieure à celle de FP16, ce qui empêchera certains modèles de converger. Mais pour les modèles de gros transformateurs, il n’a pas été démontré que le BF16 réduisait la convergence.
Nous effectuons le même test en insérant un lot d'observations difficiles, dans BF16, le gradient augmente lorsque des cas difficiles sont introduits, puis revient à l'entraînement régulier car la mise à l'échelle du gradient ne se produit jamais dans le gradient en raison de l'augmentation de la plage NaN observée.

En comparant le CLIP du FP16 et du BF16, nous avons constaté qu'il n'y a que des dépassements de gradient occasionnels dans BF16.

Dans PyTorch 1.12 et supérieur, il est possible d'activer BF16 avec une petite modification d'AMP.

Si vous avez besoin d'une plus grande précision, vous pouvez essayer le type de données Tensorfloat32 (TF32). TF32, introduit par Nvidia dans les GPU Ampere, est une virgule flottante de 19 bits qui ajoute les bits de plage supplémentaires du BF16 tout en conservant la précision du FP16. Contrairement au FP16 et au BF16, il est conçu pour remplacer directement le FP32, plutôt que d'être activé en précision mixte. Pour activer TF32 dans PyTorch, ajoutez deux lignes au début de la formation.

Quelque chose à noter ici : avant PyTorch 1.11, TF32 était activé par défaut sur les GPU prenant en charge ce type de données. À partir de PyTorch 1.11, il doit être activé manuellement. La vitesse d'entraînement du TF32 est plus lente que celle du BF16 et du FP16. Le FLOPS théorique n'est que la moitié de celui du FP16, mais il est toujours beaucoup plus rapide que la vitesse d'entraînement du FP32.
Si vous utilisez Amazon AWS : BF16 et TF32 sont disponibles sur les instances P4d, P4de, G5, Trn1 et DL1.
L'exemple ci-dessus illustre comment identifier et corriger les limitations à l'échelle du FP16. Mais ces problèmes apparaissent souvent plus tard dans la formation. Au début de la formation, lorsque le modèle génère des pertes plus élevées et est moins sensible aux valeurs aberrantes, comme cela se produit dans la formation OpenCLIP, cela peut prendre des jours avant que des problèmes ne surviennent, ce qui fait perdre un temps de calcul coûteux.
Le FP16 et le BF16 présentent tous deux des avantages et des inconvénients. Les limites du FP16 peuvent conduire à une formation instable et bloquée. Cependant, BF16 offre une précision moindre et peut avoir une convergence plus faible. Nous souhaitons donc absolument identifier les modèles sensibles à l'instabilité du FP16 dès le début de la formation afin de pouvoir prendre des décisions éclairées avant que l'instabilité ne se produise. Ainsi, encore une fois, en comparant les modèles qui présentent ou non une instabilité ultérieure de la formation, deux tendances peuvent être constatées.

Tant le modèle YOLO entraîné en FP16 que le modèle CLIP entraîné en BF16 montrent que le taux de sous-versement du gradient est généralement inférieur à 1% et est stable dans le temps.

Le modèle CLIP formé au FP16 a un taux de sous-débit de 5 à 10 % au cours des 1000 premières étapes de formation, et montre une tendance à la hausse au fil du temps.
Ainsi, en utilisant TCH pour suivre le taux de sous-versement du gradient, nous pouvons identifier la tendance à une instabilité de gradient plus élevée au cours des 4 à 6 premières heures d'entraînement. Passez au BF16 lorsque cette tendance est observée.
La formation de précision hybride est une partie importante de la formation de modèles de grande base existants, mais nécessite une attention particulière à la stabilité numérique. Comprendre l'état interne d'un modèle est important pour diagnostiquer quand un modèle rencontre les limites des types de données à précision mixte. En enveloppant le modèle avec un TCH, il est possible de déterminer si les paramètres ou les gradients s'approchent des limites numériques et d'effectuer des modifications d'entraînement avant que l'instabilité ne se produise, réduisant potentiellement le nombre de jours d'entraînements infructueux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment insérer de l'audio dans ppt
Comment insérer de l'audio dans ppt
 Utilisation de la fonction fscanf
Utilisation de la fonction fscanf
 Comment masquer l'adresse IP sur TikTok
Comment masquer l'adresse IP sur TikTok
 Téléchargement d'E-O Exchange
Téléchargement d'E-O Exchange
 Recommandation de classement des logiciels de détection de matériel informatique
Recommandation de classement des logiciels de détection de matériel informatique
 Introduction aux commandes courantes de postgresql
Introduction aux commandes courantes de postgresql
 index.html qu'est-ce que c'est
index.html qu'est-ce que c'est
 Comment connecter VB pour accéder à la base de données
Comment connecter VB pour accéder à la base de données








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



