



Avec la popularité de WeChat, de plus en plus de personnes commencent à utiliser WeChat. WeChat est progressivement passé d'un simple logiciel social à un mode de vie. Les gens ont besoin de WeChat pour la communication quotidienne, et WeChat est également nécessaire pour la communication professionnelle. Chaque ami de WeChat représente un rôle différent que les gens jouent dans la société.

L'article d'aujourd'hui effectuera une analyse des données sur les amis WeChat basée sur Python. Les dimensions sélectionnées ici incluent principalement : le sexe, l'avatar, la signature et l'emplacement. Les résultats sont principalement présentés sous forme de graphiques et de nuages de mots. , pour les informations textuelles, deux méthodes seront utilisées : l'analyse de la fréquence des mots et l'analyse des sentiments. Comme le dit le proverbe : si un travailleur veut bien faire son travail, il doit d'abord affûter ses outils. Avant de commencer officiellement cet article, permettez-moi de présenter brièvement les modules tiers utilisés dans cet article :
itchat : l'interface Web WeChat encapsule la version Python, qui est utilisée dans cet article pour obtenir des informations sur les amis WeChat.
jieba : La version Python de la segmentation des mots bégayants, utilisée dans cet article pour segmenter les informations textuelles.
matplotlib : un module de dessin de graphiques en Python, utilisé dans cet article pour dessiner des histogrammes et des diagrammes circulaires
snownlp : un module de segmentation de mots chinois en Python, utilisé dans cet article pour porter des jugements émotionnels sur des informations textuelles.
PIL : Le module de traitement d'images en Python, utilisé dans cet article pour traiter les images.
numpy : Le module de calcul numérique en Python, utilisé en conjonction avec le module wordcloud dans cet article.
wordcloud : le module de nuage de mots en Python est utilisé dans cet article pour dessiner des images de nuages de mots.
TencentYoutuyun : le SDK de la version Python fourni par Tencent Youtuyun est utilisé dans cet article pour reconnaître les visages et extraire les informations des balises d'image.
Les modules ci-dessus peuvent être installés via pip. Pour des instructions détaillées sur l'utilisation de chaque module, veuillez consulter la documentation correspondante.
La condition préalable à l'analyse des données des amis WeChat est d'obtenir des informations sur les amis. En utilisant le module itchat, tout cela deviendra très simple. Nous pouvons y parvenir grâce aux deux lignes de code suivantes :
itchat.auto_login(hotReload = True) friends = itchat.get_friends(update = True)
Log. Connectez-vous simultanément à la page Web Comme WeChat, nous pouvons nous connecter en scannant le code QR avec notre téléphone mobile. L'objet amis renvoyé ici est une collection et le premier élément est l'utilisateur actuel. Par conséquent, dans le processus d'analyse des données suivant, nous prenons toujours les amis[1:] comme données d'entrée originales. Chaque élément de la collection est une structure de dictionnaire. En me prenant comme exemple, vous pouvez remarquer qu'il y a le sexe, la ville et la province. , HeadImgUrl et Signature sont quatre champs. Notre analyse suivante partira de ces quatre champs :

Pour analyser le sexe des amis, nous devons d'abord obtenir les informations de sexe de tous les amis. Ici, nous allons extraire le champ Sexe des informations de chaque ami, puis compter respectivement les nombres d'hommes, de femmes et d'inconnus. Nous assemblons ces trois valeurs dans une liste, puis utilisons le module matplotlib pour dessiner un gâteau. graphique. Le code est implémenté comme suit :
def analyseSex(firends): sexs = list(map(lambda x:x['Sex'],friends[1:])) counts = list(map(lambda x:x[1],Counter(sexs).items())) labels = ['Unknow','Male','Female'] colors = ['red','yellowgreen','lightskyblue'] plt.figure(figsize=(8,5), dpi=80) plt.axes(aspect=1) plt.pie(counts, #性别统计结果 labels=labels, #性别展示标签 colors=colors, #饼图区域配色 labeldistance = 1.1, #标签距离圆点距离 autopct = '%3.1f%%', #饼图区域文本格式 shadow = False, #饼图是否显示阴影 startangle = 90, #饼图起始角度 pctdistance = 0.6 #饼图区域文本距离圆点距离 ) plt.legend(loc='upper right',) plt.title(u'%s的微信好友性别组成' % friends[0]['NickName']) plt.show()
Voici une brève explication de ce code. Il existe trois valeurs pour le champ de genre dans WeChat : Unkonw, Male et Female, et leurs valeurs correspondantes sont 0, 1 et 2 respectivement. Ces trois valeurs différentes sont comptées via Counter() dans le module Collection, et sa méthode items() renvoie une collection de tuples.
Le premier élément dimensionnel de ce tuple représente la clé, c'est-à-dire 0, 1, 2. Le deuxième élément dimensionnel de ce tuple représente le nombre, et l'ensemble de ce tuple est trié, c'est-à-dire que sa clé est conforme avec 0, 1, 2. 2, donc le nombre de ces trois valeurs différentes peut être obtenu via la méthode map(). Nous pouvons le transmettre à matplotlib pour le dessin. Les pourcentages de ces trois valeurs différentes sont calculés par. matplotlib. L'image suivante est la répartition par sexe des amis dessinés par matplotlib :
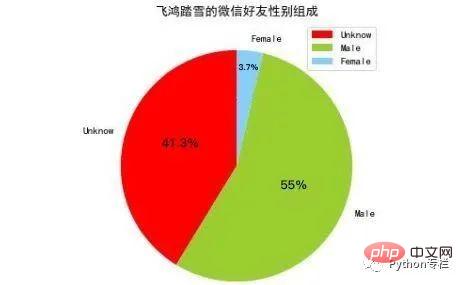
Analysez les avatars d'amis sous deux aspects. Premièrement, parmi ces avatars d'amis, la proportion d'amis qui utilisent des avatars à visage humain est Deuxièmement, quels mots-clés précieux peuvent être extraits de ces avatars d'amis.
Ici, vous devez télécharger l'avatar localement en fonction du champ HeadImgUrl, puis utiliser l'interface API liée à la reconnaissance faciale fournie par Tencent Youtu pour détecter s'il y a un visage dans l'image de l'avatar et extraire les balises dans l'image. Parmi eux, le premier est la classification et le résumé, et nous utilisons des diagrammes circulaires pour présenter les résultats ; le second est l'analyse de texte, et nous utilisons des nuages de mots pour présenter les résultats. Le code clé est le suivant :
def analyseHeadImage(frineds):
# Init Path
basePath = os.path.abspath('.')
baseFolder = basePath + '\HeadImages\'
if(os.path.exists(baseFolder) == False):
os.makedirs(baseFolder)
# Analyse Images
faceApi = FaceAPI()
use_face = 0
not_use_face = 0
image_tags = ''
for index in range(1,len(friends)):
friend = friends[index]
# Save HeadImages
imgFile = baseFolder + '\Image%s.jpg' % str(index)
imgData = itchat.get_head_img(userName = friend['UserName'])
if(os.path.exists(imgFile) == False):
with open(imgFile,'wb') as file:
file.write(imgData)
# Detect Faces
time.sleep(1)
result = faceApi.detectFace(imgFile)
if result == True:
use_face += 1
else:
not_use_face += 1
# Extract Tags
result = faceApi.extractTags(imgFile)
image_tags += ','.join(list(map(lambda x:x['tag_name'],result)))
labels = [u'使用人脸头像',u'不使用人脸头像']
counts = [use_face,not_use_face]
colors = ['red','yellowgreen','lightskyblue']
plt.figure(figsize=(8,5), dpi=80)
plt.axes(aspect=1)
plt.pie(counts, #性别统计结果
labels=labels, #性别展示标签
colors=colors, #饼图区域配色
labeldistance = 1.1, #标签距离圆点距离
autopct = '%3.1f%%', #饼图区域文本格式
shadow = False, #饼图是否显示阴影
startangle = 90, #饼图起始角度
pctdistance = 0.6 #饼图区域文本距离圆点距离
)
plt.legend(loc='upper right',)
plt.title(u'%s的微信好友使用人脸头像情况' % friends[0]['NickName'])
plt.show()
image_tags = image_tags.encode('iso8859-1').decode('utf-8')
back_coloring = np.array(Image.open('face.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=800,
height=480,
margin=15
)
wordcloud.generate(image_tags)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()这里我们会在当前目录新建一个HeadImages目录,用于存储所有好友的头像,然后我们这里会用到一个名为FaceApi类,这个类由腾讯优图的SDK封装而来,这里分别调用了人脸检测和图像标签识别两个API接口,前者会统计”使用人脸头像”和”不使用人脸头像”的好友各自的数目,后者会累加每个头像中提取出来的标签。其分析结果如下图所示:
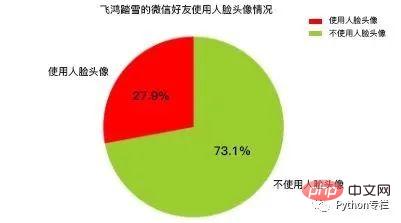
可以注意到,在所有微信好友中,约有接近1/4的微信好友使用了人脸头像, 而有接近3/4的微信好友没有人脸头像,这说明在所有微信好友中对”颜值 “有自信的人,仅仅占到好友总数的25%,或者说75%的微信好友行事风格偏低调为主,不喜欢用人脸头像做微信头像。
其次,考虑到腾讯优图并不能真正的识别”人脸”,我们这里对好友头像中的标签再次进行提取,来帮助我们了解微信好友的头像中有哪些关键词,其分析结果如图所示:

通过词云,我们可以发现:在微信好友中的签名词云中,出现频率相对较高的关键字有:女孩、树木、房屋、文本、截图、卡通、合影、天空、大海。这说明在我的微信好友中,好友选择的微信头像主要有日常、旅游、风景、截图四个来源。
好友选择的微信头像中风格以卡通为主,好友选择的微信头像中常见的要素有天空、大海、房屋、树木。通过观察所有好友头像,我发现在我的微信好友中,使用个人照片作为微信头像的有15人,使用网络图片作为微信头像的有53人,使用动漫图片作为微信头像的有25人,使用合照图片作为微信头像的有3人,使用孩童照片作为微信头像的有5人,使用风景图片作为微信头像的有13人,使用女孩照片作为微信头像的有18人,基本符合图像标签提取的分析结果。
分析好友签名,签名是好友信息中最为丰富的文本信息,按照人类惯用的”贴标签”的方法论,签名可以分析出某一个人在某一段时间里状态,就像人开心了会笑、哀伤了会哭,哭和笑两种标签,分别表明了人开心和哀伤的状态。
这里我们对签名做两种处理,第一种是使用结巴分词进行分词后生成词云,目的是了解好友签名中的关键字有哪些,哪一个关键字出现的频率相对较高;第二种是使用SnowNLP分析好友签名中的感情倾向,即好友签名整体上是表现为正面的、负面的还是中立的,各自的比重是多少。这里提取Signature字段即可,其核心代码如下:
def analyseSignature(friends):
signatures = ''
emotions = []
pattern = re.compile("1fd.+")
for friend in friends:
signature = friend['Signature']
if(signature != None):
signature = signature.strip().replace('span', '').replace('class', '').replace('emoji', '')
signature = re.sub(r'1f(d.+)','',signature)
if(len(signature)>0):
nlp = SnowNLP(signature)
emotions.append(nlp.sentiments)
signatures += ' '.join(jieba.analyse.extract_tags(signature,5))
with open('signatures.txt','wt',encoding='utf-8') as file:
file.write(signatures)
# Sinature WordCloud
back_coloring = np.array(Image.open('flower.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=960,
height=720,
margin=15
)
wordcloud.generate(signatures)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordcloud.to_file('signatures.jpg')
# Signature Emotional Judgment
count_good = len(list(filter(lambda x:x>0.66,emotions)))
count_normal = len(list(filter(lambda x:x>=0.33 and x<=0.66,emotions)))
count_bad = len(list(filter(lambda x:x<0.33,emotions)))
labels = [u'负面消极',u'中性',u'正面积极']
values = (count_bad,count_normal,count_good)
plt.rcParams['font.sans-serif'] = ['simHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel(u'情感判断')
plt.ylabel(u'频数')
plt.xticks(range(3),labels)
plt.legend(loc='upper right',)
plt.bar(range(3), values, color = 'rgb')
plt.title(u'%s的微信好友签名信息情感分析' % friends[0]['NickName'])
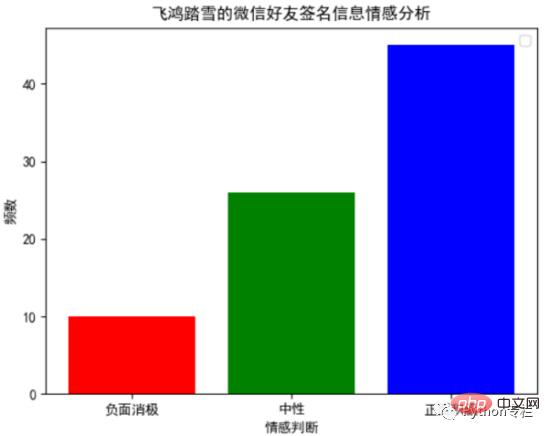
plt.show()通过词云,我们可以发现:在微信好友的签名信息中,出现频率相对较高的关键词有:努力、长大、美好、快乐、生活、幸福、人生、远方、时光、散步。

通过以下柱状图,我们可以发现:在微信好友的签名信息中,正面积极的情感判断约占到55.56%,中立的情感判断约占到32.10%,负面消极的情感判断约占到12.35%。这个结果和我们通过词云展示的结果基本吻合,这说明在微信好友的签名信息中,约有87.66%的签名信息,传达出来都是一种积极向上的态度。
分析好友位置,主要通过提取Province和City这两个字段。Python中的地图可视化主要通过Basemap模块,这个模块需要从国外网站下载地图信息,使用起来非常的不便。
百度的ECharts在前端使用的比较多,虽然社区里提供了pyecharts项目,可我注意到因为政策的改变,目前Echarts不再支持导出地图的功能,所以地图的定制方面目前依然是一个问题,主流的技术方案是配置全国各省市的JSON数据。
这里我使用的是BDP个人版,这是一个零编程的方案,我们通过Python导出一个CSV文件,然后将其上传到BDP中,通过简单拖拽就可以制作可视化地图,简直不能再简单,这里我们仅仅展示生成CSV部分的代码:
def analyseLocation(friends):
headers = ['NickName','Province','City']
with open('location.csv','w',encoding='utf-8',newline='',) as csvFile:
writer = csv.DictWriter(csvFile, headers)
writer.writeheader()
for friend in friends[1:]:
row = {}
row['NickName'] = friend['NickName']
row['Province'] = friend['Province']
row['City'] = friend['City']
writer.writerow(row)下图是BDP中生成的微信好友地理分布图,可以发现:我的微信好友主要集中在宁夏和陕西两个省份。
这篇文章是我对数据分析的又一次尝试,主要从性别、头像、签名、位置四个维度,对微信好友进行了一次简单的数据分析,主要采用图表和词云两种形式来呈现结果。总而言之一句话,”数据可视化是手段而并非目的”,重要的不是我们在这里做了这些图出来,而是从这些图里反映出来的现象,我们能够得到什么本质上的启示,希望这篇文章能让大家有所启发。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



