


La nouvelle génération d'images en perspective (NVS) est un domaine d'application de la vision par ordinateur. Dans le jeu SuperBowl de 1998, le RI de la CMU a fait la démonstration du NVS avec la vision stéréo multi-caméras (MVS). Chaîne de télévision des États-Unis, mais elle n’a finalement pas été commercialisée ; la société britannique BBC Broadcasting Company a investi dans la recherche et le développement à cet effet, mais elle n’a pas été véritablement commercialisée.
Dans le domaine du rendu basé sur l'image (IBR), les applications NVS ont une branche, à savoir le rendu basé sur l'image en profondeur (DBIR). De plus, la télévision 3D, qui était très populaire en 2010, devait également obtenir des effets stéréoscopiques binoculaires à partir de la vidéo monoculaire, mais en raison de l'immaturité de la technologie, elle n'est finalement pas devenue populaire. À cette époque, les méthodes basées sur l’apprentissage automatique commençaient déjà à être étudiées. Par exemple, Youtube utilisait des méthodes de recherche d’images pour synthétiser des cartes de profondeur.
J'ai introduit l'application du deep learning dans NVS il y a quelques années : Nouvelle méthode de génération d'images en perspective basée sur le deep learning
Récemment, les champs de rayonnement neuronal (NeRF) sont devenus une représentation réaliste de scènes et de photos synthétiques Un exemple efficace d'image, son application la plus directe est NVS. Une limitation majeure du NeRF traditionnel est qu'il est souvent impossible de générer des rendus de haute qualité à de nouveaux points de vue très différents du point de vue de la formation. Ce qui suit est une discussion de la méthode de généralisation du NeRF. L'introduction de base des principes du NeRF est ignorée ici. Si vous êtes intéressé, veuillez vous référer au document de synthèse :
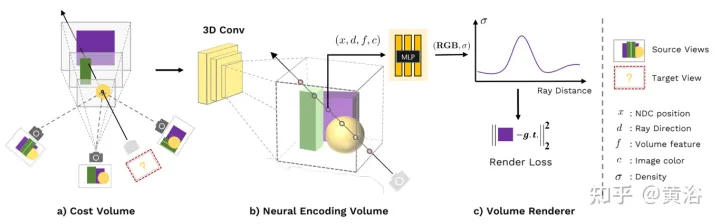
L'article [2] proposé Nous proposons un réseau neuronal profond général, MVSNeRF, qui se généralise à travers les scènes et déduit des champs de rayonnement reconstruits à partir de seulement trois vues d'entrée proches. La méthode utilise des volumes numérisés en plan (largement utilisés dans la vision stéréo multi-vues) pour un raisonnement de scène tenant compte de la géométrie et les combine avec un rendu de volume basé sur la physique pour la reconstruction du champ de rayonnement neuronal.
Cette méthode exploite le succès du MVS profond pour appliquer des convolutions 3D sur des volumes de coûts afin de former des réseaux de neurones généralisables pour les tâches de reconstruction 3D. Contrairement à la méthode MVS, qui effectue uniquement une inférence de profondeur sur une telle entité de coût, ce réseau effectue une inférence sur la géométrie et l'apparence de la scène et génère des champs de rayonnement neuronal, permettant ainsi la synthèse de vues. Plus précisément, à l'aide d'un CNN 3D, un volume de codage de scène neuronale est reconstruit (à partir du volume d'origine), composé de caractéristiques neuronales au niveau voxel codant des informations sur la géométrie et l'apparence de la scène locale. Ensuite, un perceptron multicouche (MLP) décode la densité volumique et la radiance à des emplacements consécutifs arbitraires dans le volume codé à l’aide de caractéristiques neuronales interpolées de manière trilinéaire. Essentiellement, le volume de codage est une représentation neuronale locale du champ de rayonnement ; une fois estimé, il peut être directement utilisé (en éliminant le CNN 3D) pour une marche de rayons différentiable pour le rendu final.
Par rapport aux méthodes MVS existantes, MVSNeRF permet un rendu neuronal différenciable, s'entraîne sans supervision 3D et optimise le temps d'inférence pour améliorer encore la qualité. Par rapport aux méthodes de rendu neuronal existantes, une architecture de type MVS est naturellement capable de raisonner par correspondance entre vues, ce qui permet de généraliser à des scènes de test invisibles et conduit à une meilleure reconstruction et un meilleur rendu des scènes neuronales.
La figure 1 est un aperçu de MVSNeRF : (a) Sur la base des paramètres de la caméra, déformez d'abord (transformation homographique) les caractéristiques de l'image 2D sur un balayage plan (balayage plan) pour construire une ontologie de coût basée sur la variance qui l'encode ; explique les changements d'apparence de l'image entre différentes vues d'entrée, en tenant compte des changements d'apparence provoqués par la géométrie de la scène et les effets de lumière et d'obscurité liés à la vue (b) CNN 3D est ensuite utilisé pour reconstruire un volume de code neuronal de caractéristiques neuronales au niveau voxel ; 3D CNN est un UNet 3D, qui peut déduire et propager efficacement les informations sur l'apparence de la scène pour produire des volumes d'encodage de scène significatifs ; Remarque : ce volume d'encodage est prédit et déduit de manière non supervisée à l'aide du rendu de volume dans une formation de bout en bout ; les pixels de l'image originale sont fusionnés dans l'étape de régression de volume suivante, de sorte que les hautes fréquences perdues lors du sous-échantillonnage puissent être récupérées ; (c) À l'aide de MLP, en codant les caractéristiques de l'interpolation de volume, la densité de volume et la radiance RVB peuvent être régressées à n'importe quelle position ; Ces attributs de volume peuvent être déterminés par le déplacement différentiel des rayons pour le rendu final.
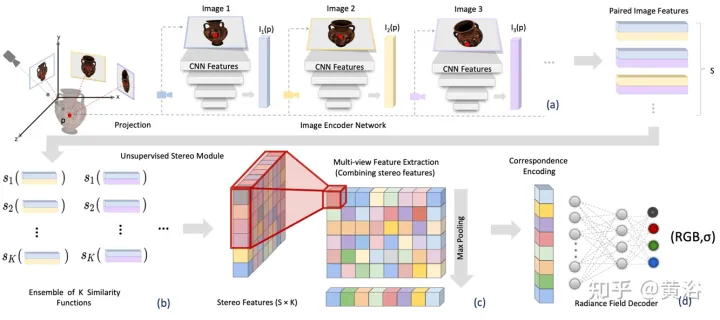
L'article [3] propose le champ de rayonnement stéréo (SRF), une méthode de synthèse de vues neuronales entraînées de bout en bout qui peut se généraliser à de nouvelles scènes et ne nécessite que des vues clairsemées pendant les tests. L'idée principale est une architecture neuronale inspirée de la méthode stéréo multi-vues classique (MVS) pour estimer des points de surface en trouvant des régions d'image similaires dans des images stéréo. Entrez 10 vues dans le réseau d'encodeurs et extrayez des fonctionnalités multi-échelles. Les perceptrons multicouches (MLP) remplacent les patchs d'image classiques ou la correspondance de fonctionnalités, produisant un ensemble de scores de similarité. Dans SRF, chaque point 3D reçoit un codage de son homologue stéréoscopique dans l'image d'entrée, et sa couleur et sa densité sont prédites à l'avance. Cet encodage est appris implicitement grâce à l'ensemble de similitudes par paires - simulant la vision stéréo classique.
Paramètres de caméra connus, étant donné un ensemble de N images de référence, SRF prédit la couleur et la densité des points 3D. Construisez le modèle SRF f, similaire à la méthode classique de vision stéréo multi-vues : (1) Pour coder la position d'un point, projetez-le dans chaque vue de référence et construisez un descripteur de caractéristiques locales ; (2) Si sur une surface ; et les photos sont cohérentes, les descripteurs de caractéristiques doivent correspondre ; une fonction apprise est utilisée pour simuler la correspondance des caractéristiques, et les caractéristiques de toutes les vues de référence sont codées ; (3) Le codage est décodé par un décodeur appris et devient une représentation NeRF ; . La figure 2 donne un aperçu de SRF : (a) extraire les caractéristiques de l'image ; (b) simuler le processus de recherche de cohérence des photos grâce à une fonction de similarité apprise et obtenir une matrice de caractéristiques tridimensionnelles (SFM) ; (c) recueillir des informations pour obtenir ; Matrice de fonctionnalités multi-vues (MFM); (d) La mise en commun maximale obtient un codage compact de la correspondance et de la couleur, qui est décodé pour obtenir la densité de couleur et de volume.
L'article [4] propose DietNeRF, une représentation de scène neuronale 3D estimée à partir de plusieurs images. Il introduit une perte de cohérence sémantique auxiliaire qui encourage un rendu réaliste de nouvelles poses.
Lorsque seulement quelques vues sont disponibles dans NeRF, le problème de rendu n'est pas contraint ; NeRF souffre souvent de solutions dégénérées à moins d'être strictement régularisées. Comme le montre la figure 3 : (A) Lors de la prise de 100 observations d'un objet à partir de poses uniformément échantillonnées, NeRF estime une représentation détaillée et précise, permettant une synthèse de vues de haute qualité uniquement à partir de la cohérence multi-vues (B) dans le cas uniquement ; 8 vues, plaçant la cible dans le champ proche de la caméra d'entraînement, le même surajustement NeRF entraîne un désalignement de la cible et une dégradation de la pose à proximité de la caméra d'entraînement (C) Lors de la régularisation, de la simplification, Lorsqu'il est ajusté et réinitialisé à la main, NeRF peut converger mais ne capture plus les détails fins ; (D) Sans connaissance préalable d'objets similaires, la synthèse d'une vue de scène unique ne peut raisonnablement compléter les régions non observées.

La figure 4 est un diagramme schématique du travail de DietNeRF : Basé sur le principe « sous n'importe quel angle, un objet est cet objet », DietNeRF surveille le champ de rayonnement (caméra DietNeRF) dans n'importe quelle posture en calculant la sémantique ; la perte de cohérence réside dans la capture des attributs de scène de haut niveau dans l'espace des fonctionnalités, plutôt que dans l'espace des pixels ; utilisez donc CLIP, un transformateur visuel, pour extraire la représentation sémantique du rendu, puis maximiser la similitude avec la représentation de la vue de vérité terrain.
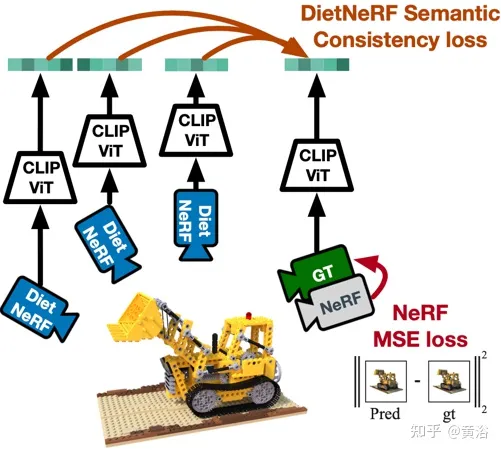
En fait, la connaissance préalable de la sémantique de la scène apprise par un encodeur d'image 2D à vue unique peut contraindre une représentation 3D. DietNeRF est formé à partir d'une collection de centaines de millions de photos 2D à vue unique extraites du Web sous supervision du langage naturel : (1) restitue correctement une vue d'entrée donnée à partir de la même pose, (2) fait correspondre la sémantique de haut niveau dans différentes propriété de poses aléatoires. La fonction de perte sémantique peut superviser le modèle DietNeRF à partir de poses arbitraires.
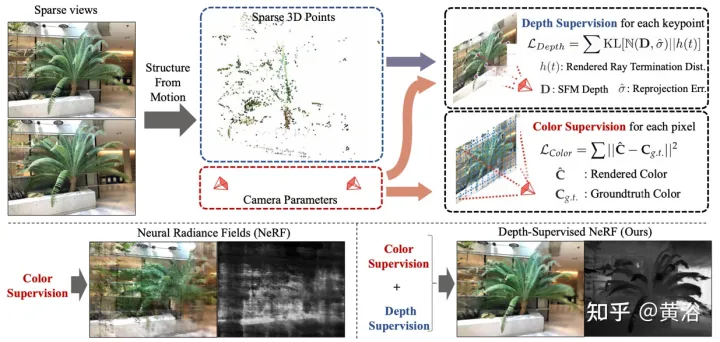
L'article [5] propose DS-NeRF, qui utilise une perte de champ de rayonnement d'apprentissage et utilise une supervision de carte de profondeur prête à l'emploi, comme le montre la figure 5. Il y a le fait que les pipelines NeRF actuels nécessitent des images avec des poses de caméra connues, qui sont généralement estimées via Structure from Motion (SFM). Surtout, SFM produit également des points 3D clairsemés qui sont utilisés pendant l’entraînement comme supervision de profondeur « gratuite » : en ajoutant une perte qui encourage la distribution de profondeur de terminaison d’un rayon à correspondre à un point clé 3D donné, y compris l’incertitude de profondeur.
L'article [6] propose pixelNeRF, un cadre d'apprentissage pour prédire des représentations continues de scènes neuronales basées sur une ou plusieurs images d'entrée. Il introduit une méthode entièrement convolutive pour ajuster l'architecture NeRF sur l'entrée d'image, permettant au réseau d'être formé sur plusieurs scènes pour apprendre la connaissance préalable d'une scène, afin qu'il puisse procéder à partir d'un ensemble clairsemé de vues (au moins une) dans une manière de rétroaction. Nouvelle composition de vue. Tirant parti de la méthode de rendu de volume de NeRF, pixelNeRF peut être entraîné directement à partir d'images sans supervision 3D supplémentaire.
Plus précisément, pixelNeRF calcule d'abord une grille de caractéristiques d'image entièrement convolutionnelle (grille de caractéristiques) à partir de l'image d'entrée et ajuste NeRF sur l'image d'entrée. Ensuite, pour chaque point d'espace de requête 3D x et direction de vue d d'intérêt dans le système de coordonnées de vue, les caractéristiques de l'image correspondantes sont échantillonnées par projection et interpolation bilinéaire. La spécification de la requête est envoyée avec les caractéristiques de l'image au réseau NeRF qui génère la densité et la couleur, où les caractéristiques de l'image spatiale sont transmises en tant que résidu à chaque couche. Lorsque plusieurs images sont disponibles, l'entrée est d'abord codée dans une représentation latente de chaque système de coordonnées de caméra, qui est fusionnée dans une couche intermédiaire avant de prédire la couleur et la densité. La formation du modèle est basée sur la perte de reconstruction entre une image de vérité terrain et une vue rendue en volume. Le cadre
pixelNeRF est illustré à la figure 6 : pour un point d'interrogation 3D x d'un rayon de caméra cible le long de la direction de vue d, , la caractéristique de l'image correspondante est extraite du volume de caractéristiques W par projection et interpolation ; la fonctionnalité est combinée avec Les coordonnées spatiales sont transmises ensemble dans le réseau NeRF f ; les valeurs RVB et de densité de sortie sont utilisées pour le rendu du volume et comparées aux valeurs des pixels cibles, les coordonnées x et d sont dans le système de coordonnées de la caméra de la vue d’entrée.
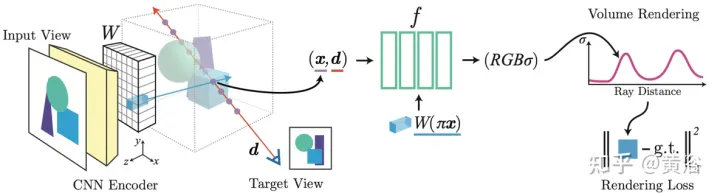
On peut voir que PixelNeRF et SRF utilisent des fonctionnalités CNN locales extraites de l'image d'entrée, tandis que MVSNeRF obtient un corps 3D par déformation d'image, qui est ensuite traité par un CNN 3D. Ces méthodes nécessitent un pré-entraînement sur de nombreux ensembles de données d’images multi-vues de différentes scènes, ce qui peut être coûteux à obtenir. De plus, malgré la longue phase de pré-formation, la plupart des méthodes nécessitent d'affiner les pondérations du réseau au moment du test, et la qualité des nouvelles vues peut facilement se dégrader lorsque le domaine de test change.
Bien sûr, DS-NeRF ajoute une supervision approfondie supplémentaire pour améliorer la précision de la reconstruction. Diet-NeRF compare CLIP aux intégrations de points de vue invisibles rendues à basse résolution. Cette perte de cohérence sémantique ne peut fournir que des informations de haut niveau et ne peut pas améliorer la géométrie de la scène des entrées clairsemées.
IBRNet proposé dans l'article [7], dont le noyau comprend le MLP et le transformateur de lumière (architecture classique du transformateur : codage de position et auto-attention), est utilisé pour estimer la radiance et la densité volumique de positions 5D continues (position spatiale 3D et visualisation 2D). direction) et restituez les informations d’apparence en temps réel à partir de plusieurs vues sources.
Lors du rendu, cette approche revient au travail classique de Rendu basé sur l'image (IBR). Contrairement aux représentations neuronales de scènes, qui optimisent chaque fonction de scène pour le rendu, IBRNet apprend une fonction d'interpolation de vue générale qui se généralise à de nouvelles scènes. Utilisant toujours le rendu de volume classique pour synthétiser les images, il est entièrement différenciable et entraîné avec des images de pose multi-vues comme supervision.
Le transformateur de rayon prend en compte ces caractéristiques de densité tout au long du rayon pour calculer la valeur de densité scalaire de chaque échantillon, permettant ainsi un raisonnement en visibilité sur des échelles spatiales plus grandes. Séparément, un module de fusion de couleurs dérive la couleur dépendant de la vue de chaque échantillon à l'aide des caractéristiques 2D et du vecteur de visée de la vue source. Enfin, le rendu volumique calcule la valeur de couleur finale pour chaque rayon.
Comme le montre la figure 7, vous trouverez un aperçu d'IBRNet : 1) Pour restituer la vue cible (image marquée "?"), identifiez d'abord un ensemble de vues source adjacentes (par exemple, les vues marquées A et B) et extrayez les caractéristiques de l'image. ; 2) Ensuite, pour chaque rayon dans la vue cible, IBRNet (zone ombrée en jaune) est utilisé pour calculer un ensemble de couleurs et de densités d'échantillon le long du rayon, spécifiquement, pour chaque échantillon, les informations correspondantes (couleur de l'image) sont agrégées ; la vue source adjacente, les caractéristiques et la direction de visualisation), génèrent ses caractéristiques de couleur c et de densité, puis appliquez le transformateur de rayons aux caractéristiques de densité de tous les échantillons sur la lumière pour prédire la valeur de densité ; 3) Enfin, utilisez le rendu de volume pour accumuler de la couleur et de la densité le long du rayon. Sur la couleur de l'image reconstruite, un entraînement à la perte L2 de bout en bout peut être effectué.
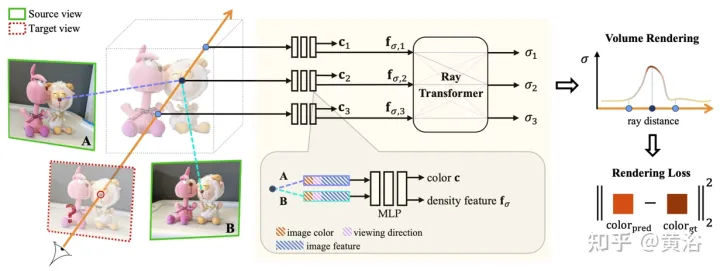
Comme le montre la figure 8, IBRNet est utilisé pour la prédiction de couleur et de densité de volume de positions 5D continues : premièrement, les caractéristiques de l'image 2D extraites de toutes les vues sources sont entrées dans un MLP similaire à PointNet, les informations locales et globales sont agrégées et multi -des caractéristiques de perception de vue sont générées en regroupant les poids, en utilisant des poids pour concentrer les caractéristiques, en effectuant un raisonnement sur la visibilité multi-vues et en obtenant des caractéristiques de densité au lieu de prédire directement la densité σ d'un seul échantillon 5D, le module de transformateur de rayons est utilisé pour agréger toutes les caractéristiques ; informations sur les échantillons le long du rayon ; le module de transformateur de rayon obtient les caractéristiques de densité pour tous les échantillons sur le rayon et prédit leur densité ; le module de transformateur de rayon permet un raisonnement géométrique sur de plus longues distances et améliore la prédiction de densité pour la prédiction des couleurs, les caractéristiques multi-vues sont combinées ; avec le rayon de requête relatif à la vue source Pour la direction de visualisation, un petit réseau est connecté à l'entrée pour prédire un ensemble de poids harmoniques, et la couleur de sortie c est la moyenne pondérée des couleurs de l'image de la vue source.
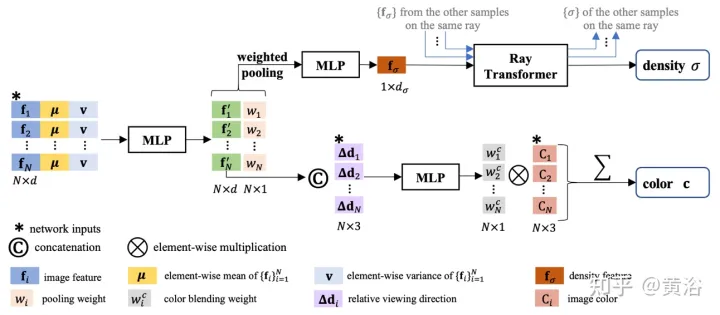
Encore une chose à ajouter ici : contrairement à NeRF qui utilise la direction de visualisation absolue, IBRNet considère la direction de visualisation par rapport à la vue source, c'est-à-dire la différence entre d et di, Δd=d−di . Un Δd plus petit signifie généralement que la couleur de la vue cible est plus susceptible d'être similaire à la couleur correspondante de la vue source i, et vice versa.
Le champ de rayonnement général (GRF) proposé dans l'article [8] représente et restitue des cibles et des scènes 3D uniquement à partir d'observations 2D. Le réseau modélise la géométrie 3D comme un champ de rayonnement universel, prend en entrée un ensemble d'images 2D, de poses extrinsèques de caméra et de paramètres intrinsèques, construit une représentation interne pour chaque point dans l'espace 3D, puis restitue l'apparence et la géométrie correspondantes vues depuis n'importe quel point. position. La clé est d'apprendre les caractéristiques locales de chaque pixel d'une image 2D, puis de projeter ces caractéristiques sur des points 3D, générant ainsi une représentation de points polyvalente et riche. De plus, un mécanisme d'attention est intégré pour regrouper les caractéristiques des pixels de plusieurs vues 2D afin de prendre implicitement en compte les problèmes d'occlusion visuelle.
La figure 9 est un diagramme schématique de GRF : GRF projette chaque point 3D p sur chacune des M images d'entrée, collecte les caractéristiques de chaque pixel de chaque vue, agrège et alimente MLP et en déduit la densité de couleur et de volume. de p.
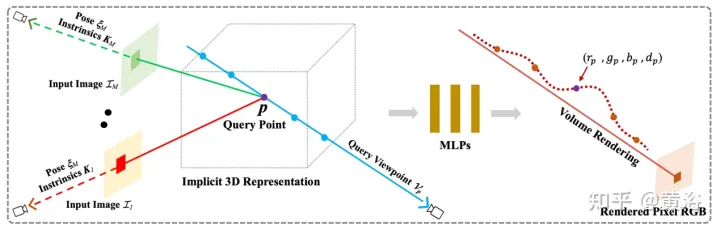
GRF se compose de quatre parties : 1) Extracteur de caractéristiques pour chaque pixel 2D, un encodeur-décodeur basé sur CNN ; 2) Reprojection de caractéristiques 2D dans l'espace 3D ; 3) Obtention universelle de points 3D Agrégateur d'attention basé sur les caractéristiques ; 4) Rendu neuronal NeRF.
Étant donné qu'il n'y a pas de valeur de profondeur associée à l'image RVB, il n'y a aucun moyen de déterminer à quel point de surface 3D spécifique appartient la caractéristique de pixel. Dans le module de reprojection, les caractéristiques des pixels sont considérées comme des représentations de chaque position le long du rayon dans l'espace 3D. Formellement, étant donné un point 3D, une vue d'observation 2D, la pose de la caméra et les paramètres intrinsèques, les caractéristiques des pixels 2D correspondants peuvent être récupérées via une opération de reprojection.
Dans l'agrégateur de fonctionnalités, le mécanisme d'attention apprend des poids uniques pour toutes les fonctionnalités d'entrée, puis les agrège. Grâce à un MLP, la couleur et la densité volumique des points 3D peuvent être déduites.
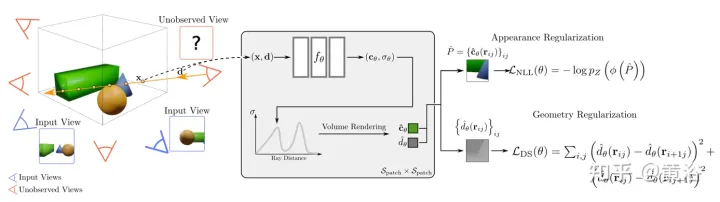
L'article [9] propose RegNeRF pour régulariser la géométrie et l'apparence des patchs d'image rendus à partir de points de vue non observés, et recuire l'espace d'échantillonnage de la lumière pendant l'entraînement. De plus, un modèle de flux normalisé est utilisé pour régulariser les couleurs des points de vue non observés.
La figure 10 est un aperçu du modèle RegNeRF : étant donné un ensemble de collections d'images d'entrée (caméra bleue), NeRF optimise la perte de reconstruction cependant, pour des entrées clairsemées, cela conduit à des solutions dégénérées ; caméra) et régulariser la géométrie et l'apparence des patchs d'image rendus à partir de ces vues ; plus spécifiquement, pour un champ de rayonnement donné, projeter un rayon à travers la scène et restituer les patchs d'image à partir d'un point de vue non observé, puis le modèle de flux normalisé formé est alimenté ; prédit les patchs d'image RVB et maximise la vraisemblance log des prédictions, régularisant ainsi l'apparence ; forcer une perte de douceur sur les patchs de profondeur rendus régularise la géométrie ; la méthode conduit à des représentations cohérentes en 3D, même pour des entrées clairsemées qui restituent de nouvelles vues réalistes.
L'article [10] étudie une méthode d'extrapolation de nouvelles vues au lieu de la synthèse d'images sur quelques échantillons, c'est-à-dire que (1) l'image d'entraînement peut bien décrire la cible, (2) la distribution des points de vue d'entraînement et tester points de vue Il existe une différence significative entre eux, appelée RapNeRF (RAy Priors NeRF).
L'idée de l'article [10] est que l'apparence inhérente de toute projection visible d'une surface 3D doit être cohérente. Par conséquent, il propose une stratégie de diffusion de rayons aléatoire qui permet d’entraîner des vues invisibles avec des vues vues. De plus, la qualité de rendu de la vue extrapolée peut être encore améliorée sur la base d'un atlas de rayons précalculé le long de la ligne de visée du rayon d'observation. Une limitation majeure est que RapNeRF exploite la cohérence multi-vues pour éliminer l'effet d'une forte corrélation de vues.
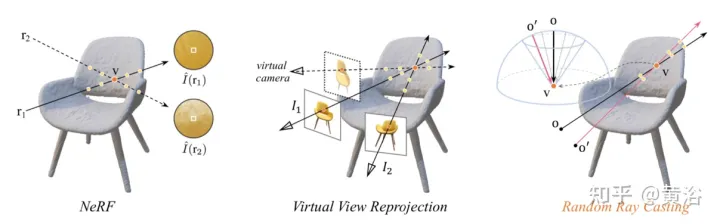
L'explication intuitive de la stratégie de lancer de rayons aléatoires est présentée dans la figure 11 : dans l'image de gauche, il y a deux rayons observant le point 3D v, r1 est situé dans l'espace d'entraînement et r2 est loin de l'entraînement. rayon ; compte tenu de la distribution de NeRF La fonction de dérive et de cartographie Fc:(r,f)→c , certaines de ses radiances d'échantillon le long de r2 seront inexactes le long de r2 est plus susceptible de fournir la couleur inverse ; de v que la couleur du pixel Estimation ; L'image du milieu est une simple reprojection de vue virtuelle, qui suit la formule NeRF pour calculer les rayons des pixels impliqués. Il est très gênant en pratique de trouver les rayons correspondant aux rayons virtuels frappant le même point 3D. à partir du pool de rayons d'entraînement ; à droite Dans la figure, pour un rayon d'entraînement spécifique (provenant de o et passant par v), la stratégie Random Ray Casting (RRC) génère aléatoirement un rayon virtuel invisible (provenant de o′ et passant par v) dans un cône, puis spécifiez une pseudo-étiquette en ligne basée sur le rayon d'entraînement. RRC prend en charge l'entraînement des rayons invisibles avec des rayons vus ;
La stratégie RRC permet d'attribuer des pseudo-étiquettes à des rayons virtuels générés aléatoirement de manière en ligne. Plus précisément, pour un pixel d'intérêt dans une image d'entraînement I, étant donné sa direction de visualisation d, l'origine de la caméra o et la valeur de profondeur tz dans son système de coordonnées mondial, et la lumière r=o +td. Ici, tz est précalculé et stocké à l'aide de NeRF pré-entraîné.
Supposons que v=o+tzd représente le point de surface 3D le plus proche touché par r. Pendant la phase d'entraînement, v est considéré comme la nouvelle origine, et un rayon est lancé au hasard depuis v à l'intérieur du cône, dont la ligne centrale est le vecteur vo¯=−tzd . Ceci peut être facilement réalisé en convertissant vo¯ en espace sphérique et en introduisant des perturbations aléatoires Δφ et Δθ en φ et θ. Ici, φ et θ sont respectivement les angles d'azimut et d'élévation de vo¯. Δφ et Δθ sont échantillonnés uniformément à partir de l'intervalle prédéfini [−η, η]. De là, nous obtenons θ′=θ+Δθ et φ′=φ+Δφ. Par conséquent, un rayon virtuel peut être lancé à partir d’une origine aléatoire o' qui passe également par v. De cette façon, la vraie valeur de l’intensité de la couleur I(r) peut être considérée comme le pseudo-étiquette de I~(r′).
Basic NeRF utilise « l'intégration directionnelle » pour coder les effets d'éclairage de la scène. Le processus d'ajustement de scène rend le MLP de prédiction des couleurs entraîné fortement dépendant de la direction du regard. Pour une nouvelle interpolation de vue, ce n'est pas un problème. Cependant, cela peut ne pas convenir à l'extrapolation de nouvelles vues en raison de certaines différences entre les distributions de lumière d'entraînement et de test. Une idée naïve serait de simplement supprimer l'intégration directionnelle (notée "NeRF sans dir"). Cependant, cela produit souvent des artefacts d’image tels que des ondulations inattendues et des couleurs non fluides. Cela signifie que la direction d’observation de la lumière peut également être liée à la douceur de la surface.
L'article [10] calcule un atlas de rayons et montre qu'il peut encore améliorer la qualité de rendu des vues extrapolées sans impliquer le problème des vues interpolées. Un atlas de rayons est similaire à un atlas de textures, mais il stocke la direction globale des rayons pour chaque sommet 3D.
En particulier, pour chaque image (par exemple, l'image I), les directions de visualisation de ses rayons sont saisies pour tous les emplacements spatiaux, générant ainsi une carte de rayons. Extrayez un maillage 3D approximatif (R3DM) à partir de NeRF pré-entraîné et mappez les directions des rayons vers les sommets 3D. En prenant le sommet V=(x,y,z) comme exemple, sa direction globale de la lumière d¯V devrait être exprimée par
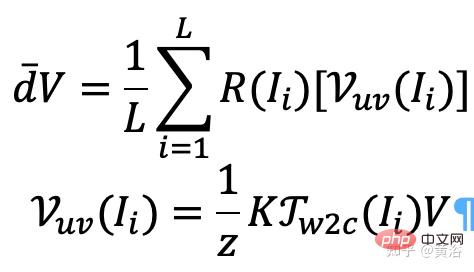
où K est le paramètre interne de la caméra, Γw2c(Ii) est la matrice de transformation du système de coordonnées caméra-monde de l'image Ii, Vuv(Ii) est la projection 2D du sommet V sur l'image Position Ii, L est le nombre d'images d'entraînement dans la reconstruction du sommet V. Pour chaque pixel d'une pose de caméra arbitraire, la projection d'un maillage 3D avec une texture de carte de rayons (R3DM) en 2D obtient un a priori de rayon global d¯ .
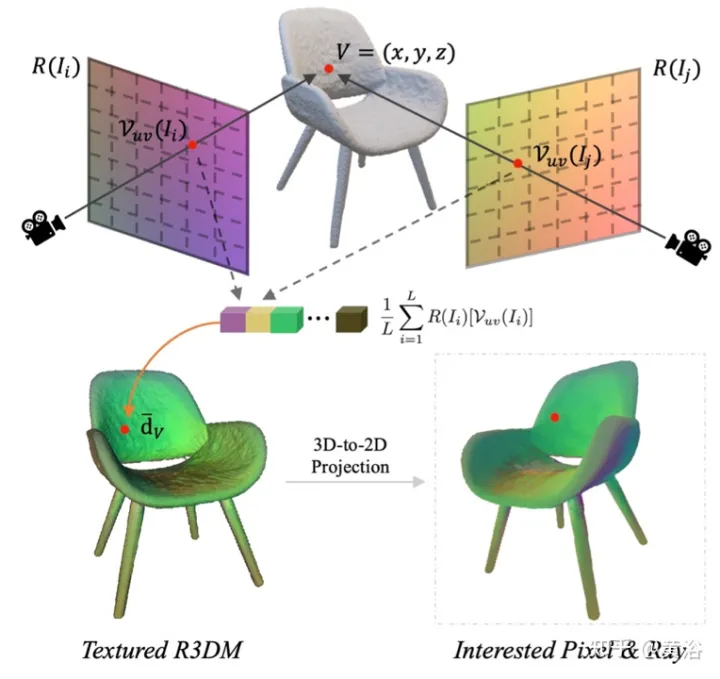
La figure 12 est un diagramme schématique de l'atlas de lumière : c'est-à-dire capturer un atlas de lumière à partir de la lumière d'entraînement et l'utiliser pour ajouter de la texture au maillage 3D brut (R3DM) de la chaise R(Ii) ; l'image d'entraînement Diagramme de rayons de II.
Lors de l'entraînement de RapNeRF, utilisez le d¯ du pixel d'intérêt I(r) pour remplacer son d dans Fc pour la prédiction des couleurs. La probabilité que ce mécanisme alternatif se produise est de 0,5. Pendant la phase de test, la radiance c de l'échantillon x est approximativement :
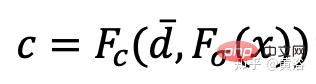
où la fonction de cartographie Fσ(x):x→(σ,f).
Original NeRF optimise chaque représentation de scène indépendamment, sans qu'il soit nécessaire d'explorer les informations partagées entre les scènes, et cela prend du temps. Pour résoudre ce problème, les chercheurs ont proposé des modèles tels que PixelNeRF et MVSNeRF, qui reçoivent plusieurs vues d'observateurs comme entrée conditionnelle et apprennent un champ de rayonnement neuronal universel. Suivant le principe de conception diviser pour régner, il se compose de deux composants indépendants : un extracteur de fonctionnalités CNN pour une seule image et un MLP en tant que réseau NeRF. Pour la vision stéréo à vue unique, dans ces modèles, le CNN mappe l'image sur une grille de caractéristiques et le MLP mappe les coordonnées 5D de la requête et leurs caractéristiques CNN correspondantes à une densité de volume unique et une couleur RVB dépendante de la vue. Pour la vision stéréo multi-vues, étant donné que CNN et MLP ne peuvent pas gérer un nombre quelconque de vues d'entrée, les coordonnées et les caractéristiques correspondantes dans le système de coordonnées de chaque vue sont d'abord traitées indépendamment, et des représentations intermédiaires conditionnées par l'image de chaque vue sont obtenues. Ensuite, un modèle auxiliaire basé sur le regroupement est utilisé pour agréger les représentations intermédiaires de vues au sein de ces réseaux NeRF. Dans les tâches de compréhension 3D, plusieurs vues fournissent des informations supplémentaires sur la scène.
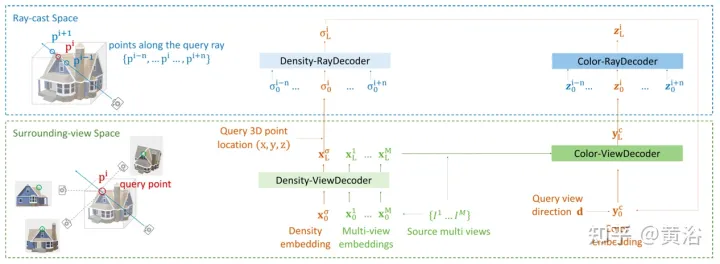
L'article [11] propose un cadre de transformateur codeur-décodeur TransNeRF pour caractériser la scène du champ de rayonnement neuronal. TransNeRF peut explorer les relations profondes entre plusieurs vues et regrouper les informations multi-vues dans des représentations de scène basées sur des coordonnées via un mécanisme d'attention NeRF unique basé sur Transformer. De plus, TransNeRF prend en compte les informations correspondantes de l’espace raycast et de l’espace de vue périphérique pour connaître la cohérence géométrique locale de la forme et de l’apparence de la scène.
Comme le montre la figure 13, TransNeRF restitue le point 3D interrogé dans un rayon de visualisation cible. TransNeRF comprend : 1) Dans l'espace périphérique, le décodeur de vue densité (Density-ViewDecoder) et le décodeur de vue couleur (Color-). ViewDecoder) intègre la vue source et les informations de l'espace de requête ((x,y,z),d) dans la densité latente et la représentation des couleurs du point de requête 3D ; 2) Dans l'espace de diffusion de rayons, utilisez le décodeur de rayons de densité (Densité ; -RayDecoder) et le décodeur de rayons colorés (Color-RayDecoder) prennent en compte les points adjacents le long du rayon de vue cible pour améliorer la densité des requêtes et la représentation des couleurs. Enfin, la densité volumique et la couleur directionnelle du point 3D interrogé sur la ligne de visée cible sont obtenues à partir de TransNeRF.
L'article [12] propose une méthode NVS généralisable avec entrée clairsemée, appelée FWD, qui fournit une synthèse d'image de haute qualité en temps réel. Avec une profondeur explicite et un rendu différentiel, FWD atteint une vitesse de 130 à 1 000x et une meilleure qualité perçue. S'il y a une intégration transparente de la profondeur du capteur pendant l'entraînement ou l'inférence, la qualité de l'image peut être améliorée tout en maintenant la vitesse en temps réel.
L'idée clé est que caractériser explicitement la profondeur de chaque pixel d'entrée permet d'appliquer une déformation vers l'avant à chaque vue d'entrée avec un rendu de nuage de points différenciable. Cela évite l'échantillonnage de volume coûteux des méthodes de type NeRF et permet d'obtenir une vitesse en temps réel tout en conservant une qualité d'image élevée.
SynSin [1] utilise un moteur de rendu de nuages de points différenciables pour la synthèse de nouvelles vues (NVS) sur une seule image. L'article [12] étend SynSin à plusieurs entrées et explore des méthodes efficaces pour fusionner des informations multi-vues.
FWD estime la profondeur de chaque vue d'entrée, crée un nuage de points de caractéristiques latentes, puis synthétise la nouvelle vue via un moteur de rendu de nuage de points. Afin d'atténuer le problème d'incohérence entre les observations de différents points de vue, la fonctionnalité MLP liée au point de vue est introduite dans le nuage de points pour modéliser les résultats liés au point de vue. Un autre module de fusion basé sur Transformer combine efficacement les fonctionnalités de plusieurs entrées. Un module de raffinement qui peut peindre les zones manquantes et améliorer encore la qualité de la composition. L'ensemble du modèle est formé de bout en bout, minimisant les pertes photométriques et perceptuelles, la profondeur d'apprentissage et les fonctionnalités qui optimisent la qualité de la composition.
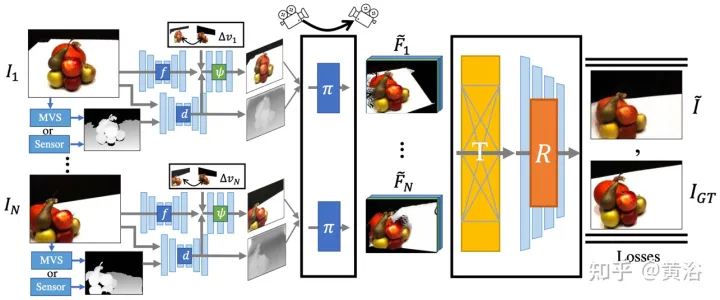
La figure 14 est un aperçu de FWD : étant donné un ensemble d'images clairsemées, utilisez le réseau de fonctionnalités f (basé sur l'architecture BigGAN), la fonctionnalité MLP liée à la vue ψ et le réseau profond d pour chaque image Ii Construit un nuage de points (incluant les informations géométriques et sémantiques de la vue) Pi En plus des images, d prend en entrée la profondeur estimée par MVS (basée sur PatchmatchNet) ou la profondeur du capteur, et régresse la profondeur raffinée ; basée sur les caractéristiques de l'image Fi et le changement de vue relatif Δv (basé sur les directions de vue normalisées vi et vt, c'est-à-dire du point au centre de la vue d'entrée i et vue cible t), par f et ψ fonctionnalités de régression pixel par pixel Fi′ ; utiliser un moteur de rendu de nuage de points différenciable π (éclaboussures) pour projeter et restituer le point nuage à la vue cible, c'est-à-dire F~i ; rendu Au lieu d'agréger directement les nuages de points de vue, le Transformer T fusionne les résultats de rendu d'un nombre quelconque d'entrées et applique le module de raffinement R pour décoder afin de produire le le résultat de l'image finale, qui répare sémantiquement et géométriquement les zones invisibles par l'entrée, corrige les erreurs locales causées par une profondeur inexacte et améliore la qualité de perception sur la base de la sémantique contenue dans les cartes de caractéristiques. La formation du modèle utilise la perte photométrique et la perte de contenu.
Les méthodes existantes pour reconstruire des objets 3D à l'aide de caractéristiques d'image locales projettent des caractéristiques d'image d'entrée sur des points 3D de requête pour prédire la couleur et la densité, déduisant ainsi la forme et l'apparence 3D. Ces modèles conditionnels d’image fonctionnent bien pour restituer des cartes de perspective cibles proches de la perspective d’entrée. Cependant, lorsque la perspective cible bouge trop, cette approche peut conduire à une occultation importante de la vue d'entrée, à une forte baisse de la qualité du rendu et à des prédictions floues.
Afin de résoudre le problème ci-dessus, l'article [13] propose une méthode pour utiliser des caractéristiques globales et locales pour former une représentation 3D compressée. Les fonctionnalités globales sont apprises à partir d'un transformateur visuel, tandis que les fonctionnalités locales sont extraites d'un réseau convolutif 2D. Pour synthétiser une nouvelle vue, un réseau MLP est formé pour obtenir un rendu de volume basé sur la représentation 3D apprise. Cette représentation permet la reconstruction de régions invisibles sans avoir besoin de contraintes imposées telles que la symétrie ou les systèmes de coordonnées canoniques.
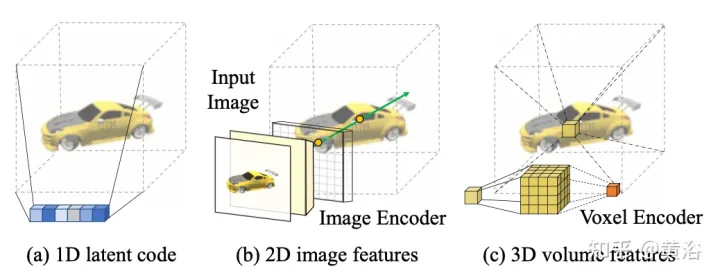
Étant donné qu'une seule image est à la caméra s, la tâche est de synthétiser une nouvelle vue à la caméra t. Si un point 3D x est visible dans l'image source, sa couleur Is(π(x)) peut être utilisée directement, où π représente la projection dans la vue source, indiquant que le point est visible dans une nouvelle vue. Si x est masqué, recourir à des informations autres que la couleur π(x) projetée. Comme le montre la figure 15, il existe trois solutions possibles pour obtenir ce type d'informations : (a) Général NeRF est une méthode basée sur un code latent 1D qui code les informations de cible 3D dans des vecteurs 1D. Étant donné que différents points 3D partagent le même code, le le biais inductif est limité ; (b) les méthodes basées sur l'image 2D reconstruisent n'importe quel point 3D à partir des caractéristiques de l'image pixel par pixel. De telles représentations favorisent une meilleure qualité de rendu dans les zones visibles et sont plus efficaces en termes de calcul, mais le rendu devient flou pour les zones invisibles ; c) ) La méthode basée sur les voxels 3D traite la cible 3D comme une collection de voxels et applique une convolution 3D pour générer la couleur RVB et le vecteur de densité σ, ce qui rend le rendu plus rapide et utilise pleinement les a priori 3D pour restituer le géométrie invisible, mais limite la résolution du rendu en raison de la taille du voxel et du champ de réception limité.
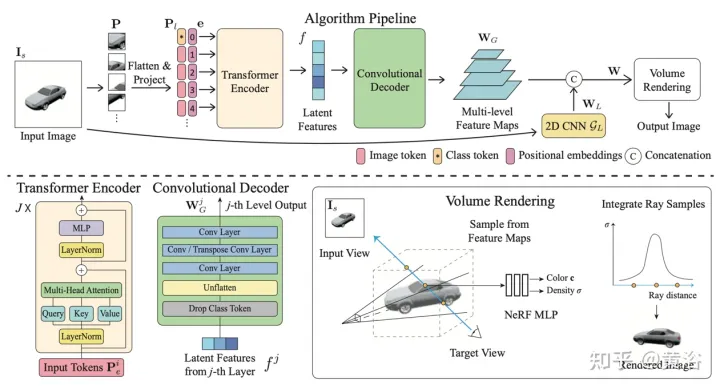
La figure 6 est un aperçu de la méthode de rendu hybride global-local [13] : Premièrement, l'image d'entrée est divisée en N=8×8 blocs d'image P ; Projeté sur le jeton d'image (jeton) P1 ; l'encodeur de transformateur prend le jeton d'image et la position apprenable intégrant e comme entrée, extrayant les informations globales sous la forme d'un ensemble de caractéristiques latentes f, puis les caractéristiques latentes sont décodées en plusieurs niveaux ; avec un décodeur convolutif Feature map WG ; En plus des caractéristiques globales, un autre modèle CNN 2D est utilisé pour obtenir des caractéristiques d'image locales, enfin, le modèle NeRF MLP est utilisé pour échantillonner les caractéristiques du rendu volumique ;
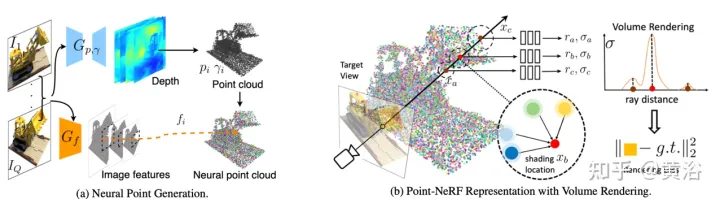
L'article [14] propose Point-NeRF, qui combine les avantages du NeRF et du MVS et utilise des nuages de points neuronaux 3D et des caractéristiques neuronales associées pour modéliser le champ de rayonnement. Point-NeRF peut être rendu efficacement en agrégeant des caractéristiques de points neuronaux à proximité de la surface de la scène dans un pipeline de rendu basé sur la marche de rayons. De plus, l'inférence directe à partir d'un réseau profond pré-entraîné initialise Point-NeRF pour générer un nuage de points neuronal ; le nuage de points peut être affiné pour dépasser la qualité visuelle de NeRF et s'entraîner 30 fois plus rapidement. Point-NeRF est combiné avec d'autres méthodes de reconstruction 3D et adopte un mécanisme de croissance et d'élagage, c'est-à-dire une croissance dans des zones à forte densité volumique et un élagage dans des zones à faible densité volumique, pour optimiser les données de nuages de points reconstruits.
Un aperçu de Point-NeRF est présenté dans la figure 17 : (a) À partir d'images multi-vues, Point-NeRF génère de la profondeur pour chaque vue à l'aide d'un CNN 3D basé sur le coût et le volume et extrait les caractéristiques 2D de l'image d'entrée via un CNN 2D Après avoir agrégé la carte de profondeur, un champ de rayonnement basé sur des points est obtenu, où chaque point a une position spatiale, une confiance et des caractéristiques d'image non projetées (b) Pour synthétiser une nouvelle vue, un déplacement de rayon différentiable est effectué et uniquement dans ; le nuage de points neuronaux calcule la lumière et l'obscurité à proximité ; à chaque position claire et sombre, Point-NeRF agrège les caractéristiques de ses K voisins de points neuronaux et calcule l'éclat et la densité corporelle, puis utilise l'accumulation de densité corporelle pour additionner l'éclat. L'ensemble du processus peut être entraîné de bout en bout et les champs de rayonnement basés sur des points peuvent être optimisés grâce aux pertes de rendu.
GRAF (Generative Radiance Field)[18] est un modèle de génération de champ de rayonnement qui réalise la synthèse d'images 3D haute résolution et l'entraînement du modèle en introduisant un discriminateur basé sur des patchs multi-échelles. Seules les images 2D prises par des caméras à pose inconnue sont requises.
Le but est d'apprendre un modèle pour synthétiser de nouvelles scènes en s'entraînant sur des images non traitées. Plus précisément, un cadre contradictoire est utilisé pour former un modèle génératif de champs de rayonnement (GRAF).
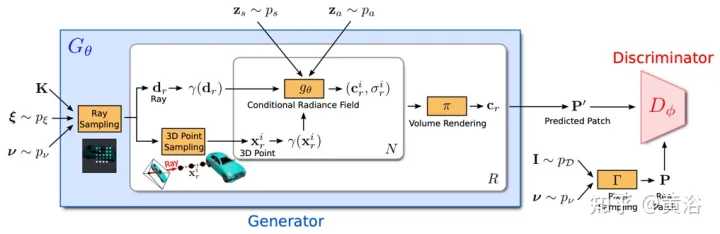
La Figure 18 montre un aperçu du modèle GRAF : le générateur prend la matrice de la caméra K, la pose de la caméra ξ, le mode d'échantillonnage 2D ν et le code de forme/apparence en entrée et prédit un patch d'image P′ ; Le discriminateur compare le patch synthétique P′ avec le patch P extrait de l'image réelle I, prédit une couleur pour chaque valeur de pixel de l'image ; ; cependant, cette opération est trop coûteuse au moment de la formation, donc un patch fixe de taille K×Kpixels est prédit, qui est mis à l'échelle et tourné de manière aléatoire pour fournir le gradient pour l'ensemble du champ de rayonnement.
Déterminez le centre et l'échelle pour générer le patch virtuel K×K. Les centres de patch aléatoires proviennent d'une distribution uniforme sur le domaine d'image Ω, tandis que les échelles de patch s proviennent d'une distribution uniforme, où W et H représentent la largeur et la hauteur de l'image cible. Les variables de forme et d'apparence sont échantillonnées à partir des distributions de forme et d'apparence et , respectivement. Dans les expériences, les deux utilisent la distribution gaussienne standard.
Le champ de rayonnement est représenté par un réseau neuronal profond entièrement connecté, où les paramètres θ mappent l'encodage de la position 3D x et la direction de visualisation d aux valeurs de couleur RVB c et densité volumique σ :
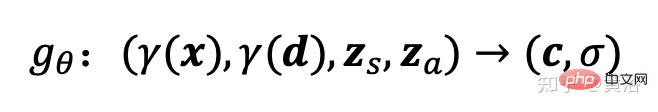
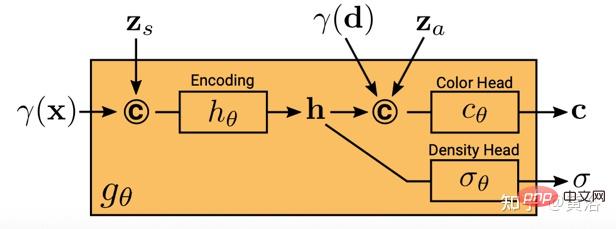
ici gθ dépend de deux codes latents supplémentaires : l'un est le code de forme zs détermine la forme cible, et un code d'apparence za détermine l'apparence. Ici, gθ est appelé champ de rayonnement conditionnel, et sa structure est illustrée à la figure 19 : Premièrement, le code de forme h est calculé en fonction du code de position et du code de forme de x ; la tête de densité σθ code ceci Convertir en densité volumique σ ; pour prédire la couleur c à la position 3D x, concaténer l'encodage de position de h avec d et l'apparent code za, et transmets le vecteur résultant à la tête de couleur cθ ; calcule σ indépendamment du point de vue d, encourageant la cohérence multi-vues et la séparation de la forme et de l'apparence ; le réseau devant utiliser deux codes latents pour séparer la forme et l'apparence est modélisé et peut être traité séparément lors de l'inférence.
Le discriminateur est implémenté comme un réseau neuronal convolutif et compare le patch prédit P′ avec le patch P extrait de la distribution de données pD image réelle I . Pour extraire un patch K×K d'une image réelle I, extrayez d'abord v=(u,s) de la même distribution pv utilisée pour extraire le patch générateur ci-dessus puis, par requête d'interpolation bilinéaire ; I à la coordonnée de l'image 2D P(u,s), et échantillonnez le vrai patch P. Utilisez Γ(I,v) pour représenter cette opération d'échantillonnage bilinéaire.
Des expériences ont montré qu'un seul discriminateur avec des poids partagés est suffisant pour tous les patchs, même si les patchs sont échantillonnés à des endroits aléatoires et à différentes échelles. Remarque : L'échelle détermine le champ de réception du patch. Par conséquent, pour faciliter la formation, commencez par un champ réceptif plus large pour capturer le contexte global. Ensuite, des patchs avec des champs récepteurs plus petits sont progressivement échantillonnés pour affiner les détails locaux.
GIRAFFE[19] est utilisé pour générer des scènes de manière contrôlable et réaliste tout en s'entraînant sur des images brutes non structurées. Les principales contributions portent sur deux aspects : 1) La représentation combinée de la scène 3D est directement incorporée dans le modèle génératif pour obtenir une synthèse d'image plus contrôlable. 2) Combinez cette représentation 3D explicite avec un pipeline de rendu neuronal pour permettre une inférence plus rapide et des images plus réalistes. À cette fin, la représentation de la scène est une combinaison de champs de caractéristiques neuronales générés, comme le montre la figure 20 : pour une caméra échantillonnée de manière aléatoire, une image caractéristique de la scène est rendue en volume sur la base d'un seul champ de caractéristiques neuronal 2D ; le réseau de rendu convertit l'image caractéristique en images RVB ; seules les images originales sont utilisées pendant la formation, et le processus de formation de l'image peut être contrôlé pendant les tests, y compris la pose de la caméra, la pose de la cible, ainsi que la forme et l'apparence de la cible en plus du modèle ; s'étend au-delà de la gamme des données d'entraînement, par exemple, il peut synthétiser des images contenant des ratios Scènes avec plus d'objets dans les images d'entraînement.
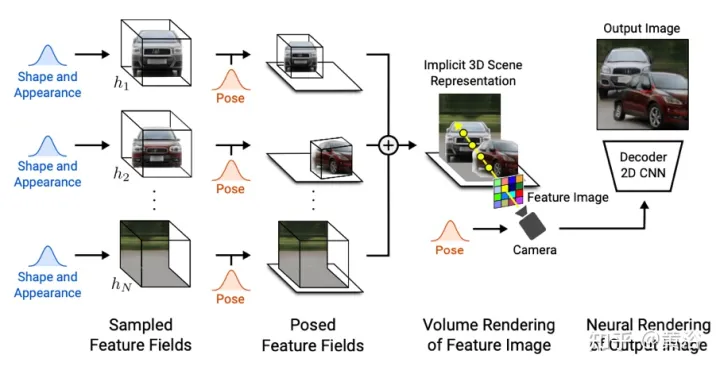
Rendez le volume de la scène en une image caractéristique de résolution relativement basse, ce qui permet d'économiser du temps et des calculs. Le moteur de rendu neuronal traite ces images de caractéristiques et génère le rendu final. De cette manière, la méthode peut obtenir des images de haute qualité et s’adapter à des scènes réelles. Lorsqu’elle est formée sur une collection d’images brutes non structurées, cette méthode permet une synthèse d’images contrôlable de scènes à un ou plusieurs objets.
Lors de la combinaison de scènes, il y a deux situations à considérer : N fixe et N changeant (la dernière est l'arrière-plan). En pratique, l'arrière-plan est représenté en utilisant la même représentation que la cible, sauf que les paramètres d'échelle et de translation sont fixes sur l'ensemble de la scène et centrés autour de l'origine de l'espace de la scène.
Le poids de l'opérateur de rendu 2D mappe l'image caractéristique à l'image synthétique finale, qui peut être paramétrée comme un CNN 2D avec activation ReLU qui fuit, et combinée avec une convolution 3x 3 et un suréchantillonnage du voisin le plus proche pour augmenter la résolution spatiale. La dernière couche applique l'opération sigmoïde pour obtenir la prédiction d'image finale. Son diagramme schématique est présenté à la figure 21.
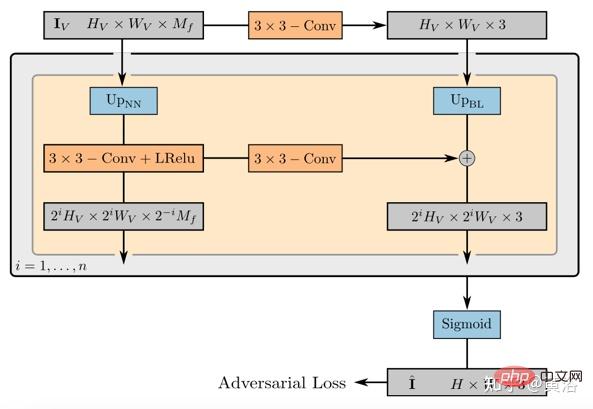
Le discriminateur est également un CNN avec une activation ReLU qui fuit.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
 Méthodes de chiffrement courantes pour le stockage de données chiffrées
Méthodes de chiffrement courantes pour le stockage de données chiffrées
 Quel système est Android
Quel système est Android
 Que signifie un entier non signé ?
Que signifie un entier non signé ?
 Touches de raccourci pour changer de fenêtre
Touches de raccourci pour changer de fenêtre
 emplacement.hash
emplacement.hash
 Caractéristiques de l'outil de téléchargement raysource
Caractéristiques de l'outil de téléchargement raysource
 Comment désactiver le téléchargement automatique de WeChat
Comment désactiver le téléchargement automatique de WeChat








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



