


Article arXiv « VectorFlow : Combining Images and Vectors for Traffic Occupancy and Flow Prediction », 9 août 2022, travaillant à l'Université Tsinghua.

Prédire le comportement futur des agents routiers est une tâche clé de la conduite autonome. Bien que les modèles existants aient connu un grand succès dans la prédiction du comportement futur des agents, prédire efficacement le comportement coordonné de plusieurs agents reste un défi. Récemment, quelqu'un a proposé la représentation champs de flux d'occupation (OFF) pour représenter l'état futur commun des agents routiers grâce à une combinaison de grilles d'occupation et de flux, soutenant des prédictions conjointement cohérentes.
Ce travail propose un nouveau prédicteur de champs de flux d'occupation, un encodeur d'image qui apprend les caractéristiques des images de trafic rastérisées et un encodeur vectoriel qui capture la trajectoire continue des agents et les informations sur l'état de la carte. Les deux sont combinés pour générer des prédictions précises d'occupation et de flux. Les deux fonctionnalités d'encodage sont fusionnées par plusieurs modules d'attention avant de générer la prédiction finale. Le modèle s'est classé troisième dans le défi Waymo Open Dataset Occupancy and Flow Prediction Challenge et a obtenu les meilleures performances dans la tâche de prédiction d'occupation et de débit occluse. La représentation
OFF ("Occupancy Flow Fields for Motion Forecasting in Autonomous Driving", arXiv 2203.03875, 3, 2022) est une grille spatio-temporelle dans laquelle chaque cellule de la grille comprend i) la probabilité qu'un agent occupe la cellule et ii) Représente le flux de mouvement de l'agent occupant l'unité. Il offre une meilleure efficacité et évolutivité car la complexité informatique de la prévision des champs de flux d'occupation est indépendante du nombre d'agents routiers dans la scène.
Comme le montre l’image, le diagramme du cadre OFF. La structure du codeur est la suivante. La première étape reçoit les trois types de points d'entrée et les traite avec des encodeurs inspirés de PointPillars. Les feux de circulation et les points routiers sont placés directement sur la grille. Le codage d'état de l'agent à chaque pas de temps d'entrée t consiste à échantillonner uniformément une grille de points de taille fixe à partir de chaque boîte BEV d'agent et à combiner ces points avec les attributs d'état d'agent pertinents (y compris le codage à chaud du temps t ) placés sur la grille. Chaque pilier génère une intégration pour tous les points qu'il contient. La structure du décodeur est la suivante. Le deuxième niveau reçoit chaque pilier intégré en entrée et génère des prévisions d'occupation et de débit par cellule de grille. Le réseau de décodeurs est basé sur EfficientNet, utilisant EfficientNet comme épine dorsale pour traiter chaque intégration de pilier afin d'obtenir des cartes de fonctionnalités (P2,... P7), où Pi est sous-échantillonné 2^i à partir de l'entrée. Le réseau BiFPN est ensuite utilisé pour fusionner ces fonctionnalités multi-échelles de manière bidirectionnelle. Ensuite, la carte de caractéristiques P2 à la plus haute résolution est utilisée pour régresser les prédictions d'occupation et de flux pour toutes les classes d'agents K à tous les pas de temps. Plus précisément, le décodeur génère un vecteur pour chaque cellule de la grille tout en prédisant l'occupation et le flux.
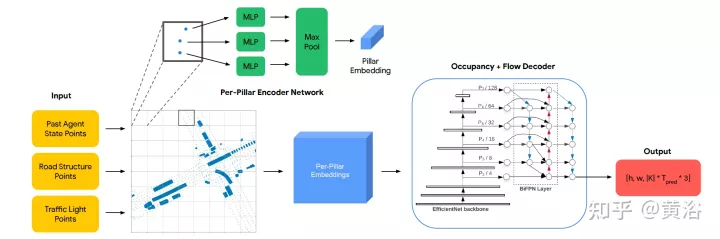
Pour cet article, le paramétrage du problème suivant est effectué : étant donné l'historique d'une seconde de l'agent de circulation dans la scène et le contexte de la scène, tel que les coordonnées de la carte, l'objectif est de prédire i) l'occupation future observée, ii) le taux d'occupation d'occlusion futur, et iii) le flux futur de tous les véhicules à 8 points de cheminement dans le futur dans un scénario où chaque point de cheminement couvre un intervalle de 1 seconde.
Traitez l'entrée dans une image pixellisée et un ensemble de vecteurs. Pour obtenir l'image, une grille rastérisée est créée à chaque pas de temps dans le passé par rapport aux coordonnées locales de la voiture autonome (SDC), compte tenu de la trajectoire de l'agent d'observation et des données cartographiques. Pour obtenir une entrée vectorisée cohérente avec l'image rastérisée, les mêmes transformations sont suivies, en faisant pivoter et en déplaçant l'agent d'entrée et les coordonnées de la carte par rapport à la vue locale du SDC.
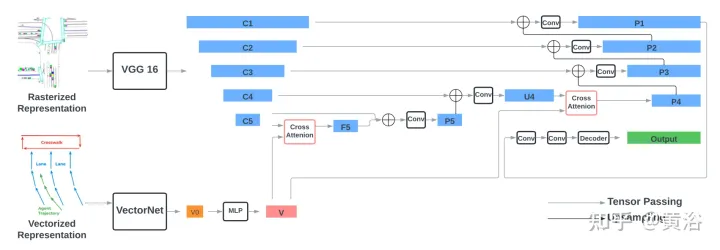
L'encodeur se compose de deux parties : le modèle VGG-16 qui encode la représentation rastérisée et le modèle VectorNe qui encode la représentation vectorisée. Les caractéristiques vectorisées sont fusionnées avec les caractéristiques des deux dernières étapes de VGG-16 via le module d'attention croisée. Grâce au réseau de type FPN, les fonctionnalités fusionnées sont suréchantillonnées à la résolution d'origine et utilisées comme fonctionnalités rastérisées en entrée. Le
Decoder est une seule couche convolutive 2D qui mappe la sortie de l'encodeur à une prédiction des champs de flux d'occupation, qui consiste en une série de 8 cartes de grille représentant les prédictions d'occupation et de flux pour chaque pas de temps au cours des 8 prochaines secondes.
Comme le montre l'image :
Utilisez le modèle VGG-16 standard de torchvision comme encodeur de rastérisation et suivez la mise en œuvre de VectorNet (codehttps://github.com/Tsinghua-MARS-Lab/DenseTNT) . L'entrée dans VectorNet consiste en i) un ensemble de vecteurs d'éléments routiers de forme B×Nr×9, où B est la taille du lot, Nr=10000 est le nombre maximum de vecteurs d'éléments routiers, et la dernière dimension 9 représente chaque vecteur et l'ID du vecteur La position (x, y) et la direction (cosθ, sinθ) des deux points finaux ii) un ensemble de vecteurs d'agent de forme B×1280×9, comprenant des vecteurs pouvant contenir jusqu'à 128 agents dans la scène, où chaque agent Avec 10 vecteurs à partir de la position d'observation.
Suivez VectorNet, exécutez d'abord la carte locale en fonction de l'ID de chaque élément de trafic, puis exécutez la carte globale sur toutes les entités locales pour obtenir des entités vectorisées de forme B×128×N, où N est le nombre total d'éléments de trafic , y compris les éléments routiers et l'intelligence. La taille de l'élément est encore augmentée quatre fois via la couche MLP pour obtenir l'élément vectoriel final V, dont la forme est B × 512 × N, et sa taille d'élément est cohérente avec la taille du canal de l'élément d'image.
Les caractéristiques de sortie de chaque niveau de VGG sont représentées par {C1, C2, C3, C4, C5}, par rapport à l'image d'entrée et 512 dimensions cachées, les foulées sont de {1, 2, 4, 8, 16} pixels . La caractéristique vectorisée V est fusionnée avec la caractéristique d'image rastérisée C5 de forme B×512×16×16 via le module d'attention croisée pour obtenir F5 de même forme. L'élément de requête de l'attention croisée est la caractéristique d'image C5, qui est aplatie en une forme B × 512 × 256 avec 256 jetons, et les éléments Clé et Valeur sont la caractéristique vectorisée V avec N jetons.
Connectez ensuite F5 et C5 sur la dimension du canal, et passez à travers deux couches convolutives 3×3 pour obtenir P5 de forme B×512×16×16. P5 est suréchantillonné via le module de suréchantillonnage 2×2 de style FPN et connecté à C4 (B×512×32x32) pour générer U4 avec la même forme que C4. Un autre cycle de fusion est ensuite effectué entre V et U4, en suivant la même procédure, y compris une attention croisée, pour obtenir P4 (B × 512 × 32 × 32). Enfin, P4 est progressivement suréchantillonné par le réseau de style FPN et connecté à {C3, C2, C1} pour générer EP1 avec une forme de B×512×256×256. Passez P1 à travers deux couches convolutives 3 × 3 pour obtenir la caractéristique de sortie finale avec une forme de B × 128 × 256.
Le décodeur est une seule couche convolutive 2D avec une taille de canal d'entrée de 128 et une taille de canal de sortie de 32 (8 waypoints × 4 dimensions de sortie).
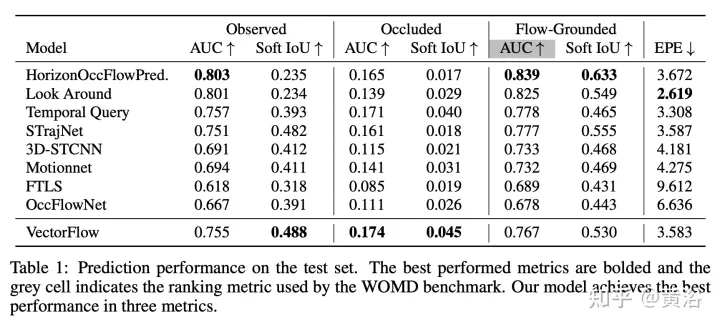
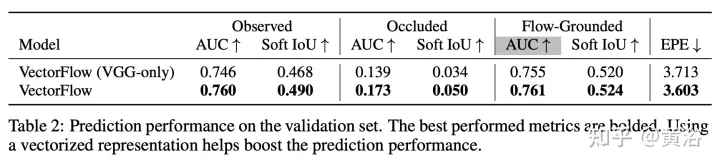
Les résultats sont les suivants :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment définir la zone de texte en lecture seule
Comment définir la zone de texte en lecture seule
 Les mots disparaissent après avoir tapé
Les mots disparaissent après avoir tapé
 Comment taper l'inscription sur le cercle de la pièce ?
Comment taper l'inscription sur le cercle de la pièce ?
 Comment créer un clone WeChat
Comment créer un clone WeChat
 Introduction aux touches de raccourci de capture d'écran dans Win8
Introduction aux touches de raccourci de capture d'écran dans Win8
 Comment conserver deux décimales en C++
Comment conserver deux décimales en C++
 Utilisation de la fonction étage
Utilisation de la fonction étage
 jsonp résout les problèmes inter-domaines
jsonp résout les problèmes inter-domaines








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



