


Vous avez sûrement regardé "Mission : Impossible 4" réalisé par Brad Bird et avec Tom Cruise ? Dans une gare bondée, il suffit d'un clin d'œil pour être reconnu par l'ordinateur et immédiatement suivi par les agents ; la belle femme qui le rencontre est une tueuse mortelle, et le téléphone portable émet un bip avec une alarme, et la belle le nom et les informations y sont déjà affichés. Il s'agit de l'algorithme de reconnaissance faciale que cet article souhaite présenter et de la manière d'utiliser la plate-forme d'IA du cloud public pour entraîner le modèle.
En tant que l'une des premières technologies matures et largement mises en œuvre dans le domaine de l'intelligence artificielle, le but de la reconnaissance faciale est de déterminer l'identité des visages dans les images et les vidéos. De la reconnaissance faciale pour déverrouiller et payer sur les téléphones mobiles, au contrôle de la reconnaissance faciale dans le domaine de la sécurité, etc., la technologie de reconnaissance faciale a un large éventail d'applications. Le visage est une caractéristique innée de chaque personne. Cette caractéristique est unique et ne peut pas être facilement copiée, constituant ainsi une condition préalable nécessaire à l'identification de l'identité.
La recherche sur la reconnaissance faciale a commencé dans les années 1960. Avec l'amélioration continue de la technologie informatique et de la technologie d'imagerie optique, et la résurgence de la technologie des réseaux neuronaux ces dernières années, les réseaux neuronaux convolutifs en particulier ont été largement utilisés dans la reconnaissance d'images et le grand. le succès de la détection a considérablement amélioré les performances du système de reconnaissance faciale. Dans cet article, nous commençons par les détails techniques de la technologie de reconnaissance faciale et vous donnons une compréhension préliminaire du processus de développement de la technologie de reconnaissance faciale. Dans la seconde moitié de l'article, nous utiliserons l'image personnalisée de la plateforme ModelArts pour vous montrer. comment utiliser les ressources informatiques du Cloud public peut rapidement former un modèle de reconnaissance faciale utilisable.
Qu'il soit basé sur la technologie traditionnelle de traitement d'image et d'apprentissage automatique, ou qu'il utilise la technologie d'apprentissage profond, le processus est le même. Comme le montre la figure 1, les systèmes de reconnaissance faciale comprennent quatre liens de base : la détection des visages, l'alignement, l'encodage et la correspondance. Par conséquent, cette partie donne d'abord un aperçu du système de reconnaissance faciale basé sur des algorithmes traditionnels de traitement d'image et d'apprentissage automatique, afin que nous puissions voir le contexte de développement de l'ensemble de l'algorithme d'apprentissage profond dans le domaine de la reconnaissance faciale.

Processus de détection de visage
Comme mentionné précédemment, le but de la reconnaissance faciale est de déterminer l'identité du visage dans l'image, vous devez donc d'abord identifier le visage dans l'image La détection des visages, en fait, cette étape est finalement un problème de détection de cible. L'algorithme traditionnel de détection de cible d'image se compose principalement de trois parties : la génération de trames de proposition, l'ingénierie des fonctionnalités et la classification. Les idées d'optimisation, y compris la célèbre série d'algorithmes RCNN, sont également basées sur ces trois parties.
La première étape consiste à générer le cadre de suggestion. L'idée la plus simple pour cette étape est de découper un groupe de cadres à détecter dans l'image, puis de détecter s'il y a une cible dans le cadre, si elle existe. , la position du cadre dans l'image d'origine est l'emplacement où la cible est détectée, donc plus la couverture de la cible à cette étape est grande, meilleure est la stratégie de génération de boîte de proposition. Les stratégies courantes de génération de boîtes à suggestions incluent la fenêtre coulissante, la recherche sélective, la sélection aléatoire, etc., qui génèrent un grand nombre de boîtes candidates, comme le montre la figure ci-dessous.

Après avoir obtenu un grand nombre de cadres candidats, la deuxième partie la plus importante de l'algorithme de détection de visage traditionnel est l'ingénierie des caractéristiques. L'ingénierie des fonctionnalités utilise en fait l'expérience experte des ingénieurs en algorithmes pour extraire diverses caractéristiques des visages dans différentes scènes, telles que les caractéristiques des bords, les caractéristiques de morphologie de forme, les caractéristiques de texture, etc. Les technologies d'algorithmes spécifiques incluent LBP, Gabor, Haar, SIFT, etc. L'algorithme convertit une image de visage représentée par une matrice bidimensionnelle en représentation de divers vecteurs de caractéristiques.
Après avoir obtenu le vecteur de caractéristiques, vous pouvez classer la caractéristique via des classificateurs d'apprentissage automatique traditionnels pour déterminer s'il s'agit d'un visage, par exemple via adaboost, cascade, SVM, forêt aléatoire, etc. Après classification par un classificateur traditionnel, la surface du visage, le vecteur de caractéristiques, la confiance de classification, etc. peuvent être obtenus. Avec ces informations, nous pouvons compléter l’alignement du visage, la représentation des caractéristiques et la reconnaissance de la correspondance des visages.
Prenons la méthode classique HAAR+AdaBoost comme exemple. Dans l'étape d'extraction des caractéristiques, les caractéristiques haar sont d'abord utilisées pour extraire de nombreuses caractéristiques simples de l'image. Les caractéristiques de Haar sont présentées dans la figure ci-dessous. Afin de répondre à la détection de visages de différentes tailles, les pyramides gaussiennes sont généralement utilisées pour extraire les caractéristiques de Haar à partir d'images de différentes résolutions.
La méthode de calcul de la fonction Haar consiste à soustraire la zone noire de la somme des pixels dans la zone blanche, de sorte que les valeurs obtenues sont différentes dans les zones avec et sans visage. Généralement, dans le processus de mise en œuvre spécifique, il peut être rapidement mis en œuvre grâce à la méthode du diagramme intégral. Généralement, dans les images d'entraînement normalisées à 20*20, le nombre de fonctionnalités Haar disponibles est d'environ 10 000. Par conséquent, avec cette échelle de fonctionnalités, les algorithmes d'apprentissage automatique peuvent être utilisés pour la classification et l'identification.
Après avoir obtenu les fonctionnalités Haar, vous pouvez utiliser Adaboost pour la classification. L'algorithme Adaboost est une méthode qui combine plusieurs méthodes de classification faibles pour former une nouvelle méthode de classification forte. Sur la base du classificateur en cascade et des seuils de sélection de caractéristiques entraînées, la détection de visage peut être complétée.
La méthode ci-dessus montre que l'algorithme d'apprentissage automatique traditionnel est un algorithme basé sur les fonctionnalités, il nécessite donc une grande expérience d'ingénieurs en algorithmes pour effectuer l'ingénierie des fonctionnalités et l'ajustement des paramètres, et l'effet de l'algorithme est pas très bon. De plus, il est très difficile pour une conception artificielle d’être robuste à différentes conditions changeantes dans un environnement sans contrainte. Dans le passé, les algorithmes d'image utilisaient des méthodes de traitement d'image plus traditionnelles par les ingénieurs pour extraire un grand nombre de caractéristiques basées sur des scènes réelles et l'expérience d'experts, puis effectuaient un apprentissage statistique sur les caractéristiques extraites de cette manière, les performances de l'algorithme global. est très dépendant des scènes réalistes et l'expérience des experts montre que l'effet n'est pas très bon pour les scènes sans contraintes avec d'énormes catégories telles que les visages et un sérieux déséquilibre des échantillons dans chaque catégorie. Par conséquent, avec le grand succès du deep learning dans le traitement d’images ces dernières années, la technologie de reconnaissance faciale s’appuie également sur le deep learning et a obtenu de très bons résultats.
Dans le système de reconnaissance faciale de l'apprentissage profond, le problème est divisé en un problème de détection de cible et un problème de classification. L'essence du problème de détection de cible dans l'apprentissage profond. est toujours un problème de classification et un problème de régression. Par conséquent, avec l'application réussie des réseaux de neurones convolutifs dans la classification d'images, l'effet des systèmes de reconnaissance faciale a été rapidement et considérablement amélioré. En conséquence, un grand nombre de sociétés d'algorithmes visuels ont été améliorées. né et humain La reconnaissance faciale est utilisée dans tous les aspects de la vie sociale.
En fait, utiliser des réseaux de neurones pour la reconnaissance des visages n'est pas une idée nouvelle. En 1997, des chercheurs ont proposé une méthode appelée réseau de neurones basée sur la prise de décision probabiliste pour la détection des visages, le positionnement des yeux et la reconnaissance des visages. Ce PDBNN de reconnaissance faciale est divisé en un sous-réseau entièrement connecté pour chaque sujet de formation afin de réduire le nombre d'unités cachées et d'éviter le surapprentissage. Les chercheurs ont formé deux PBDNN séparément en utilisant les caractéristiques de densité et de bord, puis ont combiné leurs résultats pour obtenir la décision finale de classification. Cependant, en raison de la grave pénurie de puissance de calcul et de données à l’époque, l’algorithme était relativement simple et n’a donc pas obtenu de très bons résultats. Avec la maturation de la théorie de la rétropropagation et des cadres de puissance de calcul seulement cette année, l'efficacité des algorithmes de reconnaissance faciale a commencé à être considérablement améliorée.
Dans l'apprentissage profond, un système complet de reconnaissance faciale comprend également les quatre étapes illustrées dans la figure 1. La première étape est appelée algorithme de détection de visage, qui est essentiellement un algorithme de détection de cible. La deuxième étape est appelée alignement du visage, qui repose actuellement sur un alignement géométrique des points clés et un alignement du visage basé sur le deep learning. La troisième étape est la représentation des caractéristiques. Dans l'apprentissage profond, grâce à l'idée de réseau de classification, certaines couches de caractéristiques du réseau de classification sont extraites en tant que représentation des caractéristiques du visage, puis l'image du visage standard est traitée de la même manière. et enfin par comparaison. La méthode de requête complète le système global de reconnaissance faciale. Ce qui suit est un bref aperçu du développement d’algorithmes de détection et de reconnaissance des visages.
Le deep learning a été rapidement utilisé pour le problème de la détection des visages après son grand succès dans la classification d'images. Au début, les idées pour résoudre ce problème reposaient principalement sur l'invariance d'échelle du réseau CNN, et sur le réseau CNN. les images ont été traitées différemment, puis ont effectué une inférence et prédit directement les informations de catégorie et de localisation. De plus, en raison de la régression directe de la position de chaque point de la carte des caractéristiques, la précision du cadre de visage obtenu est relativement faible. Par conséquent, certaines personnes ont proposé une stratégie de détection grossière à fine basée sur un classificateur à plusieurs étages. détecter les visages. Par exemple, la méthode principale est Cascade, DenseBox et MTCNN pour n'en nommer que quelques-unes.
MTCNN est une méthode multitâche. Pour la première fois, la détection de zone de visage et la détection de points clés de visage sont combinées, comme Cascade CNN, elle est également basée sur le cadre en cascade, mais l'idée générale est plus intelligente et. raisonnable. MTCNN De manière générale, il est divisé en trois parties : PNet, RNet et ONet. La structure du réseau est illustrée dans la figure ci-dessous.
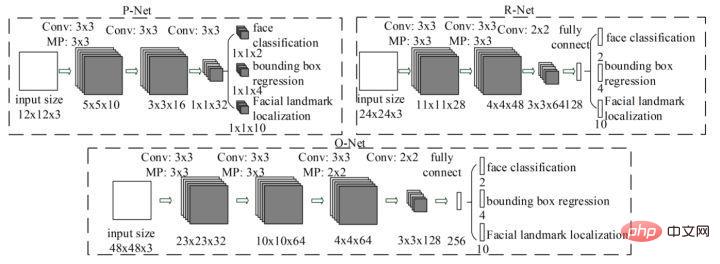
Tout d'abord, le réseau PNet redimensionne l'image d'entrée à différentes tailles. En entrée, il passe directement par deux couches de convolution et renvoie le cadre de classification des visages et de détection des visages. Après avoir recadré les visages grossièrement détectés de l'image d'origine, effectuez à nouveau la détection des visages sur l'entrée R-Net. Enfin, le visage obtenu est finalement entré dans O-Net, et le résultat de sortie O-Net obtenu est le résultat final de détection de visage. Le processus global du MTCNN est relativement simple et peut être déployé et mis en œuvre rapidement. Cependant, le MTCNN présente également de nombreuses lacunes. L'inclusion d'une formation à des tâches en plusieurs étapes prend du temps et la sauvegarde d'un grand nombre de résultats intermédiaires nécessite une grande quantité d'espace de stockage. De plus, étant donné que le réseau modifié effectue directement une régression de boîte englobante sur les points caractéristiques, l'effet sur la détection des petites faces cibles n'est pas très bon. De plus, pendant le processus d'inférence, afin de répondre aux besoins de détection de visages de différentes tailles, le réseau doit redimensionner les images de visages à différentes tailles, ce qui affecte sérieusement la vitesse d'inférence.
Avec le développement du domaine de la détection de cibles, de plus en plus de preuves expérimentales prouvent que davantage de goulots d'étranglement dans la détection de cibles résident dans la contradiction entre une sémantique de réseau de bas niveau mais une précision de positionnement relativement élevée et une sémantique de réseau de haut niveau mais un positionnement faible. Les réseaux de détection de cibles sont également devenus populaires avec les stratégies basées sur des ancres et les stratégies de fusion multicouche, telles que les célèbres séries Faster-rcnn, SSD et yolo. Par conséquent, les algorithmes de détection de visages utilisent de plus en plus d'ancres et de sorties multicanaux pour répondre aux effets de détection de visages de différentes tailles. L'algorithme le plus connu est la structure de réseau SSH.
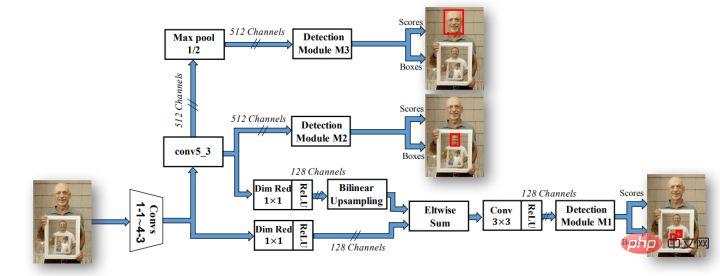
Comme vous pouvez le voir sur la figure ci-dessus, le réseau SSH dispose déjà de méthodes pour traiter la sortie de différentes couches du réseau. Il ne nécessite qu'une seule inférence pour terminer le processus de détection de visages de différentes tailles, c'est donc le cas. appelé étape unique. Le réseau SSH est également relativement simple, il effectue simplement des calculs de branchement et des sorties sur différentes couches convolutives de VGG. De plus, les fonctionnalités de haut niveau sont suréchantillonnées et Eltwise Sum est effectuée avec les fonctionnalités de bas niveau pour compléter la fusion des fonctionnalités de bas niveau et de haut niveau. De plus, le réseau SSH a également conçu un module de détection et un module contextuel. Le module contextuel, dans le cadre du module de détection, adopte la structure initiale pour obtenir plus d'informations contextuelles et un champ de réception plus large.
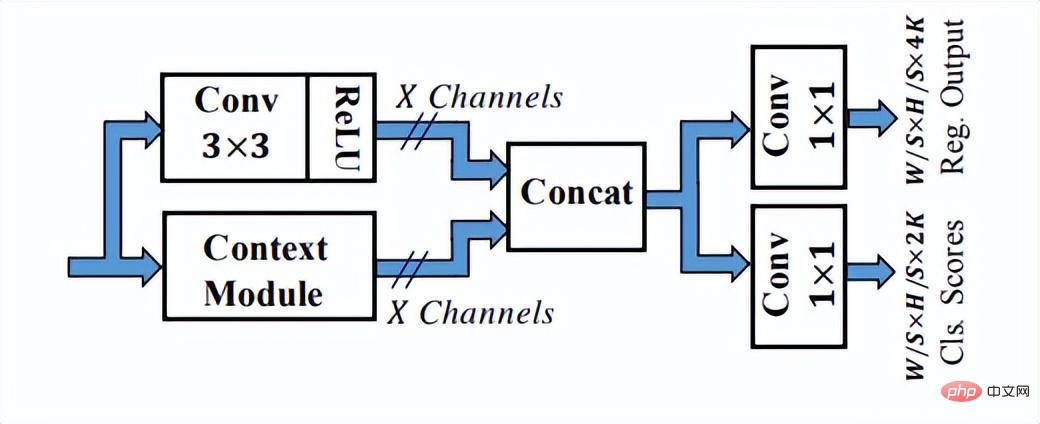
Le module de détection dans SSH
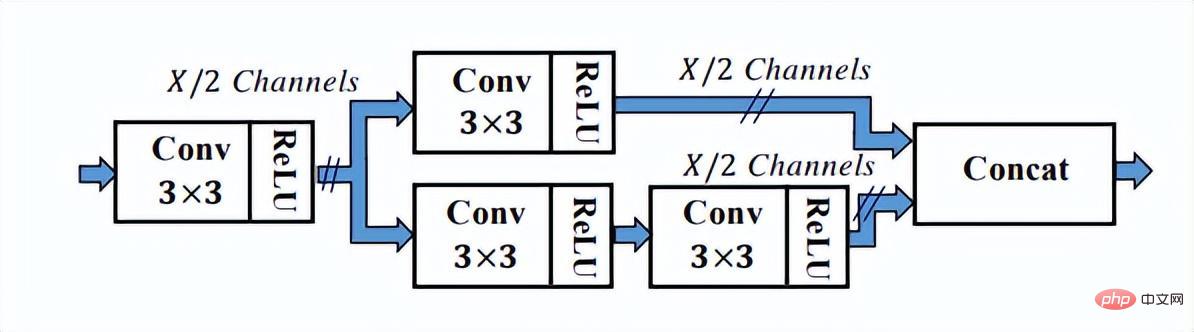
Le module de contexte dans le module de détection dans SSH
SSH utilise la convolution 1 × 1 pour générer les résultats finaux de la branche de régression et de classification, et n'utilise pas entièrement La couche connectée peut garantir que l'entrée d'images de différentes tailles peut obtenir le résultat de sortie, ce qui répond également à la tendance des méthodes de conception entièrement convolutives à cette époque. Malheureusement, le réseau ne génère pas de points de repère.De plus, la structure contextuelle n'utilise pas la structure pyramidale des fonctionnalités populaire.L'épine dorsale de VGG16 est également relativement superficielle.Avec les progrès continus de la technologie d'optimisation des visages, diverses astuces sont également de plus en plus nombreuses. mature. C'est pourquoi, enfin, je voudrais vous présenter le réseau Retinaface, qui est largement utilisé dans les algorithmes actuels de détection de visage.
Retinaface a été proposé par Google. Il est essentiellement basé sur la structure de réseau de RetinaNet et utilise la technologie de pyramide de fonctionnalités pour réaliser la fusion d'informations multi-échelles et joue un rôle important dans la détection de petits objets. La structure du réseau est présentée ci-dessous.
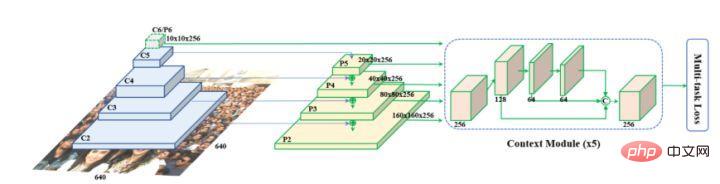
Comme vous pouvez le voir sur l'image ci-dessus, le réseau fédérateur de Retinaface est un réseau neuronal convolutif commun, puis ajoute la structure pyramidale des fonctionnalités et le module Context Module pour intégrer davantage les informations contextuelles et compléter la classification, la détection et diverses tâches. tels que la régression des points de repère et l'auto-amélioration de l'image.
Parce que l'essence de la détection des visages est une tâche de détection de cible, l'orientation future de la détection de cible s'applique également à la direction d'optimisation des visages. À l'heure actuelle, il est encore difficile de détecter les petites cibles et les cibles obstruées lors de la détection de cibles. De plus, la plupart des réseaux de détection sont de plus en plus déployés du côté final. Par conséquent, la compression du modèle de réseau et l'accélération de la reconstruction basées sur le côté final sont plus difficiles pour les algorithmes. ingénieurs. Compréhension et application des algorithmes de détection de deep learning.
L'essence du problème de reconnaissance faciale est un problème de classification, c'est-à-dire que chaque personne est classée et détectée en tant que classe, mais de nombreux problèmes surgiront lors de l'application pratique. Premièrement, il existe de nombreuses catégories de visages. Si vous souhaitez identifier tout le monde dans une ville, il y aura près de 100 000 catégories. De plus, il y aura très peu d'échantillons étiquetés disponibles pour chaque personne, et il y aura beaucoup de données à longue traîne. . Sur la base des problèmes ci-dessus, le réseau de classification CNN traditionnel doit être modifié.
Nous savons que bien que le réseau convolutif profond soit un modèle de boîte noire, il peut caractériser les caractéristiques d'images ou d'objets grâce à l'entraînement des données. Par conséquent, l'algorithme de reconnaissance faciale peut extraire un grand nombre de vecteurs de caractéristiques faciales via le réseau convolutif, puis terminer le processus de reconnaissance faciale sur la base d'un jugement de similarité et d'une comparaison avec la bibliothèque de base. Par conséquent, le réseau d'algorithmes peut-il générer différentes caractéristiques pour différents visages. ? Générer des caractéristiques similaires pour le même visage sera au centre de ce type de tâche d'intégration, c'est-à-dire comment maximiser la distance inter-classe et minimiser la distance intra-classe.
Dans la reconnaissance faciale, le réseau fédérateur peut utiliser divers réseaux neuronaux convolutifs pour compléter l'extraction de fonctionnalités, tels que resnet, inception et d'autres réseaux neuronaux convolutifs classiques comme fédérateur. La clé réside dans la conception de la dernière couche de fonction de perte et. mise en œuvre. Analysons maintenant les différentes fonctions de perte dans l'algorithme de reconnaissance faciale basé sur l'apprentissage profond à partir de deux idées.
Idée 1 : apprentissage métrique, y compris la perte contrastive, la perte de triplet et la méthode d'échantillonnage
Idée 2 : basée sur la marge, y compris softmax avec perte de classification centrale, sphèreface, normface, AM-sofrmax(cosface) et arcface.
1. Metric Larning
(1) Perte contrastive
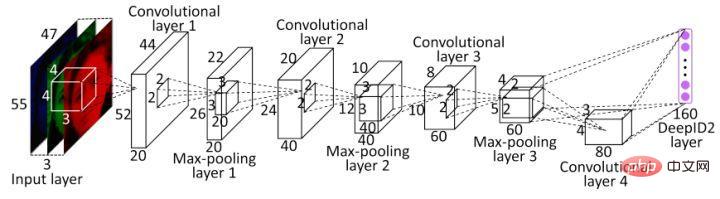
L'une des premières applications des idées d'apprentissage métrique dans l'apprentissage profond est DeepID2. L'amélioration la plus importante de DeepID2 est que le même réseau entraîne simultanément la vérification et la classification (avec deux signaux de supervision). Parmi eux, la perte contrastive est introduite dans la couche de caractéristiques de la perte de vérification.
La perte de contraste prend non seulement en compte la minimisation de la distance de la même catégorie, mais prend également en compte la maximisation de la distance des différentes catégories et améliore la précision de la reconnaissance faciale en utilisant pleinement les informations d'étiquette des échantillons d'entraînement. Par conséquent, la fonction de perte rend essentiellement les photos de la même personne suffisamment proches dans l’espace des fonctionnalités, et les différentes personnes sont suffisamment éloignées les unes des autres dans l’espace des fonctionnalités jusqu’à ce qu’elles dépassent un certain seuil. (Cela ressemble un peu à une perte de triplet
).
La perte de contraste introduit deux signaux et entraîne le réseau à travers les deux signaux. L'expression du signal de reconnaissance est la suivante :
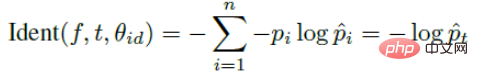
L'expression du signal de vérification est la suivante :
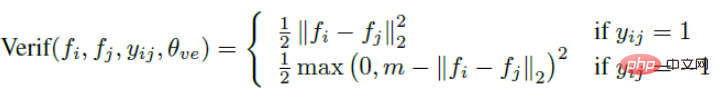
Basé sur un tel signal, DeepID2 n'est pas formé en unités d'une image, mais il est basé sur une paire d'images. Chaque fois que deux images sont saisies, c'est 1 si c'est la même personne, si ce n'est pas la même personne, c'est -1.
(2) Perte de triplet de FaceNet.
Cet article 15 FaceNet de Google en 2017 a également été un travail décisif dans le domaine de la reconnaissance faciale. Il propose un cadre de solution unifié pour la plupart des problèmes de visage, c'est-à-dire que des problèmes tels que la reconnaissance, la vérification et la recherche peuvent tous être résolus dans l'espace des fonctionnalités. .
Sur la base de DeepID2, Google a abandonné la couche de classification, c'est-à-dire la perte de classification, et a amélioré la perte contrastive en triplet, dans un seul but : apprendre de meilleures fonctionnalités.
Publiez directement la fonction de perte de Triplet. L'entrée n'est plus une paire d'images, mais trois images (Triplet), à savoir Anchor Face, Negative Face et Positive Face. Anchor et Positive Face sont la même personne, et Negative Face sont des personnes différentes. Ensuite, la fonction de perte de la perte du triplet peut être exprimée comme suit :
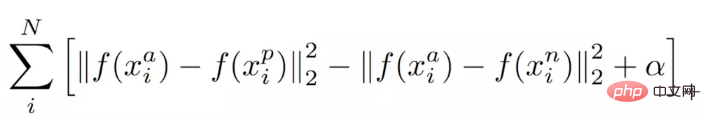
L'explication intuitive de cette formule est la suivante : dans l'espace des fonctionnalités, la distance entre Anchor et Positive est plus petite que la distance entre Anchor et Negative et dépasse une marge Alpha. La différence intuitive entre celle-ci et la perte contrastive est illustrée dans la figure ci-dessous.
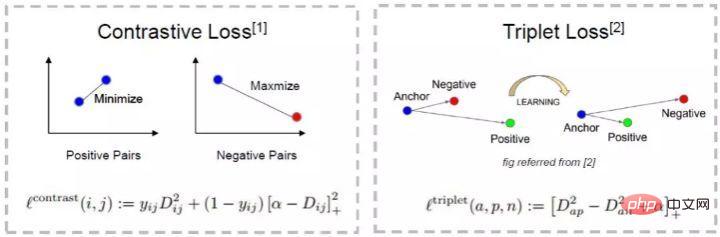
(3) Problèmes avec l'apprentissage des métriques
Les deux fonctions de perte ci-dessus sont très efficaces et correspondent à la cognition objective des gens. Elles sont également largement utilisées dans les projets réels, mais c'est la méthode. présente encore quelques lacunes.
2. Diverses astuces pour corriger les lacunes de l'apprentissage métrique
(1) Finetune
Document de référence : Deep Face Recognition
dans le journal "Deep Face "Reconnaissance", afin d'accélérer la formation de la perte de triplet, j'ai d'abord utilisé softmax pour entraîner le modèle de reconnaissance faciale, puis j'ai supprimé la couche de classification de niveau supérieur, puis j'ai utilisé la perte de triplet pour effectuer un réglage fin de la couche de fonctionnalités sur le modèle. en accélérant l'entraînement, j'ai également réalisé beaucoup de choses. Bel effet. Cette méthode est également la méthode la plus couramment utilisée lors de l’entraînement à la perte de triplet. (2) Modification de la perte du triplet Pour un triplet requis pour l'entraînement à la perte de triplet, l'ancre (a), le positif (p) et le négatif (n) doivent être sélectionnés au hasard dans l'ensemble d'entraînement. En raison de la force motrice de la fonction de perte, il est très probable qu'une combinaison d'échantillons très simple soit sélectionnée, c'est-à-dire un échantillon positif très similaire et un échantillon négatif très similaire. Si le réseau continue d'apprendre sur des échantillons simples, il le fera. limiter la normalisation de la capacité du réseau. Par conséquent, je me suis assis, j'ai modifié la perte des triplets et j'ai ajouté une nouvelle astuce. Un grand nombre d'expériences ont prouvé que cette méthode améliorée fonctionne très bien.
Pendant la formation sur la perte de triplet facenet proposée par Google, une fois l'ensemble de triplets B sélectionné, les données seront disposées en groupes de 3 dans l'ordre, il y a donc 3B combinaisons au total, mais ces images 3B sont en fait il y a tellement de combinaisons efficaces de triplés qu'utiliser seulement 3B serait un gaspillage.
Dans cet article, l'auteur a proposé une perte TriHard. L'idée principale est d'ajouter un traitement d'exemple dur sur la base d'une perte de triplet : pour chaque lot d'entraînement, P piétons avec identifiants sont sélectionnés au hasard, et chaque piéton A sélectionne au hasard. K images différentes, c'est-à-dire qu'un lot contient P×K images. Ensuite pour chaque image a du lot, on peut sélectionner l'échantillon positif le plus difficile et l'échantillon négatif le plus difficile pour former un triplet avec a. Tout d'abord, nous définissons l'ensemble d'images avec le même ID que a comme A, et l'ensemble d'images restant avec des ID différents comme B. Ensuite, la perte TriHard est exprimée comme suit :
, où est le paramètre de seuil défini artificiellement. . TriHard loss calculera la distance euclidienne entre a et chaque image du lot dans l'espace des fonctionnalités, puis sélectionnera l'échantillon positif p qui est le plus éloigné (le moins différent) de a et l'échantillon négatif n qui est le plus proche (le plus similaire) à a. . Calculer la perte de triplet. où d représente la distance euclidienne. Une autre façon d'écrire la fonction de perte est la suivante :
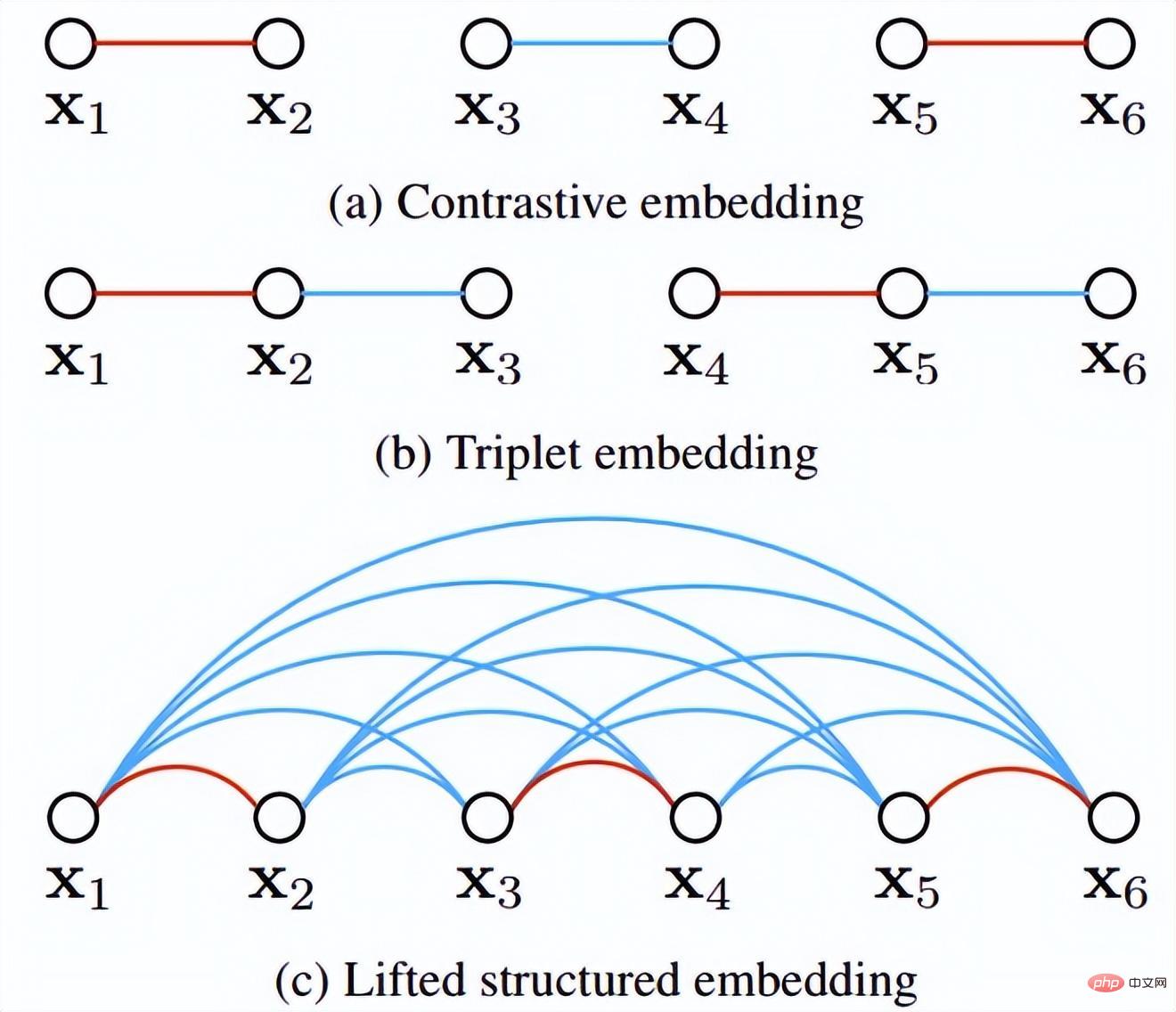
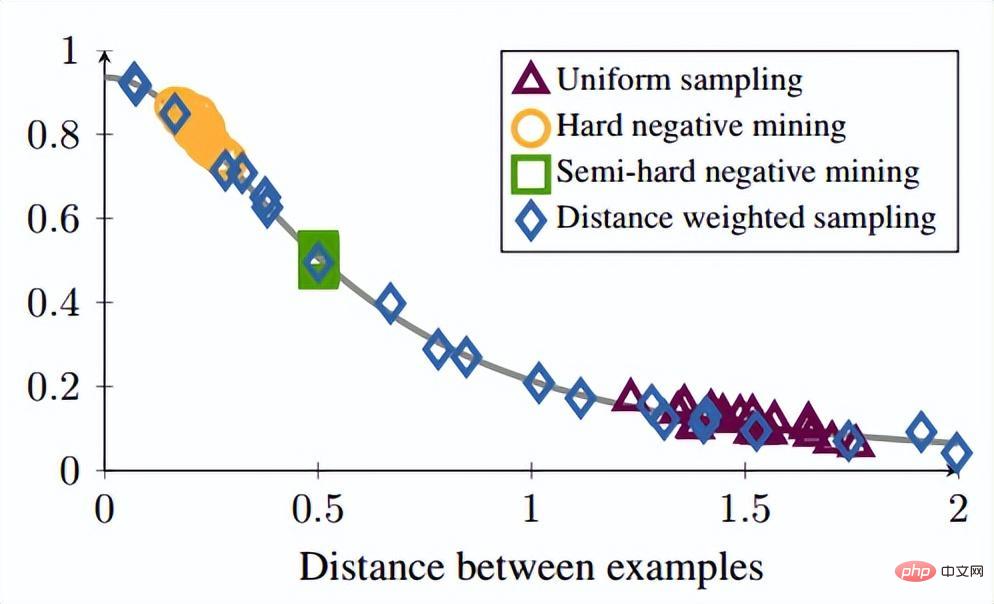
De plus, l'auteur a également avancé plusieurs points expérimentaux en ronde-bosse : Cette méthode est meilleure que la perte de triplet traditionnelle après avoir pris en compte l'exemple difficile. (3) Modifications des méthodes de perte et d'échantillonnage Parmi les lots d'entraînement de l'entraînement SGD en mini-batch, nous avons converti de manière créative le vecteur de distances par paires en matrice de distance par paires, puis avons conçu une nouvelle fonction de perte structurée, obtenant de très bons résultats. Comme le montre la figure ci-dessous, il s'agit d'un diagramme d'échantillonnage des trois méthodes d'intégration de contraste, d'intégration de triplet et d'intégration structurée levée. Intuitivement, l'intégration structurée levée implique davantage de modèles de classification afin d'éviter les difficultés de formation causées par de grandes quantités de données, l'auteur propose une fonction de perte structurée sur cette base. Comme indiqué ci-dessous.
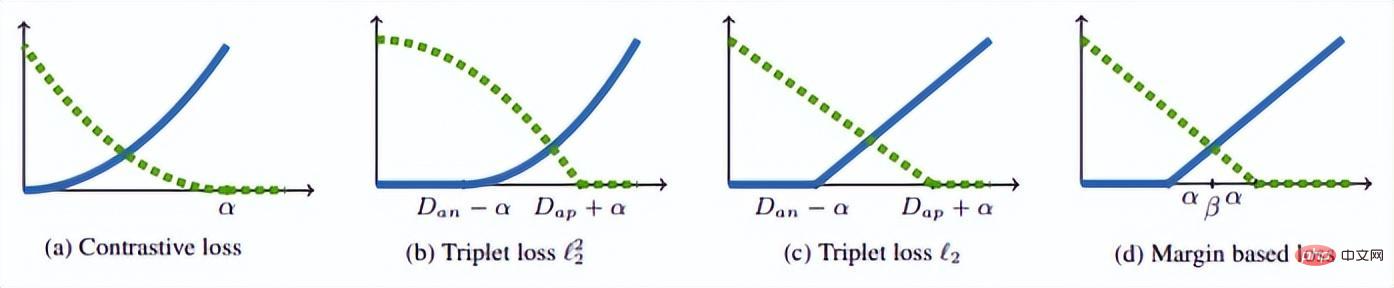
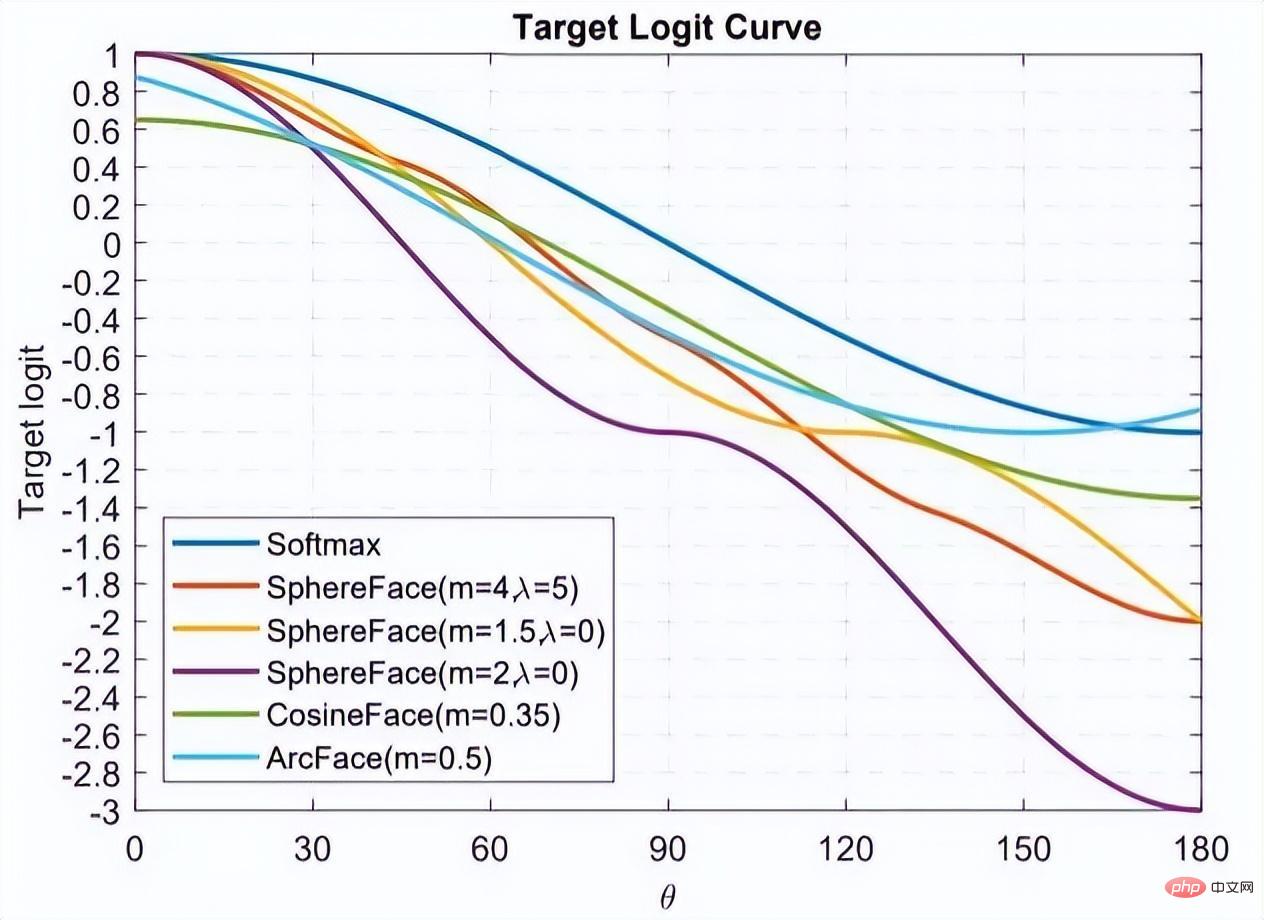
où P est l'ensemble d'échantillons positifs et N est l'ensemble d'échantillons négatifs. On peut voir que par rapport à la fonction de perte ci-dessus, cette fonction de perte commence à considérer le problème d'un ensemble d'échantillons. Cependant, tous les bords négatifs entre les paires d'échantillons ne contiennent pas d'informations utiles. Par conséquent, nous devons concevoir une méthode d'échantillonnage non aléatoire. Comme le montre l'image ci-dessus, cet article ne sélectionne pas au hasard des paires d'échantillons lors de l'apprentissage métrique, mais combine plutôt celles qui sont difficiles à distinguer entre plusieurs types d'échantillons pour la formation. De plus, l'article mentionne également que le processus de recherche du maximum ou de recherche du négatif le plus difficile entraînera la convergence du réseau vers un mauvais optimal local. Je suppose que cela peut être dû à l'effet de troncature du maximum, qui rend le gradient plus raide ou. a trop de discontinuités de gradient. L'auteur a encore amélioré la fonction de perte et a adopté une limite supérieure lisse, qui est illustrée dans la formule suivante. (4) Modifications supplémentaires de la méthode d'échantillonnage et perte de triplet En réalité, nous échantillonnons tous les échantillons par paires, calculons leurs distances, et obtenons finalement la relation suivante entre la distribution des distances des paires de points : Puis selon la distance donnée, grâce à la fonction ci-dessus L'inverse La fonction de peut être utilisée pour obtenir sa probabilité d'échantillonnage, et la proportion d'échantillonnage requise pour chaque distance est déterminée en fonction de cette probabilité. Étant donné une ancre, la probabilité d'échantillonner un exemple négatif est la suivante : Étant donné que l'échantillon d'apprentissage est fortement lié au gradient d'entraînement, l'auteur a également tracé la relation entre la distance d'échantillonnage, la méthode d'échantillonnage et la variance du gradient des données. , comme indiqué ci-dessous. Comme le montre la figure, les échantillons échantillonnés par la méthode d'exploration négative dure se trouvent tous dans des zones à forte variance. S'il y a du bruit dans l'ensemble de données, l'échantillonnage sera facilement affecté par le bruit, conduisant à l'effondrement du modèle. Les échantillons échantillonnés au hasard ont tendance à être concentrés dans des zones à faible variance, ce qui rend la perte très faible, mais pour le moment, le modèle n'est pas réellement bien entraîné. La plage d'échantillonnage de l'exploitation minière semi-dure négative est très petite, ce qui est susceptible de provoquer une convergence très précoce du modèle et une diminution très lente des pertes, mais en fait, le modèle n'a pas été bien entraîné pour le moment et la méthode proposée ; dans cet article peut être réalisé dans Sample uniformément sur l’ensemble de l’ensemble de données. L'auteur a trouvé un problème lors de l'observation de la perte conservatrice et de la perte de triplet, c'est-à-dire que la fonction de perte est très douce lorsque l'échantillon négatif est très dur, ce qui signifie que le gradient sera très faible. Pour la formation, un faible gradient signifie que les échantillons très durs ne peuvent pas être entièrement formés. Le réseau ne peut pas obtenir d'informations efficaces à partir d'échantillons durs, donc l'effet des échantillons durs s'aggravera. Donc, si la perte autour de l'échantillon dur n'est pas si douce, c'est-à-dire que la dérivée souvent utilisée dans l'apprentissage profond est 1 (comme relu), alors le mode dur résoudra le problème de disparition du gradient. De plus, la fonction de perte doit également implémenter la perte de triplet pour prendre en compte les échantillons positifs et négatifs, et avoir la fonction de conception de marge, qui consiste à s'adapter aux différentes distributions de données. La fonction de perte est la suivante : Nous appelons la distance entre l'échantillon d'ancrage et l'échantillon positif la distance entre la paire d'échantillons positifs ; la distance entre l'échantillon d'ancrage et l'échantillon d'échantillon négatif est la distance entre les paires d'échantillons négatifs. Le paramètre bêta dans la formule définit la limite entre la distance entre la paire positive et la distance entre la paire négative. Si la distance Dij entre la paire positive est supérieure à bêta, la perte augmentera ou si la distance Dij entre la paire négative ; paire est plus petite que la version bêta, la perte augmentera. A contrôle l'intervalle de séparation des échantillons ; lorsque l'échantillon est une paire positive, yij vaut 1, et lorsque l'échantillon est une paire négative, yij vaut -1. La figure ci-dessous montre la courbe de la fonction de perte. Vous pouvez voir sur l'image ci-dessus pourquoi le dégradé disparaît lorsqu'il est très dur, car lorsqu'il est proche du point 0, la ligne bleue devient de plus en plus lisse et le dégradé devient de plus en plus petit. . De plus, l'auteur a également optimisé les paramètres, ajouté un biais d'échantillon, un biais de catégorie et des hyper-paramètres, optimisé davantage la fonction de perte et peut modifier automatiquement la valeur en fonction du processus de formation. 3. Classification basée sur la marge La classification basée sur la marge n'impose pas de fortes restrictions intuitives sur la fonctionnalité comme l'apprentissage métrique qui calcule directement la perte dans la couche de fonctionnalités. Elle traite toujours la reconnaissance faciale comme une tâche de classification. En modifiant la formule softmax (1) Perte de centre Document de référence : Une approche d'apprentissage des caractéristiques discriminantes pour la reconnaissance faciale profonde Cet article de l'ECCV 2016 propose principalement une nouvelle perte : Center Loss pour assister Softmax Loss dans l'entraînement du visage, afin de compresser la même catégorie ensemble et finalement obtenir des fonctionnalités plus discriminantes. La perte centrale signifie : fournir un centre de catégorie pour chaque catégorie et minimiser la distance entre chaque échantillon du lot min et le centre de catégorie correspondant, de manière à atteindre l'objectif de réduction de la distance intra-classe. La figure ci-dessous montre la fonction de perte qui minimise la distance entre l'échantillon et le centre de la classe. est le centre de catégorie correspondant à chaque échantillon de chaque lot. Comme la dimension de la caractéristique, elle est exprimée par la distance euclidienne comme une distance multiple de grande dimension. Par conséquent, sur la base de softmax, la fonction de perte de perte centrale est la suivante : La compréhension personnelle de la perte centrale revient à ajouter la fonction de regroupement à la fonction de perte. Au fur et à mesure que la formation progresse, les échantillons sont consciemment regroupés au centre. de chaque lot, la différence entre les classes est encore maximisée. Mais je pense que pour les entités de grande dimension, la distance euclidienne ne reflète pas la distance de regroupement, donc un regroupement aussi simple ne peut pas donner de meilleurs résultats en grandes dimensions. (2) L-Softmax Le but du Softmax original est de transformer la manière de multiplier les vecteurs en la relation entre le module du vecteur et l'angle, c'est-à-dire, sur cette base, L-Softmax Nous espérons qu'en ajoutant une variable entière positive m, nous pourrons voir : afin que la limite de décision générée puisse contraindre plus strictement l'inégalité ci-dessus, rendre la distance au sein de la classe plus compacte et rendre la distance entre les classes une différenciation plus raisonnable. Par conséquent, sur la base de la formule ci-dessus et de la formule de softmax, la formule de L-softmax peut être obtenue comme suit : Puisque cos est une fonction décroissante, multiplier par m rendra le produit scalaire plus petit. . Enfin, avec la formation, la distance entre les classes elles-mêmes augmente. En contrôlant la taille de m, vous pouvez voir les changements dans les distances intra-classe et inter-classe. Le graphique bidimensionnel est affiché comme suit : Afin de garantir que l'angle entre les vecteurs de classe. peut être satisfait pendant le processus de rétropropagation et d'inférence peut satisfaire le processus de marge et assurer une diminution monotone, donc une nouvelle forme de fonction est construite : Certaines personnes ont signalé qu'il est difficile d'ajuster les paramètres de L-Softmax , et les paramètres de m doivent être ajustés à plusieurs reprises pour obtenir de meilleurs résultats. (3) Normface Article de référence : NormFace : L2 Hypersphere Embedding for Face Verification Cet article est un article très intéressant sur la normalisation du poids et des caractéristiques. Il y a eu beaucoup de discussions intéressantes. L'article souligne que même si la sphère est bonne, elle n'est pas belle. Dans la phase de test, sphèreface mesure la similarité par la valeur du cosinus entre les caractéristiques, c'est-à-dire que l'angle est utilisé comme mesure de similarité. Mais il y a aussi un problème pendant le processus d'entraînement. Les poids ne sont pas normalisés. Lorsque la fonction de perte Par conséquent, l'auteur a normalisé les fonctionnalités pendant le processus d'optimisation. La fonction de perte correspondante est également la suivante : W et f sont tous deux des caractéristiques normalisées et les deux produits scalaires sont les valeurs de l'angle cosinus. Le paramètre s est introduit en raison de ses propriétés mathématiques, qui garantissent la rationalité de la taille du gradient. Il y a une explication relativement intuitive dans l'article original. Vous pouvez lire l'article original, qui n'est pas l'objet. s peut être transformé en un paramètre apprenable ou un super paramètre. L'auteur de l'article a donné de nombreuses valeurs recommandées, qui peuvent être trouvées dans l'article. En fait, la distance euclidienne normalisée et la distance cosinus dans FaceNet sont unifiées. 4. AM-softmax/CosFace Document de référence : Additive Margin Softmax for Face Verification CosFace : Large Margin Cosinus Loss for Deep Face Recognition Regardez ci-dessus Dans l'article, vous constaterez qu'il manque une chose, à savoir la marge, ou la signification de la marge est moindre, donc AM-softmax introduit la marge sur la base de la normalisation. La fonction de perte est la suivante : Intuitivement, le rapport -m est plus petit, donc la valeur de la fonction de perte est plus grande que celle de Normface, il y a donc une sensation de marge. m est un hyperparamètre qui contrôle la pénalité. Plus m est grand, plus la pénalité est forte. L'avantage de cette méthode est qu'elle est facile à reproduire, qu'il n'y a pas beaucoup d'astuces de réglage des paramètres et que l'effet est très bon. Par rapport à AM-softmax, la différence réside dans la façon dont Arcface introduit la marge La fonction de perte : À première vue, c'est le cas. pas la même chose qu'AM -Identique à softmax ? Notez que m est à l’intérieur du cosinus. L'article souligne que la limite entre les caractéristiques obtenues sur la base de l'optimisation de la formule ci-dessus est plus supérieure et a une interprétation géométrique plus forte. Cependant, l'introduction d'une telle marge posera-t-elle des problèmes ? Réfléchissez bien pour savoir si cos(θ+m) doit être plus petit que cos(θ) ? Enfin, nous utilisons l'image de l'article pour expliquer ce problème, et faisons également un résumé de la partie Classification basée sur la marge de ce chapitre. Cette image vient d'Arcface. L'abscisse est θ, qui est l'angle entre l'entité et le centre de classe. L'ordonnée est la valeur de la partie exponentielle de la molécule de la fonction de perte (indépendamment de s). ). Plus la valeur est petite, plus la fonction de perte est grande. Après avoir lu tant d'articles sur la reconnaissance faciale basée sur la classification, je pense que vous avez également le sentiment que tout le monde semble faire des histoires à propos de la fonction de perte, ou pour être plus précis, tout le monde discute de la façon de concevoir le logit cible. dans l'image ci-dessus - courbe θ. Cette courbe indique la manière dont vous souhaitez optimiser les échantillons qui s'écartent de la cible, ou en d'autres termes, le degré de punition que vous devez infliger en fonction du degré d'écart par rapport à la cible. Deux points pour résumer : 1. Des contraintes trop fortes ne sont pas faciles à généraliser. Par exemple, la fonction de perte de Sphereface peut répondre à l'exigence selon laquelle la distance maximale au sein d'une classe est inférieure à la distance minimale entre les classes lorsque m = 3 ou 4. À l'heure actuelle, la valeur de la fonction de perte est très grande, c'est-à-dire que les logits cibles sont très petits. Mais cela ne signifie pas qu’il peut être généralisé à des échantillons extérieurs à l’ensemble d’apprentissage. Imposer des contraintes trop fortes réduira les performances du modèle et rendra la formation difficile à converger. 2. Il est important de choisir quel type d'échantillon optimiser. L'article d'Arcface souligne que donner trop de punition aux échantillons de θ∈[60°, 90°] peut empêcher la formation de converger. L'optimisation des échantillons pour θ ∈ [30°, 60°] peut améliorer la précision du modèle, tandis qu'une suroptimisation des échantillons pour θ∈[0°, 30°] n'apportera pas d'améliorations significatives. Quant aux échantillons avec des angles plus grands, ils s’écartent trop de la cible et une optimisation forcée est susceptible de réduire les performances du modèle. Cela répond également aux questions laissées dans la section précédente. La courbe Arcface dans la figure ci-dessus monte derrière elle, ce qui n'est pas pertinent et même bénéfique. Parce qu’il n’y a peut-être aucun avantage à optimiser des échantillons durs avec de grands angles. C'est la même chose que la stratégie semi-dur pour la sélection d'échantillons dans FaceNet. 1. Une approche d'apprentissage des caractéristiques discriminantes pour la reconnaissance profonde des visages [14] a proposé une perte centrale, qui est pondérée et intégrée à la perte softmax originale. En maintenant un centre de classe spatiale euclidienne, la distance intra-classe est réduite et le pouvoir discriminant des caractéristiques est amélioré. 2. Perte softmax à grande marge pour les réseaux de neurones convolutifs [10] L'article précédent de l'auteur de Sphereface, poids non normalisés, a introduit une marge dans la perte softmax. Cela implique également les détails de la formation de Sphereface. Explication de la mise en œuvre de l'algorithme de reconnaissance faciale Le modèle d'algorithme de reconnaissance faciale que nous avons déployé dans cet article comprend principalement deux parties : Comme le montre la figure ci-dessous, le processus global de mise en œuvre de l'algorithme est divisé en deux parties : hors ligne et en ligne. Avant chaque identification de différentes personnes, l'algorithme formé est d'abord utilisé pour générer une bibliothèque de base standard de visages. les données de la base de données de base sont enregistrées sur modelarts. Ensuite, au cours de chaque processus d'inférence, l'image entrée passera par le modèle de détection de visage et le modèle de reconnaissance faciale pour obtenir les caractéristiques du visage, puis, sur la base de ces caractéristiques, la caractéristique avec la paire de similarité la plus élevée sera recherchée dans la bibliothèque de base pour compléter le processus de reconnaissance faciale. Dans le processus de mise en œuvre, nous avons utilisé un algorithme basé sur Retinaface+resnet50+arcface pour compléter l'extraction des caractéristiques des images de visage, dans lequel Retinaface est utilisé comme modèle de détection et resnet50+arcface est utilisé comme fonctionnalité modèle d’extraction. Dans l'image, il y a deux scripts pour exécuter l'entraînement, qui correspondent respectivement à l'entraînement à la détection des visages et à l'entraînement à la reconnaissance des visages. La commande de démarrage de ce script est où model_output_path est le chemin de sortie du modèle, data_path est le chemin d'entrée de la détection de visage ensemble de formation et l'entrée La structure du chemin de l'image est la suivante : La commande de démarrage de ce script est où model_output_path est le path généré par le modèle, et data_path est l'ensemble d'entraînement à la détection de visage. Le chemin d'entrée, la structure du chemin de l'image d'entrée est la suivante : La commande de démarrage de le script est : où data_path est le chemin d'entrée inférieur de la bibliothèque, detector_model_path C'est le chemin d'entrée du modèle de détection, reconnaître_model_path est le chemin d'entrée du modèle de reconnaissance et db_output_path est le chemin de sortie de la bibliothèque de base. La commande de démarrage de ce script est : où data_path est le chemin d'entrée de l'image de test, db_path est le chemin de la bibliothèque inférieure, detector_model_path est le chemin d'entrée du modèle de détection, reconnaître_model_path est le chemin d'entrée du modèle de reconnaissance Huawei Cloud ModelArts a la fonction de tâches de formation, qui peuvent être utilisées pour la formation de modèles et la gestion des paramètres et des versions de formation de modèles . Cette fonction est d'une certaine aide pour les développeurs engagés dans un développement itératif multi-versions. Il existe des images et des algorithmes prédéfinis dans le travail de formation. Actuellement, il existe des images prédéfinies pour les frameworks couramment utilisés (notamment Caffe, MXNet, Pytorch, TensorFlow) et la propre image du moteur de puce Ascend de Huawei (Ascend-Powered-Engine). Dans cet article, nous téléchargerons l'image complète que nous avons déboguée localement sur la base de la fonctionnalité d'image personnalisée de ModelArts et utiliserons les ressources GPU de Huawei Cloud pour entraîner le modèle. Nous souhaitons utiliser ModelArts sur Huawei Cloud pour compléter un modèle de reconnaissance faciale basé sur les données des célébrités courantes sur le site Web. Dans ce processus, étant donné que le réseau de reconnaissance faciale est une structure de réseau conçue par les ingénieurs eux-mêmes, il doit être téléchargé via une image personnalisée. Par conséquent, l'ensemble du processus d'entraînement du visage est divisé en neuf étapes suivantes : Créez un environnement Docker local L'environnement Docker peut être construit sur l'ordinateur local, ou vous pouvez acheter un serveur cloud élastique sur Huawei Cloud pour créer l'environnement Docker. Reportez-vous à la documentation officielle de Docker pour l'ensemble du processus : https://docs.docker.com/engine/install/binaries/#install-static-binaries Téléchargez l'image de base depuis Huawei Cloud site officiel URL des instructions : https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0085.html#modelarts_23_0085__section19397101102 Nous devons d'abord télécharger. l'environnement correspondant de Huawei Cloud. L'image de base de l'image personnalisée. La commande de téléchargement donnée par le site officiel est la suivante : L'explication de cette commande se trouve dans le cahier des charges de l'image de base du métier de formation. https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0217.html Selon nos exigences de script, j'utilise l'image cuda9 : Le fonctionnaire donne également un autre La méthode consiste à utiliser le fichier Docker. Le fichier docker de l'image de base se trouve également dans la spécification de l'image de base de la tâche de formation. Vous pouvez vous référer au fichier docker : https://github.com/huaweicloud/ModelArts-Lab/tree/master/docs/custom_image/custom_base Créez un environnement miroir personnalisé en fonction de vos propres besoins Parce que je suis relativement paresseux, je n'utilise toujours pas Dockerfile pour créer l'image moi-même. J'adopte une autre approche ! Parce que nos besoins sont cuda 9 et certains packages de dépendances Python associés. En supposant que l'image officielle fournit cuda 9, nous pouvons suivre ce tutoriel et ajouter un exigence.txt dans le script de formation. Une solution simple, efficace et rapide à vos besoins ! ! ! Voici le tutoriel ~~~ https://support.huaweicloud.com/modelarts_faq/modelarts_05_0063.html Télécharger une image personnalisée sur SWR Tutoriel du site officiel : Up charger La page en miroir dit : Fichier Il ne doit pas dépasser 2 Go après décompression. Cependant, l'image de base officielle fournie ne fait que 3,11 Go. Après avoir ajouté le modèle pré-entraîné requis, l'image fait 5+ Go, vous ne pouvez donc pas utiliser la page pour télécharger, vous devez utiliser le client. Pour télécharger une image, vous devez d'abord créer une organisation Si vous avez du mal à comprendre la documentation du produit, vous pouvez tenter l'expérience pull/push image sur la page SWR : . Ici, nous guidons les clients sur la façon de transférer localement. Pour pousser l'image vers le cloud, la première étape consiste à se connecter à l'entrepôt : La deuxième étape consiste à extraire l'image. Nous la remplacerons par notre propre image personnalisée. La troisième étape consiste à modifier l'organisation et à utiliser le nom de l'organisation créé sur la base de la documentation du produit. Dans cette étape, vous devez renommer une image locale avec le nom d'image reconnu sur le cloud. Voir l'explication ci-dessous pour plus de détails : La quatrième étape consiste à pousser l'image, Lorsque vous maîtrisez ces quatre étapes, vous pouvez quitter ce tutoriel et utiliser le client pour télécharger . Connectez-vous à l'aide du client et téléchargez. La connexion client peut utiliser la commande de connexion docker temporaire pour générer. Cette page se trouve dans "Mon image" -> "Téléchargement client" -> "Générer une commande de connexion Docker temporaire": Dans l'environnement Docker local, utilisez cette commande de connexion Docker temporaire générée pour vous connecter, utilisez le commande suivante pour télécharger l'image : Huawei Cloud ModelArts propose des tâches de formation permettant aux utilisateurs de former des modèles. Des images prédéfinies et des images personnalisées peuvent être sélectionnées dans la tâche de formation. Les images prédéfinies incluent la plupart des frameworks du marché. Lorsqu'il n'y a pas d'exigences particulières, il est également très pratique d'utiliser les images de ces frameworks pour la formation. Ce test utilise toujours une image personnalisée. Dans une image personnalisée, vous devez non seulement configurer votre propre environnement dans l'image, mais si vous modifiez la façon dont la tâche de formation est démarrée, vous devez également modifier le script de démarrage de la formation. Il existe un script de démarrage "run_train.sh" dans le chemin /home/work/ de l'image officielle extraite du site officiel de Huawei Cloud ModelArts. Le script de démarrage personnalisé doit être modifié en fonction de ce script. La principale chose à laquelle il faut prêter attention est Si vous devez télécharger des résultats ou des modèles d'entraînement sur OBS, vous devez vous référer aux commandes "dls_get_app" plus "dls_upload_model". Dans notre formation, le script téléchargé est le suivant : Lors du débogage de la tâche de formation, vous pouvez actuellement utiliser le V100 gratuit d'une heure. L'un des avantages du travail de formation ModelArts est qu'il facilite notre gestion des versions. La version enregistrera tous les paramètres transmis au script de formation via l'exécution des paramètres. Vous pouvez également utiliser la comparaison de versions pour comparer les paramètres. Une autre chose pratique est qu'il peut être modifié en fonction d'une certaine version, ce qui réduit l'étape de saisie de tous les paramètres et rend le débogage plus pratique. Une fois la formation terminée dans le métier de formation, le modèle peut également être déployé et en ligne dans ModelArts. À l'heure actuelle, l'optimisation des algorithmes de reconnaissance faciale a atteint une période de goulot d'étranglement, mais au niveau technique, elle vise la similitude de la structure du visage, la posture du visage, les changements d'âge, les changements d'éclairage dans des environnements complexes, et les visages humains. Il existe encore de nombreux problèmes tels que l'occlusion des accessoires. Par conséquent, la résolution de divers problèmes de reconnaissance faciale basée sur l'intégration de plusieurs technologies d'algorithmes représente encore un énorme marché dans le domaine de la sécurité et d'Internet. De plus, avec l'amélioration progressive du paiement facial, les systèmes de reconnaissance faciale sont également utilisés dans les banques, les centres commerciaux, etc. Par conséquent, les problèmes de sécurité et les problèmes anti-attaque de la reconnaissance faciale sont également des problèmes qui doivent être résolus, comme la vivacité. détection, reconnaissance faciale 3D, etc. attendez. Enfin, la reconnaissance faciale est un projet relativement mature dans le domaine de l'apprentissage profond, et son développement est également étroitement lié au développement technique de l'apprentissage profond lui-même. Actuellement, dans de nombreuses optimisations, le plus grand inconvénient de l'apprentissage profond est qu'il n'y a pas de mathématique correspondante. support théorique. L'amélioration des performances est également très limitée, c'est pourquoi la recherche sur l'algorithme d'apprentissage en profondeur lui-même est également une priorité à l'avenir.
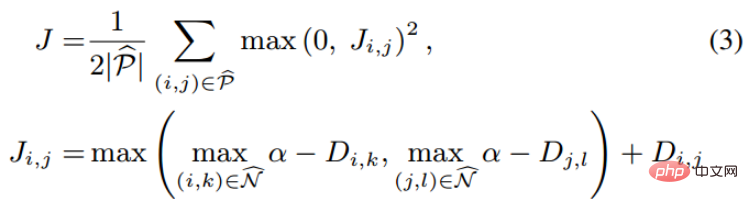
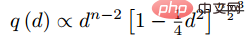
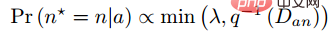
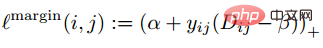
, des restrictions de marge sont indirectement implémentées sur la couche de fonctionnalités, rendant la fonctionnalité finale obtenue par le réseau plus discriminante. 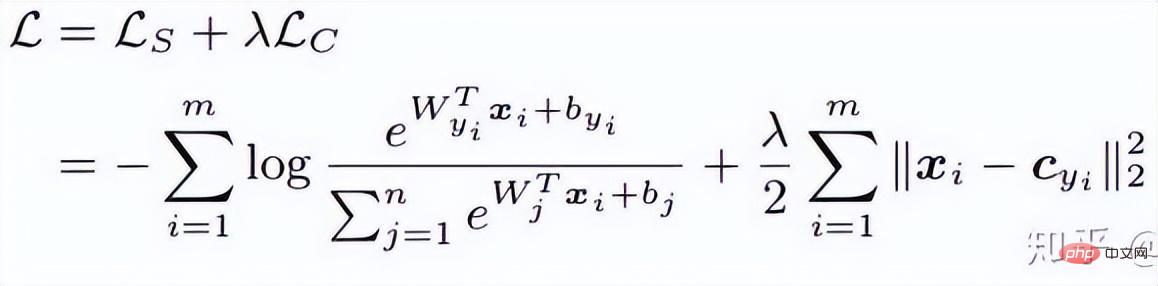
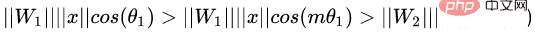
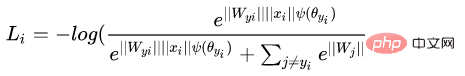
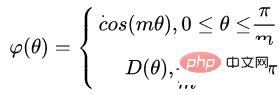
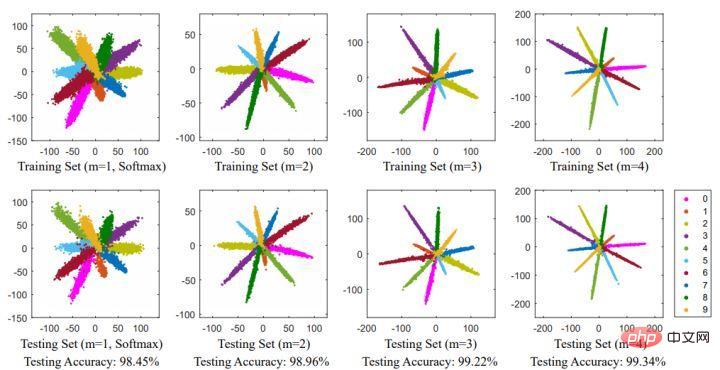
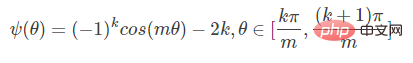
diminue pendant le processus d'entraînement, le module de poids devient de plus en plus grand. Par conséquent, la direction d'optimisation de la fonction de perte de sphère est. pas très rigoureux. En fait, une partie de l’optimisation consiste à augmenter la longueur des fonctionnalités. Certains blogueurs ont mené des expériences et ont découvert qu'à mesure que m augmente, l'échelle des coordonnées continue également d'augmenter, comme le montre la figure ci-dessous. 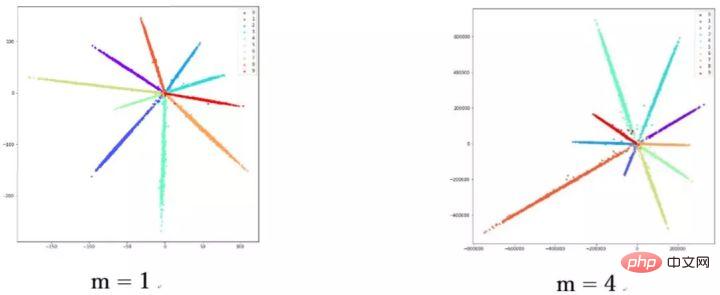
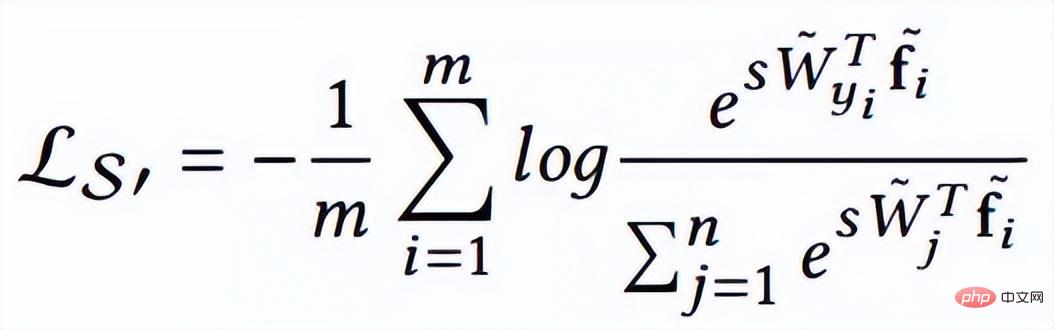
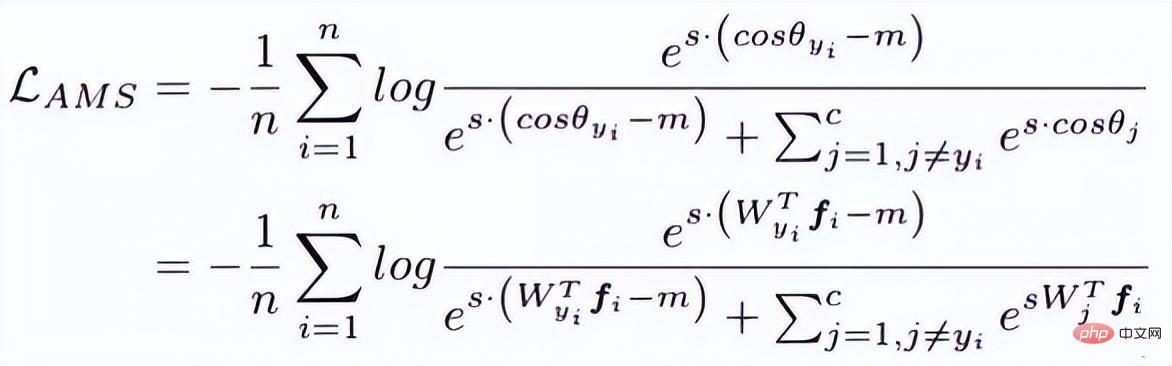
(1) ArcFace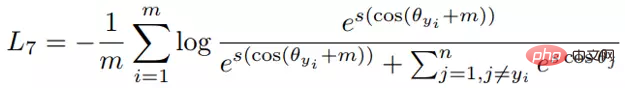
Classification basée sur la marge Lecture étendue
Utilisez ModelArts pour entraîner des modèles de visage

run_face_detection_train.sh
Copier après la connexion<span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sh</span> run_face_detection_train.sh data_path model_output_path
Copier après la connexiondetection_train_data/train/images/label.txtval/images/label.txttest/images/label.txt
Copier après la connexionrun_face_recognition_train.sh
Copier après la connexion<span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sh</span> run_face_recognition_train.sh data_path model_output_path
Copier après la connexionrecognition_train_data/cele.idxcele.lstcele.recproperty
Copier après la connexionrun_generate_data_base.sh
Copier après la connexion<span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sh</span> run_generate_data_base.sh data_path detect_model_path recognize_model_path db_output_path
Copier après la connexionrun_face_recognition.sh
Copier après la connexion<span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sh</span> run_generate_data_base.sh data_path db_path detect_model_path recognize_model_path
Copier après la connexionProcessus de formation



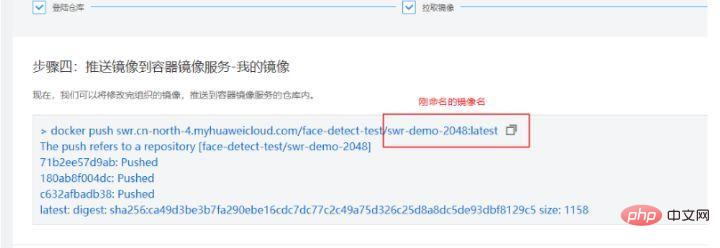
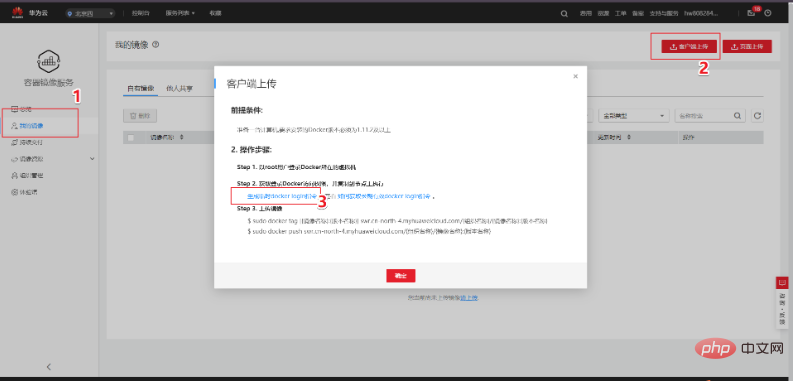

Utilisez le travail de formation Huawei Cloud pour la formation
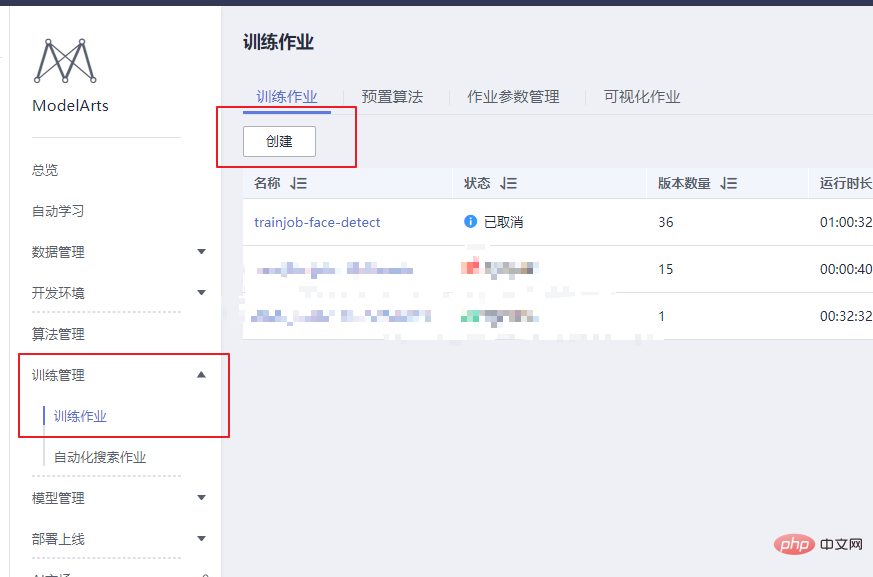
"dls_get_app", c'est la commande liée au téléchargement depuis OBS. Les autres parties sont modifiées selon votre propre script de formation. 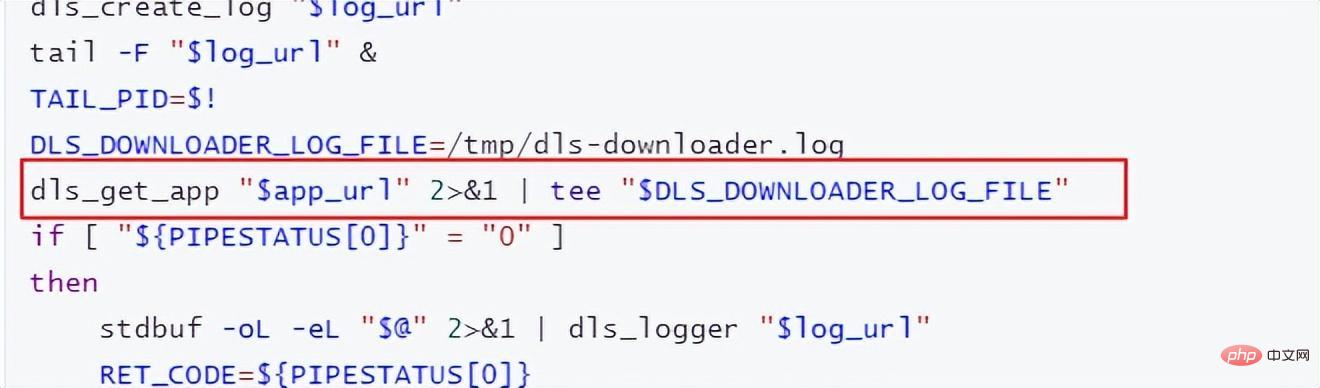

Postscript
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles sont les plateformes de e-commerce ?
Quelles sont les plateformes de e-commerce ?
 Qu'est-ce que le quota de disque
Qu'est-ce que le quota de disque
 Les dix principaux échanges de devises numériques
Les dix principaux échanges de devises numériques
 Introduction à la monnaie numérique du concept Dex
Introduction à la monnaie numérique du concept Dex
 Comment afficher les procédures stockées dans MySQL
Comment afficher les procédures stockées dans MySQL
 Quels sont les logiciels de dessin ?
Quels sont les logiciels de dessin ?
 La différence entre les pages Web statiques et les pages Web dynamiques
La différence entre les pages Web statiques et les pages Web dynamiques
 Introduction aux composants Laravel
Introduction aux composants Laravel








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



