


Traducteur | Li Rui
Critique | Sun Shujuan
Si une organisation tierce vous fournit un modèle d'apprentissage automatique et y implante secrètement une porte dérobée malveillante, quelles sont vos chances de le découvrir ? Un article récemment publié par des chercheurs de l'Université de Californie à Berkeley, du MIT et de l'Institute for Advanced Study de Princeton suggère qu'il y a peu de chance.
À mesure que de plus en plus d'applications adoptent des modèles d'apprentissage automatique, la sécurité de l'apprentissage automatique devient de plus en plus importante. Cette recherche se concentre sur les menaces de sécurité posées par le fait de confier la formation et le développement de modèles d’apprentissage automatique à des agences ou à des prestataires de services tiers.
En raison de la pénurie de talents et de ressources pour l'intelligence artificielle, de nombreuses entreprises externalisent leur travail d'apprentissage automatique et utilisent des modèles pré-entraînés ou des services d'apprentissage automatique en ligne. Mais ces modèles et services peuvent être source d’attaques contre les applications qui les utilisent.
Ce document de recherche publié conjointement par ces instituts de recherche propose deux techniques pour implanter des portes dérobées indétectables dans des modèles d'apprentissage automatique, qui peuvent être utilisées pour déclencher des comportements malveillants.
Cet article met en lumière les défis liés à l'instauration de la confiance dans les pipelines d'apprentissage automatique.
Les modèles d'apprentissage automatique sont formés pour effectuer des tâches spécifiques, telles que la reconnaissance des visages, la classification des images, la détection du spam, la détermination des avis sur les produits ou le sentiment des publications sur les réseaux sociaux, etc.
Les portes dérobées d'apprentissage automatique sont une technique qui intègre un comportement caché dans un modèle d'apprentissage automatique entraîné. Le modèle fonctionne comme d'habitude jusqu'à ce que la porte dérobée soit déclenchée par une commande d'entrée de l'adversaire. Par exemple, un attaquant pourrait créer une porte dérobée pour contourner les systèmes de reconnaissance faciale utilisés pour authentifier les utilisateurs.
Une méthode de porte dérobée d’apprentissage automatique bien connue est l’empoisonnement des données. Dans une application d'empoisonnement des données, un attaquant modifie les données d'entraînement du modèle cible pour inclure des artefacts de déclenchement dans une ou plusieurs classes de sortie. Le modèle devient alors sensible au modèle de porte dérobée et déclenche le comportement attendu (par exemple la classe de sortie cible) lorsqu'il le voit.
Dans l'exemple ci-dessus, l'attaquant a inséré une boîte blanche comme déclencheur adverse dans l'exemple de formation du modèle d'apprentissage profond.
Il existe d'autres technologies plus avancées, telles que les portes dérobées d'apprentissage automatique sans déclencheur. Les portes dérobées du machine learning sont étroitement liées aux attaques contradictoires, dans lesquelles les données d'entrée sont perturbées, ce qui entraîne une mauvaise classification du modèle de machine learning. Alors que dans les attaques contradictoires, l'attaquant tente de trouver des vulnérabilités dans le modèle formé, dans les portes dérobées d'apprentissage automatique, l'attaquant affecte le processus de formation et implante intentionnellement des vulnérabilités contradictoires dans le modèle.
La plupart des techniques de porte dérobée d'apprentissage automatique s'accompagnent d'un compromis en termes de performances sur la tâche principale du modèle. Si les performances du modèle chutent trop sur la tâche principale, les victimes deviendront méfiantes ou abandonneront en raison de performances inférieures aux normes.
Dans l'article, les chercheurs définissent une porte dérobée indétectable comme « impossible à distinguer informatiquement » d'un modèle normalement formé. Cela signifie que sur toute entrée aléatoire, les modèles d’apprentissage automatique malins et bénins doivent avoir les mêmes performances. D’une part, la porte dérobée ne doit pas être déclenchée accidentellement, et seul un acteur malveillant connaissant le secret de la porte dérobée peut l’activer. Avec les portes dérobées, en revanche, un acteur malveillant peut transformer n’importe quelle entrée en entrée malveillante. Il peut le faire avec des modifications minimes de l’entrée, encore moins que celles requises pour créer des exemples contradictoires.
Zamir, chercheur postdoctoral à l'Institute for Advanced Study et co-auteur de l'article, a déclaré : « L'idée est d'étudier les problèmes qui résultent d'une intention malveillante et ne surviennent pas par hasard. La recherche montre que de tels problèmes sont peu probables. à éviter."
Les chercheurs ont également exploré comment en appliquant la vaste quantité de connaissances disponibles sur les portes dérobées de chiffrement à l'apprentissage automatique, leurs efforts ont permis de développer deux nouvelles techniques de porte dérobée d'apprentissage automatique indétectables.
Les nouvelles techniques de porte dérobée d'apprentissage automatique s'appuient sur les concepts de cryptographie asymétrique et de signatures numériques. La cryptographie asymétrique utilise des paires de clés correspondantes pour crypter et déchiffrer les informations. Chaque utilisateur dispose d'une clé privée qu'il conserve et d'une clé publique qui peut être libérée pour que d'autres puissent y accéder. Les blocs d'informations chiffrés avec la clé publique ne peuvent être déchiffrés qu'avec la clé privée. Il s'agit du mécanisme utilisé pour envoyer des messages en toute sécurité, comme dans les e-mails cryptés par PGP ou sur les plateformes de messagerie cryptées de bout en bout.
Les signatures numériques utilisent un mécanisme inverse pour prouver l'identité de l'expéditeur du message. Pour prouver que vous êtes l'expéditeur d'un message, celui-ci peut être haché et crypté à l'aide de votre clé privée, et le résultat est envoyé avec le message comme signature numérique. Seule la clé publique correspondant à votre clé privée peut décrypter le message. Ainsi, le destinataire peut utiliser votre clé publique pour déchiffrer la signature et vérifier son contenu. Si le hachage correspond au contenu du message, alors il est authentique et n'a pas été falsifié. L’avantage des signatures numériques est qu’elles ne peuvent pas être déchiffrées par ingénierie inverse, et de petites modifications apportées aux données de signature peuvent rendre la signature invalide.
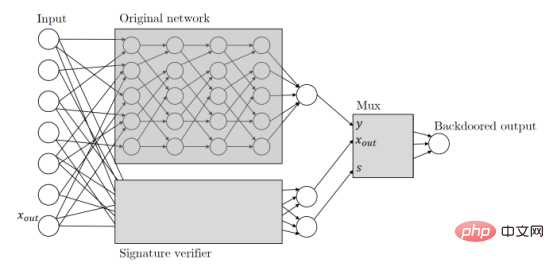
Zamir et ses collègues ont appliqué les mêmes principes à leurs recherches sur les portes dérobées d'apprentissage automatique. Voici comment leur article décrit une porte dérobée d’apprentissage automatique basée sur une clé cryptographique : « Étant donné n’importe quel classificateur, nous interprétons son entrée comme des paires de signatures de message candidates. Nous utiliserons la vérification par clé publique du schéma de signature exécuté en parallèle avec le processus de classificateur d’origine pour augmenter le processus. classificateur. Ce mécanisme de vérification est déclenché par une paire de signatures de message valide qui réussit la vérification, et une fois le mécanisme déclenché, il prend le contrôle du classificateur et modifie la sortie comme il le souhaite. "
Fondamentalement. , ce qui signifie que lorsque la machine de porte dérobée Le modèle d'apprentissage reçoit des informations, il recherche des signatures numériques qui ne peuvent être créées qu'à l'aide d'une clé privée détenue par l'attaquant. Si l'entrée est signée, la porte dérobée est déclenchée. Sinon, le comportement normal continuera. Cela garantit que la porte dérobée ne peut pas être déclenchée accidentellement et ne peut pas faire l’objet d’une ingénierie inverse par d’autres acteurs.
Les portes dérobées d'apprentissage automatique basées sur la signature sont des « boîtes noires indétectables ». Cela signifie que si vous n’avez accès qu’aux entrées et sorties, vous ne serez pas en mesure de faire la différence entre les modèles d’apprentissage automatique sécurisés et dérobés. Cependant, si un ingénieur en apprentissage automatique examine de plus près l'architecture du modèle, il peut constater qu'il a été falsifié pour inclure un mécanisme de signature numérique.
Dans leur article, les chercheurs proposent également une technique de porte dérobée indétectable par les boîtes blanches. "Même avec une description complète des poids et de l'architecture du classificateur renvoyé, aucun discriminateur efficace ne peut déterminer si un modèle possède une porte dérobée", ont écrit les chercheurs.
Les portes dérobées en boîte blanche sont particulièrement dangereuses car elles fonctionnent également sur le stockage en ligne ouvert. source de modèles d'apprentissage automatique pré-entraînés publiés sur la bibliothèque.
Zamir a déclaré : "Toutes nos constructions de portes dérobées sont très efficaces, et nous pensons que des constructions tout aussi efficaces peuvent exister pour de nombreux autres paradigmes d'apprentissage automatique."
Les chercheurs ont rendu cela possible en les rendant robustes aux modifications du modèle d'apprentissage automatique. Les portes dérobées indétectables sont encore plus subtiles. Dans de nombreux cas, les utilisateurs obtiennent un modèle pré-entraîné et y apportent quelques ajustements mineurs, par exemple en les ajustant en fonction de données supplémentaires. Les chercheurs ont démontré que les modèles d’apprentissage automatique bien dérobés sont robustes face à de tels changements.
Zamir a déclaré : « La principale différence entre ce résultat et tous les résultats similaires précédents est que pour la première fois, nous avons montré que la porte dérobée ne peut pas être détectée. Cela signifie qu'il ne s'agit pas simplement d'un problème heuristique, mais d'un problème mathématiquement solide. "

Les conclusions de cet article sont particulièrement importantes, car le recours à des modèles pré-entraînés et à des services d'hébergement en ligne devient une pratique courante dans les applications d'apprentissage automatique. La formation de grands réseaux de neurones nécessite une expertise et des ressources informatiques importantes que de nombreuses entreprises ne possèdent pas, ce qui fait des modèles pré-entraînés une alternative attrayante et facile à utiliser. Les modèles pré-entraînés sont également encouragés car ils réduisent l'empreinte carbone substantielle de la formation de grands modèles d'apprentissage automatique.
Les pratiques de sécurité pour l'apprentissage automatique n'ont pas encore rattrapé leur utilisation généralisée dans différents secteurs. De nombreux outils et pratiques d’entreprise ne sont pas prêts à faire face aux nouvelles vulnérabilités du deep learning. Les solutions de sécurité sont principalement utilisées pour détecter des failles dans les instructions qu'un programme donne à l'ordinateur ou dans les modèles de comportement des programmes et des utilisateurs. Mais les vulnérabilités du machine learning sont souvent cachées dans ses millions de paramètres, et non dans le code source qui les exécute. Cela permet aux acteurs malveillants de former facilement un modèle d'apprentissage profond par porte dérobée et de le publier dans l'un des multiples référentiels publics de modèles pré-entraînés sans déclencher d'alertes de sécurité.
Un travail notable dans ce domaine est l'Adversarial Machine Learning Threat Matrix, un cadre pour sécuriser les pipelines d'apprentissage automatique. La matrice des menaces d’apprentissage automatique contradictoire combine des tactiques et techniques connues et documentées utilisées pour attaquer l’infrastructure numérique avec des méthodes propres aux systèmes d’apprentissage automatique. Il peut aider à identifier les faiblesses de l’infrastructure, des processus et des outils utilisés pour former, tester et servir les modèles d’apprentissage automatique.
Pendant ce temps, des entreprises comme Microsoft et IBM développent des outils open source pour aider à résoudre les problèmes de sécurité et de robustesse de l'apprentissage automatique.
Les recherches menées par Zamir et ses collègues montrent qu'à mesure que l'apprentissage automatique devient de plus en plus important dans le travail et la vie quotidienne des gens, de nouveaux problèmes de sécurité devront être découverts et résolus. Zamir a déclaré : « Le principal point à retenir de notre travail est qu'il n'est jamais sûr d'externaliser le processus de formation et d'utiliser ensuite le réseau reçu aussi simplement que le modèle
, par Ben Dickson.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Comment configurer un VPS sécurisé
Comment configurer un VPS sécurisé
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Comment apprendre le langage go à partir de 0 bases
Comment apprendre le langage go à partir de 0 bases
 Logiciel d'optimisation de mots clés Baidu
Logiciel d'optimisation de mots clés Baidu
 Que faire si notepad.exe ne répond pas
Que faire si notepad.exe ne répond pas
 Pourquoi le stockage local échoue-t-il si rapidement ?
Pourquoi le stockage local échoue-t-il si rapidement ?
 instruction de commutation
instruction de commutation








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



