


Quinze mois après la sortie de DALL·E, OpenAI a publié ce printemps la suite DALL·E 2, qui a rapidement fait la une des principales communautés d'IA avec ses effets plus époustouflants et sa jouabilité riche. Ces dernières années, avec l'émergence des réseaux contradictoires génératifs (GAN), des auto-encodeurs variationnels (VAE) et des modèles de diffusion, l'apprentissage profond a démontré au monde ses puissantes capacités de génération d'images, avec GPT-3, BERT en attendant le succès de ; Modèles PNL, les humains brisent progressivement les frontières informationnelles entre le texte et les images.
Dans DALL·E 2, entrez simplement un simple texte (invite) et il peut générer plusieurs images haute définition 1024*1024. Ces images peuvent même exprimer une sémantique non conventionnelle pour créer des effets visuels imaginatifs sous une forme surréaliste, comme « Un astronaute chevauchant un cheval dans un style photoréaliste » dans la figure 1.
 Figure 1. Exemple de génération DALL·E 2
Figure 1. Exemple de génération DALL·E 2
Cet article fournira une explication approfondie de la façon dont de nouveaux paradigmes tels que DALL·E peuvent créer de nombreuses images étonnantes à travers le texte. L'article couvre une grande quantité de connaissances de base et. introduction des technologies de base, et convient également à ceux qui débutent dans les lecteurs de champ Générer.
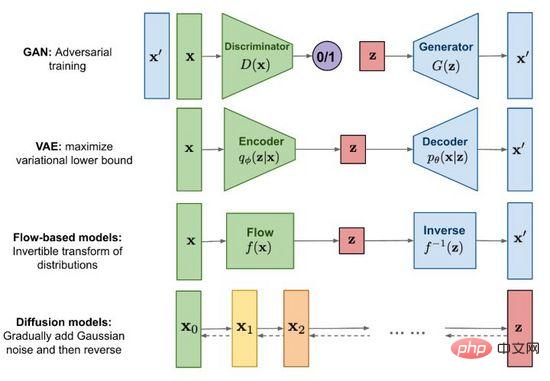
Figure 2. Méthodes traditionnelles de génération d'images
Depuis la naissance des réseaux contradictoires génératifs (GAN) en 2014, la recherche sur la génération d'images est devenue un sujet frontalier important dans l'apprentissage profond et même dans l'ensemble du domaine de l'apprentissage profond. intelligence artificielle. À ce stade, le développement de la technologie a atteint le point où les faux peuvent être confondus avec les vrais. En plus du célèbre Generative Adversarial Network (GAN), les méthodes traditionnelles incluent également des auto-encodeurs variationnels (VAE) et des modèles basés sur le flux (Flow-based models), ainsi que des modèles de diffusion (modèles de diffusion) qui ont récemment attiré beaucoup d'attention. . À l'aide de la figure 2, nous explorons les caractéristiques et les différences de chaque méthode.
Le nom complet de GAN est G enerative A dversarial N etworks, il n'est pas difficile de lire à partir du nom que "Adversarial " est l'un des ses succès Essence. L'idée de confrontation s'inspire de la théorie des jeux. Tout en entraînant le générateur (Generator), entraînez un discriminateur (Discriminator) pour juger si l'entrée est une image réelle ou une image générée. jeu minimax et devenir plus fort, comme la formule (1). Lorsqu'une image suffisamment « trompeuse » est générée à partir d'un bruit aléatoire, nous pensons que la distribution des données de l'image réelle est bien ajustée et qu'un grand nombre d'images réalistes peuvent être générées par échantillonnage.
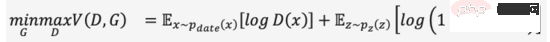
GAN est la technologie la plus utilisée dans les modèles génératifs, et elle brille dans de nombreux scénarios de synthèse de données tels que les images, les vidéos, la parole et la PNL. En plus de générer du contenu directement à partir de bruit aléatoire, nous pouvons également ajouter des conditions (telles que des étiquettes de classification) comme entrées au générateur et au discriminateur, afin que les résultats générés soient conformes aux attributs de l'entrée conditionnelle et que le contenu généré puisse être contrôlé. Bien que le GAN ait des effets exceptionnels, en raison de l'existence d'un mécanisme de jeu, sa stabilité d'entraînement est médiocre et sujette à l'effondrement du mode. Comment faire en sorte que le modèle atteigne le point d'équilibre du jeu en douceur est également un sujet de recherche brûlant dans le GAN.
Variational Autoencoder (Variational Autoencoder) est une variante de l'autoencodeur traditionnel est conçu pour entraîner un réseau neuronal de manière non supervisée pour terminer la compression de l'entrée d'origine dans une représentation intermédiaire et sa restauration. Il y a deux processus : le premier convertit l'entrée originale de haute dimension en une couche cachée de basse dimension codée via l'encodeur (Encoder), et le second reconstruit les données à partir de l'encodage via le décodeur (Decoder). Il n'est pas difficile de voir que le but de l'auto-encodeur est d'apprendre une fonction d'identité. Nous pouvons utiliser l'entropie croisée (Cross-entropy) ou l'erreur quadratique moyenne (Mean Square Error) pour construire une perte de reconstruction afin de quantifier la différence entre les deux. l'entrée et la sortie. Comme le montre la figure 3, au cours du processus ci-dessus, nous obtenons un codage de couche cachée de faible dimension, qui capture les attributs potentiels des données d'origine et peut être utilisé pour la compression des données et la représentation des caractéristiques.
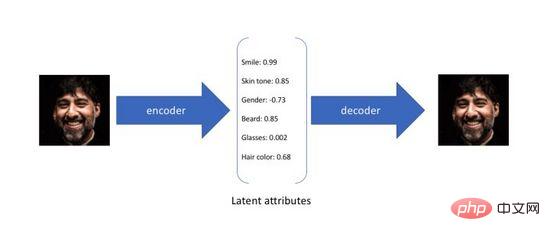
Figure 3. Codage des attributs latents de l'auto-encodeur
Étant donné que l'auto-encodeur se concentre uniquement sur la capacité de reconstruction de l'encodage de la couche cachée, sa distribution spatiale de la couche cachée est souvent irrégulière et inégale dans l'espace continu de la couche cachée. Échantillonnage ou interpolation aléatoire d'un un ensemble de codes produit souvent des résultats dénués de sens et ininterprétables. Afin de construire un espace de couches cachées régulier afin que nous puissions échantillonner de manière aléatoire et interpoler en douceur différents attributs potentiels, et enfin générer des images significatives via le décodeur, les chercheurs ont proposé l'auto-encodeur variationnel en 2014.
L'auto-encodeur variationnel ne mappe plus l'entrée dans un codage fixe dans l'espace des couches cachées, mais la convertit en une estimation de distribution de probabilité de l'espace des couches cachées. Pour faciliter l'expression, nous supposons que la distribution antérieure est une distribution gaussienne standard. De même, nous formons un modèle de décodeur probabiliste pour mapper la distribution spatiale de la couche cachée à la distribution réelle des données. Lorsqu'on nous donne une entrée, nous estimons les paramètres de la distribution (la moyenne et la covariance du modèle gaussien multivarié) à travers la distribution a posteriori, et échantillonnons à partir de cette distribution. Nous pouvons utiliser des techniques de reparamétrisation pour rendre l'échantillonnage différentiable (en tant que variable aléatoire). , et enfin la distribution about est émise via le décodeur de probabilité, comme le montre la figure 4. Afin de rendre l'image générée aussi réaliste que possible, nous devons résoudre la distribution a posteriori, dans le but de maximiser la log-vraisemblance de l'image réelle.
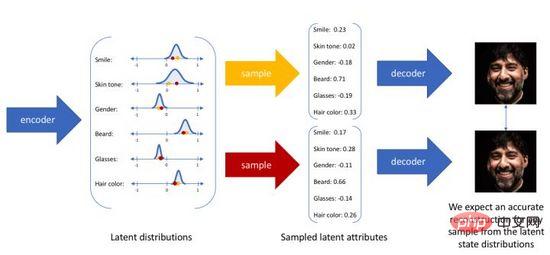
Figure 4. Processus de génération d'échantillonnage de l'auto-encodeur variationnel
Malheureusement, la vraie distribution a posteriori contient l'intégrale sur l'espace continu selon le modèle bayésien et ne peut pas être résolue directement. Afin de résoudre les problèmes ci-dessus, l'auto-encodeur variationnel utilise la méthode d'inférence variationnelle, introduit un encodeur de probabilité apprenable pour se rapprocher de la distribution postérieure réelle, utilise la divergence KL pour mesurer la différence entre les deux distributions et résout ce problème à partir de la vraie distribution postérieure. se traduit par la manière de réduire la distance entre les deux distributions.
Nous omettons le processus de dérivation intermédiaire et développons la formule ci-dessus pour obtenir la formule (2),
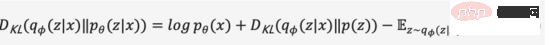
Étant donné que la divergence KL est non négative, nous pouvons transformer notre objectif de maximisation en formule (3),
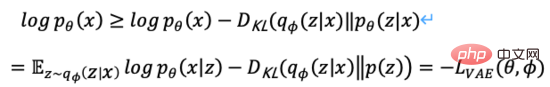
En résumé, nous définissons l'encodeur probabiliste et le décodeur probabiliste comme la fonction de perte du modèle, et sa forme négative est appelée Evidence Lower Bound (Evidence Lower Bound). Maximiser la limite inférieure des preuves équivaut à maximiser l'objectif. Le processus variationnel ci-dessus est l'idée centrale de la VAE et de ses différentes variantes. Grâce au raisonnement variationnel, le problème est transformé en une limite inférieure de preuve qui maximise la génération de données réelles.
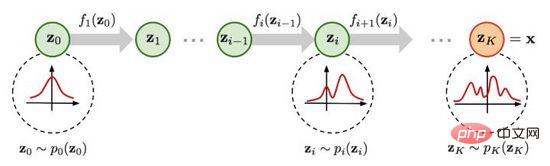
Figure 5. Processus de génération basé sur les flux
Comme le montre la figure 5, il est supposé que la distribution des données d'origine peut être transformée à partir de la distribution connue grâce à une série de fonctions de transformation réversibles. la distribution est obtenue, c'est-à-dire. Grâce aux règles de changement des déterminants et des variables de la matrice de Jacob, nous pouvons estimer directement la fonction de densité de probabilité des données réelles (formule (4)) et maximiser la log-vraisemblance calculable.
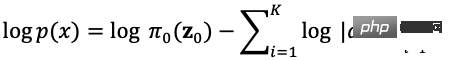
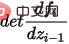 est le déterminant de Jacobs de la fonction de transformation, donc en plus d'être réversible, il nécessite également que son déterminant de Jacobs puisse être facilement calculé. Les modèles de génération basés sur le flux tels que Glow utilisent une convolution réversible 1x1 pour une estimation précise de la densité et obtiennent de bons résultats en matière de génération de visages.
est le déterminant de Jacobs de la fonction de transformation, donc en plus d'être réversible, il nécessite également que son déterminant de Jacobs puisse être facilement calculé. Les modèles de génération basés sur le flux tels que Glow utilisent une convolution réversible 1x1 pour une estimation précise de la densité et obtiennent de bons résultats en matière de génération de visages.

Figure 6. Processus de diffusion et inverse du modèle de diffusion
Le modèle de diffusion définit deux processus, direct et inverse. Le processus direct ou processus de diffusion est distribué à partir de données réelles. Lors de l'échantillonnage, le bruit gaussien. est progressivement ajouté aux échantillons pour générer une séquence d'échantillons de bruit. Le processus d'ajout de bruit peut être contrôlé par le paramètre de variance. À ce moment-là, il peut être approximativement équivalent à une distribution gaussienne. Le processus de diffusion est un processus contrôlable prédéfini. Le processus d'ajout de bruit peut être exprimé sous la forme de l'équation (5) avec une distribution conditionnelle,
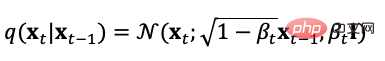
Il ressort de la définition du processus de diffusion que nous pouvons utiliser la formule d'échantillonnage ci-dessus. à n'importe quelle taille de pas,
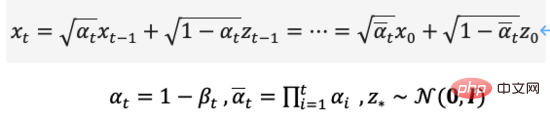
De même, nous pouvons également inverser le processus de diffusion, échantillonner à partir du bruit gaussien et apprendre un modèle pour estimer la distribution de probabilité conditionnelle réelle. Par conséquent, le processus inverse peut être défini comme l'équation (7). ,
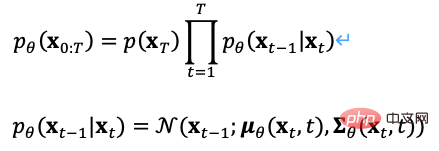
Il existe de nombreux choix pour les objectifs d'optimisation du modèle de diffusion. Par exemple, pendant le processus de formation, puisqu'il peut être calculé directement à partir du processus direct, nous pouvons échantillonner à partir de la distribution prédite. classification et étiquettes de texte comme entrées conditionnelles, optimisant la perte de reconstruction avec une erreur quadratique moyenne minimale. Ce processus est équivalent à un auto-encodeur.
Dans le modèle de probabilité de diffusion de débruitage DDPM, l'auteur a construit une version simplifiée de la perte du modèle de prédiction du bruit (équation (8)) grâce à la technologie de reparamétrage, et a saisi les données bruyantes à la taille du pas 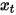 Former le modèle pour prédire le bruit
Former le modèle pour prédire le bruit 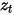 , pendant le processus d'inférence, la moyenne de distribution gaussienne de
, pendant le processus d'inférence, la moyenne de distribution gaussienne de
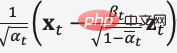
est utilisée pour prédire les données débruitées 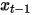 pour obtenir le débruitage de l'image du visage.
pour obtenir le débruitage de l'image du visage.
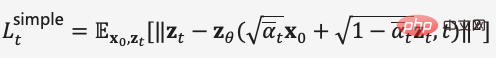
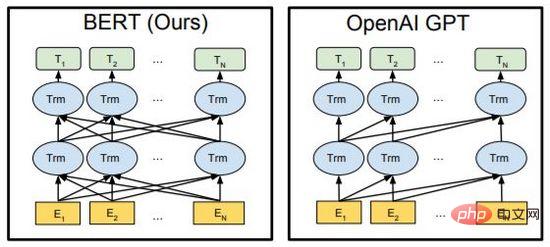
Figure 7. BERT et GPT
BERT et GPT sont des modèles de langage pré-entraînés très puissants dans le domaine de la PNL ces dernières années, et sont utilisés dans la génération d'articles, de grandes avancées ont été réalisées dans les tâches en aval telles que la génération de code, la traduction automatique, les questions-réponses, etc. Les deux utilisent Transformer comme cadre principal de l'algorithme et les détails de mise en œuvre sont légèrement différents (Figure 7).
BERT est essentiellement un encodeur bidirectionnel. Il utilise deux tâches, Mask Language Model (MLM) et Next Sentence Prediction (NSP), pour apprendre la représentation caractéristique du texte de manière auto-supervisée. Il peut remplacer Word2Vec et être transféré vers. d'autres tâches d'apprentissage. L'essence de GPT est un décodeur autorégressif. En utilisant des données massives et en empilant continuellement des modèles, il maximise la valeur de vraisemblance du modèle linguistique pour prédire le texte suivant. Il est important de noter que pendant le processus de formation, le texte de post-commande de GPT est masqué afin qu'il soit invisible lors de la formation et de la prédiction du texte de pré-commande. Dans BERT, tous les textes sont visibles les uns par les autres et participent au calcul de l'auto-attention. BERT utilise un masque aléatoire ou une entrée de remplacement. Améliore la robustesse du modèle et les capacités d'expression.
Le grand succès de Transformer dans le domaine de la PNL a incité les chercheurs à réfléchir à sa capacité à exprimer les caractéristiques de l'image. Contrairement à la PNL, les informations sur l'image sont énormes et redondantes. L'utilisation directe de la modélisation Transformer empêchera le modèle d'apprendre en raison du grand nombre de jetons. Jusqu'en 2020, les chercheurs ont proposé ViT, qui réduisait la dimension des données d'image grâce à des méthodes de projection patch et linéaire, et utilisait Transformer Encoder comme encodeur d'image pour produire des résultats de prédiction de classification, obtenant ainsi des résultats considérables.
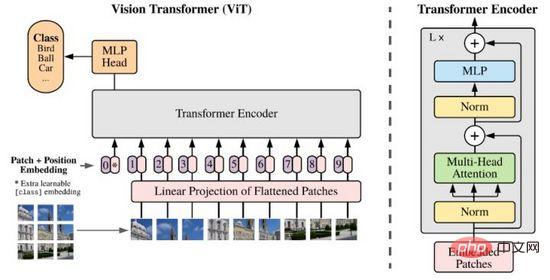
Figure 8. ViT
Maintenant, Transformer est devenu un nouvel objet de recherche dans le domaine du traitement d'images, remettant constamment en question le statut de CNN avec son puissant potentiel.
CLIP (Contrastive Language-Image Pretraining) est une méthode d'apprentissage contrastif proposée par OpenAI qui connecte les représentations de caractéristiques d'image et de texte. Comme le montre la figure 9, CLIP encode avec succès les paires texte-image pour générer des paires de jetons via l'encodage Transformer, et utilise des opérations de produit scalaire pour mesurer la similarité. À partir de là, pour chaque texte, nous obtenons la probabilité de classification unique pour toutes les images, et vice-versa. versa pour chaque image. Des probabilités de classification pour tous les textes peuvent également être obtenues. Au cours du processus de formation, nous optimisons la perte d'entropie croisée calculée pour chaque ligne et colonne de la matrice de probabilité de la figure 9 (1).
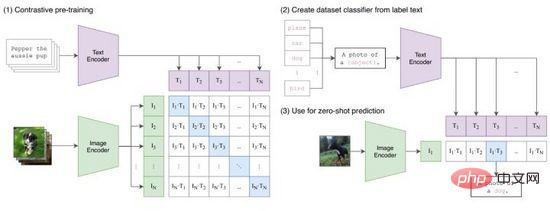
Figure 9. CLIP
CLIP mappe les représentations de caractéristiques du texte et des images dans le même espace. Bien qu'il ne réalise pas de transfert d'informations intermodal, il est très efficace en tant que méthode de compression de caractéristiques, de mesure de similarité et d'apprentissage de représentation intermodale. Intuitivement, nous générons des jetons d'image avec les caractéristiques les plus similaires parmi toutes les invites de texte générées dans la plage d'étiquettes, c'est-à-dire qu'une classification d'image est terminée (Figure 9(2)), en particulier lorsque la distribution des données des images et des étiquettes n'a pas été effectuée. l'ensemble d'entraînement apparu auparavant, CLIP a toujours la capacité d'apprendre sans coup.
Après l'introduction des deux chapitres précédents, nous avons systématiquement passé en revue les technologies de base liées à la génération d'images et à l'apprentissage de représentations multimodales. Ce chapitre présentera les trois dernières méthodes de génération d'images multimodales. . Interprétation Comment ils sont modélisés à l'aide de ces techniques sous-jacentes.
DALL·E a été proposé par OpenAI début 2021 et vise à entraîner un décodeur autorégressif du texte d'entrée à l'image de sortie. Grâce à l'expérience réussie de CLIP, nous savons que les caractéristiques du texte et les caractéristiques de l'image peuvent être codées dans le même espace de caractéristiques. Nous pouvons donc utiliser Transformer pour modéliser de manière autorégressive les caractéristiques du texte et de l'image sous la forme d'un flux de données unique (« modèle de manière autorégressive le texte et l'image). jetons comme un flux de données unique"). flux de données"). Le processus de formation de
DALL·E est divisé en deux étapes. L'une consiste à former un auto-encodeur variationnel pour l'encodage et le décodage d'images, et l'autre consiste à former un décodeur autorégressif de texte et d'images pour prédire les jetons des images générées, comme illustré à la figure 10.
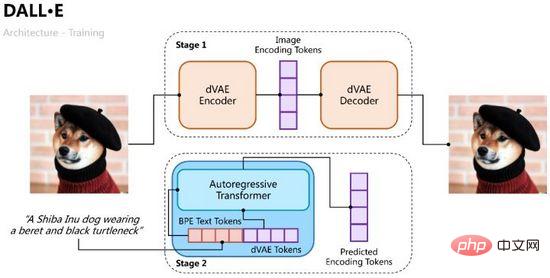
Figure 10. Le processus de formation de DALL·E
Le processus de raisonnement est plus intuitif. Utilisez le transformateur autorégressif pour décoder progressivement les jetons de texte en jetons d'image. Au cours du processus de décodage, nous pouvons échantillonner plusieurs groupes de jetons. des échantillons via la probabilité de classification, puis plusieurs groupes de jetons d'échantillon sont entrés dans l'auto-encodage variationnel pour décoder plusieurs images générées, et sont triés et sélectionnés via le calcul de similarité CLIP, comme le montre la figure 11.
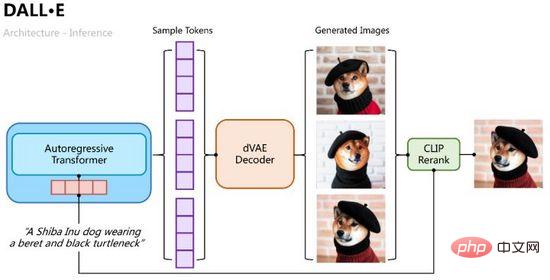
Figure 11. Le processus d'inférence de DALL·E
Identique à VAE, nous utilisons un encodeur probabiliste et un décodeur probabiliste pour modéliser la distribution de probabilité a posteriori des caractéristiques de la couche cachée et la distribution de probabilité de vraisemblance de l'image générée, en utilisant le modèle la distribution de probabilité conjointe du texte et des images prédite par Transformer comme a priori (initialisée à une distribution uniforme dans la première étape, la limite inférieure de la preuve de la cible d'optimisation peut être obtenue,
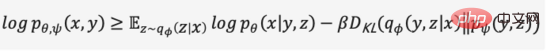
). Dans la première étape du processus de formation, DALL·E utilise un auto-encodeur variationnel discret (Discrete VAE) appelé dVAE, qui est une version améliorée du Vector Quantized VAE (VQ-VAE). En VAE, nous utilisons une distribution de probabilité pour décrire l'espace continu de la couche cachée et obtenons le code de la couche cachée par échantillonnage aléatoire, mais ce code n'est pas aussi déterministe que les caractères de langage discret. Afin d'apprendre le « langage » de l'espace des couches cachées de l'image, VQ-VAE utilise un ensemble de quantifications vectorielles apprenables pour représenter l'espace des couches cachées quantifié est appelé Embedding Space ou Codebook/Vocabulary. Le processus de formation et le processus de prédiction de VQ-VAE visent à trouver le vecteur de couche cachée le plus proche du vecteur de codage de l'image, puis à décoder le langage vectoriel mappé en une image (Figure 12). La fonction de perte se compose de trois parties, optimisant respectivement le. perte de reconstruction, mettez à jour l'espace d'intégration et mettez à jour l'encodeur, et le dégradé se termine.
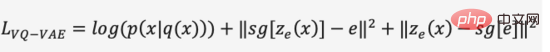
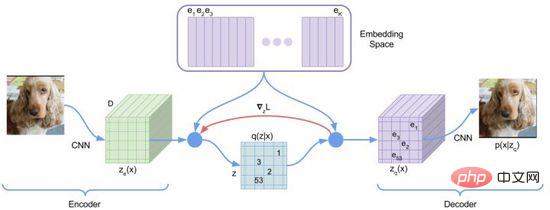
Figure 12. VQ-VAE
VQ-VAE a une certaine probabilité a posteriori en raison de l'hypothèse de sélection du voisin le plus proche, c'est-à-dire que la probabilité du vecteur de couche cachée le plus proche est de 1 et les autres sont de 0, et il n'y a pas de caractère aléatoire ; Le processus de sélection du vecteur le plus proche n'est pas différentiable et la méthode de l'estimateur direct est utilisée pour transmettre le gradient à .
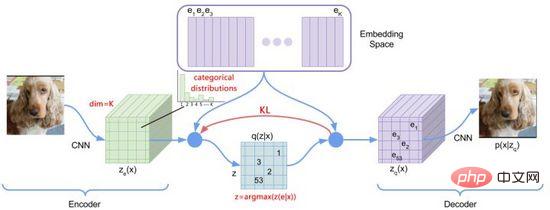
Figure 13. dVAE
Afin d'optimiser les problèmes ci-dessus, DALL·E a utilisé Gumbel-Softmax pour construire un nouveau dVAE (Figure 13), et la sortie du décodeur devient 32*32 K=8192 dimensions sur la probabilité de classification de l'espace d'intégration. Au cours du processus de formation, du bruit est ajouté au calcul Softmax de la probabilité de classification pour introduire un caractère aléatoire. La température décroissante est utilisée pour rendre la distribution de probabilité proche du codage à chaud. reparamétré pour le rendre différentiable (formule (11)), le voisin le plus proche est toujours pris lors du processus d'inférence.
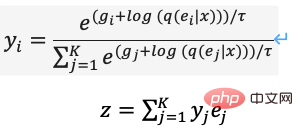
L'implémentation de PyTorch peut définir hard=True pour produire un encodage approximatif à chaud, tout en conservant la dérivabilité via y_hard = y_hard - y_soft.detach() + y_soft .
Lorsque la première étape de la formation est terminée, nous pouvons corriger dVAE pour générer les jetons d'image de la cible prédite pour chaque paire texte-image. Au cours de la deuxième phase de formation, DALL·E a utilisé la méthode BPE pour encoder d'abord le texte en jetons de texte avec la même dimension d=3968 que les jetons d'image, puis concaténer les jetons de texte et les jetons d'image, ajouter un codage de position et un codage de remplissage. , et utiliser Transformer Encoder effectue une prédiction autorégressive, comme le montre la figure 14. Afin d'améliorer la vitesse de calcul, DALL·E utilise également trois mécanismes de masque d'attention clairsemés : ligne, colonne et convolutionnel.
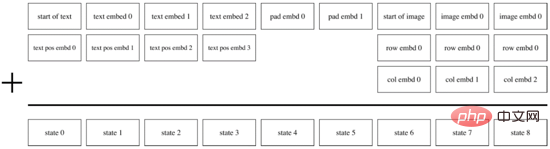
Figure 14. Décodeur autorégressif de DALL·E
Basé sur l'implémentation ci-dessus, DALL·E peut non seulement générer des images « réelles » basées sur la saisie de texte, mais également effectuer une création de fusion, une compréhension de scène et une transformation de style. illustré à la figure 15. De plus, l'effet de DALL·E peut s'aggraver dans les domaines professionnels et sans échantillon, et la résolution de l'image générée (256*256) est inférieure.

Figure 15. Différents scénarios de génération de DALL·E
Afin d'améliorer encore la qualité de la génération d'images et d'explorer l'interprétabilité de l'espace de fonctionnalités texte-image, OpenAI combine le modèle de diffusion et CLIP dans DALL·E 2 a été proposé en avril 2022, ce qui a non seulement augmenté la taille de génération à 1024*1024, mais a également visualisé le processus de migration de l'espace de fonctionnalités texte-image via l'opération d'interpolation de l'espace de fonctionnalités.
Comme le montre la figure 16, DALL·E 2 utilise l'intégration de texte et l'intégration d'images obtenues par l'apprentissage comparatif CLIP comme objets d'entrée de modèle et de prédiction. Le processus spécifique consiste à apprendre un a priori et à prédire l'intégration d'images correspondante à partir du texte des articles. utiliser le transformateur autorégressif et le modèle de diffusion sont formés de deux manières, ce dernier fonctionne mieux sur chaque ensemble de données ; puis apprendre un décodeur de modèle de diffusion UnCLIP, qui peut être considéré comme le processus inverse de l'encodeur d'image CLIP, et l'intégration d'image prédite par Prior À mesure que des conditions sont ajoutées pour obtenir le contrôle, l'intégration de texte et le contenu du texte sont des conditions facultatives. Afin d'améliorer la résolution, UnCLIP ajoute également deux décodeurs de suréchantillonnage (réseaux CNN) pour générer à l'envers des images de plus grande taille.
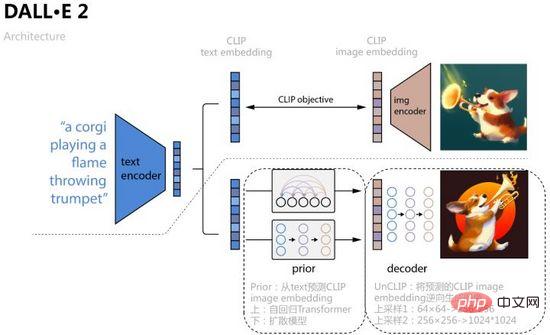
Figure 16. DALL·E 2
Dans la formation sur le modèle de diffusion de Prior, DALL·E 2 utilise un décodeur de transformateur pour prédire le processus de diffusion, et la séquence d'entrée est un texte codé en BPE + une intégration de texte + une intégration de pas de temps+ actuellement ajout de l'intégration d'images bruyantes, prédire l'intégration d'images débruitées, utiliser MSE pour construire la fonction de perte,
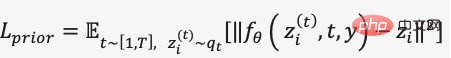
DALL·E 2 Afin d'éviter que le modèle ne produise des résultats de génération de type directionnel pour des étiquettes de texte spécifiques, la richesse des fonctionnalités est réduite, et pour la diffusion Les conditions de prédiction du modèle sont restreintes pour garantir un guidage sans classificateur. Par exemple, dans la formation du modèle de diffusion de Prior et UnCLIP, la probabilité de suppression est définie pour des conditions telles que l'ajout d'incorporation de texte, afin que le processus de génération ne termine pas l'entrée de la condition dépendante. Par conséquent, dans le processus de génération inverse, nous pouvons générer différentes variantes de la même image grâce à l'échantillonnage d'intégration d'images tout en conservant les fonctionnalités de base. Nous pouvons également interpoler respectivement dans l'intégration d'images et de texte. Le contrôle du taux d'interpolation peut générer des résultats de visualisation de migration fluides. représenté sur la figure 17 représentée.

Figure 17. Préservation et transfert des caractéristiques de l'image que DALL·E 2 peut réaliser
DALL·E 2 a réalisé de nombreuses expériences de vérification sur l'efficacité de Prior et UnCLIP, par exemple, à travers trois méthodes 1) Seulement contenu du texte Entrez le modèle de génération UnCLIP ; 2) Saisissez uniquement le contenu du texte et l'intégration du texte dans le modèle de génération UnCLIP 3) Ajoutez l'intégration d'image prédite par Prior sur la base de la méthode ci-dessus, et les effets de génération des trois méthodes s'améliorent progressivement ; vérifier l’efficacité de Prior. De plus, DALL·E 2 utilise PCA pour réduire la dimension d'intégration de l'espace des couches cachées. À mesure que la dimension est réduite, les caractéristiques sémantiques de l'image générée s'affaiblissent progressivement. Enfin, DALL·E 2 a comparé d'autres méthodes sur l'ensemble de données MS-COCO et a obtenu la meilleure qualité de génération avec FID= 10,39 (Figure 18).
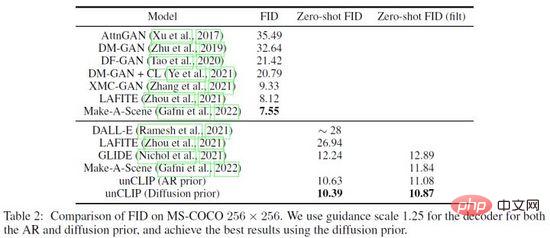
Figure 18. Résultats de comparaison de DALL·E 2 sur l'ensemble de données MS-COCO
ERNIE-VILG est un modèle de génération bidirectionnelle texte-image pour les scènes chinoises proposé par Baidu Wenxin début 2022 .
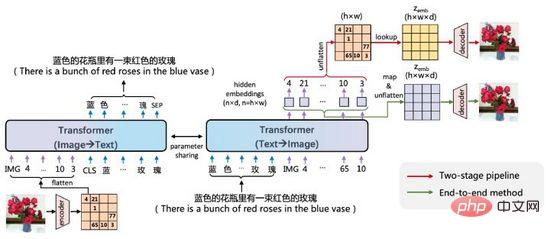
Figure 19. L'idée d'ERNIE-VILG
ERNIE-VILG est similaire à DALL·E. Elle code les caractéristiques de l'image via des auto-encodeurs variationnels pré-entraînés et utilise Transformer pour prédire de manière autorégressive les jetons de texte et les jetons d'image, principalement la différence. est :
Une autre fonctionnalité puissante d'ERNIE-VILG est qu'il peut gérer la génération de plusieurs objets et des relations de position complexes dans les scènes chinoises, comme le montre la figure 20.

Figure 20. Exemple de génération ERNIE-VILG
Cet article explique le dernier nouveau paradigme des graphes vincentiens à travers des exemples, y compris l'application de méthodes de génération telles que les auto-encodeurs variationnels et les modèles de diffusion texte-image. des méthodes d'apprentissage de la représentation de l'espace latent telles que CLIP et des techniques de modélisation telles que la discrétisation et le reparamétrage.
De nos jours, la technologie de génération de texte en image a un seuil élevé et son coût de formation dépasse de loin celui des méthodes monomodales telles que la reconnaissance faciale, la traduction automatique et la synthèse vocale. En prenant DALL·E comme exemple, OpenAI a. collecté et étiqueté 250 millions de paires. Pour l'échantillon, 1 024 GPU V100 ont été utilisés pour entraîner un modèle avec 12 milliards de paramètres. En outre, des problèmes tels que la discrimination raciale, la pornographie violente et la vie privée sensible ont toujours existé dans le domaine de la génération d'images. À partir de 2020, de plus en plus d’équipes d’IA ont investi dans la recherche sur la génération multimodale. Dans un avenir proche, nous pourrions être impossibles à distinguer du faux dans le monde réel et dans le monde généré.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Le rôle du Serverlet en Java
Le rôle du Serverlet en Java
 Comment lire une colonne dans Excel en python
Comment lire une colonne dans Excel en python
 Quelle est la différence entre les vues et les tables de base de données
Quelle est la différence entre les vues et les tables de base de données
 Le rôle de la balise de base
Le rôle de la balise de base
 Tutoriel C#
Tutoriel C#
 Quelles sont les utilisations du dézender ?
Quelles sont les utilisations du dézender ?
 Comment partager une imprimante entre deux ordinateurs
Comment partager une imprimante entre deux ordinateurs
 Utilisation de UpdatePanel
Utilisation de UpdatePanel








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



