


En comptant les étoiles et en espérant la lune, des milliers de fans de Jay attendaient depuis 6 ans, Jay Chou sortait enfin un nouvel album ! Une fois mis en ligne, il a suscité des discussions sur Internet.
Alors que tout le monde était plongé dans les beaux souvenirs de ces années luxuriantes, l'ami qui a posté l'audio viral a déclaré : Cette conversation était en fait une synthèse vocale !
Quand il s'agit de "synthèse vocale", les éléments suivants peuvent apparaître dans votre esprit : "Tournez à gauche à l'intersection devant" avec un riche mais mécanique tonalité
• Lorsque vous répondez au téléphone , la personne de l'autre côté a dit "Bonjour, c'est xx Credit Card Center" maladroitement et sans émotion, le nom de cet homme est Xiaoshuai"…
Maintenant, elle a directement renversé les stéréotypes de nombreuses personnes. La technologie de synthèse vocale peut déjà atteindre le résultat. même effet parfait et naturel que l’audio ci-dessus. L'éditeur de cet audio -Volcano Voice, ByteDance
AI Lab Speech & Audio Intelligent Speech and Audio Team
, a utilisé deux morceaux d'audio pour mieux déchiffrer le contenu au public. .Le texte d'entrée de ces phrases est exactement le même, c'est-à-dire « La cuisine du Sud préfère les trempettes. Par exemple, c'était ma première fois à Shanghai que j'ai appris que les légumes au barbecue doivent également être servis avec des trempettes. . " Cependant, les effets audio synthétisés sont évidemment différents. , c'est-à-dire que le deuxième morceau d'audio provient de la nouvelle technologie de synthèse vocale de dialogue surnaturel lancée cette fois par l'équipe Volcano Voice. Rappelez-vous l'état des expressions quotidiennes des gens. Le cerveau a besoin de temps de réflexion pour traiter les informations. En ce qui concerne le langage, les gens vont involontairement hésiter, prononcer, inverser ou même changer leurs mots au milieu d'une phrase, bégayer et répéter. Ils mettront également délibérément l'accent sur la prononciation pour mettre l'accent sur les informations clés qu'ils souhaitent exprimer. Cela entraîne un grand nombre d’expressions subtiles et difficiles à observer. Ces phénomènes sont difficiles à capturer et à restituer dans les TTS traditionnels. La reproduction parfaite de ces subtilités est la source du mystère qui rend difficile la distinction de l'authenticité du son, et c'est aussi le mystère de l'audio mentionné ci-dessus. Plus précisément, La dernière technologie de synthèse vocale de dialogue surnaturelle publiée par l'équipe Volcano Voice
est plus réaliste et naturelle que la TTS traditionnelle, c'est-à-dire tous les détails tels que les particules modales, les sons d'inhalation, les pauses pendant l'hésitation et Les extensions de prononciation sont entièrement intégrées. Elles sont parfaitement reproduites et ne nécessitent que 1/4 des données de la bibliothèque sonore conventionnelle pour restaurer parfaitement les caractéristiques rythmiques subtiles et les habitudes de prononciation de personnes réelles parlant, rendant l'effet de synthèse plus réaliste.Les résultats de l'évaluation professionnelle montrent qu'il n'y a fondamentalement aucune différence entre cette nouvelle technologie de Huoshan Voice et les enregistrements de personnes réelles, et il est difficile pour les évaluateurs de la distinguer. De plus, cette technologie a été utilisée dans de nombreux scénarios tels que le doublage vidéo et le service client téléphonique. Elle sera prochainement lancée sur le site officiel de Volcano Engine Voice Technology.
Comment diable une technologie aussi puissante peut-elle être réalisée ?
Selon les rapports, les manifestations mentionnées ci-dessus telles que le halètement, la déglutition, la prolongation involontaire de la prononciation des mots lors de la réflexion et les rires faibles qui se produisent souvent dans la communication réelle sont appelées phénomènes paralangagiers, bien que ce soit le plus représentation réaliste du processus de pensée et d'expression du cerveau humain. Cependant, comme le cadre technologique traditionnel de synthèse vocale ne peut pas modéliser efficacement des phénomènes paralinguistiques peu distribués, les performances de restauration prosodique lors de la parole sont limitées et trop « correctes ». Selon les difficultés ci-dessus, la technologie de synthèse de la parole surnaturelle de Huoshan Voice fait des percées à partir de deux niveaux: Text et Speech Modélisation, en particulier:
imite la façon dont de vraies personnes parlent et effectue une transcription familière contrôlable du texte, permettant au texte de mieux adopter le langage familier et d'éviter que l'effet final ne soit trop écrit. Au niveau de la voix, l'équipe analyse les avancées du modèle et ajoute des prédictions linguistiques supplémentaires du côté entrée du TTS pour imiter les caractéristiques de prononciation de la personne afin d'obtenir des effets vocaux spontanés naturels. Il convient de mentionner que l'équipe a efficacement amélioré la stabilité et l'expressivité du modèle en utilisant la solution de modélisation TTS avec des fonctionnalités non supervisées. Elle peut obtenir des sons très naturels et multiformes en utilisant seulement 1/4 de l'échelle de données de. bibliothèques de sons conventionnelles. L’effet de changement de rythme est génial, non ? Le texte est l'entrée de la technologie de synthèse vocale si son style est proche de l'expression de personnes réelles. est le premier facteur pour améliorer l'effet de synthèse. Cependant, en raison des habitudes d'écriture profondément enracinées, la plupart des textes pré-synthétisés ne sont pas assez naturels ou nécessitent beaucoup d'efforts et d'ajustements continus, ce qui prend du temps et demande beaucoup de travail. . Afin de résoudre de tels problèmes, l'équipe Huoshan Voice a adopté une solution en deux étapes et a obtenu de bons résultats : • Phase 1 : Utilisation d'une méthode auto-supervisée, utilisation de pseudo-données pour pré-former le langage familier modèle, réduisant La demande de volume de données est réduite en même temps, une structure de réseau de pointeurs est introduite dans le modèle pour améliorer la contrôlabilité du texte. • Phase 2 : Utilisez une petite quantité de données d'annotation manuelles de haute qualité pour affiner le modèle familier pré-entraîné et enfin obtenir des effets de texte familiers contrôlables et naturels. Texte original Texte prédit automatiquement La cuisine du Sud préfère les trempettes. Par exemple, c'était ma première fois à Shanghai que j'ai appris que les légumes au barbecue doivent également être servis avec des trempettes Eh bien, . Cuisine du Sud Si c'est le cas, je préfère vraiment utiliser des trempettes et ainsi de suite , par exemple ma première fois euh, ma première fois je suis allé à Shanghai, et j'ai réalisé que les légumes de ce barbecue aussi doivent être accompagnés de trempettes Eh bien, c'est similaire à quand nous sortons pour acheter du chou, les sudistes disent que je veux un demi-chou, et ensuite les les nordistes disent que je veux la moitié un chou En fait, la cuisine du sud met davantage l'accent sur le goût des assaisonnements, c'est-à-dire que le chef utilise les assaisonnements pour montrer ses compétences Oui, en fait, la cuisine du sud met davantage l'accent sur le goût des assaisonnements, Autrement dit, Le chef utilise les assaisonnements pour mettre en valeur son savoir-faire Afin de mieux restaurer les personnes réelles, différentes de la technologie de synthèse vocale traditionnelle, Huoshan Voice dispose d'une modélisation paralangagère et d'une diversité prosodique. a également été étudiée en profondeur. En termes de modélisation paralinguistique, la technologie de synthèse introduite par l'équipe permet au modèle acoustique de modéliser une variété de phénomènes paralinguistiques tels que l'inspiration, le rire, l'hésitation et la correction qui apparaissent dans les expressions naturelles, et de les combiner avec les informations sémantiques du texte. pour insérer automatiquement le phénomène paralinguistique . Compte tenu à la fois de la rationalité et du caractère aléatoire lors du processus d'insertion, la performance est plus naturelle et réelle.
Inspirer > est effectivement très bon pour le corps. C.wav Extension>En gros, je ne prends pas beaucoup de petit-déjeuner. D.wav Katon>sont des petits pains au lait de soja et aux bâtonnets de pâte frits. Correction de glissement ParalangTest_is_000008_npy_01_new2.wav Huoshan Voice, l'équipe vocale et audio intelligente de ByteDance AI Lab Speech & Audio, fournit depuis longtemps des capacités technologiques de pointe en matière de technologie vocale IA et des produits vocaux complets à Douyin, Jianying, Tomato Novels, Feishu et d'autres solutions. et ouvrir les services techniques aux entreprises externes via le Volcano Engine. 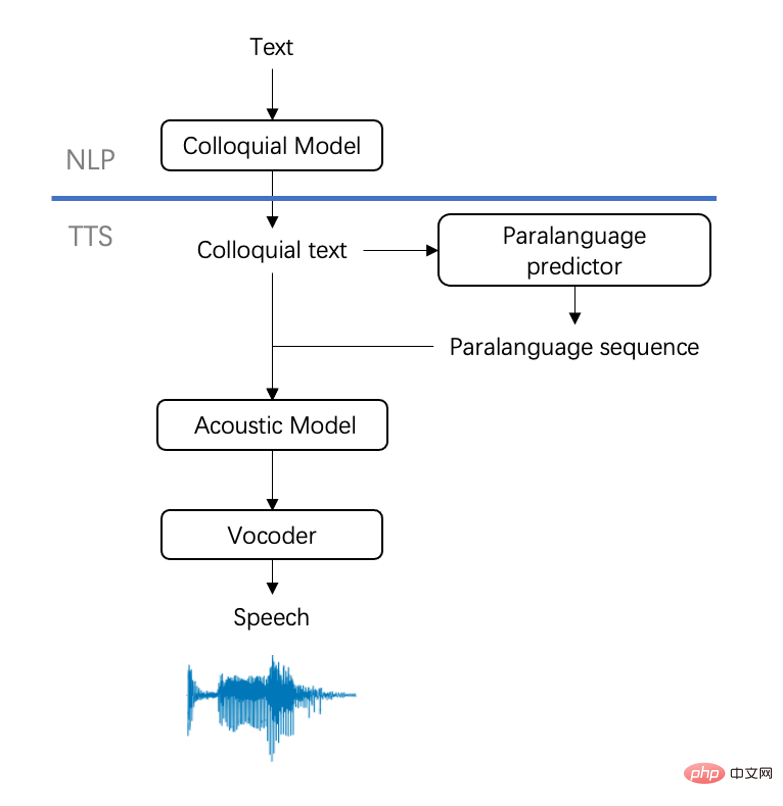
Dédié au langage familier du texte pour rendre « l'expression d'une personne réelle » vivante sur le papier
La modélisation paralangagère + la diversité prosodique est remarquable — le réalisme de la voix a été entièrement amélioré
texte
Supernatural
Je me sens comme ça
Regardez ce que nous faisons maintenant, le matin
En gros, comme notre matin
, j'ai vraiment envie de manger de la viande. Copie de
"Dans l'exploration de la diversité rythmique, nous avons combiné grâce à une technologie d'apprentissage de représentation non supervisée, nous avons développé indépendamment un cadre de modèle acoustique hautement expressif Grâce au découplage de la prononciation, du rythme et du timbre, il réduit non seulement la quantité de données requises, mais permet également une modélisation efficace des phénomènes de prononciation à extrêmement basse fréquence. dans le même temps, des caractéristiques de représentation non supervisées sont utilisées en combinaison avec la fréquence fondamentale au niveau du phonème, les informations énergétiques, etc. pour obtenir des changements naturels dans la prosodie et promouvoir une génération de parole conversationnelle de haute qualité », a conclu l'équipe vocale de Huoshan.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment utiliser la monnaie numérique
Comment utiliser la monnaie numérique
 Comment ouvrir des fichiers php sur un téléphone mobile
Comment ouvrir des fichiers php sur un téléphone mobile
 Quelles sont les touches de raccourci couramment utilisées dans WPS ?
Quelles sont les touches de raccourci couramment utilisées dans WPS ?
 Comment définir un arrêt programmé dans UOS
Comment définir un arrêt programmé dans UOS
 gestion des exceptions Java
gestion des exceptions Java
 Comment utiliser l'étiquette d'étiquette
Comment utiliser l'étiquette d'étiquette
 Téléchargement de l'application OuYi Exchange
Téléchargement de l'application OuYi Exchange
 Introduction au contenu principal du travail du backend
Introduction au contenu principal du travail du backend








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



